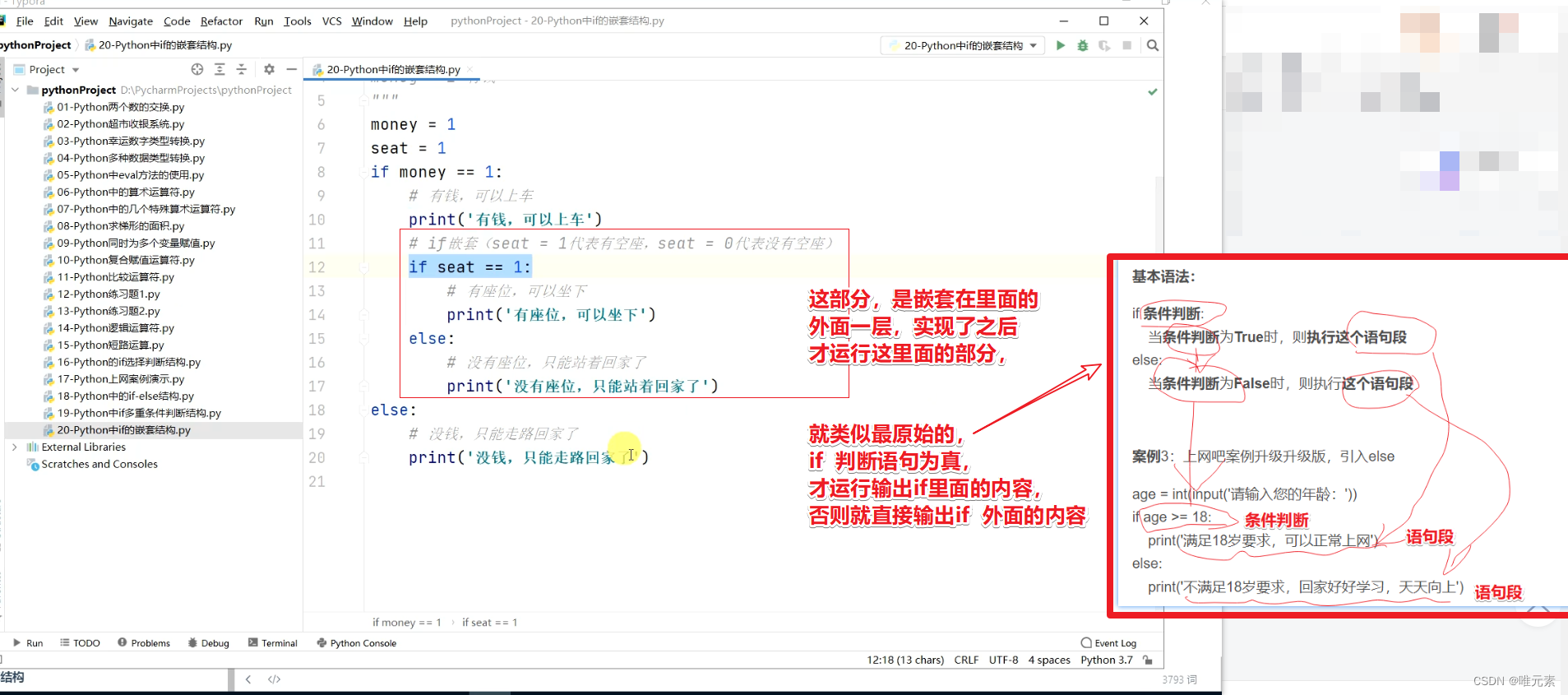
Python编程(1~6级)全部真题・点这里
C/C++编程(1~8级)全部真题・点这里
一、单选题(共25题,每题2分,共50分)
第1题
下列程序运行结果是?( )
a=12
b=23
c=str("a+b")
print(c)
A:35
B:1223
C:a+b
D:出现错误提示
答案:C
该程序将整数变量a和b分别赋值为12和23。然后,使用str函数将字符串"a+b"赋值给变量c。最后,程序打印变量c的值。
由于在str函数中将"a+b"作为字符串处理,因此变量c的值是字符串"a+b",而不是变量a和b的相加结果。
因此,程序的输出结果是"a+b"。
第2题
通过算式1×2^3 + 1×2^2 + 0×2^1 + 1×2^0可将二进制1101 转为十进制,下列进制转换结果正确的是?( )
A:0b10转为十进制,结果是2
B:0d10转为十进制,结果是8
C:0x10转为十进制,结果是10
D:0o10转为十进制,结果是16
答案:A
给定0b10,它表示二进制数10。将二进制数10转换为十进制的计算如下:
1 × 2^1 + 0 × 2^0 = 2 + 0 = 2
因此,二进制数10转换为十进制的结果是2。选项A中的0b10表示二进制数10,并且结果也是2,所以选项A是正确的。
第3题
语句float(‘something’)抛出的异常名称为?( )
A:ValueError
B:ImportError
C:IndexError
D:FileNotFoundError
答案:A
语句float(‘something’)会抛出ValueError异常。float函数用于将一个字符串或数值转换为浮点数。当传递给float函数的参数无法被解析为有效的浮点数时,会引发ValueError异常。
在这种情况下,字符串’something’无法转换为浮点数,因为它不符合浮点数的格式要求,所以会引发ValueError异常。选项A中的ValueError是正确的异常名称。
第4题
在Python语言中,关于bin(0x11)的功能,下列说法正确的是?( )
A:将十进制数11转换为二进制
B:将十六进制数11转换为二进制
C:将二进制数11转换为十进制
D:将十六进制数11转换为十进制
答案:B
在Python中,bin()函数用于将整数转换为二进制字符串表示。当使用bin()函数时,传递给它的参数可以是整数或者带有’0b’前缀的字符串。
在给定的表达式bin(0x11)中,0x11表示十六进制数11。bin(0x11)将十六进制数11转换为对应的二进制字符串。
因此,选项B中的说法是正确的,bin(0x11)将十六进制数11转换为二进制字符串。
第5题
问题如图所示,用计算机解决该问题,比较适合使用?( )
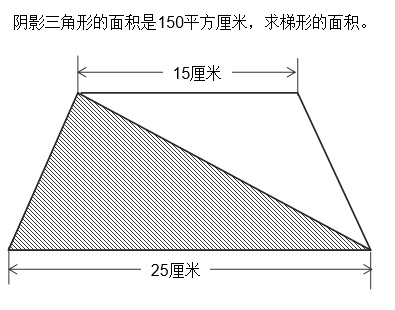
A:解析算法
B:枚举算法
C:冒泡算法
D:二分查找算法
答案:A
解析算法是一种通过分析问题的特性和数学关系,推导出问题的解决方法的算法。对于求解梯形面积的问题,可以使用解析算法来推导出计算公式。
三角形的面积公式为:面积 = 底 × 高 / 2,即:高 = 面积 × 2 / 底,可求出梯形的高度;
梯形的面积计算公式为:面积 = (上底 + 下底) × 高 / 2,可求出梯形面积。
第6题
将十进制数30转换为十六进制数,最低位上是?( )
A:c
B:b
C:e
D:f
答案:C
要将十进制数30转换为十六进制数,我们可以使用除法和取余操作。将30除以16得到商为1和余数为14。余数14对应的十六进制数是e。
因此,十进制数30转换为十六进制数后,最低位上是e。选项C中的e是正确答案。
第7题
以下表达式的值为Fasle的是?( )
A:all (())
B:all ([])
C:all ((0,))
D:all ([1,2])
答案:C
all()函数用于检查给定可迭代对象中的所有元素是否为真。对于(0,)这个元组,它只有一个元素为0,而在Python中,0被视为假值。因此,all((0,))的结果为False。
第8题
现在一组初始记录无序的数据“7,9,3,2,5”使用选择排序算法,按从小到大的顺序排列,则第一轮排序的结果为?( )
A:7,9,3,2,5
B:3,2,5,7,9
C:2,3,5,7,9
D:2,9,3,7,5
答案:D
选择排序算法是一种简单的排序算法,它通过反复选择未排序部分的最小元素,并将其放置在已排序部分的末尾来进行排序。
对于给定的初始记录无序的数据"7,9,3,2,5",第一轮选择排序的过程如下:
从未排序部分选择最小元素,即"2"。
将最小元素"2"与未排序部分的第一个元素"7"交换位置,得到"2,9,3,7,5"。
排序结果为"2,9,3,7,5"。
第9题
关于hex()函数,描述不正确的是?( )
A:hex()函数的功能是将十进制整数转换成十六进制数
B:hex()函数的参数是一个十进制整数
C:hex()函数的返回值是一个十六进制数
D:hex()函数的返回值是一个字符串
答案:B
hex()函数是Python的内置函数,用于将整数转换为十六进制字符串表示。它的参数可以是任意整数类型,包括十进制、二进制、八进制等。hex()函数会将传入的整数转换为对应的十六进制字符串,并返回该字符串作为结果。
第10题
下列关于表达式的计算结果,不正确的是?( )
A:hex(0x37) 的结果是’0x37’
B:hex(0o67) 的结果是’0x37’
C:hex(0b1011) 的结果是’0xb’
D:hex(int(‘11’,16))的结果是’0x17’
答案:D
int(‘11’, 16) 将字符串’11’作为十六进制数解析为整数,结果为17。
hex(17) 将整数17转换为十六进制字符串表示,结果为’0x11’。
第11题
有如下程序段,下列说法正确的是?( )
ls=['武汉','温州','香港','重庆']
f=open('city.csv','w')
f.write(','.join(ls)+'\n')
f.close()
A:f=open(‘city.csv’,‘w’)说明当前是读取模式
B:f.write(‘,’.join(ls)+‘\n’)语句改成f.write(’ ‘.join(ls)+’\n’),结果依然以逗号分隔
C:删除f.close()语句,也能保存文件
D:当前程序的功能是将列表对象输出到CSV文件
答案:D
给定的程序段的功能是将列表ls中的元素以逗号分隔的形式写入到名为city.csv的文件中。
下面是对每个选项的解释:
A:f=open(‘city.csv’,‘w’)说明当前是读取模式
这是错误的说法。f=open(‘city.csv’,‘w’)是以写入模式打开文件city.csv,而不是读取模式。
B:f.write(‘,’.join(ls)+‘\n’)语句改成f.write(’ ‘.join(ls)+’\n’),结果依然以逗号分隔
这也是错误的说法。‘,’.join(ls)将列表元素以逗号分隔,而’ '.join(ls)则将列表元素以空格分隔。修改为空格分隔后,结果将以空格分隔,而不是逗号分隔。
C:删除f.close()语句,也能保存文件
这是错误的说法。虽然在某些情况下,Python会自动关闭文件,但最好还是显式地关闭文件,以确保资源的正确释放。因此,建议保留f.close()语句。
D:当前程序的功能是将列表对象输出到CSV文件
这是正确的说法。给定的程序段将列表ls中的元素以逗号分隔的形式写入到名为city.csv的文件中,这符合CSV(逗号分隔值)文件的格式。
因此,选项D是正确的,当前程序的功能是将列表对象输出到CSV文件。
第12题
异常是指?( )
A:程序设计时的错误
B:程序编写时的错误
C:程序编译时的错误
D:程序运行时的错误
答案:D
异常是指程序在运行过程中遇到的错误或异常情况。当程序执行到某个出错的语句时,会引发异常,导致程序无法继续正常执行。
异常可以由多种原因引发,例如无效的输入、文件不存在、内存不足等。在Python中,当程序运行时发生异常,会抛出相应的异常对象,并可以通过异常处理机制进行捕获和处理。
第13题
关于input()函数,描述不正确的是?( )
A:input()函数是输入函数
B:input()函数的功能是从键盘读入一行文本
C:input()函数不需要参数
D:input()函数接收到的数据类型是数值类型
答案:D
input()函数是Python的内置函数,用于从用户处获取输入。它会在程序执行时暂停,并等待用户输入一行文本。输入的内容以字符串形式返回。
第14题
有如下程序段,程序运行后,输出的结果是?( )
strSZ=["语文","数学","英语","科学"]
str=strSZ[1]
print(str)
A:语文
B:数学
C:英语
D:科学
答案:B
有如下程序段,程序运行后,输出的结果是?( )
strSZ=["语文","数学","英语","科学"]
str=strSZ[1]
print(str)
A:语文
B:数学
C:英语
D:科学
第15题
print(min(80,100,max(50,60,70)))的运行结果是?( )
A:80
B:100
C:50
D:70
答案:D
首先,max(50, 60, 70)计算出最大值,即70。
然后,min(80, 100, 70)计算出最小值,即70。
最后,print()函数将结果70输出到控制台。
第16题
下列表达式的结果不为’f’的是?( )
A:‘g’-1
B:chr(ord(‘g’)-1)
C:chr(ord(‘F’)+32)
D:chr(ord(‘G’)+31)
答案:A
在Python中,字符串和整数之间不能进行减法运算,因此表达式’g’-1会引发TypeError异常。
第17题
关于查找的说法,下列说法正确的是?( )
A:顺序查找要先对数据进行排序
B:进行顺序查找,一定能找到数据
C:二分查找是一种高效的查找方法
D:二分查找法不需要对数据进行排序
答案:C
下面对每个选项进行解释:
A:顺序查找要先对数据进行排序
这是错误的说法。顺序查找不需要对数据进行排序,它是一种逐个比较的查找方法,按照数据的顺序逐个比较,直到找到目标元素或遍历完整个数据集。
B:进行顺序查找,一定能找到数据
这是错误的说法。顺序查找是一种简单的查找方法,但并不保证一定能找到数据。如果目标元素不在数据集中,顺序查找会遍历整个数据集才能确定目标元素不存在。
C:二分查找是一种高效的查找方法
这是正确的说法。二分查找是一种高效的查找方法,适用于已经排序的数据集。它通过将数据集分成两部分,并与目标元素进行比较,从而缩小查找范围,每次迭代都可以排除一半的数据,因此具有较快的查找速度。
D:二分查找法不需要对数据进行排序
这是错误的说法。二分查找要求数据集必须是有序的,通常要求先对数据进行排序,然后才能使用二分查找方法。
因此,只有选项C是正确的,二分查找是一种高效的查找方法。
第18题
用open()打开文件时,返回的是?( )
A:列表
B:字符串
C:文件对象
D:元组
答案:C
当使用open()函数打开文件时,它返回的是一个文件对象。文件对象可以用于执行各种文件操作,如读取文件内容、写入文件、移动文件指针等。
通过文件对象,可以使用相应的方法和属性来操作文件,例如read()、write()、close()等。
第19题
打开a.txt文件后,将“See you next time.”写入文件,下列语句不正确的是?( )
A:f.write(‘See you next time.\n’)
B:f.write([‘See’,’ you’,’ next’,’ time’,‘.\n’])
C:f.writelines([‘See you next time.\n’])
D:f.writelines([‘See’,’ you’,’ next’,’ time’,‘.\n’])
答案:B
因为 write 方法需要一个字符串作为参数,而不是一个字符串列表。正确的写法是将列表的元素连接成一个字符串,如 f.write(‘’.join([‘See’,’ you’,’ next’,’ time’,‘.\n’]))。
第20题
语句运行后,结果是?( )
for i in range(5):
print(i)
A:
0
1
2
3
4
B:
01234
C:
1
2
3
4
5
D:
12345
答案:A
循环从 0 到 4 迭代,并打印每个迭代的值,print打印后会换行。
第21题
若输入指令是list(‘1234’),结果是?( )
A:(‘1’, ‘2’, ‘3’,‘4’)
B:[‘1’, ‘2’, ‘3’,‘4’]
C:{‘1’, ‘2’, ‘3’,‘4’}
D:{ 1, 2, 3, 4, }
答案:B
list(‘1234’) 会将字符串 ‘1234’ 转换为一个包含每个字符作为元素的列表。所以,正确的结果是一个包含字符 ‘1’、‘2’、‘3’ 和 ‘4’ 的列表。
第22题
表达式divmod(36,10) 的值为?( )
A:(3,4)
B:(6,3)
C:(3,6)
D:(4,3)
答案:C
divmod(a, b) 函数返回一个包含两个值的元组,第一个值是 a 除以 b 的整数商,第二个值是 a 除以 b 的余数。在这种情况下,36 除以 10 的商为 3,余数为 6。所以值为:(3,6)
第23题
把文件写入到csv文件的程序段如下,划线处的代码应该为?( )
ls=[‘北京’,’上海’,’天津’,’重庆’]
f=open("city.csv","w")
______________
f.write(','.join(row)+'\n')
f.close()
A:for i in ls:
B:for row in ls:
C:for i in range(len(ls)):
D:for row in range(len(ls)):
答案:B
在给定的代码段中,应该使用选项 B:for row in ls:。
正确的代码段如下:
ls = ['北京', '上海', '天津', '重庆']
f = open("city.csv", "w")
for row in ls:
f.write(','.join(row)+'\n')
f.close()
解释如下:
-
for row in ls:遍历列表ls中的元素,将每个元素赋值给变量row。 -
f.write(','.join(row)+'\n')将每个元素row转换为字符串,并使用逗号连接各个元素,然后写入文件f。最后加上换行符\n。 -
f.close()关闭文件。
第24题
ascii(chr(65))的值是?( )
A:“‘a’”
B:‘A’
C:“‘A’”
D:‘B’
答案:B
chr(65) 返回 ASCII 值为 65 的字符,即大写字母 ‘A’。
ascii() 函数返回给定对象的 ASCII 表示形式,它返回一个字符串。对于可打印的 ASCII 字符,它将返回字符本身。
因此,ascii(chr(65)) 返回的值是字符串 ‘A’。
第25题
int()函数根据传入的参数创建一个新的整数,下列返回的值不是0的是?( )
A:int(1.0)
B:int(0.5)
C:int(0)
D:int()
答案:A
int(1.0) 将浮点数 1.0 转换为整数,即返回整数值 1。
二、判断题(共10题,每题2分,共20分)
第26题
小明准备编写一个程序,把新同学的联系方式保存到一个名为list的现有CSV格式文件里。实现这一功能可以使用语句f=open(‘list.csv’,‘+’)来打开list.csv文件。( )
答案:正确
语句 f=open(‘list.csv’,‘+’) 可以用于打开名为 “list.csv” 的现有 CSV 格式文件。使用 ‘+’ 模式将同时允许读取和写入文件。
第27题
语句float(‘2020’) 运行后的输出结果是:2020。( )
答案:错误
语句 float(‘2020’) 将字符串 ‘2020’ 转换为浮点数。由于字符串 ‘2020’ 可以被解释为有效的浮点数表示,输出结果将是相应的浮点数值 2020.0。
第28题
在Python中,代码print(‘{:8}’.format(12))中数字8的作用是按8位字符宽度输出数字12。( )
答案:正确
在 Python 中,代码 print(‘{:8}’.format(12)) 中的数字 8 表示输出的字段宽度为 8 个字符。通过使用冒号后的格式化语法 {:8},可以指定输出的字符串在给定的宽度内对齐。
第29题
‘KaTeX parse error: Double superscript at position 33: …四']).replace(' '̲,'').split('’)可以去掉列表项中姓名中间的空格。( )
答案:正确
‘$’.join([‘张 三’, ‘李 四’]) 将列表中的元素用 ‘$’ 连接起来,得到字符串 ‘张 三$李 四’。
.replace(’ ‘, ‘’) 用空字符串替换字符串中的空格,得到 ‘张三$李四’。
.split(’$') 使用 ‘$’ 分割字符串,得到 [‘张三’, ‘李四’],即去除了姓名中间的空格。
第30题
二进制数11110011转化为十六进制数为F3。( )
答案:正确
二进制数 11110011 表示的是一个八位二进制数。
将八位二进制数拆分为两个四位二进制数 1111 和 0011。
将每个四位二进制数转换为对应的十六进制数,其中 1111 对应的十六进制数是 F,0011 对应的十六进制数是 3。
组合起来得到十六进制数 F3。
第31题
在Python中,执行print(ord(‘a’)+12)语句,能够得到一个数字结果。( )
答案:正确
ord(‘a’) 返回字符 ‘a’ 的 ASCII 值,即 97。
ord(‘a’)+12 将 ASCII 值 97 和 12 相加,得到数字结果 109。
print() 函数用于输出结果。
第32题
round(5566.6)=5567,所以说round()函数其实是取整函数。( )
答案:错误
在 Python 中,round() 函数并不是简单的取整函数,而是用于四舍五入的函数。
对于 round(5566.6),返回的结果是 5567 而不是 5566。这是因为四舍五入规则中,小数部分大于等于 0.5 时会向上取整。
第33题
数据处理,通常是指利用四则运算中的加、减、乘、除来进行运算,从而得到正确结果。( )
答案:错误
数据处理并不仅仅局限于四则运算中的加、减、乘、除运算。数据处理是指对数据进行操作、转换、分析和提取有用信息的过程,可以包括各种数据处理方法和技术,如聚合、筛选、排序、过滤、转换、连接、分组、统计等。
虽然四则运算是数据处理中常见的一种操作,但数据处理的范围远远超出了简单的四则运算,还包括更复杂的算法、逻辑判断、条件处理等。
第34题
hex函数可以将十进制数转换成十六进制数。在Python交互式编程环境下,执行语句hex(2020)后,显示的运行结果是’7e4’。( )
答案:错误
在 Python 中,hex() 函数可以将十进制数转换为十六进制数。
执行语句 hex(2020) 后,显示的运行结果是 ‘0x7e4’。其中 ‘0x’ 是十六进制数的前缀,表示该数是十六进制数。
第35题
异常处理结构中,try程序段中的每一个运行错误语句,都要转移到except程序段中,执行异常处理语句。( )
答案:错误
在异常处理结构中,try 程序段中的每一个可能引发异常的语句并不都需要转移到 except 程序段中执行异常处理语句。
在 try 程序段中,可以包含多个语句,但只有当其中的某个语句引发了与 except 程序段中定义的异常类型匹配的异常时,才会执行 except 程序段中的异常处理语句。
如果 try 程序段中的语句没有引发异常,那么就会跳过 except 程序段,继续执行后续的代码。
三、编程题(共3题,共30分)
第36题
请读取1班和2班语文学科的成绩文件“score.csv” 的数据,数据内容如下图显示:
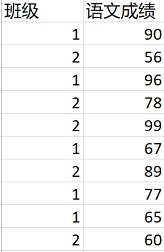
下列代码实现了读取数据并分别统计1班和2班语文成绩的和,请你补全代码。
(考生对于本题不需要运行通过,请直接编写代码确认无误后保存答案即可)
import csv
with open(" ① ") as f:
rows = list(csv.reader(f))
sum1 = 0
sum2 = 0
for row in rows[1:]:
if int( ② ) == 1:
sum1 += int(row[1])
else:
sum2 += int(row[1])
print( ③ )
解析:
在代码中, score.csv 文件的第一列为班级,第二列为语文成绩。我们使用 csv.reader() 函数读取文件内容,并将每一行存储在 rows 列表中。然后,我们遍历 rows[1:],即从第二行开始的每一行数据。通过判断第一列的班级(使用 int() 函数将其转换为整数),将语文成绩累加到相应的班级总和变量 sum1 和 sum2 中。最后,通过打印语句输出两个班级的语文成绩总和。
完整代码如下:
import csv
with open("score.csv") as f: # ①
rows = list(csv.reader(f))
sum1 = 0
sum2 = 0
for row in rows[1:]:
if int(row[0]) == 1: # ②
sum1 += int(row[1])
else:
sum2 += int(row[1])
print("1班语文成绩总和:", sum1, "\n2班语文成绩总和:", sum2) # ③
第37题
牧场举行联欢会,n头奶牛自发举行歌咏比赛。邀请了山羊公公、斑马哥哥、白兔弟弟、小喵妹妹一共四位担任歌咏比赛的评委。评比规则参赛选手的最终得分为所有评委打分的平均分。编程输出每位参赛选手的最终得分,请你补全代码。
n=int(input())
for i in range( ① ):
a=[]
for j in range(0,4):
x=int(input())
a.append( ② )
print( ③ / 4)
解析:
在这段代码中,我们首先通过 int(input()) 获取参赛选手的数量 n。
接下来,使用外层的 for 循环 range(n) 来迭代每个参赛选手。在每个选手的循环中,我们定义一个空列表 a 来存储四位评委的打分。
然后,使用内层的 for 循环 range(0, 4) 来迭代四位评委。在每个评委的循环中,使用 int(input()) 获取评委的打分,并将其添加到列表 a 中。
最后,使用 sum(a) 计算列表 a 中所有分数的总和,然后除以 4 得到平均分并使用 print() 函数输出最终得分。
完整代码如下:
n = int(input())
for i in range(n): # ①
a = []
for j in range(0, 4):
x = int(input())
a.append(x) # ②
print(sum(a) / 4) # ③
第38题
科技小组分2个小队搜集到西红柿生长的数据信息。2个小队将数据进行了从小到大排序: a = [1,3,4,6,7,13,17,21], b = [2,5,6,8,10,12,14,16,18] ,请明明将这2个小队的数据进行合并,生成为一个从小到大有序的列表。
输入:
1,3,4,6,7,13,17,21
2,5,6,8,10,12,14,16,18
输出:
[1,2,3,4,5,6,6,7,8,10,12,13,14,16,17,18,21]
请帮明明编写程序实现上述功能,或补全代码。
x = input()
s = x.split(',')
a=[]
for i in range( ① ):
a.append(int(s[i]))
y = input()
s = y. ②
b=[]
for i in range(len(s)):
b.append(int(s[i]))
ret = []
i = j = 0
while len(a) >= i + 1 and ③ :
if a[i] <= b[j]:
④
i += 1
else:
ret.append(b[j])
j += 1
if len(a) > i:
ret += a[i:]
if len(b) > j:
⑤
print(ret)
解析:
在这段代码中,我们首先通过 input() 函数获取两个输入字符串,然后使用 split(',') 将每个字符串分割为列表。
接下来,我们分别定义了两个空列表 a 和 b 来存储从输入中提取的整数数据。
然后,我们创建一个空列表 ret 用于存储合并后的有序列表。通过维护两个指针 i 和 j 分别指向列表 a 和 b 的当前位置,我们使用 while 循环来比较当前指针位置的元素,并将较小的元素添加到 ret 中。
在循环结束后,我们通过判断列表 a 和 b 是否还有剩余元素,将剩余的元素添加到 ret 中。最后,我们使用 print() 函数输出合并后的有序列表 ret。
完整代码如下:
x = input()
s = x.split(',')
a = []
for i in range(len(s)): # ①
a.append(int(s[i]))
y = input()
s = y.split(',') # ②
b = []
for i in range(len(s)):
b.append(int(s[i]))
ret = []
i = j = 0
while len(a) >= i + 1 and len(b) >= j + 1: # ③
if a[i] <= b[j]:
ret.append(a[i]) # ④
i += 1
else:
ret.append(b[j])
j += 1
if len(a) > i:
ret += a[i:]
if len(b) > j:
ret += b[j:] # ⑤
print(ret)