1 安装 Chrome
yum install https://dl.google.com/linux/direct/google-chrome-stable_current_x86_64.rpm
2 下载 chromedriver
# 进入下载目录
cd soft/crawler_tools
# 查看chrome 版本号
google-chrome --version
# 在chromedriver下载地址中找到对应版本,下载对应版本chromedriver
wget url
# 如:
wget https://edgedl.me.gvt1.com/edgedl/chrome/chrome-for-testing/118.0.5993.70/linux64/chromedriver-linux64.zip
# 解压
unzip chromedriver-linux64.zip
# 赋权
cd chromedriver-linux64
chmod +x chromedriver
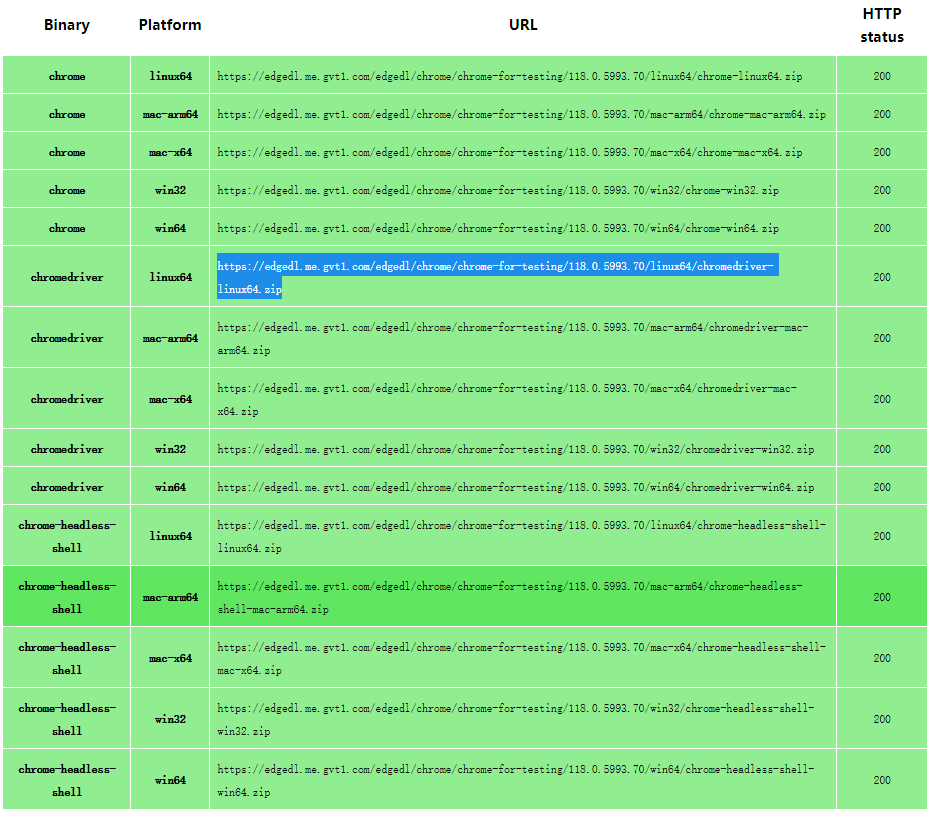
chromedriver 下载地址:
https://googlechromelabs.github.io/chrome-for-testing/ (推荐,包含最新稳定版)
https://chromedriver.storage.googleapis.com/index.html?
http://npm.taobao.org/mirrors/chromedriver/
https://registry.npmmirror.com/-/binary/chromedriver/
查看版本:

chromedriver对应下载地址
3 使用 selenium webdriver
现在就可以使用 selenium 的 webdriver 爬取内容了
from selenium import webdriver
class SeleniumWebdriver:
def __init__(self):
self.chrome_options = webdriver.ChromeOptions()
self.chrome_options.add_argument('--headless')
self.chrome_options.add_argument(
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.83 Safari/537.36')
# chromedriver 地址
self._CHROME_DRIVER_LINUX = '/soft/crawler_tools/chromedriver'
# 浏览器模拟的方式获取含有专辑 mid 信息的页面
def get_pagesource_by_chrome(self, url):
browser = webdriver.Chrome(executable_path=self._CHROME_DRIVER_LINUX, options=self.chrome_options)
browser.get(url)
time.sleep(2)
res = browser.page_source
browser.close()
return res
if __name__ == "__main__":
sw= SeleniumWebdriver()
url = "www.baidu.com"
content = sw.get_pagesource_by_chrome(url)
print(content)
参考:
傻瓜式linux下安装Chrome和chromedriver
chromedriver高于114版本的版本如115、116、117、118等,如何下载对应版本