在初步接触了深度学习以后,我们把目光投向对于一些图像的识别。
其实在d2l这本书中,我们接触过用深度神经网络去识别一个图像,并且对其进行一个分类操作,核心原理是将图像展开成一维tensor,然后作为特征进行检测。
其实理论是这个思路和方式都没有问题,怀就坏在这个图片的大小可能是不固定的,如果是288×288×3的图片,展开成张量然后拿去训练,那么特征值的数目就会很恐怖,对构建神经网络产生了一个巨大的开销。
为了避免这种开销,有效地缩小构建网络,训练模型的开销(也就是少点参数),我们使用卷积神经网络
1.什么是卷积层
卷积层的这个卷积,在计算机图形学中的应用同样很广泛,而且概念上也是一样的.
其实严格来说,我们这个操作并不能称之为卷积操作,因为数学论文中的卷积操作需要额外的一个步骤就是倒转卷积核,在这里我们仅仅是对固定的层数和区域做运算而已.
在大一的时候,我们接触过滑动窗口算法,用来进行平滑的操作,,或者就像是我们在ps中进行图像处理的时候,所用到的污点修复工具, 也是一种卷积.
这其实就是卷积神经网络中的一部分,只不过严格来说这个操作被称之为pooling(池化)
首先我们要介绍一下卷积核 / 过滤器 / convolution kernel / filtering
就是一个小型矩阵,深度和被卷积对象匹配(为什么这里说被卷积对象而不是输入,这个和我们后面的一个叫做分离卷积的东西有关,当然这个是后话了)
过滤器是怎么样工作的,或者说卷积的数学原理是什么,差不多就这样,那个小的过滤矩阵被称之为核
然后类似滑动窗口的操作,只不过这次窗口被严格限制在了原本张量范围内,窗口的每个计算,对应着目标中一个数字的输出
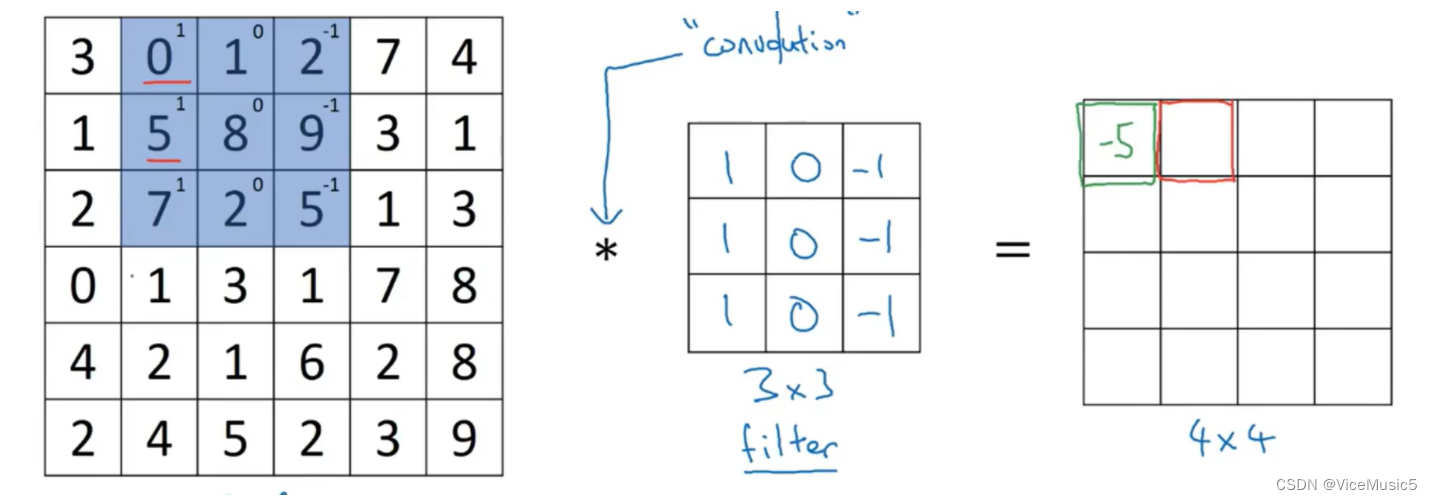
比如这张图上,这个核起到的作用就是:垂直边缘检测,可以看一下效果
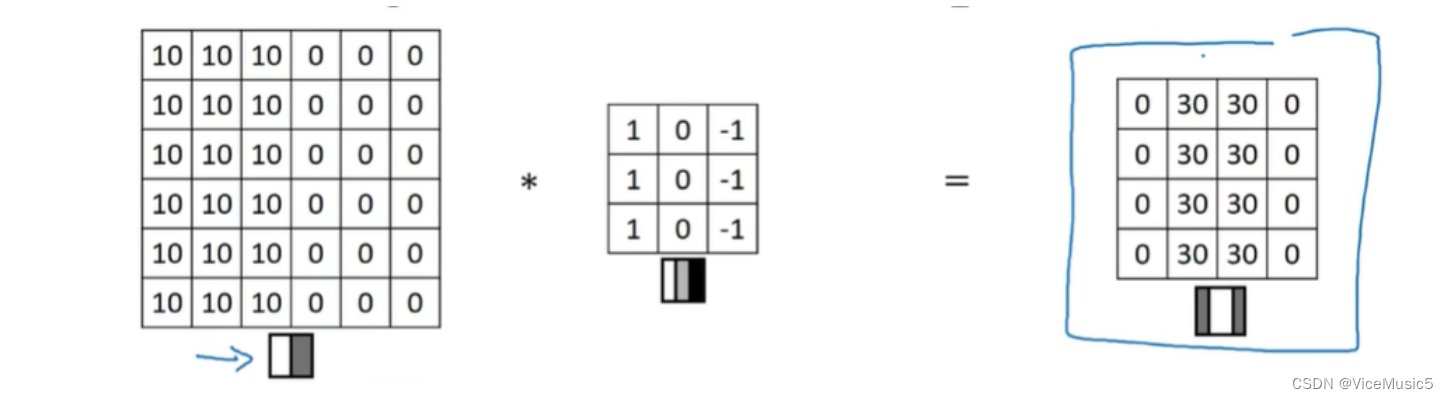
很好地展现了一个垂直的边缘检测器,这个检测器也是我们常用的类型了
还有一些其他的核
但是迄今为止,我们说到的东西仅仅止步于数学和图形学,神经网络呢???
别急,核心的数目很多,种类很多,能达到的效果都不一样,如果能检测到更适合我们手中样本的数据,就是训练呗.
比如这样一个9*9大小的卷积核心,我们可以设置参数w1--w9, 后面如果有需要还可以使用bias还有激活函数之类的东西进行处理,紧接着根据参数开始训练,这就是我们的一个核心思路.
2.卷积层的相关参数
这里我们展示一个比较完整的卷积神经网路的图像.
我们可以看到,现在我们的卷积是在三维上进行处理的,每个核的卷积结果都是一个二维矩阵.
如图所示
而具体的计算方法可以是这样子的
在这种比较正常的卷积操作中,我们设置一些相关的参数,并且将他们的名称作为约定俗成
有关参数
n:输入的长宽度
f:卷积核的长宽
s;卷积运算的移动步长
p:填充的长度(注意这个填充长度,不同的材料中表示的含义不太一样)
num:卷积核的数目,卷积核的数目在一般情况下决定了输出的三维张量的频道数量(频道是深度的另一种称呼)
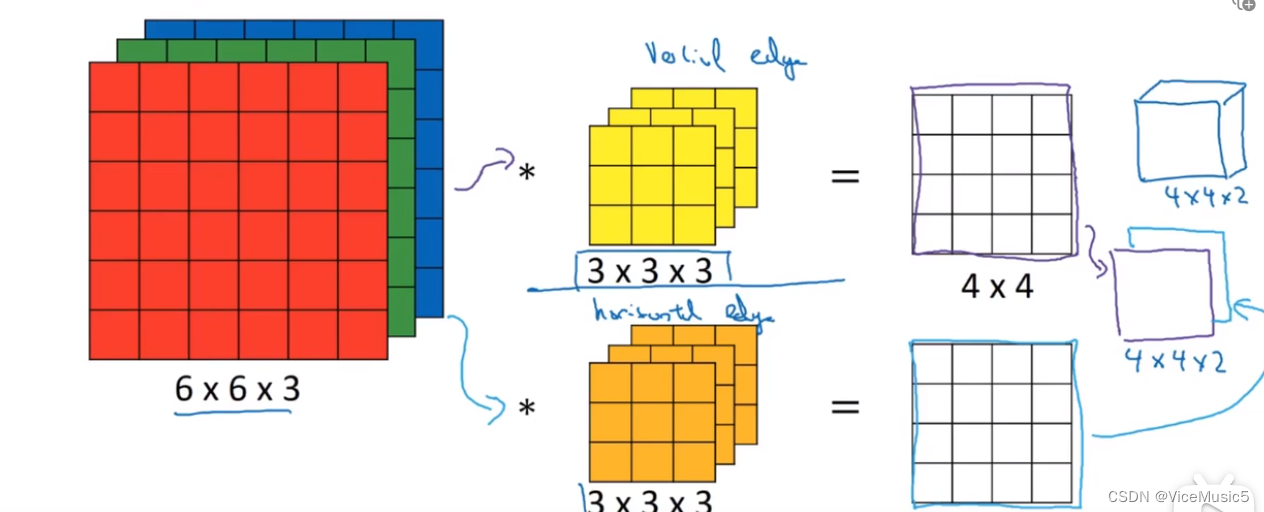
这是一张纯三维的展示图像,途中我们可以看到这里又不止一个卷积核,每个卷积核都能得到一个结果.这里其实存在一个物理意义,每个卷积核都是提取自己需要的特征,比如A获取的是垂直边缘,B获取的是水平边缘.叠加起来就是我们需要的东西(比如轮廓图)
填充和步长
在进行卷积的时候,可以注意到一个问题,随着卷积的增加,虽然特征提取了,但是输出的长宽是肉眼可见的不断变小的.并且步长也会直接影响输出的因素.
而且,卷积也会导致对于边缘部分的采集不充分,所以对于这种情况,我们的处理方法是在原本的输入基础上,在四周填充长度为p的部分,使得卷积出来的结果大小发生一些变化
如图所示:
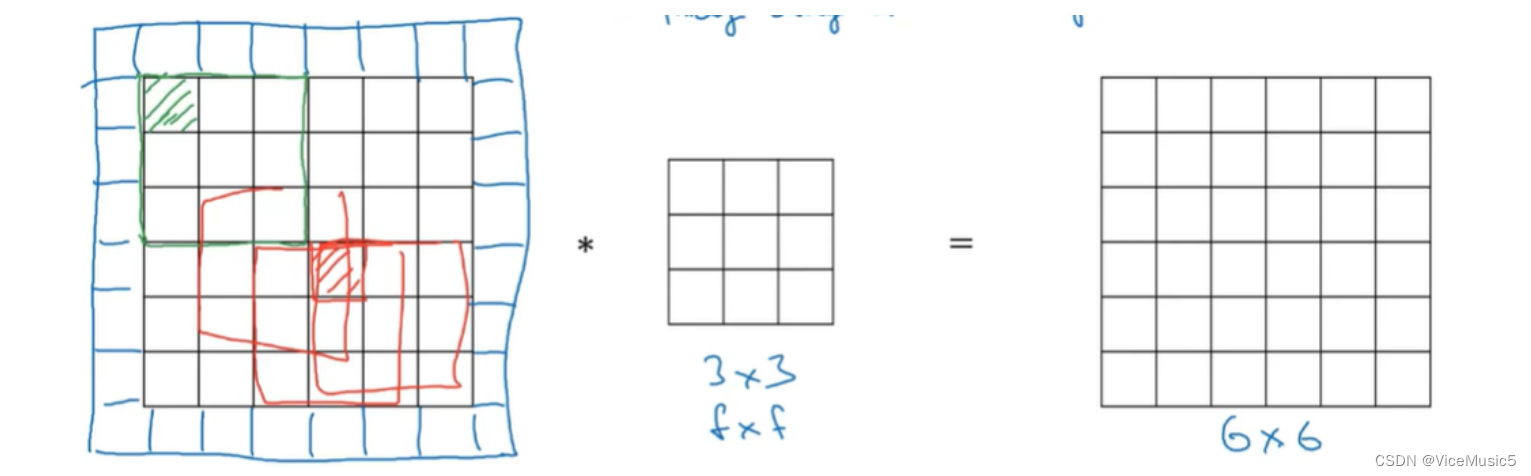
步长
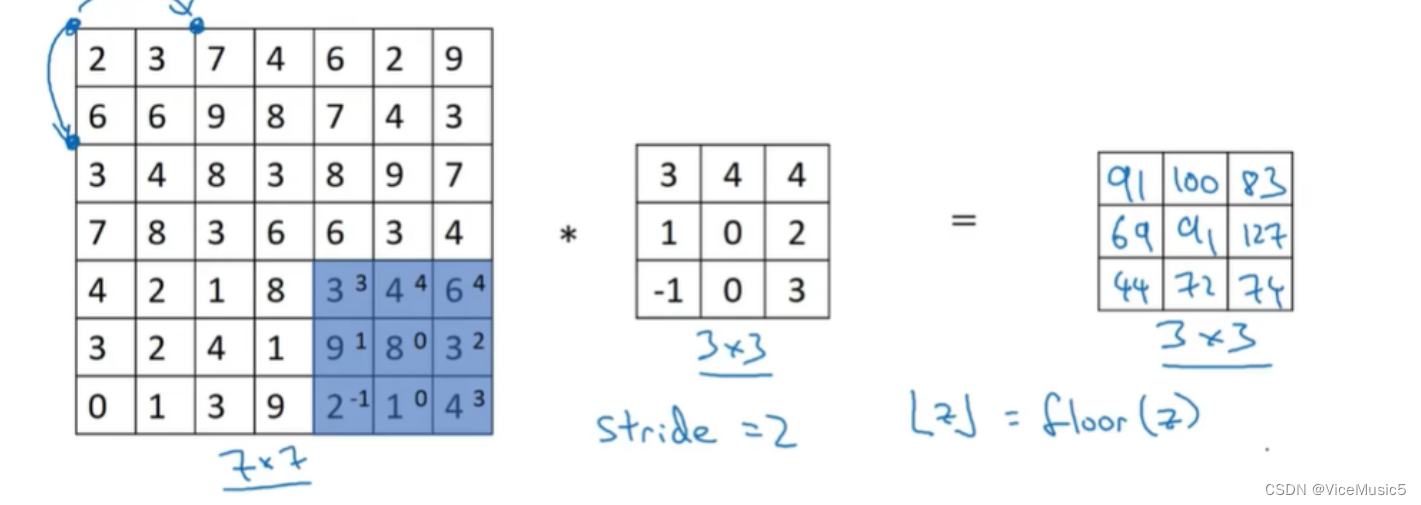
其实在这里我们可以看到一个计算公式
这个公式即可得到卷积层输出的结果长度,如果是想要完成一些保持操作,可以选择让其size=n
3.池化层pool
池化层其实个人感觉和卷积没有本质上的区别,都是对局部特征进行提取,然后够获取特征部分,压缩输入,节约计算.或者一些其他的奇奇怪怪的功能.
但是真说计算上的区别,那么就是池化层不需要任何训练参数,比较常用的两个池化核心是最大池化和平均池化.
举个例子,这就是average pooling
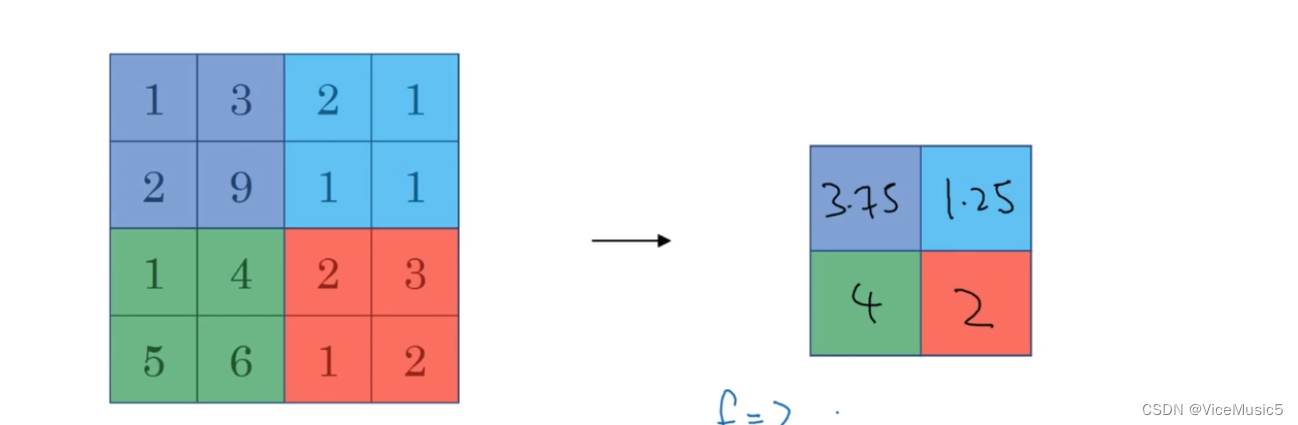
4.CNN的简单展示
下面是一段代码,用来展示一个简单的卷积操作的底层原理
import torch
from torch import nn
from d2l import torch as d2l
#cross-correlation,这个被称之为卷积的东西其实不能算是卷积运算
#一个纯粹的数学方法,默认卷积步长为1
def corr2d(X, K): #@save
"""计算二维互相关运算"""
h, w = K.shape
Y = torch.zeros((X.shape[0] - h + 1, X.shape[1] - w + 1))
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
Y[i, j] = (X[i:i + h, j:j + w] * K).sum()
return Y
X = torch.tensor([[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]])
K = torch.tensor([[0.0, 1.0], [2.0, 3.0]])
print('进行一下测试',corr2d(X, K))
#定义一个卷基层:这个卷及层只有一个核。。。而且只能对一个二维进行卷积
class Conv2D(nn.Module):
def __init__(self, kernel_size):
super().__init__()
self.weight = nn.Parameter(torch.rand(kernel_size)) #还随机生成是吧。。。。
self.bias = nn.Parameter(torch.zeros(1)) #广播机制计算?
def forward(self, x):
return corr2d(x, self.weight) + self.bias #除了这个乘法的计算结果不一样,其他的还行
#创造一个用来边缘检测的图
X = torch.ones((6, 8))
X[:, 2:6] = 0
print('展示一下这个张良边缘\n',X)
#设置一个竖直边缘检测核心
K = torch.tensor([[1.0, -1.0]])
Y = corr2d(X, K)
print('展示一下这个检测结果\n',X)
#----------------------卷积层的训练--------------------------#
# 构造一个二维卷积层,它具有1个输出通道和形状为(1,2)的卷积核
conv2d = nn.Conv2d(1,1, kernel_size=(1, 2), bias=False)
#参数分别为:输入通道数目,输出通道数目(卷积核数目),卷积核是个啥,是否需要bias
# 这个二维卷积层使用四维输入和输出格式(批量大小、通道、高度、宽度),
# 其中批量大小和通道数都为1
X = X.reshape((1, 1, 6, 8))
Y = Y.reshape((1, 1, 6, 7))
lr = 3e-2 # 学习率
for i in range(10):
Y_hat = conv2d(X) #先算一下
l = (Y_hat - Y) ** 2 #计算损失
conv2d.zero_grad() #清空梯度
l.sum().backward() #反响传播计算梯度
conv2d.weight.data[:] -= lr * conv2d.weight.grad # 迭代卷积核,具体的迭代计算。。。。
if (i + 1) % 2 == 0:
print(f'epoch {i+1}, loss {l.sum():.3f}')
5.ResNet
一般来说,我们正常去训练一些数据差不多都是这个样子的,这就是我们平时所谓的'前向传播'
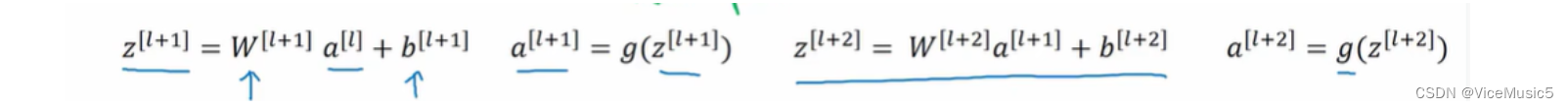
但是我们之前就知道,神经网络的深度够深,或者是出现一些不适应情况的时候,会产生'梯度爆炸'/'梯度消失'两种情况,并且在卷积中,我们渴望去减少计算量,所以出现了残差网络

所以在某些步骤可以选择跳过:,在向前传递的时候,直接把输出交给后面的层
这样每一个跳过的部分我们都称之为一个residual block,这种跳跃向前传递我们称之为: skip connection
假设我们条约了i个步骤,从 n层输出到 n+i 层输出
a[n+i] = ReLU( z[n+i] + a[i] ) = ReLU 这里要把条约之前的输入一起加上
,这是一个关键步骤.....
6.inception
初始网路块
同时完成卷积层还有池化层的操作,并且将他们的结果拼接在一起,这个东西叫做inception层已经肥肠勉强了,直接叫模块算了...
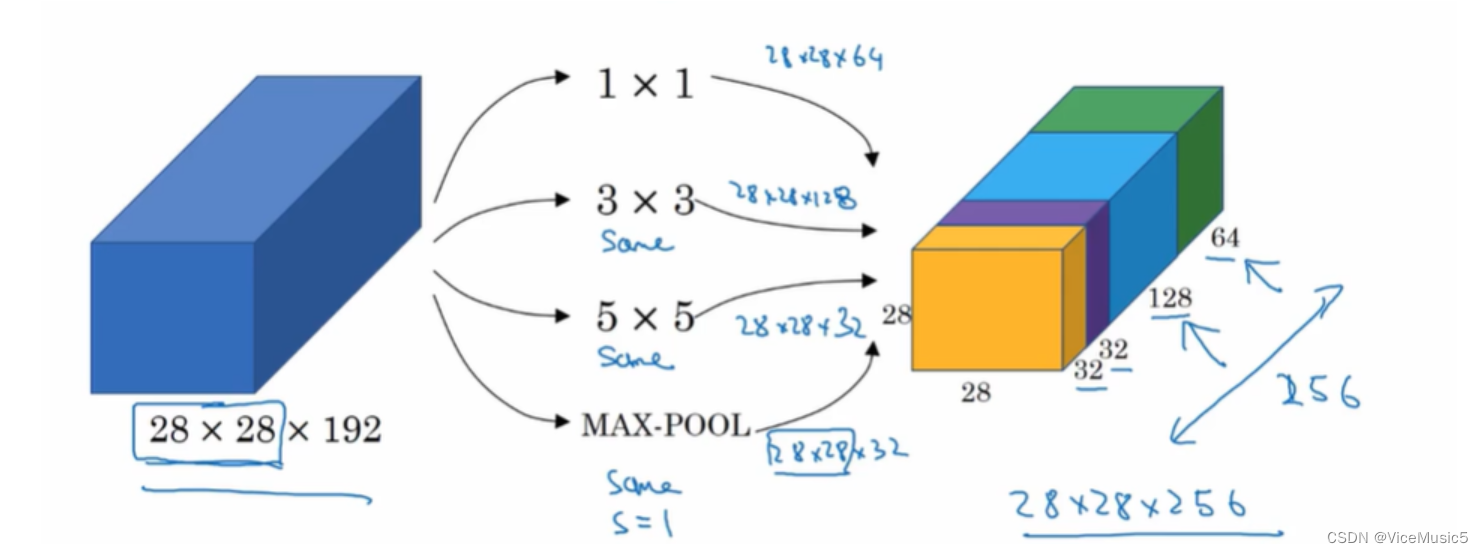
初始化网络
初始网络的模块就是一次可以提供多个计算并且合并为一个输出\
有点类似我们之前在博客上写的神经网络块
7.mobileNet
1*1的卷积有很多的用途

用来降低通道大小(深度)就是其中最重要的一个用途
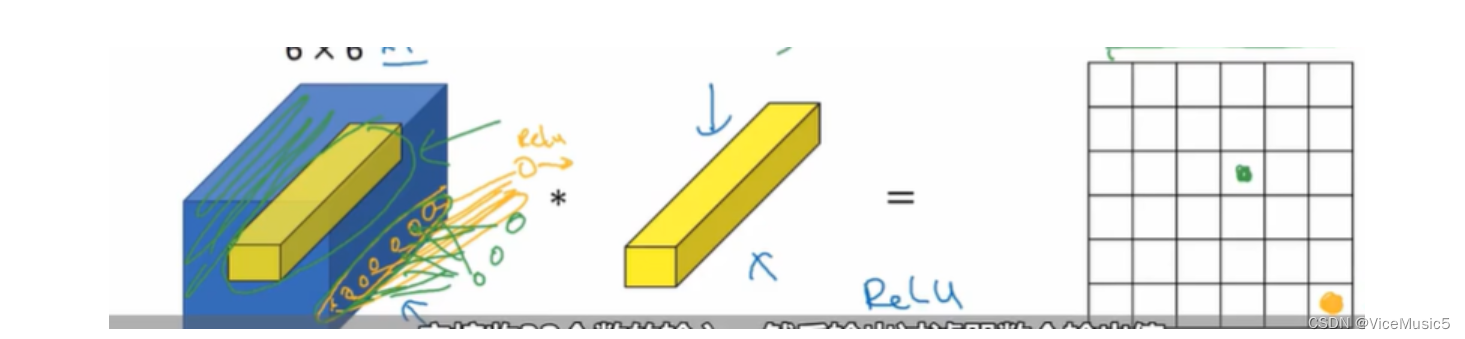
使用瓶颈的思路,将大规模的乘法运算改变为两个使用瓶颈缩减一些计算量

mobileNet(移动卷积网络)
(目标:计算损耗更小)
计算损失 = 核的单位数目*输出结果的单位数目,前面适当加上一些中间的1*1卷积层可以用来处理一些简单的深度降低操作,介于一部分的计算
可分离深度卷积:先进行逐层卷积,然后进行逐个卷积,将两个计算拆分开,形成一个
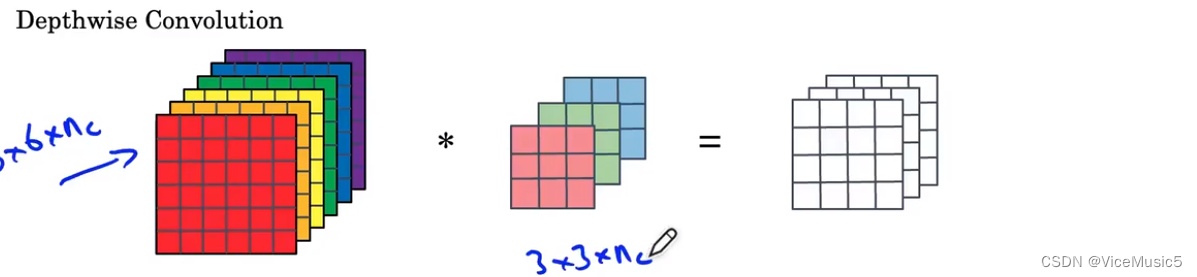
逐层卷积:
卷积层:卷积层的每个卷积核都是二维,而且每个卷积只负责对应输入的一个层.
输出:输出的每一层都是输入的每一层对应的二维卷积结果,
意思就是这种:
计算成本为:卷积核面积*输出二维面积*层数
逐点卷积:
接下来就是沿着第三维度的方向,然后进行1*1的卷积核,计算出最终的卷积产物
计算成本=卷积核体积*输出的体积

将这个部分封装成一个块
8.基于keras的简单应用:数字图像识别
import numpy as np
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D, Dense, Flatten
from keras.utils import to_categorical
import tensorflow._api.v2.compat.v1 as tf
tf.disable_v2_behavior()
#get dataSet
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
train_images = (train_images / 255) - 0.5
test_images = (test_images / 255) - 0.5
train_images=train_images.reshape(-1, 28, 28, 1)
test_images=test_images.reshape(-1, 28, 28, 1)
num_filters = 8
filter_size = 2
pool_size = 4
# Build the model.
model = Sequential([
Conv2D(num_filters, filter_size, input_shape=(28, 28, 1), activation='relu'),
MaxPooling2D(pool_size=pool_size),
Flatten(), #展开层
Dense(10, activation='softmax'), #密集层,使用softmax进行输出
])
model.compile( 'adam', loss='categorical_crossentropy', metrics=['accuracy'])
model.fit(
train_images, #训练
to_categorical(train_labels),
epochs=5,
validation_data=(test_images, #测试
to_categorical(test_labels)),
)
# Save the model to disk.
model.save_weights('cnn.mnist')
# Load the model from disk later using:
model.load_weights('cnn.mnist')
# Predict on the test dataset
predictions = model.predict(test_images)
# Get the predicted labels
predicted_labels = np.argmax(predictions[:8], axis=1)
# Print the predicted labels
print('Predicted labels:', predicted_labels[:8])
# Print the real labels
print('Real labels:', test_labels[:8])
9.迁移学习以及数据增强
迁移学习:
(又回来了真的是...之前的说法.把一个神经网络的计算结果迁移到另一个神经网络的输入)
再深度学习/计算机视觉的应用中,其实更贴切的一种说法是借用其他人已经训练好的一部分层和参数
比如极端一点的,我们获取到一个作者已经训练好的深度学习网络,获取架构以及参数
前面前几层的参数我们都不做处理,只有最后一层改成我们自己需要的softmax层输出(举例)
然后根据我们自己的数据集合,只训练自己的一层即可,前面几层可以视为别人帮我准备好的特征提取器
(根据我们自己数据集合的大小,多少参数被冻结也是按照我们自己的想法来,如果数据足够大,我们就可以自己训练所有的参数)
数据增强:
:????:这不就数据生成:
对于图像来说:裁剪,变色,滤镜,失真,扭曲,生成相关目标的新数据