多模态论文串讲
近几年,尤其是 CLIP 出现以来,多模态学习的发展异常火爆。除了传统的VQA、图文检索、图像描述等,还有受启发于 CLIP 的新任务 Language Guided Detection/Segmentation、文本图像生成、文本视频生成等。本次串讲主要还是围绕传统多模态任务,包括图文检索、图文问答、视觉推理、视觉蕴含等。本次串讲的内容可分为两部分。第一部分是只用 Transformer Encoder的方法,包括 CLIP、ViLT、ALBEF、VLMo;第二部分是同时用到 Transformer 的 Encoder 和 Decoder 的方法,如 BLIP、CoCa、BEIT v3、PaLI 等。
一:Transformer Encoder
ViLT
图文多模态任务,关键是提取视觉特征和文本特征,然后对齐。在之前的多模态研究工作中,视觉侧通常需要一个目标检测器来确定图像中物体所在的区域,再提取各区域的特征。ViT 将 Transformer 迁移到视觉领域之后,人们意识到,直接使用 patch projection 来处理图像输入也是可行的。由此,ViLT 首次使用 patch projcetion 来直接提取图像特征,摆脱了笨重的目标检测器。
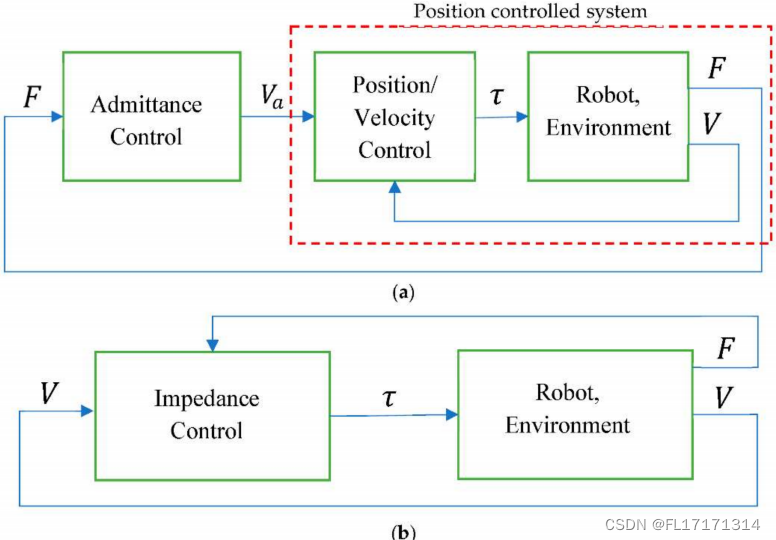
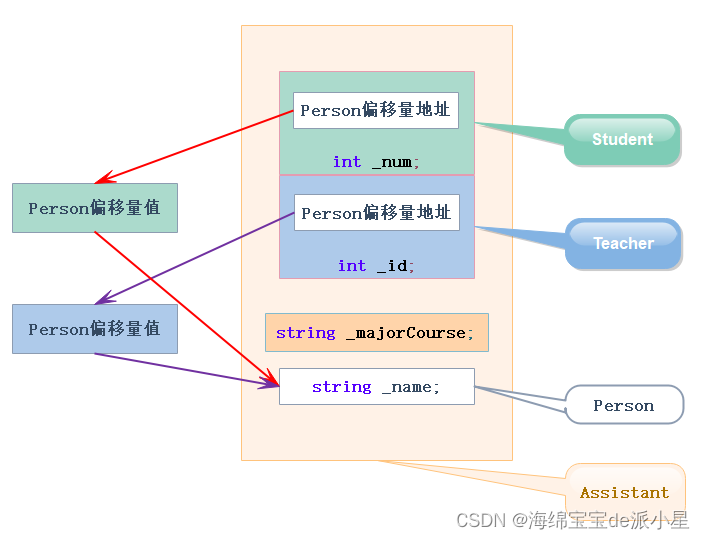
ViLT 引言部分的示意图(如图1所示)将当时已有的多模态工作归纳地很清晰,并突出了 ViLT 减轻视觉侧推理负担的优势。

图中,VE(视觉嵌入)、TE(文本嵌入)和 MI(模态交互)分别表示不同的网络组件,他们在途中模块的大小表示对应网络的复杂度。在图 1 所示的四种结构中,(a)、(b)、©三种方法中,由于使用目标检测器确定图像的区域,因此视觉端(Visual Embed)都是一个复杂的网络。在 (d) 中,也就是 ViLT 中,使用简单的线性映射,实现了视觉端处理。ViLT 将网络的大部分复杂度放在多模态任务中重要的模态交互部分。
图中,ViLT 的作者将前几年的多模态学习的工作进行了归纳。其中各种方法的代表工作如下:
(a):VSE、VSE++
(b):CLIP
©:OSCAR、ViLBERT、UNITER
(d):ViLT
(a),早期的 VSE 之类的工作,由于视觉端需要目标检测器来确定图像中各个物体的区域,因此整个网络的 VE 部分都较为复杂。而文本端 TE 只需要简单的嵌入即可。在模态交互部分,早期工作也通常是一个简单的点积来计算文本特征与视觉特征的余弦相似度。
(b), CLIP 之类的工作是一种典型的双塔结构,使用两个 Transformer 分别提取图像特征和文本特征,模态交互部分也是简单的余弦相似度。
©,研究者们认识到模态交互部分在多模态学习中的重要作用,因此,在 (a) 类工作的基础上,使用表达能力更强的网络代替简单的余弦相似度,来进行模态交互。©类的方法取得了当时最好的效果。
(d) 中的 ViLT 方法,通过直接使用线性映射代替掉复杂的视觉端处理,大大降低了模型推理的时间,并且性能相较于最好的 ©类工作也下降不多。

上图 展示了 ViLT 的具体模型结构与损失函数。模型结构上,ViLT 首先分别使用词嵌入和可学习的线性映射来提取文本和视觉嵌入,然后通过一个 Transformer 来进行特征交互。损失函数上,ViLT 共使用了三个损失,分别是图文匹配 ITM、掩膜语言模型 MLM 和文本图像块对齐 WPA。
ITM 判断输入的文本与图像是否匹配,本质上是一个二分类问题。
MLM 即 BERT 提出的”完形填空“,预测输入的文本中被挖去的单词。
WPA 则是要对齐输入文本与图像块。
ViLT 仍旧存在两个局限:
1.虽然 ViLT 通过改用线性映射,降低了视觉端嵌入网络的复杂度。但是性能有所下降,综合当时的多模态研究工作来看,视觉端的嵌入网络相较于文本端,的确需要更复杂一些。原因是文本端的 tokenizer 已经有一定语义理解能力了,而视觉端的 patch embedding 是随机初始化的。
2.虽然 ViLT 的推理很快,但是训练时间并不短。
CLIP
一种典型的双塔结构:在视觉端和文本端分别有一个独立的编码器来提取视觉特征和文本特征,而模态间的交互就是简单的点乘余弦相似度。在训练时,CLIP 模型通过图文多模态对比学习,对比损失 ITC 要求来自同一图文对的图像文本特征在特征空间中靠近,来自不同图文对的特征在特征空间中远离。

CLIP 这种双塔式多模态特征提取、模态交互部分较为简单的多模态模型十分适合图像文本匹配、图像文本检索等多模态任务。因为这种模型有一个显著的优点,即可以将数据库中的图像或文本特征预先进行特征提取并保存到硬盘中。这使得检索过程仅需要提取待检索图像的特征并计算相似度即可,大大提升了检索过程的效率。
然而,也正是由于模态交互过程过于简单,这类模型在面对视觉问答、视觉推理等需要处理复杂的模态间关系的任务时,效果一般。
至此,我们可以分析现有模型结构与损失函数,得到接下来多模态学习可行的方向。
- 模型结构方面,我们有两点结论。一是视觉特征的提取应当使用一个相对复杂(相较于文本特征提取)的网络,二是模态交互的部分也应该较为复杂,而不只是一个简单的点乘交互。也就是说,目前理想的多模态学习模型结构应当img encoder 大,模态交互也大。
- 损失函数方面,现有工作使用了多种不同的损失函数驱动训练。根据他们的计算效率和对最终模型性能的提升,我们会有所取舍地选择。在现有文献中,MLM、ITC、ITM 被证明是比较有效的,而 WPA 则计算复杂且帮助不大。
ALBEFi👍
ALBEF(ALign BEfore Fuse)贡献:
1.在 ALBEF之前,多模态领域的工作通常是使用一个 Transformer 模型来联合编码文本 token 和图像 token。其中图像 token 是经过目标检测器检出的图像区域,目标检测器是预训练得到,而非与整体网络一起进行端到端的训练。因此文本与图像没有“对齐”(align)。ALBEF 提出在进行多模态交互之前,先通过一个对比损失(其实就是 CLIP 中的 ITC 损失)来对齐图像和文本数据。
2.ALBEF 在训练时,通过动量蒸馏(momentum distillation)这种自训练的学习方式来从网络图文对数据中学习,缓解原始数据中噪声较大的问题。ALBEF 通过改进训练方式,通过自学习生成伪标签的方式来进行数据清洗,改进数据的质量。在理论上,ALBEF 论文通过互信息最大化的角度,解释了不同的多模态任务,其实就是在为图文对提供不同的视角(view),类似于在做一种数据增强,使得训练得到的多模态模型能理解不同模态下的语义,即具备 Semantic Preserving 的能力。
3**.hard neg**:Image text matching loss中FC层判断I和T是不是一个对,实际操作的时候太简单了,负样本多,很简单。选负样本的时候给constraint,选最接近正样本的负样本(文本),hard neg来源:itc的时候算余弦相似度时除了自己选一个最高的文本当作neg
4.把BERT劈两半,6层当作text encoder,6层当作fusion
方法
模型结构与损失函数
结合上面我们分析出的两点对未来多模态学习的改进方向,我们来看一下 ALBEF 提出的方法。ALBEF 的模型结构如图 4 所示。ALBEF 模型中,图像编码器是一个 12 层的 Transformer 网络,而在文本侧,相当于将一个 12 层的 Transformer 网络一分为二,其中前 6 层用于文本编码,后 6 层则用于多模态的交互。这与我们之前对模型结构的分析结果一致:视觉编码器相对较大、模态交互网络复杂。损失函数上,ALBEF 也选择了较为有效的 MLM、ITC、ITM 损失。
总结insight、对比优缺点
img:12transformer block
**text:6text encoder
fusion:bert 6*encoder

模型其它细节
• 上图中右侧的 Momentum Model,就是用于进行自训练学习的动量模型,根据主模型进行动量更新,类似 MoCo 。
• ITM 损失需要模型判断出输入图像和文本是否匹配,即一个二分类问题。直接与当前批次中所有的样本进行比对过于简单,对模态交互训练的帮助不大。ALBEF 中通过 ITC 损失计算得到的各样本间的余弦相似度,为 ITM 损失进行hard negtives挖掘,取除正样本外相似度最高的作为负样本(不知道能否适用于多对多,讲道理学到了多对多的关系的)。
• 在计算 ITC 和 ITM 两种损失时,模型的输入是原始图像和原始文本,而在计算 MLM 损失时,模型的输入则是原始图像和经过 mask 的文本。因此,ALBEF 训练时的每一轮迭代需要经过两次forward的过程。多模态学习的方法通常训练时长较长,就是因为需要进行多次前向传播,计算不同的损失。
动量蒸馏
ALBEF 中动量蒸馏的提出,是为了解决网络图文对训练数据噪声过大的问题。网上爬取的图文对训练数据,称为 Alt text(Alternative Text),这种训练数据无需人工标注,规模巨大,是近年来多模态学习主要使用的训练数据。但是这种数据的缺点是噪声较大。很多网络图片和它的描述文本是不对应的。比如一张青山绿水的景点照片,网络上的对应文字不会是“一座很美丽的山,下面有清澈的河流”这种我们想要的描述性的文本,而很可能会是这个景点的名字,如“桂林山水”。从语义的角度来说,这样的图文对是弱关联(weakly correlated)的,不是我们想要的训练样本。
这种弱关联的训练样本中可能出现某些负样本的图文匹配程度,比 GT 中正样本的 one-hot 标签的匹配程度更高的情况,不利于 ITC 和 MLM 两种任务的训练。ALBEF 中除了梯度更新的主模型之外,还有一个动量模型(Momentum Model,图 4 中右侧),用于为主模型的训练生成 multi-hot 的伪标签。动量模型通过滑动指数平均(EMA)的方式,根据主模型进行动量更新。这样,除了 GT 中的 one-hot 标签,我们就又得到了 multi-hot 的伪标签,用于 ITC 和 MLM 任务的损失计算。补充一句,对于 ITM 任务,由于其本身就是基于 GT 的二分类任务,并且通过 ITC 中计算的相似度结果进行了难负例挖掘,因此无需进行动量计算。
图 5 中展示了动量模型为 MLM(第一行)和 ITC(第二行)生成的伪标签与 GT 标签的对比。第一行第一张图,“polar bear in the [MASK]”,动量模型预测的结果中 “pool”、“water” 等甚至比 GT 的 “wild” 更清楚地表达了图像的语义。第二行第一张图中,动量模型生成的伪标签包含了图中的 ”woman“、“tree” 等元素,而这在 GT 中是没有的。作者给出的这些示例表明,ALBEF 中的动量模型生成的伪标签有时甚至比 GT 中图像文本对的语义更接近,这种自训练的方式,有利于缓解网络数据中图文不够匹配的问题。

实验:多模态表征学习的下游任务
图文检索(Image-Text Retrieval)
描述:图文互搜两种形式,是否在数据库中找到目标样本
指标:召回率R1、R5、R10
视觉蕴含(Visual Entailment)
描述:图像和文本之间是否存在推理出的关系,本质是三分类:entailment蕴含、neutral中立、contradictory矛盾
指标:准确率
视觉问答(Visual Question Answering)
描述:输入问题文本和图片,回答问题。又分为开集 VQA 和 闭集 VQA。
闭集 VQA 在给定答案集合中选择一个,本质是分类。
开集 VQA 根据输入图像和问题生成答案文本,本质是文本生成。
指标
闭集 VQA:准确率
开集 VQA:文本生成相关指标
视觉推理(Natural Language for Visual Reasoning, NLVR2)
描述:预测一个文本能否同时描述一对图片,本质是二分类问题。
指标:准确率
视觉定位(Visual Grounding)
单独领域,多模态表征学习的工作一般不涉及。
实验部分主要看一下消融实验结果,验证本文提出的哪些技巧发挥作用,实验结果如表 1 所示。作者将 MLM+ITM 两个任务作为 baseline,在此基础上添加本文提出的各种创新,观察指标的提升。
首先,加入 ITC 损失,即 ALBEF 中在多模态交互之前的的 Align 对齐。可以看到,加入 ITC 损失相较于基线模型有答复提升,在各个下游任务上都有 2-3 个百分点的提升。说明使用对比学习的损失 ITC,或者用本文中的说法,在模态融合前进行对齐,效果明显。在此基础上,再添加 ITC 对于 ITM 的难负例挖掘,效果也不错,在各项任务上有接近 1 个百分点的提升。而动量模型(MoD),无论是在预训练阶段还是下游任务阶段,带来的提升不大,可能数据量本来就大。

VLMo👍
贡献:
1.在每个 Tranformer 块中:自注意力层权重在不同类型输入间共享,而 FFN 层权重则根据输入类型的不同而不同
2.可以用文本和视觉各自领域的超大规模数据集先分别对 “文本专家” 和 “视觉专家” 进行预训练,然后再在多模态数据集上进行预训练
Intro
双编码器模型(dual-encoder)的优点是在进行检索等任务时,可以预先对数据库中的数据进行特征提取,运行效率高。缺点是模态交互部分只有一个简单的余弦相似度的计算,过于简单,在视觉推理等模态交互复杂的任务上表现较差。与之相反的,融合编码器模型(fusion-encoder)的优点是模态交互充分,缺点是无法预先进行特征提取,效率稍差。
为了解决这种冲突,VLMo 提出了 MoME(Mixture of Multi Expert),由不同的 “专家” 来处理不同类型(文本/图像)的输入数据。简单来说,就是在每个 Tranformer 块中:自注意力层权重在不同类型输入间共享,而 FFN 层权重则根据输入类型的不同而不同。
在当时,多模态学习领域还没有特别巨大规模的数据集(如现在 LAION 数据集规模已过十亿)。VLMo 的作者想到可以用文本和视觉各自领域的超大规模数据集先分别对 “文本专家” 和 “视觉专家” 进行预训练,然后再在多模态数据集上进行预训练。实验证明,在文本/视觉各自领域数据集上进行预训练带来的提升很大。
方法
下图展示了 VLMo 的模型结构和预训练任务。其中 MoME 的结构设计可以借助左侧小图理解,整体是一个标准的 Transformer Block,区别在于 FFN 层有三组参数,分别对应视觉信号、文本信号和图文信号。在接受不同的输入信号时,会使用对应的 FFN 层参数进行计算。
在预训练任务的选择上,VLMo 与 ALBEF 一致,同样使用 ITC、ITM 和 MLM 三种,并且同样借助 ITC 为 ITM 进行hard negtives。
在进行不同的任务时,会使用 MoME 结构中不同的 FFN 层参数进行训练:
• ITC:在计算 ITC 损失时,VLMo 的模型是一种 “dual encoder” 模型,以双塔的结构分别对文本和图像进行嵌入。
• ITM、MLM:在计算 ITM、MLM 损失时,VLMo 模型又成了一种 “fusion encoder” 模型,分别提取图像文本的特征之后,再用 F F F 层 Transformer Block 进行模态融合。

MoME 结构最大的优势就是灵活。在训练时,对应不同的任务时使用不同结构计算损失函数,并更新对应参数。这样的训练有一个缺点是需要做多次模型前向。
MoME Transformer:单模态能帮多模态,多模态能帮单模态
Vision 用的是BEiT
在推理时,灵活性的优势得到体现。如果要做检索类任务,可以用单独的文本/图像编码器去提取特征,提高处理效率;而如果要做推理类任务,又可以通过图文编码器进行充分的模态交互。巧妙地解决了前言部分提到的两种结构的冲突。VLMo 训练时的另一个优化是引入图像、文本单独领域内的大规模数据,对各自 FFN 专家进行预训练。
下展示了 VLMo 的分阶段训练方式,图中虚线的部分是冻结的参数。
训练共分为三个阶段。首先,VLMo 先在单独的图像数据上训练自注意力层和视觉 FFN ;然后,在单独的文本数据上训练文本 FFN ;最后,在多模态数据上训练自注意力层和三种 FFN 专家。
这里比较有意思的是在单独的文本数据上进行训练时,自注意力层是冻结的。也就是说,通过图像数据训练出的自注意力层,在文本数据上甚至连微调都不需要,就能工作得很好。
如果换过来,先文本,在视觉,效果会怎样呢(不好)?是否不同模态间的注意力是可以通用的呢?(这里的是可以的)

实验
VLMo 的性能对比实验如下表所示。可以看到,在同为 base 尺寸的模型中,VLMo 通过 MoME 灵活的结构设计,领先 ALBEF 两个多百分点。扩大模型尺寸为 large 模型后,VLMo 的性能又有三个多点的提升。最后,通过加入不同单模态数据预训练,还能再提高两个多百分点。VLMo 中 MoME 的结构设计和加入单模态数据后多阶段训练方式,带来的提升都是显著的

二、Transformer Encoder-Decoder
BLIP:Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
贡献
1.bootstrapping:Captioner + Filter 的数据处理策略
2.encoder-decoder 架构,不但能做 understanding 类的任务(如上一节介绍的下游任务),也能做 generation 类的任务
Intro
BLIP 的两个关键点都包含在标题内,一是 bootstrapping,是数据方面的改进,指的是用含噪声的数据训练出模型后,再用某些方法得到更干净的数据,用这些干净的数据训练出更好的模型;二是 unified,指的是 BLIP 作为一种 encoder-decoder 架构,不只能做 understanding 类的任务(如上一节介绍的下游任务),也能做 generation 类的任务,如图像字幕 image captioning。
研究动机:
1.模型:最近要么用transformer encoder,要么用SimVLM,encoder only的模型很难用在文本生成任务,encoder decoder模型没有统一的框架很难做image-text retrieval 任务
2.数据层面:CLIP,ALBEF,SIMVLM数据都是爬的,noisy不好。如何更好利用?设计了captioner(生成好的描述性文本)和filter可以选择GT和cap的文本选个好的
BLIP:结合ALBEF和VLMO
方法
BLIP 的模型结构和目标函数如下图所示,图中相同的颜色表示相同的参数。细分开来,BLIP 模型共包含四个网络。图中左侧是一个标准的 ViT 模型,用于处理图像数据。右侧三个网络都用于处理文本数据,但他们的细节有所不同。三个文本特征提取网络分别与图像特征提取网络配合,计算不同损失函数。

左二所示网络为 Text Encoder,提取文本特征,用于与视觉特征计算 ITC 损失。Text Encoder 不与视觉特征计算交叉注意力。
左三所示网络为 Image-gounded Text Encoder,与视觉特征计算交叉注意力,提取文本特征用于计算 ITM 损失。
左四所示网络为 Image-gounded Text Decoder,与视觉特征计算交叉注意力,用于进行 LM 语言建模训练。为了进行语言建模训练,需要 mask 掉后面的单词。因此该网络的注意力层是 Causal SA,而非 Bi SA。
其他细节
三个文本特征提取网络附加的 token 不同,分别为 [CLS]、[Encode]、[Decode]
与 ALBEF 一样,同样采用动量模型为 ITC 生成伪标签;同样使用 ITC 为 ITM 进行难负例挖掘。(BLIP 与 ABLEF 来自同一研究团队)
BLIP 的整个模型称为 MED(Mixture of Encoder and Decoder)。虽然看起来模型很多,但实际上大部分网络是共享参数的,因此实际模型参数增加并不多。
和ALBEF的区别是 fusion的text是直接输入的,不是从文本的encoder获取的,因为参数共享,不用劈成两份了,第一个文本编码器和第二个文本编码器基本一样
Captioner + Filter
除了模型结构的创新之外,BLIP 的另一个贡献在数据清洗方面,其方法流程如下图所示。
图中 I , T I , T I,T 分别表示图像数据和文本数据;红色、绿色字体分别表示噪声较大、较小的文本;下标 h , w h , w h,w 分别表示人工标注数据、网络数据和模型生成数据。
BLIP 先使用含噪声的数据训练一个 MED 模型,然后将该模型的 Image-grounded Text Encoder 和 Image-grounded Text Decoder 在人工标注的 COCO 数据集上进行微调,分别作为 Filter 和 Captioner。Captioner 为图像数据生成对应的文本,Filter 对噪声较大的网络数据和生成数据进行过滤清洗,得到较为可靠的训练数据。再根据这些可靠的训练数据,训练更好地 MED 模型,从而实现 bootstraping 训练。

实验
BLIP 的消融实验结果如下表所示。表中 Bootstrap 一列的 C , F C , F C,F 分别表示是否使用 Captioner 和 Filter,而下表 B , L B , L B,L 分别表示使用 base 模型或 large 模型作为Captioner 和 Filter。可以看到,加入 Captioner 和 Filter 对模型的性能均有一个多点的提升,并且,使用更可靠的 large 模型来进行数据处理,也能得到更优的性能。

注意 BLIP 中训练数据的处理与模型训练是解耦的,也就是说,也可以通过 large 模型数据处理,根据所得数据训练 base 模型。实际上,BLIP 中 Captioner + Filter 的数据处理策略可以为任何需要图像文本对来训练的模型进行数据生成和清洗,可以视作为多模态学习领域的一个通用的数据处理工具。如 lambdalabs 用 BLIP 生成宝可梦图像的文本描述、LAION 用 BLIP 进行数据集清洗等。
CoCa
Contrastive Captioning
贡献
1.attentional pooling(可学习得的),可以针对不同任务产生不同特征,对比学习差不多有个fc
2.decoder可以做生成式多模态任务,删掉了ITMloss,大大提升训练效率和速度(训练效率太慢了,少forward一次,想只做一次forward同时计算两个forward)
方法
看方法名称就能猜测出它是使用对比损失和文本生成损失进行训练,实际上也的确如此,CoCa 的模型框架和目标函数如下图所示。
从结构上看来,CoCa 与 ALBEF 十分接近,都是左侧网络处理图像,右侧网络劈开,前半段处理文本,后半段进行多模态交互。
与 ALBEF 最大的不同在于,CoCa 左侧处理文本和进行多模态交互的网络是一个文本解码器(Text Decoder)而非文本编码器。目标函数为 ITC 对比损失和文本解码器的语言建模损失 。使用文本解码器,模型能够处理生成式多模态任务(如 image captioning)。并且,CoCa 在图像编码器的最后使用可学习的 attention pooling 进行降采样。另外,CoCa 没有使用 ITM 损失,减少了模型参数每次迭代所需前向传播的次数,大大降低了训练时间。

实验
这个图的画法很好

BEIT V3👍
贡献
1.把图片当成是一种语言,token序列直接当另一句话
2.统一了框架,只用mask modeling
Intro
BEITv3 的关键词就是大一统(big convergence),输入形式大一统,目标函数大一统,模型大一统。BEITv3 将图像也视作一种语言(Imglish),与文本输入(English),图像文本对输入(parallel sentence)一起,实现了输入形式的大一统。在输入形式统一之后,也不需要 ITC、ITM、MLM、WPA 等其他目标函数,而是可以使用统一的 mask modeling 来驱动训练。模型层面上,自从 ViT 在视觉领域取得成功之后,Transformer 架构已有一统多模态模型的趋势。虽然在纯视觉领域,CNN 与 Transformer 谁更适合至今尚无定论,但如果要实现多模态模型大一统,Transformer 无疑更加适合。
BEITv3 使用本组之前工作 VLMo 中提出的 MoME(本文中称为 Multi-way Transformer),对不同模态使用不同的专家 FFN,实现统一。

BEITv3 的性能对比实验直接放在了论文的第一页。同样采用了 CoCa 中的多边形图,展现出了 BEITv3 相较于现有工作的巨大提升。除了多模态的任务之外,BEITv3 还可以做语言、视觉单模态的任务,图中展示了语义分割、图像分类、目标检测等视觉任务,但没有展示语言单模态的性能。可以看到,BEITv3 相较于 CoCa,也实现了全面的领先。并且,BEITv3 使用的训练数据量是远小于 CoCa 的,并且全都是公开数据集(CoCa 使用了谷歌自家的 JFT-3B)。BEITv3 的大一统框架取得了巨大的领先。
方法
BEITv3 本文并没有提出特别新的技巧,主要是将本组的 VLMo、BEITv1v2、VL-BEIT 整合并做大做强,展示了多模态领域的统一框架能够达到怎样的性能。其模型结构和目标函数如图 13 所示。模型结构就是之前介绍过的 VLMo 中的 MoME,自注意力层权重共享,根据不同的输入来选择不同的 FFN 专家。与 VLMo 不同之处在于训练的目标函数,是大一统的 masked data modeling,即遮住部分数据,要求模型还原出被遮住的数据。
如图 13 所示,BEiTv3 在单模态和多模态的数据上进行掩码数据建模(masked data modeling) 对 Multiway Transformers 进行预训练。预训练完成后,模型可以迁移到视觉任务和 VL 多模态任务上。
骨干网络:multiway transformer
BEiTv3 的骨干网络为 multiway transformer,实际上就是 VLMo 的模型 MoME。该网络的 transformer block 中的自注意力层是共享的,而 FFN 层(模态专家)则有三种,分别针对文本、图像、图文,当接收不同类型的输入数据时,数据会通过对应的 FFN 层进行计算。
预训练任务:masked data modeling
BEiTv3 在单模态、多模态数据上,通过一个统一的掩码数据建模任务进行训练。在训练时,随机掩码掉一定比例的 token,然后训练模型恢复出被掩码的 token。统一的掩码数据建模不仅能够学习数据的表示,还能学习对不同模态数据进行对齐。BEiTv3 中,使用 SentencePiece 对文本数据进行 tokenize,使用 BEiTv2 中使用 VQ-KD 训练得到的 tokenizer 对图像数据进行 tokenize(得到离散的视觉 token),作为重构目标。
关于用于视觉掩码建模的 BEiT、BEiTv2,可参考:自监督表征预训练之掩码

大一统的 BEITv3 具有极高的灵活性,可以处理视觉、文本各自单模态以及视觉文本多模态的各种任务。BEITv3 用于各种下游任务的示意图如下图 所示。
(a)、(b) 中,仅使用视觉编码器或文本编码器,BEITv3 可以处理视觉文本各自领域的单模态任务;
(c) 中,使用视觉编码器和文本编码器提取特征之后,再经过多模态交互,相当于 Fusion Encoder 多模态模型,适合于处理推理类多模态任务;
(d) 中,分别使用视觉编码器和文本编码器提取特征之后计算相似度,相当于 Dual Encoder 多模态模型,适合于处理检索类多模态任务;
(e) 中,将输入文本 mask 掉,可用于 image captioning 这种生成类多模态任务。就像搭积木一样,大一统的 BEITv3 模型可处理视觉、文本领域各类任务。

总结
朱老师化的多模态近期脉络
FLIP论文:CLIP基础上用了MAE思想,没mask的当作token,减少序列长度,值得看
MetaLM PaLi做什么由prompt决定,调整prompt决定任务调整输出
其他:Unified IO Uniperceiver1,2,uniperceiverMOE

Ref
多模态论文串讲·上【论文精读·46】
多模态论文串讲·下【论文精读·49】
多模态论文串讲笔记-CSDN博客