1 字符
- Char类型的值代表单个字符
c='a'
#'a': ASCII/Unicode U+0061 (category Ll: Letter, lowercase)
typeof(c)
#Char- 将 Char 转换为其对应的整数值,即 Unicode 代码
c=Int(c)
c
#97
typeof(c)
#Int64- 将一个整数值(Unicaode)转回 Char
Char(97)
#'a': ASCII/Unicode U+0061 (category Ll: Letter, lowercase)- 字符也可以进行
'A' < 'a'
#true
'A' +1
#'B': ASCII/Unicode U+0042 (category Lu: Letter, uppercase)2 字符串
2.1 创建
由双引号或三重双引号分隔
- 双引号 (
") 通常用于定义单行字符串
str="Hello world"
str
# "Hello world"
- 三重双引号 (
""") 可以用于定义多行字符串。- 在这种情况下,可以在一个字符串中包含多行文本,而无需使用明确的换行字符或连接多个单行字符串。
s = """This is a multiline
string in Julia."""
s
#"This is a multiline\nstring in Julia."- 当需要在字符串中包含双引号等转义字符时,使用三重双引号可以更加方便,因为你不需要转义内部的双引号
s = """He said, "Hello, Julia!" without any issues."""
s
#"He said, \"Hello, Julia!\" without any issues."- 在字符串中,如果一行内容太长,可以在换行之前加上反斜杠 (
\) 来将其分割。- 使用反斜杠后,实际的字符串内容不会包含换行符
- 这样可以使代码更易读,同时不改变字符串的实际内容。
str="Hello \
world"
str
#"Hello world"2.2 索引
可以使用数字(索引从1开始),也可以是begin和end(他们俩可以视作普通值,可以直接在上面进行计算)
str="Hello world"
str
#"Hello world"
str[begin]
#'H': ASCII/Unicode U+0048 (category Lu: Letter, uppercase)
str[1]
#'H': ASCII/Unicode U+0048 (category Lu: Letter, uppercase)
str[end]
#'d': ASCII/Unicode U+0064 (category Ll: Letter, lowercase)
str[begin*3]
#'l': ASCII/Unicode U+006C (category Ll: Letter, lowercase)- 使用小于 begin (1) 或大于 end 的索引会引发错误:
str[begin-1]
'''
BoundsError: attempt to access 11-codeunit String at index [0]
Stacktrace:
[1] checkbounds
@ .\strings\basic.jl:216 [inlined]
[2] codeunit
@ .\strings\string.jl:117 [inlined]
[3] getindex(s::String, i::Int64)
@ Base .\strings\string.jl:238
[4] top-level scope
@ In[48]:1
'''
str[end+1]
'''
BoundsError: attempt to access 11-codeunit String at index [12]
Stacktrace:
[1] checkbounds
@ .\strings\basic.jl:216 [inlined]
[2] codeunit
@ .\strings\string.jl:117 [inlined]
[3] getindex(s::String, i::Int64)
@ Base .\strings\string.jl:238
[4] top-level scope
@ In[49]:1
'''- 可以使用范围索引来提取字符串(左闭右闭)
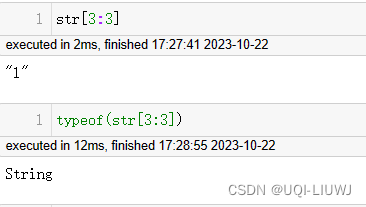
str[3:4]
#"ll"- 表达式 str[k] 和 str[k:k] 不会给出相同的结果:
- 前者是一个
Char类型的单个字符,而后者是一个恰好只包含一个字符的字符串
- 前者是一个

2.3 拼接
- 使用string拼接
greet = "Hello"
whom = "world"
string(greet, ", ", whom, ".\n")
#"Hello, world.\n"- 也使用*用于字符串级联
greet = "Hello"
whom = "world"
greet * ", " * whom * ".\n"
#"Hello, world.\n"- 使用$插值进行拼接
greet = "Hello"
whom = "world"
"$greet, $whom.\n"2.4 其他方法
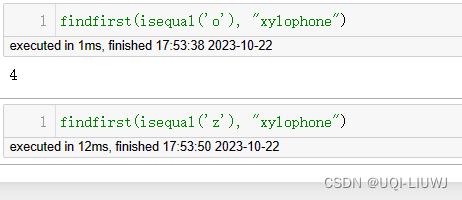
findfirst | 搜索特定字符第一次出现的索引
|
findlast | 搜索特定字符最后一次出现的索引
|
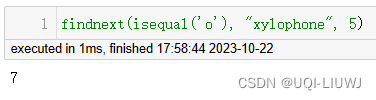
findnext | 搜索特定偏移处之后,某字符出现的索引
|
findprev | 搜索特定偏移处之前,某字符出现的索引
|
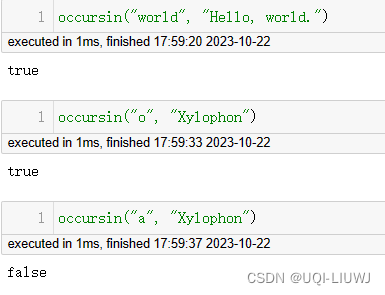
occursin | 检查在字符串中某子字符串可否找到
|
repeat | 字符串重复多次
|
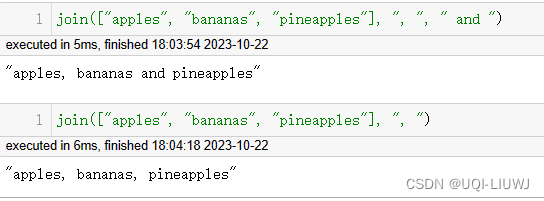
join | 拼接 像第一种情况:每个字符串之间拼接的是对应的字符(串) 第二种情况,join后面只有一个参数,那么所有字符串都用这个参数拼接
|
length | 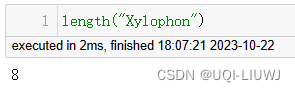 |










![[Docker]一.Docker 简介与安装](https://img-blog.csdnimg.cn/b240c91596204ffa974936dc021e0129.png)