🌈write in front :🔍个人主页 : @啊森要自信的主页
✏️真正相信奇迹的家伙,本身和奇迹一样了不起啊!
欢迎大家关注🔍点赞👍收藏⭐️留言📝>希望看完我的文章对你有小小的帮助,如有错误,可以指出,让我们一起探讨学习交流,一起加油鸭。

文章目录
- 前言
- 一、转移表
- 二、回调函数是什么?
- 三、qsort函数细解
- 3.1 类比冒泡排序?
- 3.2 qosrt函数超详解
- 3.2.1qsort函数排序整型数据
- 3.2.2 使⽤qsort排序结构数据
- 四、 qsort函数的模拟实现
- 4.1 模拟qsort整形数据
- 4.2 模拟`qsort`排序结构数据
- 总结
前言
本小节,我们将继续学习C语言转移表,什么是回调函数,回调函数又是什么?qsort函数怎么使用,怎么理解处理,要注意的细节,当然qsort使用举例,最后我们进行qsort函数的模拟实现!文章干货满满,走起!
一、转移表
C语言转移表是指根据一定条件,实现程序执行流程的跳转或转移的机制。
具体来说,C语言中实现转移表的主要方式有:
goto语句:
goto语句可以实现无条件跳转,直接跳转到指定标签所在的代码块
goto 标签名;
例如:
goto label;
switch语句:
switch语句根据表达式的值,选择性地执行一个代码块。它实现了有条件跳转。
switch(表达式)
{
case 常数表达式1:
//语句
break;
case 常数表达式2:
//语句
break;
//其他case
default:
//语句
}
- continue语句:
continue用于跳过循环体剩余部分,直接跳转到循环条件判断语句。
例如:
for(i=0;i<10;i++)
{
if(i==5)
continue;
printf("%d",i);
}
break语句:
break用于跳出整个循环或switch语句。
例如:
for(i=0;i<10;i++)
{
if(i==5)
break;
printf("%d",i);
}
return语句:
return用于从函数中返回。
例如:
int func()
{
return 0;
}
- 拓展:
longjmp()/setjmp():
setjmp()和longjmp()是C语言中的两个非常重要的函数,它们可以实现非局部跳转的功能。
setjmp()函数声明如下:
int setjmp(jmp_buf env);
-
jmp_buf是可以保存环境信息的结构体。 -
setjmp()会将当前函数的执行环境信息保存到env中,并返回0。 -
然后程序可以正常执行。
-
当需要跳转时,调用
longjmp(env, val);longjmp()函数声明如下:
void longjmp(jmp_buf env, int val);
-
longjmp()第一个参数就是setjmp()保存的env。 -
它会将程序跳转回
setjmp()后面要执行的代码。 -
但此时
setjmp()会返回longjmp()第二个参数val,而不是0。
jmp_buf env是setjmp和longjmp函数用来保存环境信息的结构体变量。
jmp_buf是一个预定义的数据类型,它用来描述一个环境的状态。
env是一个jmp_buf类型的变量。- 当调用
setjmp(env)时,setjmp函数会将当前函数调用栈(包括函数参数、局部变量等环境信息)保存到env这个结构体变量中。- 之后程序可以正常执行。
- 当需要非局部跳转时,调用
longjmp(env, val)。longjmp函数第一个参数就是这个env。longjmp通过env这个结构体,可以恢复到setjmp函数保存环境时的状态。实现一个“跳回”的效果。
小总结:
jmp_buf是一个结构体类型,它可以保存一个函数环境的状态信息。env是一个此类型的变量,用于在setjmp和longjmp之间传递环境信息。setjmp函数把当前环境信息保存到env中。longjmp函数通过env这个结构体,实现恢复到setjmp时的环境状态,从而实现非局部跳转。
哎!当然你可以把env可以看作是一个“传送令牌”,只要通过longjmp把令牌改了,他就重新传送到setjmp,然后继续执行,它连接setjmp和longjmp,使得longjmp能找到正确的环境信息进行跳转。
所以通过setjmp()/longjmp()就实现了一个非局部跳转:程序似乎"跳回"到setjmp()后面要执行的代码,但实际上环境已经发生了变化。这在异常处理等场景中很有用。
工作原理是:
-
setjmp()函数会保存当前函数调用栈(包括函数参数和局部变量等信息)的环境,并返回0。 -
之后程序可以正常执行。
-
当需要非局部跳转时,调用
longjmp(),并将在setjmp()保存的环境作为参数传入。 -
这个时候程序就会跳转回
setjmp()保存的环境,仿佛从setjmp()后面继续执行。但此时setjmp()会返回非0值。
举个例子
# define _CRT_SECURE_NO_WARNINGS 1
#include <stdio.h>
#include <setjmp.h>
jmp_buf env; //jmp_buf是一个预定义的数据类型,它用来描述一个环境的状态。
//env是一个jmp_buf类型的变量。
void func()
{
//设置跳转点
int ret = setjmp(env);
if (0 == ret)
{
//正常流程
printf("In func()\n");
//触发跳转
longjmp(env, 1);
}
else
{
//跳转后流程
printf("Jumped back to func()\n");
}
}
int main()
{
func();
return 0;
}
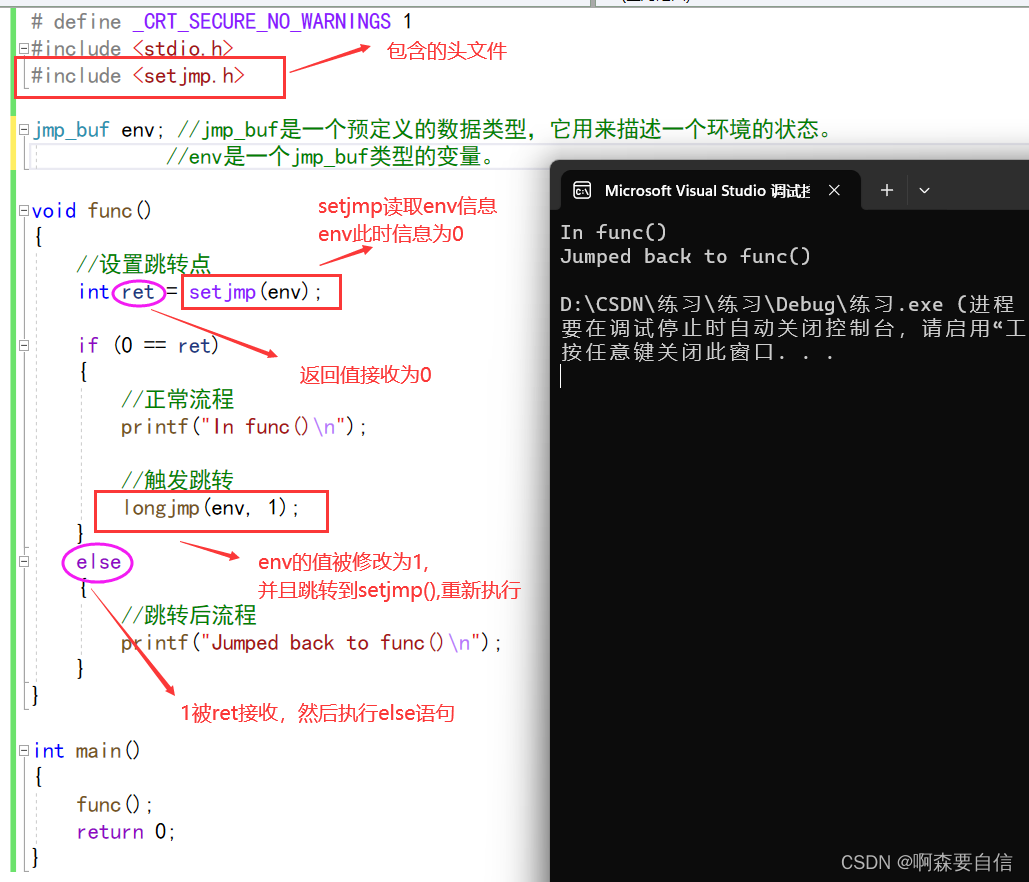
程序执行流程:
- 主函数调用
func()函数。func()内首先调用setjmp()设置跳转点env。由于setjmp()第一次调用会返回0,所以进入if块。- 打印"
In func()"信息。- 调用
longjmp(),触发非局部跳转。- 程序跳转回
setjmp()设置的环境env,此时setjmp()返回1。- 执行else块内的代码,打印"Jumped back to func()"。
- func()返回,主函数结束。
通过在函数内使用setjmp()/longjmp(),实现了从函数内非局部跳回函数外的功能。这与goto不同,可以实现跨函数的非顺序跳转。它常用于异常和错误处理等场景。
- C语言函数指针数组可以用来实现转移表。
具体来说:
-
定义一个函数指针数组,元素类型为函数指针。
-
每个数组元素都指向一个具体的函数。
-
根据条件调用数组对应元素所指向的函数。
这与传统的switch语句实现转移的效果是一致的。
一个简单的示例:
// 函数定义
void func1()
{
printf("func1\n");
}
void func2()
{
printf("func2\n");
}
// 主函数
int main()
{
// 函数指针数组
void (*funcs[])(void) =
{
func1,
func2
};
int id = 1; // 条件值
// 根据条件调用数组元素函数
funcs[id]();
return 0;
}
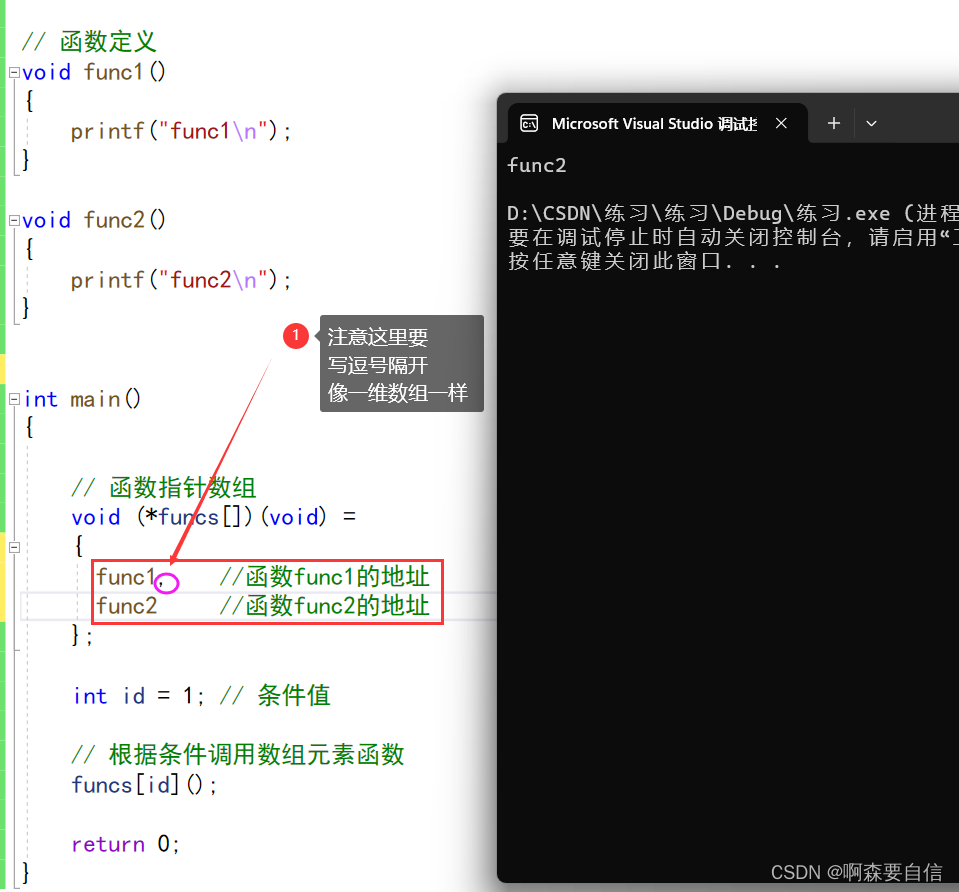
这样就实现了根据条件值动态调用不同函数的功能,相当于一个简单的转移表。
函数指针数组用于转移表的优点是:
- 更灵活,可以在运行时动态添加/删除函数
- 扩展性好,支持条件复杂情况下的多路径转移
- 与传统switch语句相比代码更简洁清晰
所以总的来说,函数指针数组正是C语言实现转移表的一个很好的选择。它可以很好地替代switch语句实现更复杂的多路转移逻辑。
通过这个你可能不太能看出哪里能很好的替代switch语句,让我们来看一个典型的例子,实现一个计算器!!!
switch实现计算器:
主要实现计算器程序思路:
-
定义了四个运算函数add、sub、mul、div实现四则运算。
-
main函数中:
-
使用do while循环控制程序循环执行。
-
打印菜单让用户选择运算类型。
-
根据用户选择用switch case调用对应的运算函数。
-
每次运算前输入两个操作数,运算后打印结果。
- 选择0退出循环,退出程序。
#include <stdio.h>
int add(int a, int b)//加法
{
return a + b;
}
int sub(int a, int b)//减法
{
return a - b;
}
int mul(int a, int b)//乘法
{
return a * b;
}
int div(int a, int b)//除法
{
return a / b;
}
int main()
{
int x, y;
int input = 1;
int ret = 0;
do
{
printf("*************************\n");
printf("**** 1:add 2:sub ***\n");
printf("**** 3:mul 4:div ***\n");
printf("**** 0:exit .... ***\n");
printf("*************************\n");
printf("请选择:");
scanf("%d", &input);
switch (input)//选择
{
case 1:
printf("输入两个操作数:");
scanf("%d %d", &x, &y);
ret = add(x, y);
printf("ret = %d\n", ret);
break;
case 2:
printf("输入两个操作数:");
scanf("%d %d", &x, &y);
ret = sub(x, y);
printf("ret = %d\n", ret);
break;
case 3:
printf("输入两个操作数:");
scanf("%d %d", &x, &y);
ret = mul(x, y);
printf("ret = %d\n", ret);
break;
case 4:
printf("输入两个操作数:");
scanf("%d %d", &x, &y);
ret = div(x, y);
printf("ret = %d\n", ret);
break;
case 0:
printf("退出程序\n");
break;
default:
printf("选择错误,请重新选择\n");
break;
}
} while (input);
return 0;
}
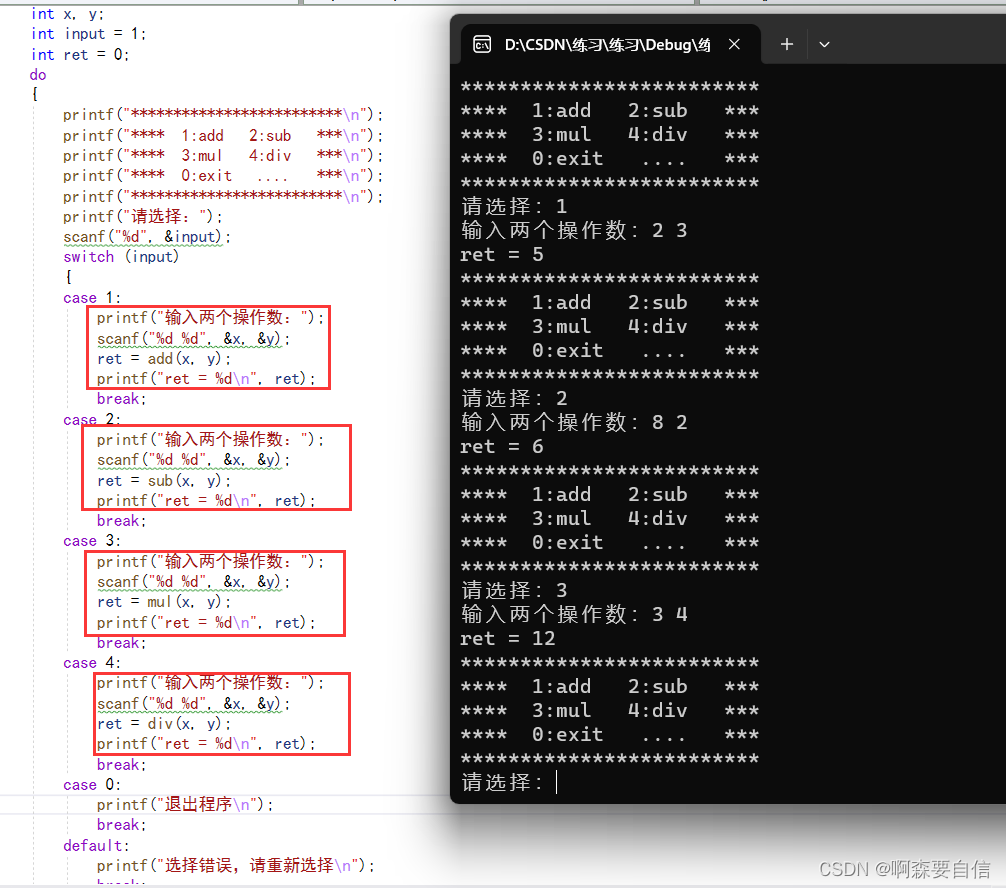
实现是实现了,但是
case里面的每个代码块除了ret = (?)(x,y);有点不同,其他都很相似,这么多代码重复写,会造成代码的冗余,如果我们又继续给用户增加功能,比如&,^,>>等等,然后一个功能我们就加一个case,case多了,代码重复的也多咋改变呢?不着急,我们不是学习了函数指针数组吗?
我们可以把函数的地址存储在数组里面,然后通过指针访问数组下标
(0,1,2,3,4,5...),然后解引用找到我们要找到我们要实现函数的地址
然后给他传参,再接收他的计算的返回值不就搞定了。
哈哈哈哈!!掌声应该送给自己,说做就做!让我们继续往下走。
函数指针数组实现计算器:
思路:
-
定义了4个函数Add、Sub、Mul、Div,用于四则运算。
-
menu()函数打印菜单界面。 -
定义了一个函数指针数组pfArr,元素类型为int (*)(int, int),可以存储这4个二元运算函数的地址。
-
在主函数中使用
do-while循环不断运行:-
调用
menu()打印菜单 -
scanf输入选择 -
根据选择从
pfArr数组中获取对应函数的地址 -
调用该函数进行运算
-
打印结果
-
void menu()//封装菜单
{
printf("******************************\n");
printf("**** 1. add 2. sub ****\n");
printf("**** 3. mul 4. div ****\n");
printf("**** 0. exit ****\n");
printf("******************************\n");
}
int Add(int x, int y)
{
return x + y;
}
int Sub(int x, int y)
{
return x - y;
}
int Mul(int x, int y)
{
return x * y;
}
int Div(int x, int y)
{
return x / y;
}
int main()
{
int input = 0;
int x = 0;
int y = 0;
int ret = 0;
do
{
menu();
//函数指针数组的方式解决一下
//这里的函数指针数组,我们称为转移表
//
为什么这里要加NULL,直接{add,sub,mul,div}不行吗?
如果真是可以的话,那我们观察他的下标 0 1 2 3
此时此刻,如果我们选择1.add,那么(*p[1])取出的地址是sub,这不对呀,
如果我们在前面加一个NULL,{ NULL,add,sub,mul,div }
下标为 0 1 2 3 4
地址:*p[ 0 ] == 0, *p[ 1 ] ==add
int (*pfArr[])(int, int) = { NULL, Add, Sub, Mul, Div };
// 0 1 2 3 4
printf("请选择:");
scanf("%d", &input);
if (input == 0)
{
printf("退出计算器\n");
}
else if (input >= 1 && input <= 4)
{
printf("请输入两个操作数:");
scanf("%d %d", &x, &y);
ret = pfArr[input](x, y); //(*p[input])==add/sub/mul/div函数名,也就是函数的地址
//(p[input])也可以,*号有无,都相当于函数名,也是函数地址
// 也就是ret=(p[input])(x,y);
printf("%d\n", ret);
}
else
{
printf("选择错误,重新选择\n");
}
} while (input);
return 0;
}
解释:
当input输入1, pfArr[1]取得Add的地址,然后通过Add函数的地址,执行指令。(当然同理input输入2,3,4也是同样的步骤)。
如果要增加功能,那么可以int (*pfArr[])(int, int) = { NULL, Add, Sub, Mul, Div };增加相应的功能,然后增加相应功能的代码块!
比如,你想要增加位运算(&, |, ^)的功能:
- 增加位运算函数:
int And(int x, int y) {
return x & y;
}
int Or(int x, int y) {
return x | y;
}
int Xor(int x, int y) {
return x ^ y;
}
- 修改菜单显示:
void menu() {
printf("******************************\n");
printf("**** 1. add 2. sub ****\n");
printf("**** 3. mul 4. div ****\n");
printf("**** 5. & 6. | ****\n");
printf("**** 7. ^ ****\n");
printf("**** 0. exit ****\n");
printf("******************************\n");
}
- 增加函数指针:
int (*pfArr[])(int, int) = {NULL, Add, Sub, Mul, Div, And, Or, Xor};
- 判断函数选择范围:
if(input >= 1 && input <= 7) {
ret = pfArr[input](x, y);
}
这样就增加了位运算的功能选择了。
如果还需要其他运算,可以继续增加对应的函数和菜单显示即可。
但是,思考———>
int (*p[5])(int x, int y) = { NULL,add,sub,mul,div };那函数的add,sub,mul,div这些地址是不是也和一维数组一样,存储在函数指针数组里面,他们的地址是否是连续的呢?
解释:
函数地址在函数指针数组中的存储方式与一维数组类似,但有一点不同:
-
函数指针数组
pfArr中,add、sub等函数地址的存储是连续的,就像一维数组元素一样,如下标0,1,2,3,4这样连续存储后就可以访问了。 -
但是,函数本身的代码可能不一定存储在连续内存地址中。
更准确地说:
-
在函数指针数组
pfArr中,add、sub等函数地址是以连续方式存储的。 -
而函数本身的代码可能分散在不同代码段(code section)中,地址不一定连续。
举个例子:
假设add函数代码在地址0x00001000,sub函数代码在0x00002000,mul在0x00003000。
那么在函数指针数组pfArr中:
pfArr[1] 指向 add函数地址 0x00001000
pfArr[2] 指向 sub函数地址 0x00002000
pfArr[3] 指向 mul函数地址 0x00003000
我们可以看到,pfArr[1]、pfArr[2]、pfArr[3]中的函数地址是以连续的方式存储在数组中的。
但是函数本身的代码地址0x00001000、0x00002000、0x00003000并不连续。
所以总结来说:
- 函数指针数组pfArr中函数地址是连续存储的
- 但函数代码本身不一定连续存储在内存中

二、回调函数是什么?
C语言中的回调函数是指在函数调用的过程中,被另外一个函数作为参数传递并调用的函数。
回调函数的主要特征如下:
-
回调函数必须事先定义。
-
回调函数的地址作为参数传递给另一个函数,这个函数称为主函数。
-
主函数在适当的时候,通过调用回调函数的地址来调用回调函数。
一个典型的回调函数使用场景例子:
// 回调函数定义
void callback_func(int value)
{
printf("value is %d\n", value);
}
// 主函数定义
void main_func(void (*callback)(int))
{
int num = 10;
// 调用回调函数
callback(num);
}
int main()
{
// 注册回调函数
main_func(callback_func);
return 0;
}
注:回调函数的特点是函数的调用关系由使用者在运行时决定,而不是在编译时就确定,这提供了更大的灵活性。
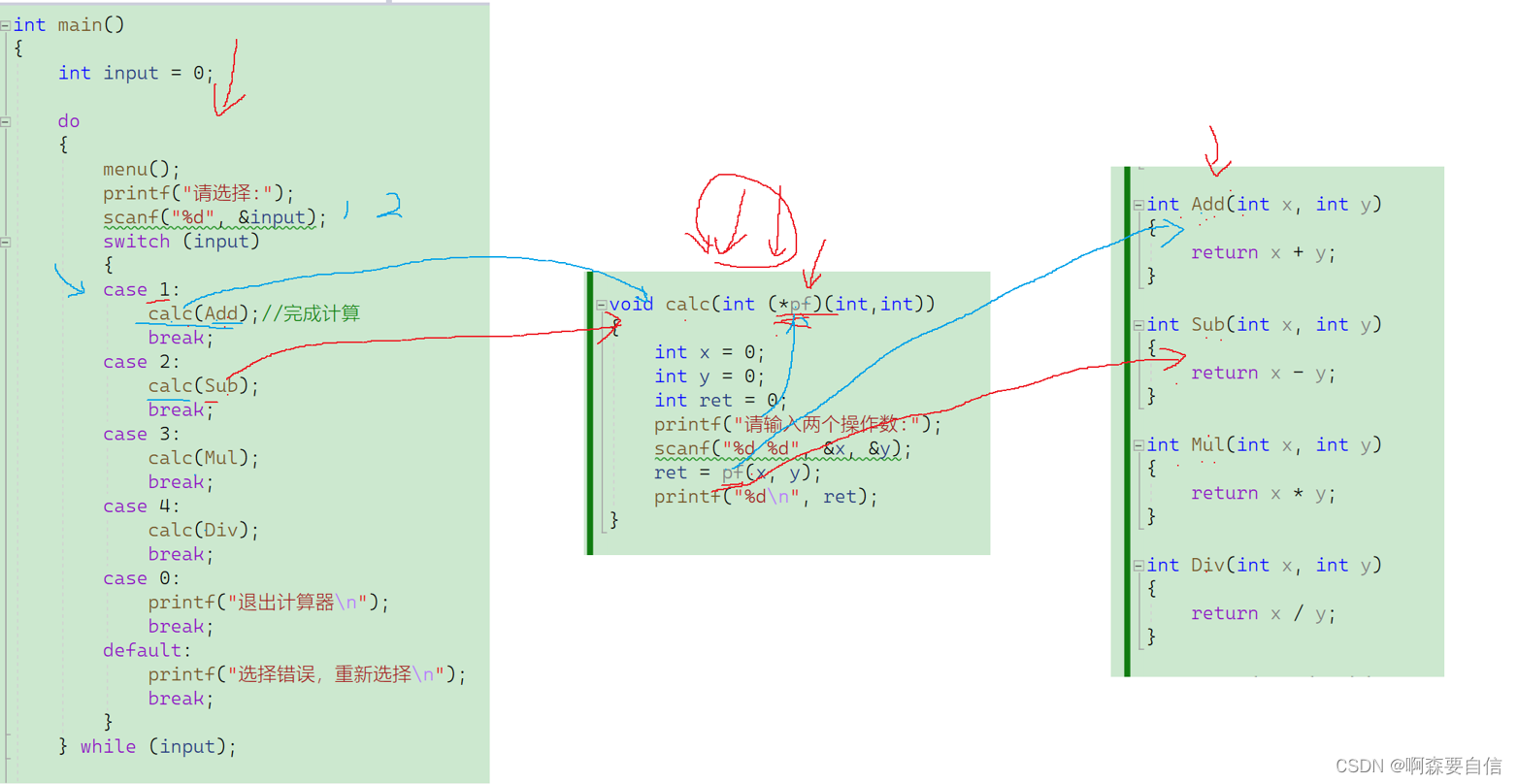
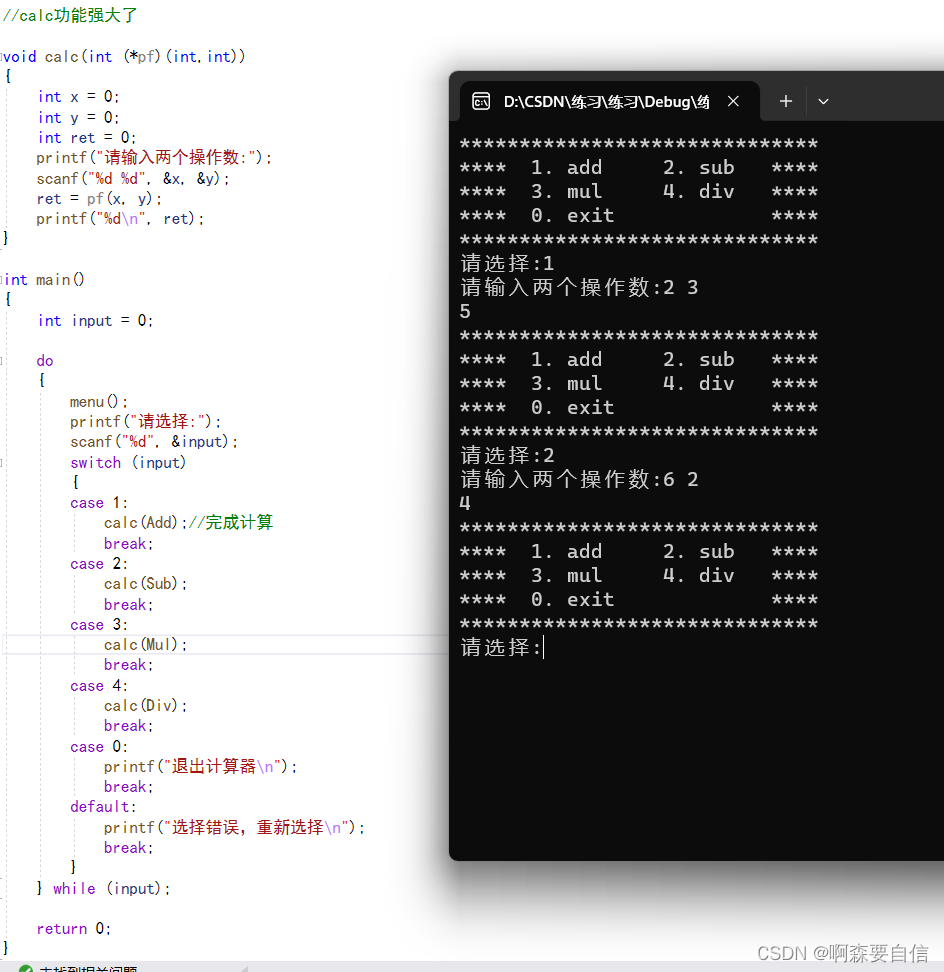
那可不可以使用回调函数实现计算器呢?
- 定义一个通用的计算函数
calc,它接收一个函数指针作为参数。- 在
main函数中,根据用户选择直接调用calc函数,并传入相应的运算函数。- 回调函数是
Add、Sub、Mul、Div
void menu()
{
printf("******************************\n");
printf("**** 1. add 2. sub ****\n");
printf("**** 3. mul 4. div ****\n");
printf("**** 0. exit ****\n");
printf("******************************\n");
}
int Add(int x, int y)
{
return x + y;
}
int Sub(int x, int y)
{
return x - y;
}
int Mul(int x, int y)
{
return x * y;
}
int Div(int x, int y)
{
return x / y;
}
//calc功能强大了
void calc(int (*pf)(int,int))
{
int x = 0;
int y = 0;
int ret = 0;
printf("请输入两个操作数:");
scanf("%d %d", &x, &y);
ret = pf(x, y);
printf("%d\n", ret);
}
int main()
{
int input = 0;
do
{
menu();
printf("请选择:");
scanf("%d", &input);
switch (input)
{
case 1:
calc(Add);//完成计算
break;
case 2:
calc(Sub);
break;
case 3:
calc(Mul);
break;
case 4:
calc(Div);
break;
case 0:
printf("退出计算器\n");
break;
default:
printf("选择错误,重新选择\n");
break;
}
} while (input);
return 0;
}
三、qsort函数细解
3.1 类比冒泡排序?
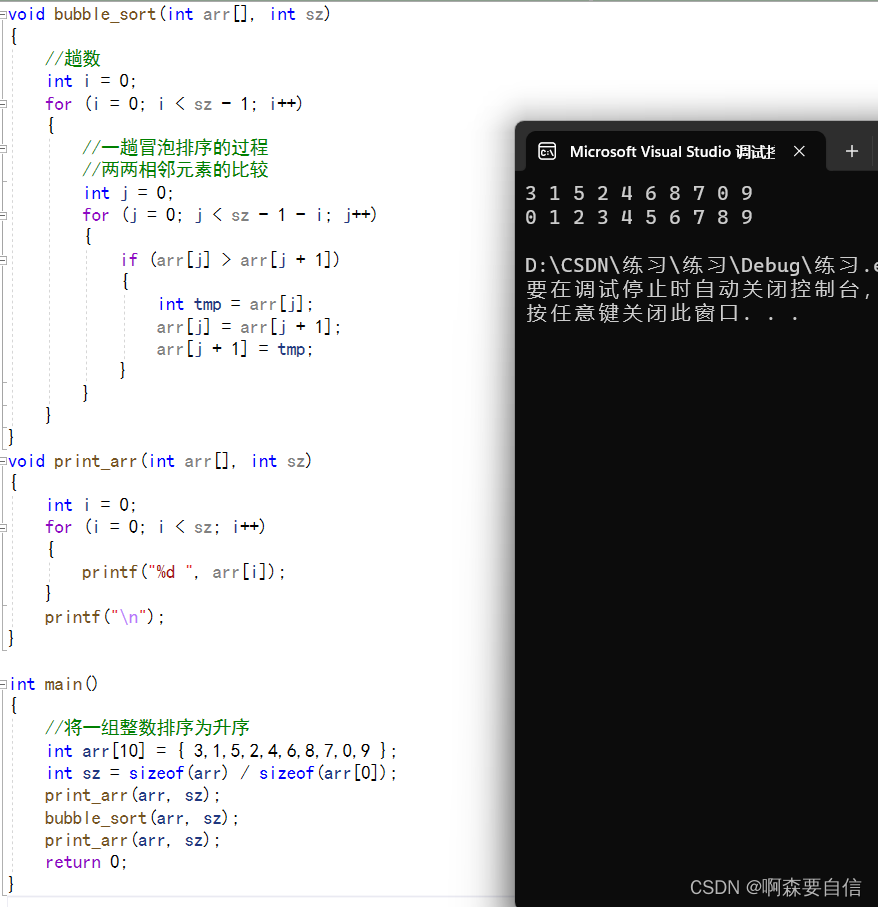
通过前面我们学过冒泡排序,qsort函数的排序让我们类比一下:
void bubble_sort(int arr[], int sz)
{
//趟数
int i = 0;
for (i = 0; i < sz - 1; i++)
{
//一趟冒泡排序的过程
//两两相邻元素的比较
int j = 0;
for (j = 0; j < sz - 1 - i; j++)
{
if (arr[j] > arr[j + 1])
{
int tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
}
}
}
}
void print_arr(int arr[], int sz)
{
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
}
int main()
{
//将一组整数排序为升序
int arr[10] = { 3,1,5,2,4,6,8,7,0,9 };
int sz = sizeof(arr) / sizeof(arr[0]);
print_arr(arr, sz);
bubble_sort(arr, sz);
print_arr(arr, sz);
return 0;
}

3.2 qosrt函数超详解
库函数的学习和查看⼯具很多,⽐如:
C/C++官⽅的链接:https://zh.cppreference.com/w/c/header
cplusplus.com:https://legacy.cplusplus.com/reference/clibrary/
qsort函数是C标准库中用于对数组进行快速排序的函数。(注:qsort函数底层使用的排序算法就是快速排序。)
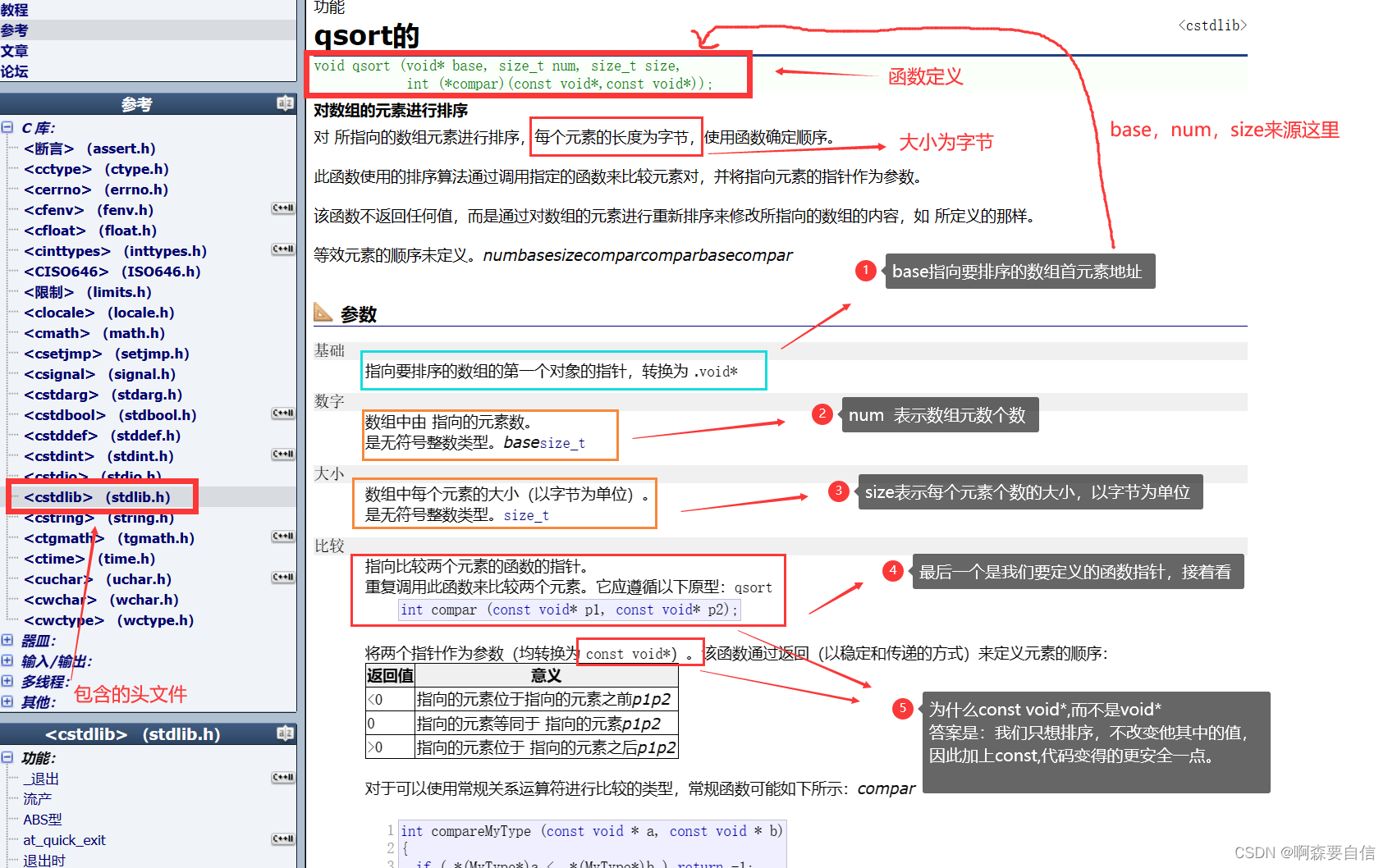
- 函数原型:
void qsort(
void* base,//base 指向了要排序的数组的第一个元素
size_t num, //base指向的数组中的元素个数(待排序的数组的元素的个数)
size_t size,//base指向的数组中元素的大小(单位是字节)
int (*compar)(const void*p1, const void*p2)//函数指针 - 指针指向的函数是用来比较数组中的2个元素的
);
.- [ ] 分析定义:
-
base指向要排序的数组首地址。 -
num表示数组元素个数。 -
size表示每个元素的大小,以字节为单位。 -
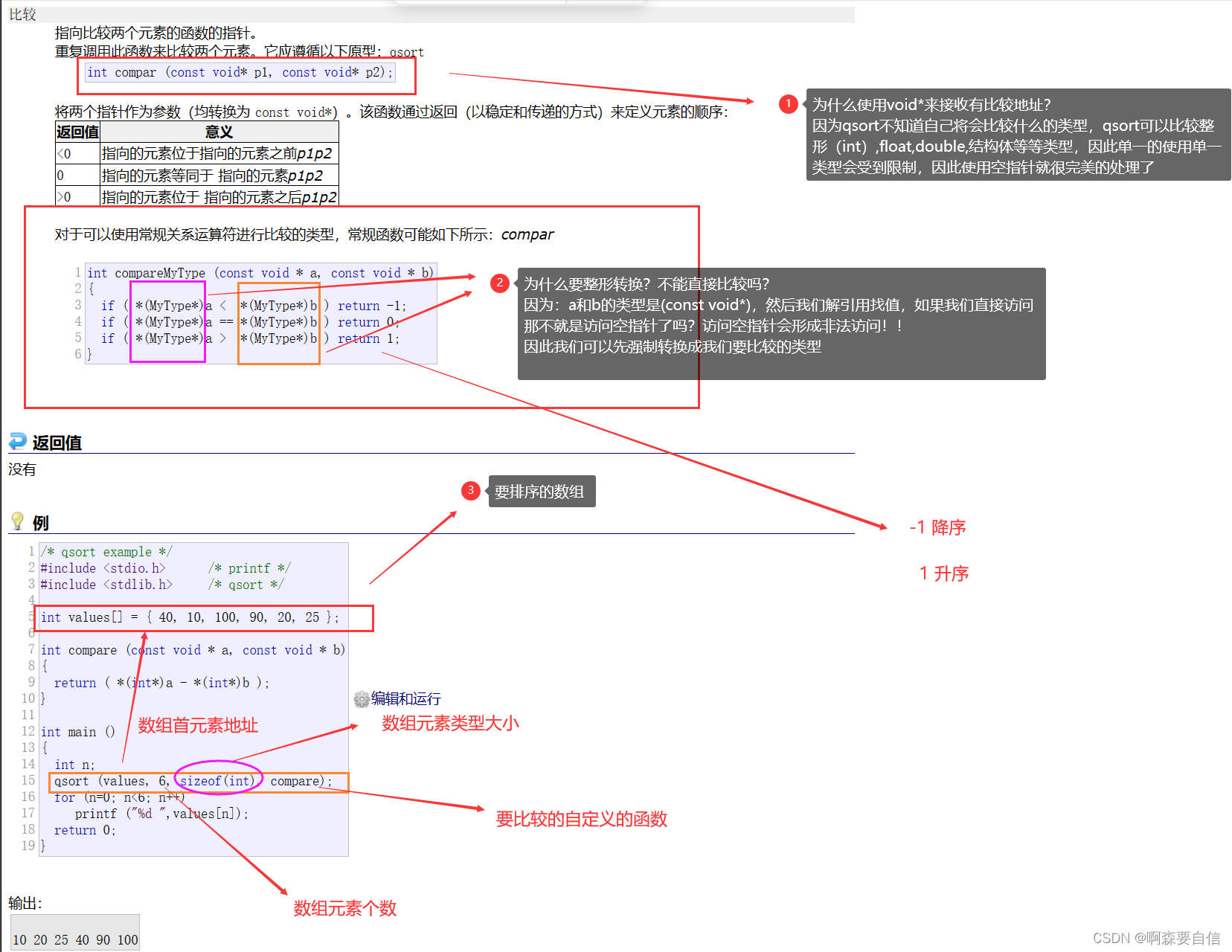
compar是比较函数,它接收两个void指针,返回值小于0表示第一个参数小于第二个参数,等于0表示相等,大于0表示第一个参数大于第二个参数。
.- [ ] 特点:
-
qsort使用快速排序算法,时间复杂度为O(nlogn)。 -
调用qsort时,需要提供一个比较函数
compar来判断两个元素的大小关系。 -
比较函数通过
void指针间接访问元素,避免与数据类型绑定,实现了最大程度的通用性。 -
qsort会在内部调用比较函数多次对数组进行排序,这就是回调机制的实现。
-
qsort是inplace排序,不需要额外的空间。
3.2.1qsort函数排序整型数据
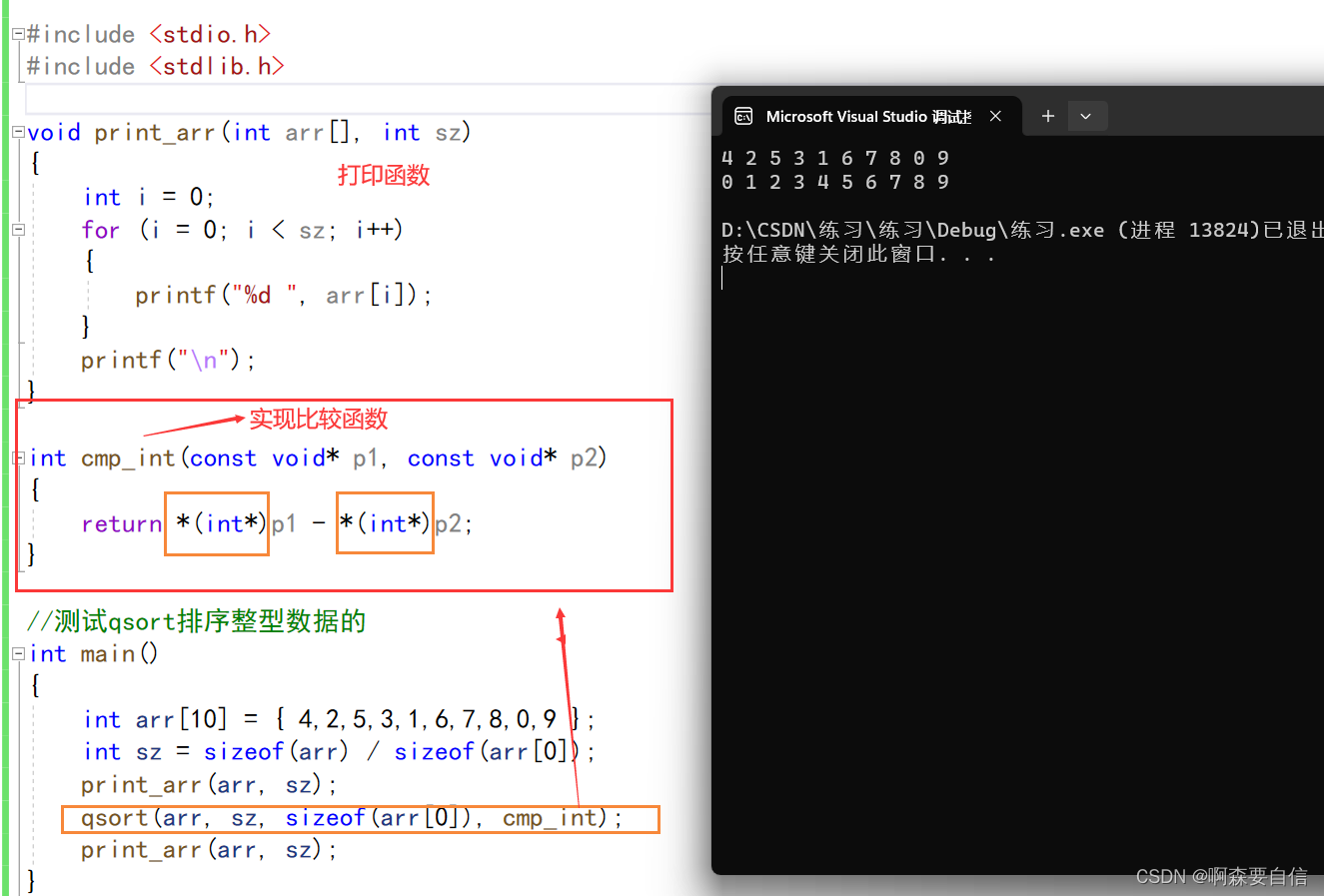
#include <stdio.h>
#include <stdlib.h>
void print_arr(int arr[], int sz)
{//打印函数
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
}
int cmp_int(const void* p1, const void* p2)
{//好比冒泡排序
return *(int*)p1 - *(int*)p2;
}
//测试qsort排序整型数据的
int main()
{
int arr[10] = { 4,2,5,3,1,6,7,8,0,9 };
int sz = sizeof(arr) / sizeof(arr[0]);
print_arr(arr, sz);//打印前
qsort(arr, sz, sizeof(arr[0]), cmp_int);
//arr->数组首元素地址
//sz->数组元素个数也可以这样写sz==sizeof(arr)/sizeof(arr[0])
//sizeof(arr[0])->数组元素大小,这里字节大小为4
//cmp_int比较函数
print_arr(arr, sz);//打印后
}
3.2.2 使⽤qsort排序结构数据
- 定义结构体类型
struct Stu
{
char name[20];//名字
int age;
};
- 定义比较函数
- 怎么比较2个结构体数据? - 不能直接使用 > < ==比较
- 可以按照名字比较
- 可以按照年龄比较
//按照年龄比较
int cmp_stu_by_age(const void* p1, const void* p2)
{
return ((struct Stu*)p2)->age - ((struct Stu*)p1)->age;
}
- 声明结构体数组和元素个数
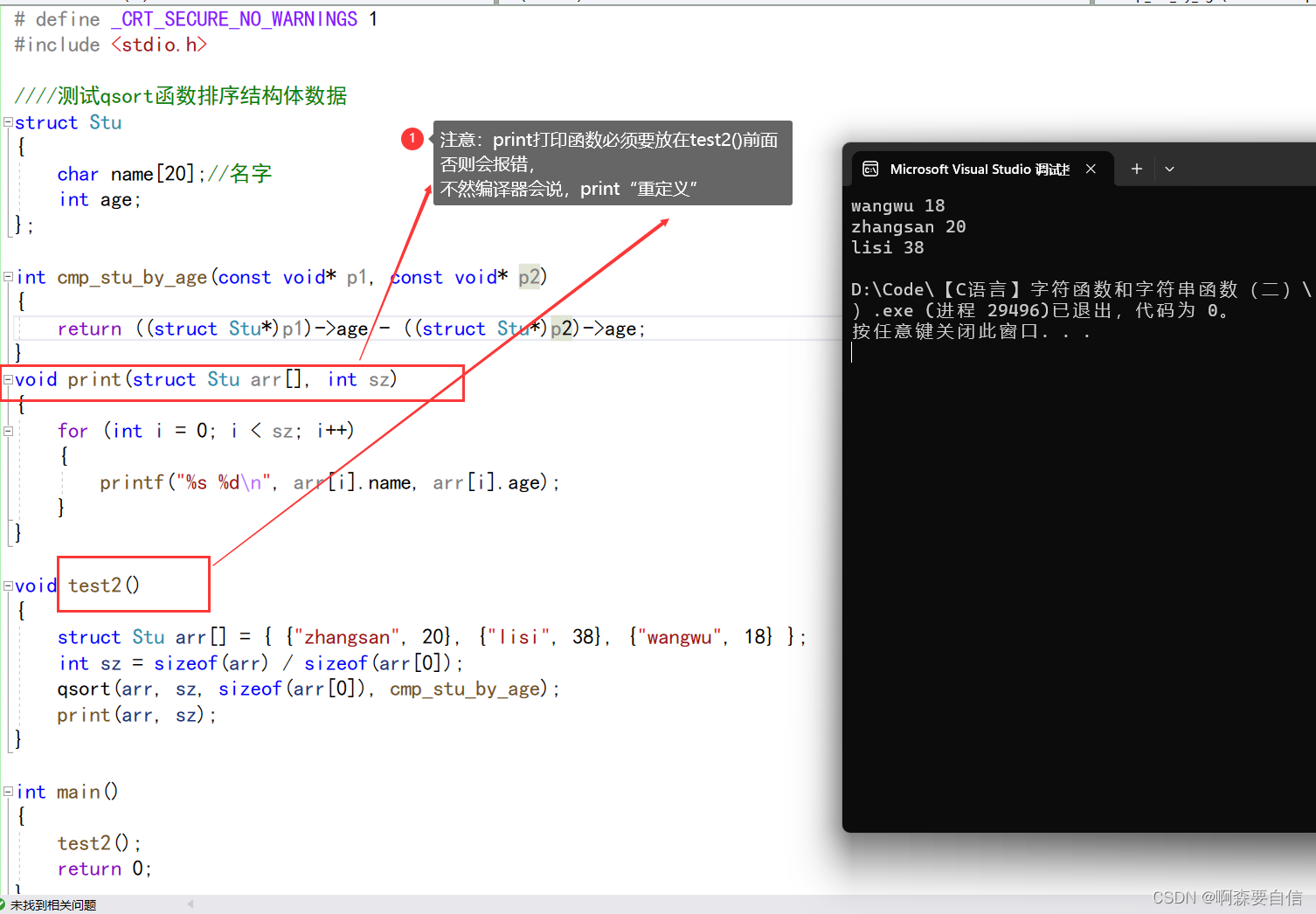
void test2()
{
struct Stu arr[] = { {"zhangsan", 20}, {"lisi", 38}, {"wangwu", 18} };
int sz = sizeof(arr) / sizeof(arr[0]);
qsort(arr, sz, sizeof(arr[0]), cmp_stu_by_age);
}
代码实现:
# define _CRT_SECURE_NO_WARNINGS 1
#include <stdio.h>
测试qsort函数排序结构体数据
struct Stu
{
char name[20];//名字
int age;
};
int cmp_stu_by_age(const void* p1, const void* p2)
{
return ((struct Stu*)p2)->age - ((struct Stu*)p1)->age;
}
void print(struct Stu arr[], int sz)
{
for (int i = 0; i < sz; i++)
{
printf("%s %d\n", arr[i].name, arr[i].age);
}
}
void test2()
{
struct Stu arr[] = { {"zhangsan", 20}, {"lisi", 38}, {"wangwu", 18} };
int sz = sizeof(arr) / sizeof(arr[0]);
qsort(arr, sz, sizeof(arr[0]), cmp_stu_by_age);
print(arr, sz);
}
// //两个字符串不能使用> < ==
// //而是使用库函数strcmp - string compare
int cmp_stu_by_name(const void* p1, const void* p2)
{
return strcmp(((struct Stu*)p1)->name, ((struct Stu*)p2)->name);
}
void test3()
{
struct Stu arr[] = { {"zhangsan", 20}, {"lisi", 38}, {"wangwu", 18} };
int sz = sizeof(arr) / sizeof(arr[0]);
qsort(arr, sz, sizeof(arr[0]), cmp_stu_by_name);
print(arr, sz);
}
int main()
{
test3();//姓名排序
//test2();//年龄排序
return 0;
}
运行
test2()//年龄排序
四、 qsort函数的模拟实现
4.1 模拟qsort整形数据
-
主函数:
- 定义
int测试数据 - 调用
bubble排序 - 打印结果验证
- 定义
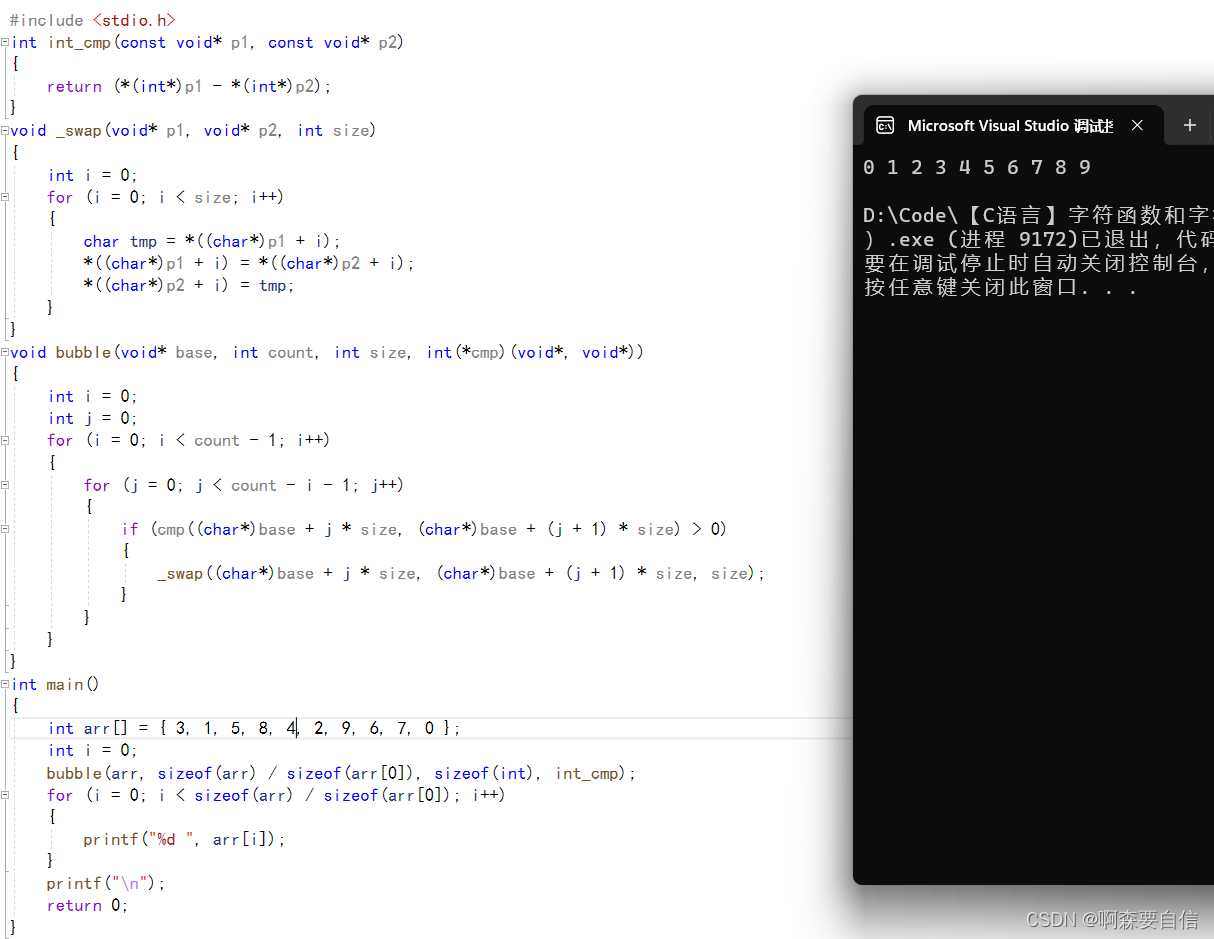
#include <stdio.h>
int main()
{
int arr[] = { 3, 1, 5, 8, 4, 2, 9, 6, 7, 0 };
int i = 0; //元素个数 //元素大小
bubble(arr, sizeof(arr) / sizeof(arr[0]), sizeof(int), int_cmp);
//数组首元素地址arr //比较函数
for (i = 0; i < sizeof(arr) / sizeof(arr[0]); i++)
{
printf("%d ", arr[i]);
}
printf("\n");
return 0;
}
-
bubble函数:
- 接收基地址、元素个数、元素大小、比较函数作为参数
- 实现冒泡排序核心算法
- 通过传递的比较函数
int_cmp来决定排序顺序 - 使用
_swap函数交换元素
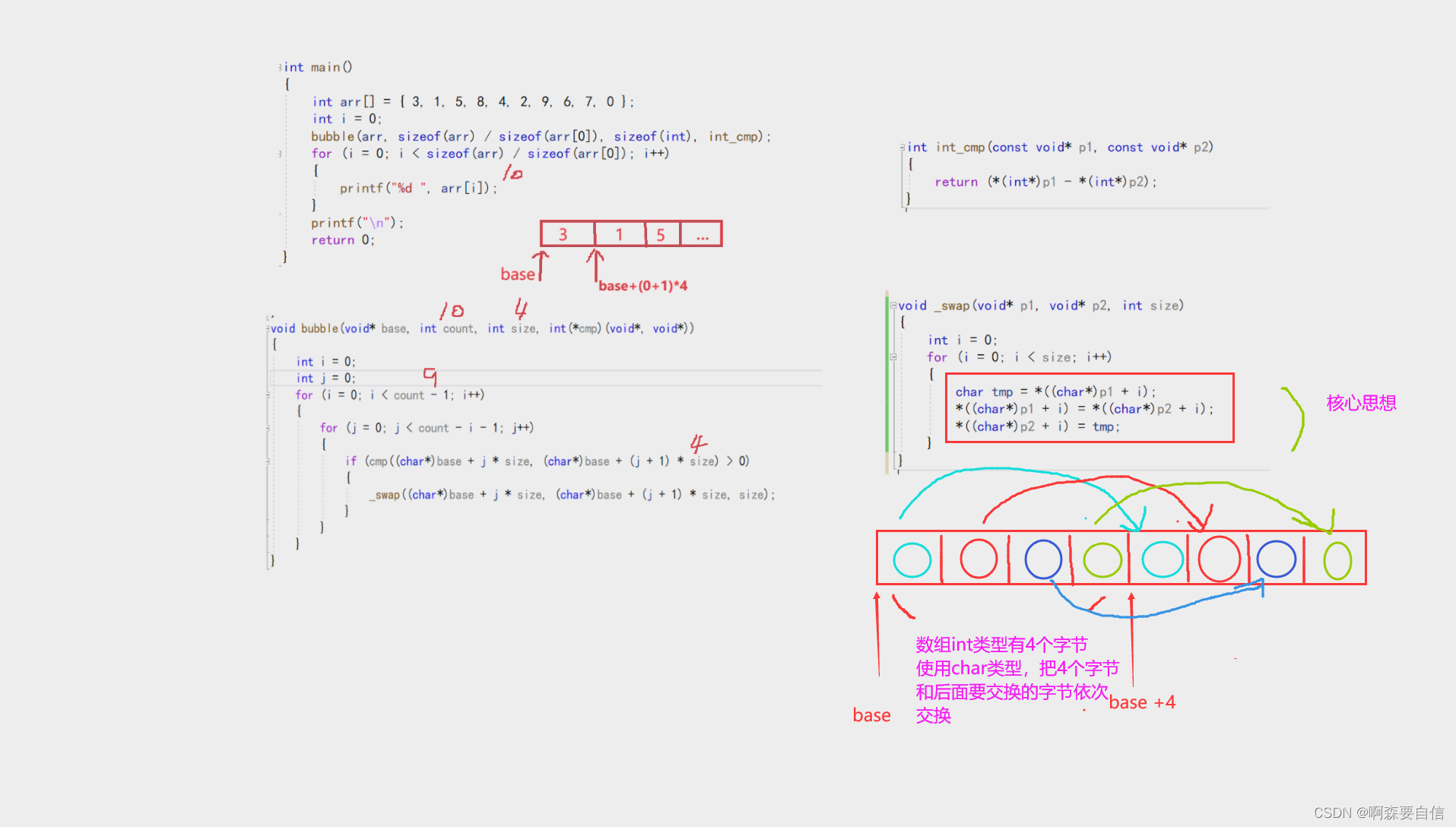
void bubble(void* base, int count, int size, int(*cmp)(void*, void*))
{
int i = 0;
int j = 0;
for (i = 0; i < count - 1; i++)
{
for (j = 0; j < count - i - 1; j++)
{
if (cmp((char*)base + j * size, (char*)base + (j + 1) * size) > 0)
{
_swap((char*)base + j * size, (char*)base + (j + 1) * size, size);
}
}
}
}
-
int_cmp函数:- 定义一个
int类型的数据比较函数 - 通过减法实现两个int*指针所指向的数据比较
- 返回值
大于0表示p1大于p2(升序),小于0表示p1小于p2(降序) - 实现了冒泡排序中的比较规则
- 定义一个
int int_cmp(const void* p1, const void* p2)
{
return (*(int*)p1 - *(int*)p2);
}
-
_swap函数:- 定义泛型数据交换函数
- 通过循环交换每个字节实现数据交换
- 使用
char*来交换,实现数据类型无关
void _swap(void* p1, void* p2, int size)
{
int i = 0;
for (i = 0; i < size; i++)
{
char tmp = *((char*)p1 + i);
*((char*)p1 + i) = *((char*)p2 + i);
*((char*)p2 + i) = tmp;
}
}
总结:
每个代码块实现的功能:
- 主函数: 测试驱动开发
bubble: 实现冒泡排序算法int_cmp: 提供比较规则_swap: 实现泛型数据交换
4.2 模拟qsort排序结构数据
各个代码块分析如下:
struct Stu定义结构体类型,包含姓名和年龄字段。
# define _CRT_SECURE_NO_WARNINGS 1
#include <stdio.h>
struct Stu
{
char name[20];
int age;
};
- Swap函数实现泛型数据交换,通过循环交换每个字节实现数据交换。
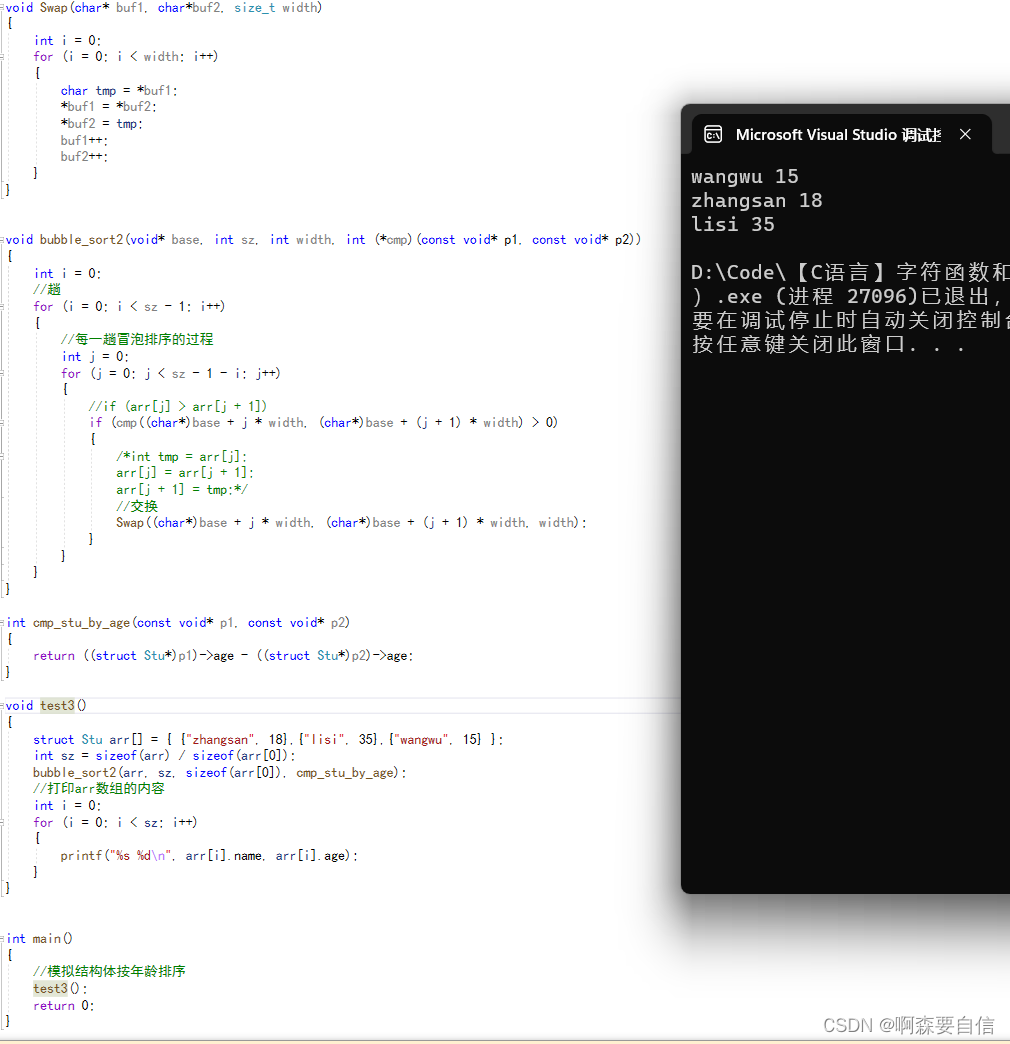
void Swap(char* buf1, char*buf2, size_t width)
{
int i = 0;
for (i = 0; i < width; i++)
{
char tmp = *buf1;
*buf1 = *buf2;
*buf2 = tmp;
buf1++;
buf2++;
}
}
- bubble_sort2函数实现冒泡排序算法,和普通冒泡排序区别在于使用void*作为参数,通过width实现对结构体进行排序。
void bubble_sort2(void* base, int sz, int width, int (*cmp)(const void* p1, const void* p2))
{
int i = 0;
//趟
for (i = 0; i < sz - 1; i++)
{
//每一趟冒泡排序的过程
int j = 0;
for (j = 0; j < sz - 1 - i; j++)
{
//if (arr[j] > arr[j + 1])
if (cmp((char*)base + j * width, (char*)base + (j + 1) * width) > 0)
{
/*int tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;*/
//交换
Swap((char*)base + j * width, (char*)base + (j + 1) * width, width);
}
}
}
}
cmp_stu_by_age函数实现结构体比较规则,根据年龄字段进行比较。
int cmp_stu_by_age(const void* p1, const void* p2)
{
return ((struct Stu*)p1)->age - ((struct Stu*)p2)->age;
}
- test4函数定义测试数据,调用
bubble_sort2进行排序,打印结果验证。
void test4()
{
struct Stu arr[] = { {"zhangsan", 18},{"lisi", 35},{"wangwu", 15} };
int sz = sizeof(arr) / sizeof(arr[0]);
bubble_sort2(arr, sz, sizeof(arr[0]), cmp_stu_by_age);
//打印arr数组的内容
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%s %d\n", arr[i].name, arr[i].age);
}
}
main函数调用test4函数进行测试。
int main()
{
//模拟结构体按年龄排序
test3();
return 0;
}
小总结:
struct Stu定义了需要排序的数据类型Swap函数实现数据交换bubble_sort2实现泛型冒泡排序cmp_stu_by_age定义了结构体比较规则test4函数测试驱动开发
总结
一、转移表
利用函数指针数组实现转移表是动态规划算法解决最优子结构问题时使用的一种技术。它记录了子问题的解,避免重复计算。
二、回调函数是什么?
回调函数是指在函数调用后,被当作参数传递给另一个函数的函数。调用方在需要时,会调用被调用方内部的这个函数。
三、qsort函数细解
3.1 类比冒泡排序?
qsort函数实现的也是冒泡排序算法。不同之处在于:
-
qsort是通用排序函数,可以对任意数据类型进行排序,而冒泡排序只能对数组进行排序; -
qsort通过回调函数来指定元素的比较方式,而冒泡排序直接比较元素值; -
qsort内部实现采用快速排序思想,而不是纯粹的冒泡排序。
3.2 qsort函数超详解
qsort函数原型:
void qsort(void *base, size_t num, size_t size, int (*compar)(const void*, const void*));
base:待排序数组首地址num:数组元素个数size:每个元素大小compar:比较函数回调,返回值小于0时交换元素
3.2.1 qsort排序整型数据
直接传入整型比较函数如int cmp(const void*, const void*)
3.2.2 使用qsort排序结构数据
定义结构体比较函数,通过强制类型转换比较结构体字段
四、qsort函数的模拟实现
4.1 模拟qsort整形排序
实现了一个简单快速排序函数,可以对整型数组排序。
4.2 模拟qsort结构体排序 同样实现快速排序,但使用结构体比较函数作为回调。
感谢你的收看,如果文章有错误,可以指出,我不胜感激,让我们一起学习交流,如果文章可以给你一个帮助,可以给博主点一个小小的赞😘