本文是关于MyBatis源码的第二篇,解读了MyBatis的核心执行SQL流程,对源码做了详细注释。内容较长,推荐电脑阅读。
点击上方“后端开发技术”,选择“设为星标” ,优质资源及时送达
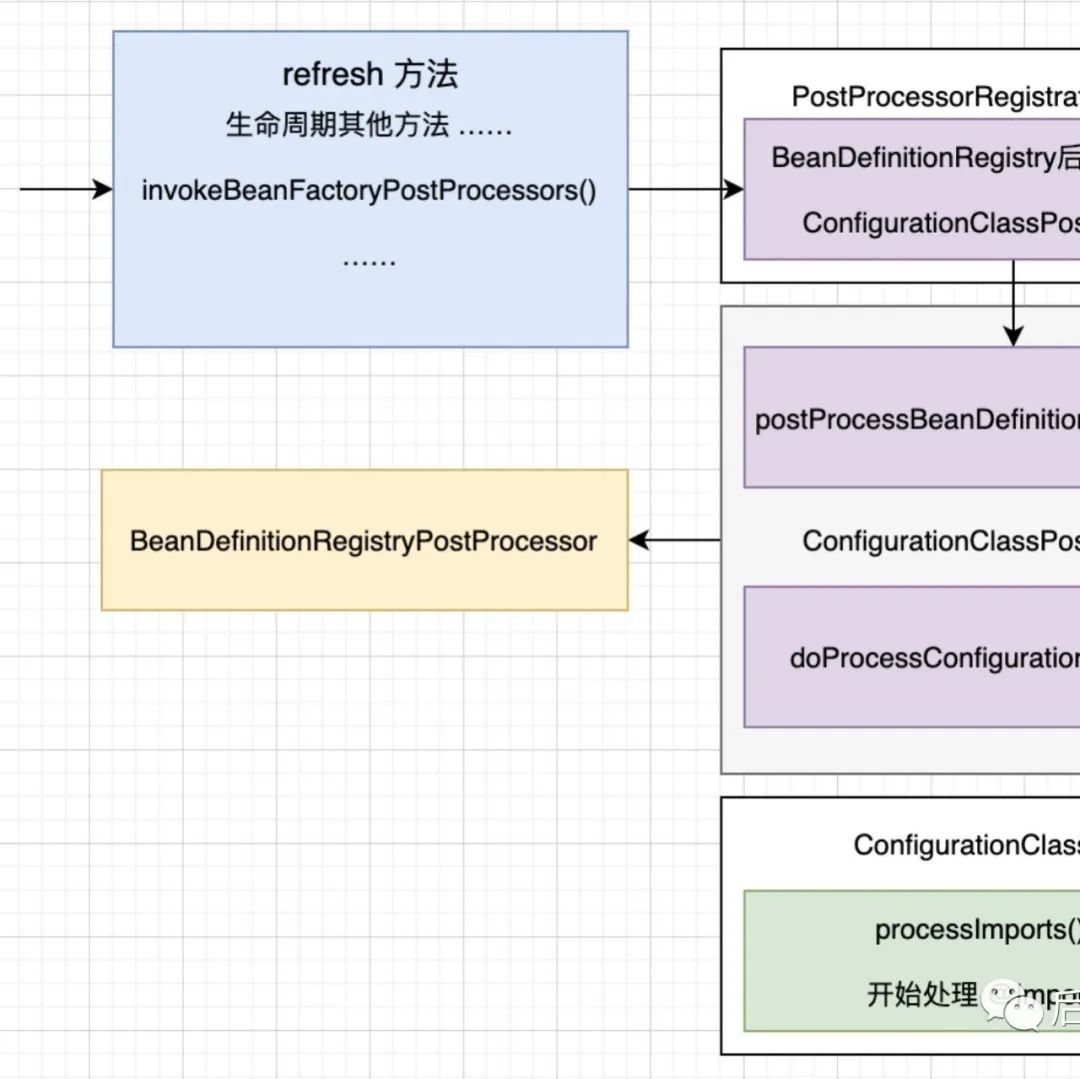
执行阶段流程
第一篇文章讲解了Mybatis启动阶段的流程,大家自行阅读。
这里将讲解剩余的执行阶段流程,涉及的主要内容如下:
根据方法签名,获得mapper对应的代理对象。
通过JDK动态代理找到对应的执行逻辑,获得数据库连接,然后执行SQL。
拿到执行结果,并且根据映射关系处理为Java对象。
相关测试用例的代码如下:
// 获取数据库的会话,创建出数据库连接的会话对象
SqlSession sqlSession = sqlSessionFactory.openSession();
// 获取要调用的接口类,创建出对应的mapper的动态代理对象
UserDao mapper = sqlSession.getMapper(UserDao.class);
// 调用方法开始执行SQL,并且将返回结果映射为Java对象
User userInfo = mapper.findUserInfo(1);从代码可以便看出,对于JDBC来说那些繁琐的SQL执行流程都变得如此简单。比如准备statement、设置参数、解析结果、根据不同类型设置到Java对象中等,这里只需要两行代码,MyBatis 的优势就在于此,解决了JDBC开发中的那些痛点。
一.获得代理对象
之前的流程介绍过,SqlSession 的实现类是 DefaultSqlSession,configuration 全局配置对象作为其成员变量,sqlSession 的 getMapper方法本质就是调用 configuration 的 getmapper方法,最后会去调用 MapperRegistry.getMapper()。

紧接着 MapperRegistry 中根据接口类型拿到 mapperProxyFactory ,这是在启动阶段根据xml配置的package中读取时put进knownMappers 里的(可以回顾第一篇文章)。
//DefaultSqlSession
public <T> T getMapper(Class<T> type) {
//最后会去调用MapperRegistry.getMapper
return configuration.getMapper(type, this);
}
//configuration
public <T> T getMapper(Class<T> type, SqlSession sqlSession) {
return mapperRegistry.getMapper(type, sqlSession);
}
//MapperRegistry
public <T> T getMapper(Class<T> type, SqlSession sqlSession) {
// 查找指定type对应MapperProxyFactory对象
final MapperProxyFactory<T> mapperProxyFactory = (MapperProxyFactory<T>) knownMappers.get(type);
……
// 创建实现了type接口的代理对象
return mapperProxyFactory.newInstance(sqlSession);
……
}拿到 mapperProxyFactory 后便可以调用其 newInstance()方法开始对 mapper 的代理对象进行实例化。在 newInstance() 方法中会首先实例化 MapperProxy ,MapperProxy继承了 InvocationHandler 接口。看到这里你应该懂了,MyBatis 正是运用了JDK代理的方式来实现代理对象。
mapperProxyFactory.newInstance的本质便是那段熟悉的代码,调用 Proxy 的 newProxyInstance 来创建动态代理对象,mapperInterface 就是需要被代理的接口。
在本例中,执行到这里就拿到了 UserDao 接口的动态代理实现类。
protected T newInstance(MapperProxy<T> mapperProxy) {
// 创建实现了mapperInterface接口的代理对象
return (T) Proxy.newProxyInstance(mapperInterface.getClassLoader(), new Class[] { mapperInterface }, mapperProxy);
}
public class MapperProxy<T> implements InvocationHandler, Serializable {
}
protected T newInstance(MapperProxy<T> mapperProxy) {
// 创建实现了mapperInterface接口的代理对象
return (T) Proxy.newProxyInstance(mapperInterface.getClassLoader(), new Class[] { mapperInterface }, mapperProxy);
}JDK动态代理的详细知识可以回顾这篇文章:
快速深入理解JDK动态代理原理
2022-05-19

二.执行代理方法
拿到mapper的对象后便可以开始执行SQL,这里以select语句为例:User userInfo = mapper.findUserInfo(1);
之前提到,所有的 mapper 接口实际的实现类是通过动态代理的方式实现的,并且是通过重要的实现类 MapperProxy。
MapperProxy 实现了 InvocationHandler 接口,在真正发生方法调用时通过 InvocationHandler.invoke 方法调用真正的实现逻辑。每一个具体实现方法都在 methodCache 这个 map 中保存,根据 method name从map中拿出来然后调用 invoke。
// MapperProxy
private final Map<Method, MapperMethodInvoker> methodCache;
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
// 如果目标方法继承自Object,则直接调用目标方法
if (Object.class.equals(method.getDeclaringClass())) {
return method.invoke(this, args);
} else {
// 根据被调用接口方法的method对象,从缓存中获取MapperMethodInvoker对象,如果没有则创建一个并放入缓存,然后调用invoke
return cachedInvoker(method).invoke(proxy, method, args, sqlSession);
}
}真正Mapper的实现类
JDK动态代理生成了自定义mapper接口真正的实现类,其实是可以生成并保存在文件系统中的。这里我贴了出来,方便大家理解MyBatis的实现逻辑。里面一些无关紧要的成员变量和方法已经删除,只留下最重要的实现部分。
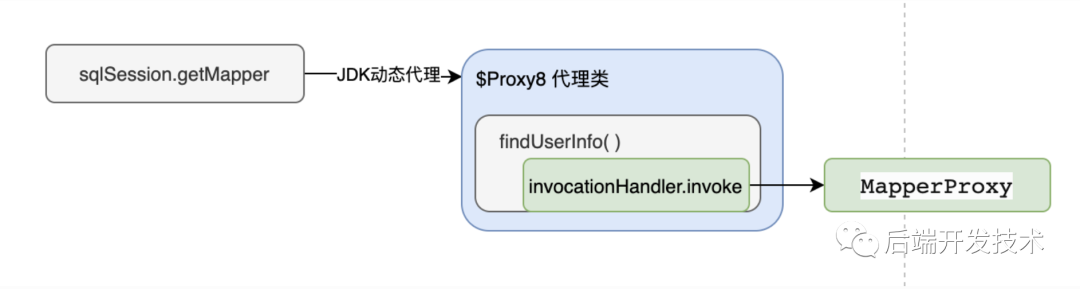
可以看到成员变量 m7就代表了方法 findUserInfo,在创建代理对象的时候需要传入实现 InvocationHandler接口类的实力对象,这里的 InvocationHandler var1 其实就是 MapperProxy,m7方法就是 UserDao接口中 findUserInfo方法的代理实现。可以看出其中真正调用的是 InvocationHandler 的invoke方法,也就是 MapperProxy.invoke()。
public final class $Proxy8 extends Proxy implements UserDao {
// findUserInfo
private static Method m7;
// 实际在父类Proxy中,为了方便理解加到这里。
protected InvocationHandler h;
public $Proxy8(InvocationHandler var1) throws {
super(var1);
}
// findUserInfo
public final User findUserInfo(Integer var1) throws {
try {
return (User)super.h.invoke(this, m7, new Object[]{var1});
} catch (RuntimeException | Error var3) {
throw var3;
} catch (Throwable var4) {
throw new UndeclaredThrowableException(var4);
}
}
static {
m7 = Class.forName("com.daley.dao.UserDao").getMethod("findUserInfo", Class.forName("java.lang.Integer"));
}
}三.查找方法对应 MapperMethodInvoker
MethodCache 用于缓存MapperMethod对象,其中 key 是mapper接口中方法对应的Method对象,value是MapperMethodInvoker ,里面包含对应的MapperMethod对象,MapperMethod对象会完成参数转换,以及SQL语句的执行功能,需要注意的是,MapperMethod中并不记录任何状态相关的信息,所以可以在多个代理对象之间共享。他们之间的关系如下图:
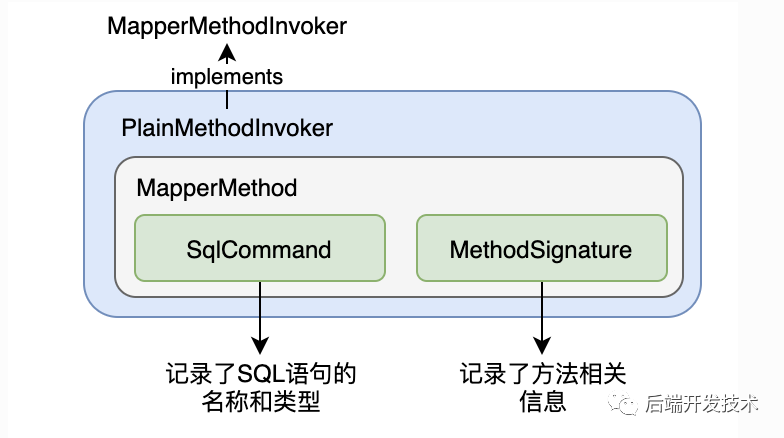
从缓存中查找 method,如果是接口默认方法直接执行,如果是普通方法,创建 PlainMethodInvoker 保存到 methodCache 中,key 为 Method 类型。
这样SQL和方法便绑定了起来,注意现在只是创建过程,绑定接口、方法、configuration三者的关系,还没有开始执行。
// 获取缓存中MapperMethodInvoker,如果没有则创建一个,而MapperMethodInvoker内部封装这一个MethodHandler
private MapperMethodInvoker cachedInvoker(Method method) throws Throwable {
……
return MapUtil.computeIfAbsent(methodCache, method, m -> {
if (m.isDefault()) {
// 如果调用接口的是默认方法
…… 省略try
if (privateLookupInMethod == null) {
return new DefaultMethodInvoker(getMethodHandleJava8(method));
} else {
return new DefaultMethodInvoker(getMethodHandleJava9(method));
}
…… 省略try
} else {
// 如果调用的普通方法,则创建一个PlainMethodInvoker并放入缓存,其中MapperMethod保存对应接口方法的SQL以及入参和出参的数据类型等信息
return new PlainMethodInvoker(new MapperMethod(mapperInterface, method, sqlSession.getConfiguration()));
}
});
…… 省略 catch
}
public class MapperMethod {
// 记录了SQL语句的名称和类型
private final SqlCommand command;
// mapper接口中对应方法的相关信息
private final MethodSignature method;
// mepperinferface 为当前被代理的 mapper 接口
// method 为当前执行的方法
// config 是当前全局配置对象
public MapperMethod(Class<?> mapperInterface, Method method, Configuration config) {
this.command = new SqlCommand(config, mapperInterface, method);
this.method = new MethodSignature(config, mapperInterface, method);
}
}绑定SQL和method关系
还记得上篇文章提到的 mappedStatements吗,里面保存了方法签名和SQL对应的信息。在这里创建 MapperMethod 的成员 SqlCommand 的时候,就会根据方法签名把这里面绑定的 mappedStatement 从这个Map结构中取出来。
public MapperMethod(Class<?> mapperInterface, Method method, Configuration config) {
this.command = new SqlCommand(config, mapperInterface, method);
this.method = new MethodSignature(config, mapperInterface, method);
}
public SqlCommand(Configuration configuration, Class<?> mapperInterface, Method method) {
final String methodName = method.getName();
final Class<?> declaringClass = method.getDeclaringClass();
MappedStatement ms = resolveMappedStatement(mapperInterface, methodName, declaringClass,
configuration);
……
}与此同时,关于方法的信息 MethodSignature 也会在这里做解析,比如返回的数据类型、@Param注解的参数名等等,所有信息都会保存在这个变量中,具体逻辑可以看 MethodSignature类的构造方法。
这样,SQL和方法的关系便关联了起来。
代码调试截图如下:
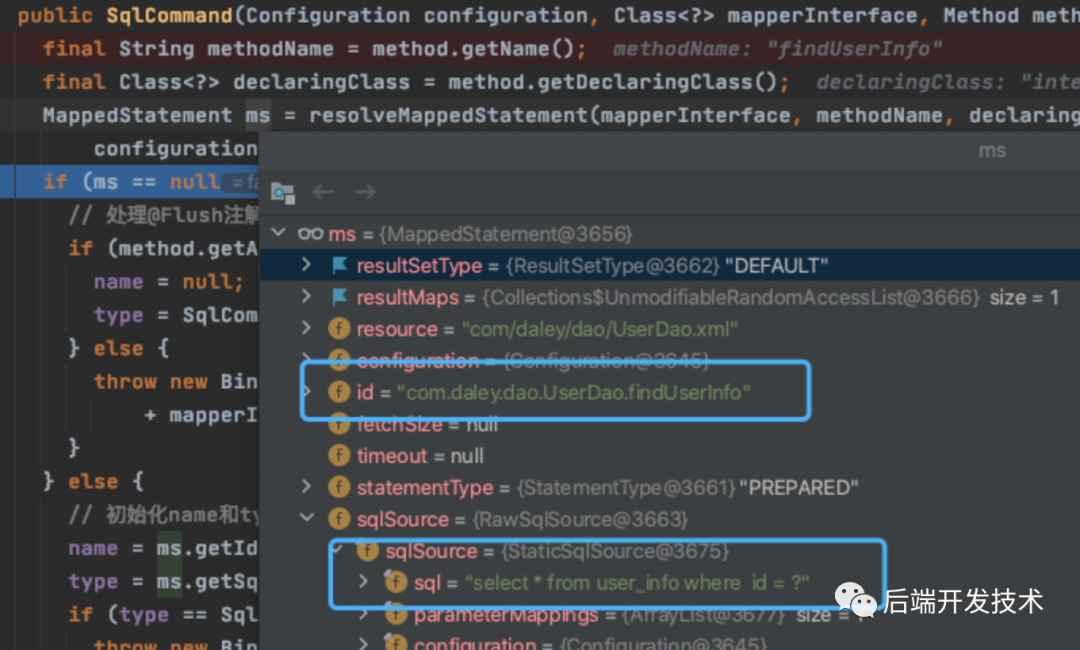
四.正式执行SQL
创建好 MapperMethod 之后会put到 methodCache 中,Method作为key,便于下次访问这个方法的时候直接取出来使用。
接着便可以调用Invoke方法,最终会调用 mapperMethod.execute(sqlSession, args)开始真正执行SQL。
execute 方法需要根据 SQL 类型和返回值类型确定执行哪一段逻辑,中间代码做了省略,道理一样大家自行调试,这里我们执行SELECT逻辑。
//MapperMethod
public Object execute(SqlSession sqlSession, Object[] args) {
Object result;
// 根据SQL语句的类型调用SqlSession对应的方法
switch (command.getType()) {
……
case UPDATE: {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.update(command.getName(), param));
break;
}
……
case SELECT:
// 处理返回值为void是ResultSet通过ResultHandler处理的方法
if (method.returnsVoid() && method.hasResultHandler()) {
// 如果有结果处理器
executeWithResultHandler(sqlSession, args);
result = null;
// 处理返回值为集合和数组的方法
……
} else {
// 处理返回值为单一对象的逻辑
// 执行这段逻辑
Object param = method.convertArgsToSqlCommandParam(args);
result = sqlSession.selectOne(command.getName(), param);
if (method.returnsOptional()
&& (result == null || !method.getReturnType().equals(result.getClass()))) {
result = Optional.ofNullable(result);
}
}
break;
……
return result;
}因为本方法是根据id查询的,只有一个查询结果,所以执行 DefaultSQLSession.selectOne方法。
最终会需要执行器方法执行查询操作,也就是 cachingExecutor.query()。
// DefaultSQLSession
public <T> T selectOne(String statement, Object parameter) {
// 从这里的返回值可以看出,尽量使用包装类,否则返回结果为空会报 NPE
List<T> list = this.selectList(statement, parameter);
if (list.size() == 1) {
return list.get(0);
}
……
}
public <E> List<E> selectList(String statement, Object parameter) {
return this.selectList(statement, parameter, RowBounds.DEFAULT);
}
//核心selectList
private <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds, ResultHandler handler) {
//根据方法签名找到对应的MappedStatement(SQL)
MappedStatement ms = configuration.getMappedStatement(statement);
//用执行器来查询结果,注意这里传入的ResultHandler是null
return executor.query(ms, wrapCollection(parameter), rowBounds, handler);
}执行器查询结果
在cachingExecutor的query方法中,会首先准备好boundSql,里面包含了SQL以及参数、返回等信息。然后会根据参数、sql等信息生产一个缓存 key,在本例中,这个cacheKey等于 1148877182:3356992236:com.daley.dao.UserDao.findUserInfo:0:2147483647:select * from user_info where id = ?:1:development。这就是二级缓存的key,其目的当然是为了在用同样参数执行的时候可以直接返回缓存中的结果,只有在开启缓存后才会生效。

//cachingExecutor
@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
// 获取BoundSql对象
BoundSql boundSql = ms.getBoundSql(parameterObject);
// 创建CacheKey对象
CacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql);
return query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}执行cachingExecutor 中的query方法,本质是执行BaseExecutor.query,这里使用了装饰者模式。这里的 delegate 就是 BaseExecutor 。
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
throws SQLException {
Cache cache = ms.getCache();
// 是否开启了二级缓存 如果没有使用缓存直接看最后一行
if (cache != null) {
……
List<E> list = (List<E>) tcm.getObject(cache, key);
if (list == null) {
// 二级缓存没有相应的结果对,调用封装的Executor对象的query方法
list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
// 将查询结果保存到TransactionalCache.entriesToAddOnCommit集合中
tcm.putObject(cache, key, list); // issue #578 and #116
}
return list;
}
}
// 没有启动二级缓存,直接调用底层Executor执行数据库查询操作
return delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}中间的链路很简单,这里做了省略,最终会追到 doQuery方法。看到这里的你应该感觉很熟悉了吧,就像JDBC的执行流程一样使用 PreparedStatement 开始执行查询。
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null;
try {
// 获取配置对象
Configuration configuration = ms.getConfiguration();
// 创建StatementHandler对象,实际返回的是RoutingStatementHandler对象
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
// 完成Statement的创建和初始化
stmt = prepareStatement(handler, ms.getStatementLog());
// 调用query方法执行sql语句,并通过ResultSetHandler完成结果集的映射
return handler.query(stmt, resultHandler);
} finally {
// 关闭Statement对象
closeStatement(stmt);
}
}
public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException {
PreparedStatement ps = (PreparedStatement) statement;
//执行SQL
ps.execute();
//处理返回结果
return resultSetHandler.handleResultSets(ps);
}五.处理返回结果
在 PreparedStatement 执行完 execute 方法后便拿到了MySQL服务器返回的结果,这就可以开始结果处理流程了。
具体过程代码中已经详细注释,简单来说就是根据ResultMap的类型找到对应的类型处理handler,然后根据返回结果类型调用 constructor.newInstance()创建结果对象,然后解析属性名,利用反射不同字段对应的value设置到Java对象中。
public List<Object> handleResultSets(Statement stmt) throws SQLException {
ErrorContext.instance().activity("handling results").object(mappedStatement.getId());
// 该集合用于保存映射结果得到的结果对象
final List<Object> multipleResults = new ArrayList<>();
int resultSetCount = 0;
// 获取第一个ResultSet对象
ResultSetWrapper rsw = getFirstResultSet(stmt);
// 获取MappedStatement.resultMaps集合
List<ResultMap> resultMaps = mappedStatement.getResultMaps();
int resultMapCount = resultMaps.size();
// 如果集合集不为空,则resultMaps集合不能为空,否则抛出异常
validateResultMapsCount(rsw, resultMapCount);
// 遍历resultMaps集合
while (rsw != null && resultMapCount > resultSetCount) {
// 获取该结果集对应的ResultMap对象
ResultMap resultMap = resultMaps.get(resultSetCount);
// 根据ResultMap中定义的映射规则对ResultSet进行映射,并将映射的结果对象添加到multipleResult集合中保存
handleResultSet(rsw, resultMap, multipleResults, null);
// 获取下一个结果集
rsw = getNextResultSet(stmt);
// 清空nestedResultObjects集合
cleanUpAfterHandlingResultSet();
// 递增resultSetCount
resultSetCount++;
}
// 获取MappedStatement.resultSets属性,该属性对多结果集的情况使用,该属性将列出语句执行后返回的结果集,并给每个结果集一个名称,名称是逗号分隔的,
String[] resultSets = mappedStatement.getResultSets();
if (resultSets != null) {
while (rsw != null && resultSetCount < resultSets.length) {
// 根据resultSet的名称,获取未处理的ResultMapping
ResultMapping parentMapping = nextResultMaps.get(resultSets[resultSetCount]);
if (parentMapping != null) {
String nestedResultMapId = parentMapping.getNestedResultMapId();
ResultMap resultMap = configuration.getResultMap(nestedResultMapId);
// 根据ResultMap对象映射结果集
handleResultSet(rsw, resultMap, null, parentMapping);
}
// 获取下一个结果集
rsw = getNextResultSet(stmt);
// 清空nestedResultObjects集合
cleanUpAfterHandlingResultSet();
// 递增resultSetCount
resultSetCount++;
}
}
return collapseSingleResultList(multipleResults);
}到这里,MyBatis的主要执行流程就全部讲解完了。
最后,欢迎大家提问和交流。
如果觉得对你有帮助,欢迎点赞、标🌟或分享!
大厂程序员常用的几款「高效工具」,已整理资源!
2022-12-20

MySQL主从复制太慢,怎么办?
2022-12-15
引入新模块都在用这个注解,它是如何生效的?|原创
2022-12-11