| Year | Name | Area | model | description | drawback |
|---|---|---|---|---|---|
| 2021 ICML | Clip (Contrastive Language-Image Pre-training) | contrastive learning、zero-shot learing、mutimodel |  | 用文本作为监督信号来训练可迁移的视觉模型 | CLIP’s zero-shot performance, although comparable to supervised ResNet50, is not yet SOTA, and the authors estimate that to achieve SOTA, CLIP would need to add 1000x more computation, which is unimaginable;CLIP’s zero-shot performs poorly on certain datasets, such as fine-grained classification, abstraction tasks, etc; CLIP performs robustly on natural distribution drift, but still suffers from out-of-domain generalisation, i.e., if the distribution of the test dataset differs significantly from the training set, CLIP will perform poorly; CLIP does not address the data inefficiency challenges of deep learning, and training CLIP requires a large amount of data; |
| 2021 ICLR | ViT (VisionTransformer) |  | 将Transformer应用到vision中:simple, efficient,scalable | 当拥有足够多的数据进行预训练的时候,ViT的表现就会超过CNN,突破transformer缺少归纳偏置的限制,可以在下游任务中获得较好的迁移效果 | |
| 2022 | DALL-E | 基于文本来生成模型 | |||
| 2021 ICCV | Swin Transformer |  | 使用滑窗和层级式的结构,解决transformer计算量大的问题;披着Transformer皮的CNN | ||
| 2021 | MAE(Masked Autoencoders) | self-supervised |  | CV版的bert | scalablel;very high-capacity models that generalize well |
| TransMed: Transformers Advance Multi-modal Medical Image Classification |  | ||||
| I3D | |||||
| 2021 | Pathway | ||||
| 2021 ICML | VILT | 视觉文本多模态Transformer | 性能不高 推理时间快 训练时间特别慢 | ||
| ALBef | align before fusion 为了清理noisy data 提出用一个momentum model生成pseudo target |
CV论文阅读大合集
news2026/5/6 1:04:37
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/1157901.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章

js实现容器之间交换
🔥博客主页: 破浪前进 🔖系列专栏: Vue、React、PHP ❤️感谢大家点赞👍收藏⭐评论✍️ JavaScript是一种非常流行和常用的编程语言,它在web开发中起着至关重要的作用,在实现网页动态交互、数据…
弹幕游戏制作,弹幕互动游戏开发,弹幕直播游戏
弹幕互动游戏是一种特殊类型的游戏,其中玩家可以在屏幕上发送实时评论或"弹幕",这些评论通常以文字形式出现在游戏画面上,同时影响游戏的进行。这种游戏类型通常与实况直播和在线社交互动相结合,为观众提供了参与游戏和…
Qt 使用Quazip解压缩、压缩文件
1.环境搭建
Quazip,是在zlib基础上进行了简单封装的开源库,适用于多种平台,利用它可以很方便将单个或多个文件打包为zip文件,且打包后的zip文件可以通过其它工具打开。
下载Quazip
QuaZIP download | SourceForge.net
解压后&…

阿里云99元服务器ECS经济型e实例是什么来头?
阿里云99元服务器ECS经济型e实例是什么来头?阿里云新品云服务器实例:ECS经济型e实例,价格优惠2核2G经济型e实例、3M带宽、40G ESSD entry系统盘,优惠价99元一年,老用户也可以买,第二年续费不涨价依旧是99元…
如何翻译shader graph到代码并添加额外的效果
使用shader graph翻译到代码可以使用连线工具快速制作效果并转换为代码,如果你对shader的“贴心/详细”报错,以及提示不完善等等问题感到恼火,这个方式或许可以一定程度上缓解以上问题。
本次使用的三个shader graph资源:https:…

速卖通卖家如何通过自己搭建测评补单系统,提高产品权重和排名?
速卖通卖家如何给店铺增加权重和排名?
在竞争激烈的速卖通平台上,为自己的店铺增加权重是吸引更多买家和提升销售的关键。店铺的权重决定着在搜索排名、推荐位和广告展示方面的优先级。今天珑哥为您介绍一些有效的策略,帮助您提升速卖通店铺…
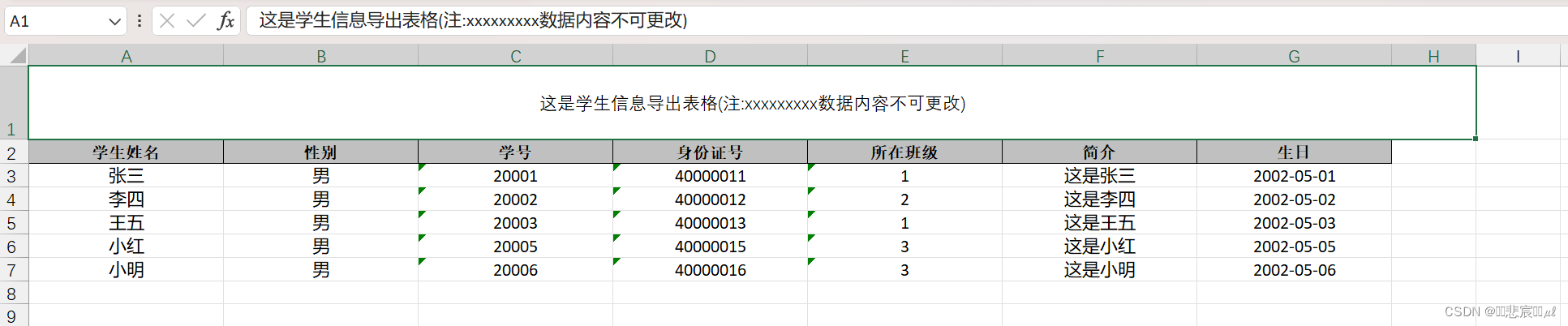
Springboot使用EasyExcel导入导出Excel文件
1,准备Excel文件和数据库表结果 2,导入代码
1,引入依赖 <!-- https://mvnrepository.com/artifact/com.alibaba/easyexcel --><dependency><groupId>com.alibaba</groupId><artifactId>easyexcel</artifac…
![[鹏城杯 2022]简单的php 取反的另一种无数字字母rce 通过请求头执行命令](https://img-blog.csdnimg.cn/0f5ff57f6ef844ebbc220508c539a75c.png)
[鹏城杯 2022]简单的php 取反的另一种无数字字母rce 通过请求头执行命令
鹏城杯2022部分web-CSDN博客
无字母webshell | Bypass-腾讯云开发者社区-腾讯云
这里记录一下
首先获取过滤if(strlen($code) > 80 or preg_match(/[A-Za-z0-9]|\|"||\ |,|\.|-|\||\/|\\|<|>|\$|\?|\^|&|\|/is,$code))
写个脚本看看还有什么没有被过滤 …

低成本语音芯片是如何写入语音到芯片里面otp和flash型
一、简介
低成本语音芯片是如何写入语音到芯片里面otp和flash型。低成本其实是一个相对的概念,比如:玩具类型的巨量产品,简单,它的低成本就是最低,能抠出来一分,就是一分。所以对芯片的要求就很高…

基于单片机设计的太阳能跟踪器
一、前言
随着对可再生能源的需求不断增长,太阳能作为一种清洁、可持续的能源形式,受到越来越多的关注和应用。太阳能光板通常固定在一个固定的角度上,这限制了它们对太阳光的接收效率。为了充分利用太阳能资源,提高太阳能光板的…

Oracle(10)Managing Undo Data
目录
一、基础知识 1、AUM :Init Parameters AUM:初始化参数
2、AUM:Other Parameters AUM:其他参数
3、AUM:Sizing an UNDO TS AUM:调整UNDOTS的大小
4、AUM :Undo Quota AUM:撤消配额
5、Get Undo Segment Info 获取撤消段信息
二、基础操作
1、AUM:UNDO Tablespace
…
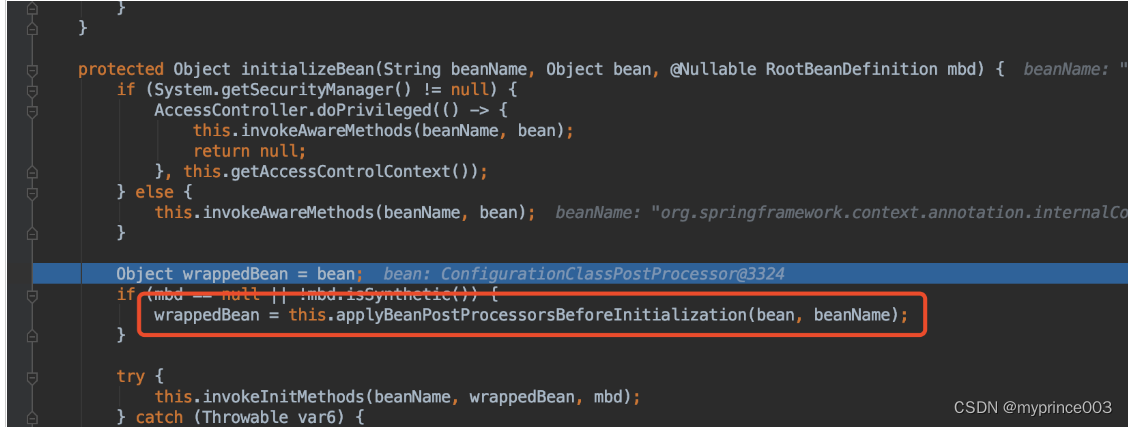
2、循环依赖详解(二)
bean的实例化过程源码解析
建议用IDEA的debug模式来观察Spring的IOC过程 进入到此类的构造方法中 查看setConfigLocations,就是将配置文件加载到configLocations里去 向下执行,查看refresh() this.prepareRefresh(): 此方法是准备工作,大家…
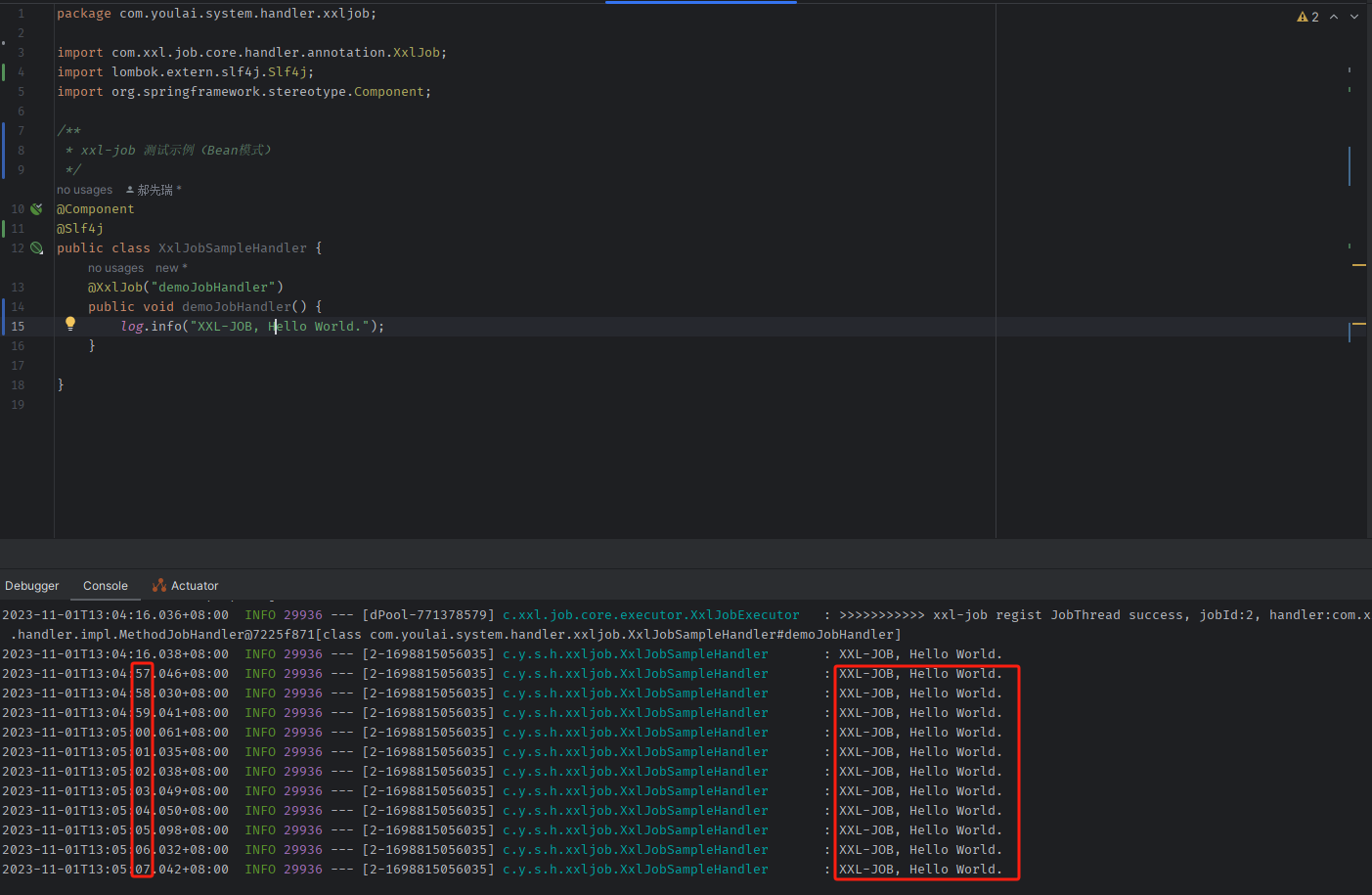
Spring Boot 3 整合 xxl-job 实现分布式定时任务调度,结合 Docker 容器化部署(图文指南)
目录 前言初始化数据库Docker 部署 xxl-job下载镜像创建容器并运行访问调度中心 SpringBoot 整合 xxl-jobpom.xmlapplication.ymlXxlJobConfig.java执行器注册查看 定时任务测试添加测试任务配置定时任务测试结果 结语附录xxl-job 官方文档xxl-job 源码测试项目源码 前言
xxl-…

防雷接地测试方法完整方案
防雷接地是保障电力系统、电子设备和建筑物安全的重要措施,防雷接地测试是检验防雷接地装置是否合格的必要手段。本文介绍了防雷接地测试的原理、方法和注意事项,以及如何编写防雷接地测试报告。
地凯科技防雷接地测试的原理
防雷接地测试的基本原理是…

人工智能快速发展时代下的“AI诈骗防范”
当前,AI技术的广泛应用为社会公众提供了个性化智能化的信息服务,也给网络诈骗带来可乘之机,如不法分子通过面部替换语音合成等方式制作虚假图像、音频、视频仿冒他人身份实施诈骗、侵害消费者合法权益。你认为AI诈骗到底应该如何防范…
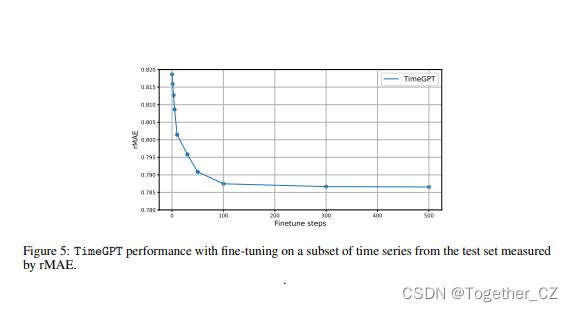
TimeGPT-1——第一个时间序列数据领域的大模型他来了
一直有一个问题:时间序列的基础模型能像自然语言处理那样存在吗?一个预先训练了大量时间序列数据的大型模型,是否有可能在未见过的数据上产生准确的预测?最近刚刚发表的一篇论文,Azul Garza和Max Mergenthaler-Canseco提出的TimeGPT-1,将ll…

国内某发动机制造工厂RFID智能制造应用解决方案
一、工厂布局和装备
国内某发动机制造工厂的装配车间布局合理,设备先进,在这个5万平方米的生产区域内,各个工位之间流程紧密,工厂采用了柔性设备,占比达到了67%,数控化率超过90%,自动化率达到了…

AD教程(四)排针类元件模型的创建
AD教程(四)排针类元件模型的创建 新建元件,输入排针型号作为元件命名 快捷键TC 快速创建元件 放置外框 放置管脚,排针管脚号在原理图上一般不显示,需要将管脚号隐藏,但一般不建议隐藏,如果将管…

如何在《阴阳师》游戏中使用Socks5搭建工具
题目:如何在《阴阳师》游戏中使用S5搭建工具S5一键搭建脚本进行游戏战队组建?
引言: 游戏加速和游戏战队组建已经成为《阴阳师》玩家们非常关心的话题。在这篇文章中,我们将向您展示如何在《阴阳师》游戏中使用S5搭建工具S5一键搭…

有奖快来抱走全新HUAWEI WATCH GT4
亲爱的openGauss用户,
为了给您提供更好的社区体验,现诚邀您参与openGauss社区满意度问卷调研。您的每一个宝贵建议都是我们进步的方向。
手机扫描二维码即可填写问卷,请根据您真实的体验情况填写问卷,问卷反馈越真实有效越有机…