LLaMA-Adapter源码解析
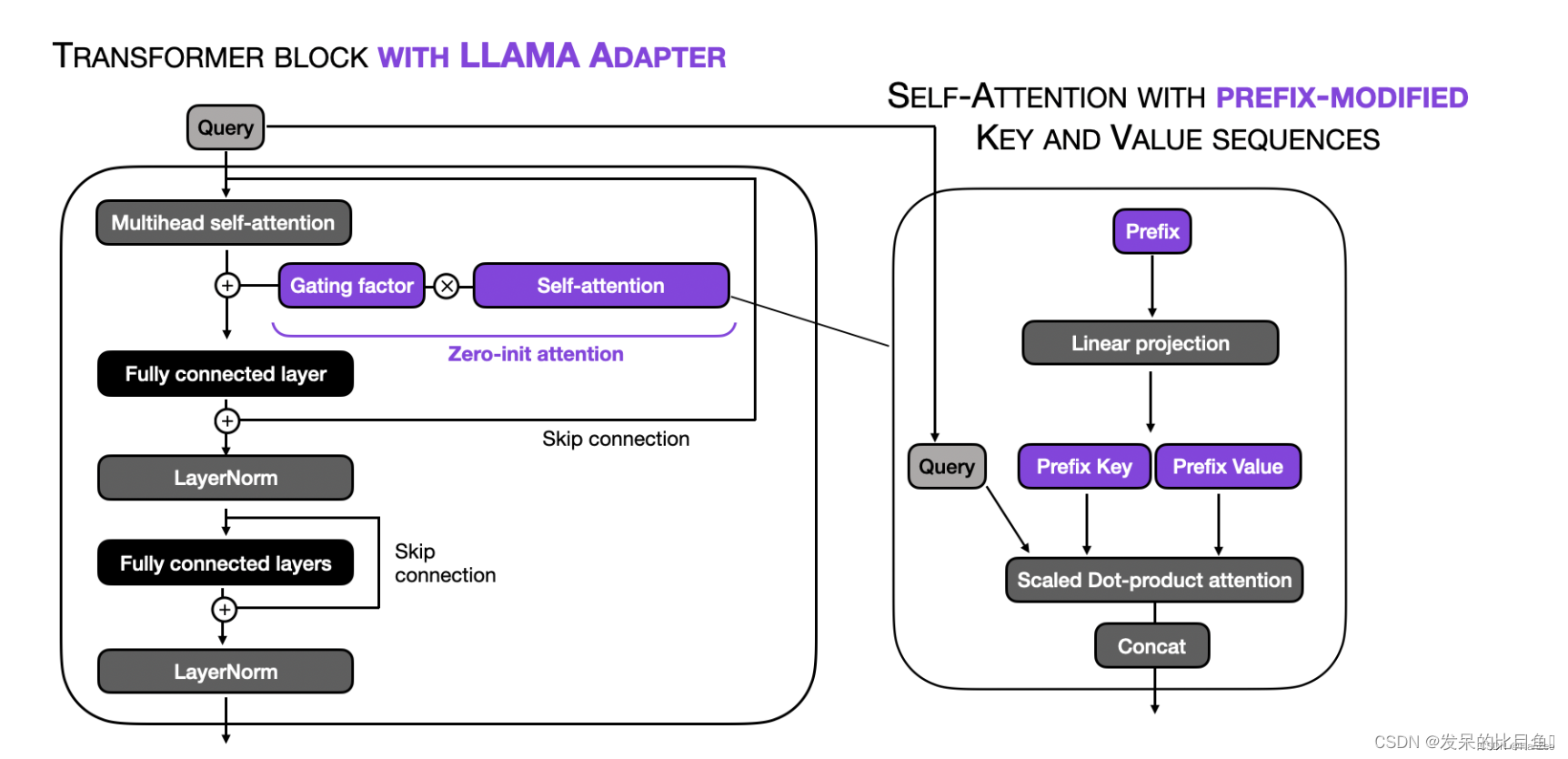
伪代码
def transformer_block_with_llama_adapter(x, gating_factor, soft_prompt):
residual =x
y= zero_init_attention(soft_prompt, x)
x= self_attention(x)
x = x+ gating_factor * y
x = LayerNorm(x+residual)
residual = x
x = FullyConnectedLayers(x)
x = AdapterLayers(x)
x = LayerNorm(x + residual)
return x
源码
class Attention(nn.Module):
def __init__(self, args: ModelArgs):
super().__init__()
self.n_local_heads = args.n_heads // fs_init.get_model_parallel_world_size()
self.head_dim = args.dim // args.n_heads
self.wq = ColumnParallelLinear(
args.dim,
args.n_heads * self.head_dim,
bias=False,
gather_output=False,
init_method=lambda x: x,
)
self.wk = ColumnParallelLinear(
args.dim,
args.n_heads * self.head_dim,
bias=False,
gather_output=False,
init_method=lambda x: x,
)
self.wv = ColumnParallelLinear(
args.dim,
args.n_heads * self.head_dim,
bias=False,
gather_output=False,
init_method=lambda x: x,
)
self.wo = RowParallelLinear(
args.n_heads * self.head_dim,
args.dim,
bias=False,
input_is_parallel=True,
init_method=lambda x: x,
)
self.cache_k = torch.zeros(
(args.max_batch_size, args.max_seq_len, self.n_local_heads, self.head_dim)
).cuda()
self.cache_v = torch.zeros(
(args.max_batch_size, args.max_seq_len, self.n_local_heads, self.head_dim)
).cuda()
self.gate = torch.nn.Parameter(torch.zeros(1))
def forward(self, x: torch.Tensor, start_pos: int, freqs_cis: torch.Tensor, mask: Optional[torch.Tensor], adapter=None):
bsz, seqlen, _ = x.shape
xq, xk, xv = self.wq(x), self.wk(x), self.wv(x)
xq = xq.view(bsz, seqlen, self.n_local_heads, self.head_dim)
xk = xk.view(bsz, seqlen, self.n_local_heads, self.head_dim)
xv = xv.view(bsz, seqlen, self.n_local_heads, self.head_dim)
xq, xk = apply_rotary_emb(xq, xk, freqs_cis=freqs_cis)
self.cache_k = self.cache_k.to(xq)
self.cache_v = self.cache_v.to(xq)
self.cache_k[:bsz, start_pos : start_pos + seqlen] = xk
self.cache_v[:bsz, start_pos : start_pos + seqlen] = xv
keys = self.cache_k[:bsz, : start_pos + seqlen]
values = self.cache_v[:bsz, : start_pos + seqlen]
if adapter is not None:
adapter_len = adapter.shape[1]
adapter_k = self.wk(adapter).view(1, adapter_len, self.n_local_heads, self.head_dim).repeat(bsz, 1, 1, 1)
adapter_v = self.wv(adapter).view(1, adapter_len, self.n_local_heads, self.head_dim).repeat(bsz, 1, 1, 1)
adapter_k = adapter_k.transpose(1, 2)
adapter_v = adapter_v.transpose(1, 2)
xq = xq.transpose(1, 2)
keys = keys.transpose(1, 2)
values = values.transpose(1, 2)
scores = torch.matmul(xq, keys.transpose(2, 3)) / math.sqrt(self.head_dim)
if mask is not None:
scores = scores + mask
scores = F.softmax(scores.float(), dim=-1).type_as(xq)
output = torch.matmul(scores, values)
if adapter is not None:
adapter_scores = torch.matmul(xq, adapter_k.transpose(2, 3)) / math.sqrt(self.head_dim)
adapter_scores = self.gate * F.softmax(adapter_scores.float(), dim=-1).type_as(xq)
output = output + torch.matmul(adapter_scores, adapter_v)
output = output.transpose(
1, 2
).contiguous().view(bsz, seqlen, -1)
return self.wo(output)