一、项目概述
latency-case-study 项目是一个增量延迟分析系统。该系统从系统的总体框架开始,逐步迭代增进,最终建立起系统的模型并实现对模型的分析。(个人觉得这个过程有一些类似于“自顶向下,逐步求精”的过程)
示例系统呈现“输入-处理-输出”式结构。主要包含三个主要的功能模块:sensing(检测)、prossing(处理)、actuating(驱动)。即:从传感器等设备对环境进行检测并作为输入的原始数据,然后对其进行数值处理,最后将处理结果传送给设备以对其进行驱动。
示例系统主要涉及了这样的一个端到端流:数据流起源于传感设备,经过处理部件,最终汇集于驱动设备。
本项目的核心是对系统的端到端流延迟进行建模并分析,其具体过程大致如下:
1. 确定各个模块的功能,初步实现系统的总体框架。(见functional.aadl文件)
2. 将各个模块的功能进行细化,建立其软件结构。(见impl.aadl文件)
3. 对系统的硬件执行平台进行建模。(见platform.aadl文件)
4. 建立起系统的完整模型,并实现软件与硬件的绑定。(见integration.aadl文件)
5. 进行系统的端到端流延迟分析。(对所建模的系统实例化,并进行端到端流延迟分析)
之后会结合代码(调整了示例项目源代码的缩进和不同模块的顺序)与项目论文(Incremental Latency Analysis of Heterogeneous Cyber-Physical Systems),对系统的建立进行逐过程的分析。
二、代码规范
1.模型规范
AADL使用软件包对模型进行组织。AADL的核心是组成软件包的组件类型说明和组件实现说明。
组件的类型说明定义了组件的类别,以及组件的接口特征。
组件的实现说明定义了组件内部的结构,描述了组件内部的构成及其交互。
2.组件类别
AADL的组件被分为四类:通用组件(抽象组件)、应用软件组件、硬件组件、复合组件。
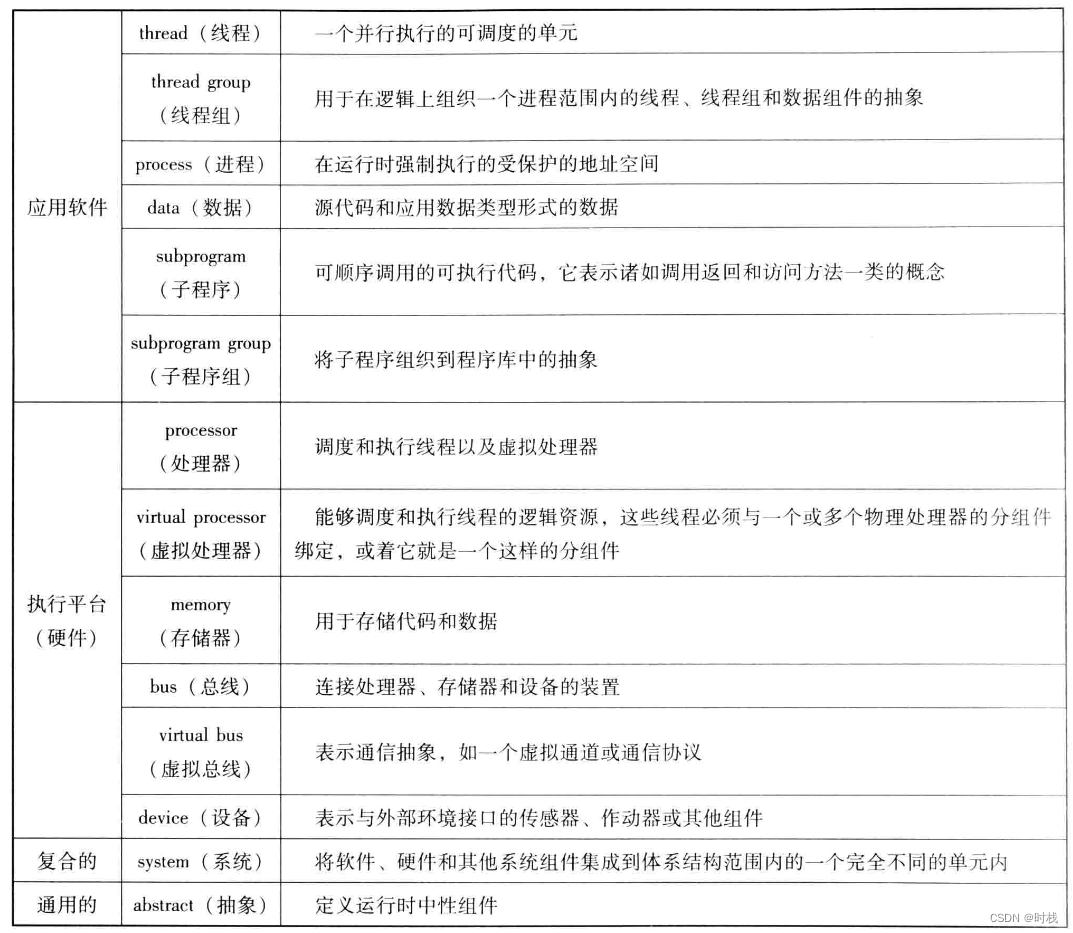
3.组件名称
一个合法的AADL标识符是由字母开头并由数字或字母组成的字符串(字母和数字可以使用下划线隔开),该标识符不能是AADL备用字。
组件类型的名称为一个AADL标识符。
组件实现的名称为:由 . 隔开的两个标识符。第一个标识符是该实现的组件类型名称,第二个标识符需要保证该标识符在该类型的实现中唯一。
4.AADL备用字
对本项目中的代码,补充以下AADL备用字:
组件类型说明:
features 用来声明一个组件的接口/端口。
flows 用于流的相关说明,之后提到的流规范、流实现和端到端流就在该模块被声明。
properties 为组件及相关要素的各种属性赋值。
组件实现说明:
subcomponents 用来说明一个组件所包含的子组件。
flows 用于流的相关说明。
connections 定义组件之间的连接
三、流说明
流能够对整个体系结构的逻辑路径进行表述和分析。这里的流可以表示任何逻辑流,比如数据流、控制流、故障事件流等。对于流的说明,可以分为以下三种类型:
1.流规范(flow specification):明确组件的角色。包含在在组件的 类型说明 flows 之中。可以分为以下三种类型。
①流源(flow source):定义组件中流的起源,流源借助组件的流出特征(exit feature)从组件中流出。
②流汇(flow sink):定义组件中流的终止,流汇借助组件的流入特征(entry feature)流入组件。
③流路径(flow path):定义流经组件的一个流,流路径借助组件的流入特征流入组件,然后借助组件的流出特征流出组件。
注:特征(feature),主要对组件的接口进行定义。上述的流入特征和流出特征可以理解为组件的输入端口和输出端口。
2.流实现(flow implementation):对组件中流经分组件的流规范进行详细说明,这一步是流规范在组件内部实现的细化。它指定了如何在组件内部实现流(如果组件中存在分组件,需要将分组件考虑在内)。比如,一个 流路径 的流实现描述了数据如何从一个输入端口输入,如何通过连接将其传递到子组件(这里也需要考虑不同子组件间如何进行连接),并最终从输出端口输出。
3.端到端流(end-to-end flow):对从起始组件到最终组件的完整流路径进行定义。它列出了流的所有元素,包括流涉及的组件以及组件之间的连接。
流规范的代码模板如下( []内的为可选内容):
Name :flow source <exit feature> [{properties}];
Name :flow sink <entry feature> [{properties}];
Name :flow path <entry feature> -> <exit feature> [{properties}];
流实现的代码模板如下( path sequence 为路径序列):
Name :flow source <source path sequence> -> <exit feature> [{properties}];
Name :flow sink <entry feature> -> <source path sequence> [{properties}];
Name :flow path <entry feature> -> <flow path sequence> -> <exit feature> [{properties}];
端到端流的代码模板如下:
Name :end to end flow <origin> -> <path sequence> -> <destination> [{properties}] [in modes];
四、抽象功能模块与系统顶层模型的建立(functional.aadl)
本系统包含两个检测功能模块(s1和s2),一个处理功能模块(p)以及一个驱动功能模块(a),其功能结构如下图所示。数据流源于s1和s2,经过p进行处理并最终汇集于a。
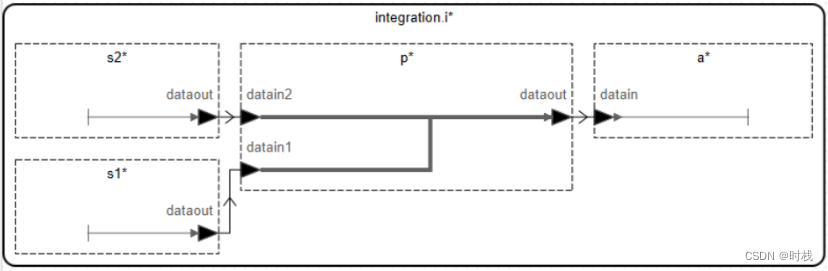
每个检测功能模块通过一个数据输出端口输出数据,没有数据输入端口。
处理功能模块通过两个数据输入端口接收数据,通过一个数据输出端口输出处理结果。
驱动功能模块通过一个数据输入端口接收数据,没有数据输出端口。
系统顶层模型包含4个子组件:2个检测功能模块、一个处理功能模块、一个驱动功能模块。系统也包含若干端口之间的连接,进而构成了两条主要的端到端流,如上图所示。
从抽象层次上对传感功能进行定义。该模块属于流源,包含一个数据输出端口,传感功能的执行时间为1ms .. 3ms,代码如下:

从抽象层次上对处理功能进行定义。该模块属于流路径,包含两个数据输入端口和一个数据输出端口。处理功能的执行时间为3ms .. 4ms,代码如下:

从抽象层次上对驱动功能进行定义。该模块属于流汇,包含一个数据输入端口。驱动功能的执行时间为5ms .. 7ms,代码如下:

在以上功能的基础上对系统进行集成。首先进行组件类型说明。然后定义系统的四个子组件,定义各个子组件之间的连接,并且进而对系统的端到端流进行声明,最后声明系统端到端流延迟属性的范围是20ms .. 30ms。

五、抽象功能模块的细化——实现各模块的软件功能(impl.aadl)
首先对原本的模型进行进一步细化,系统处理的数据为坐标数据position,传感器可以获取当前位置的GPS坐标,因此需要对各个端口传输的数据类型进行定义:首先说明position的数据类型,然后实现该数据类型(该data类型组件包含两个子组件,x坐标和y坐标,均为基本数据类型中的64位无符号整数类型),可以将该实现名为 position.实现名称 ,为了简单且便于理解,取实现名称为 i ,因此数据类型的实现被命名为position.i

既然不同端口的数据类型已经被定义,那么可以对functional.aadl中各个模块的features进行细化。也同时通过extends备用字,完成抽象模块到具体的进程模块的细化过程(为了便于展示,调整了源代码的模块声明顺序),如下:
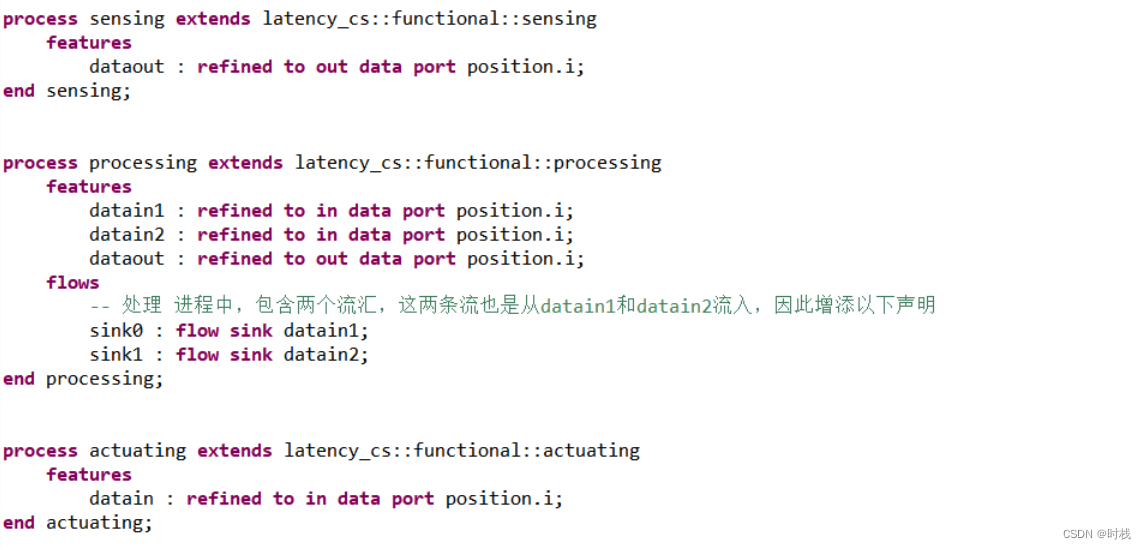
对传感进程(process)进行实现:该进程中包含一个线程thr_sensing,该线程是周期性线程并且每隔20ms执行一次,执行时长为1ms .. 2ms。首先对线程类型进行说明然后将其作为子组件加入到线程 sensing.i 中,并且实现线程 数据输出端口 到进程 数据输出端口 的连接。在将子组件考虑在内之后,还需要将流规范细化为流实现。代码如下:

对处理进程进行实现:该进程包含两个线程。线程tf中包含两条流路径,流从两个输入端口输入,从同一个数据输出端口输出。线程ts包含两个流汇,流从两个输入端口输入,终结于线程内部。两个线程的执行周期都为20ms,执行时长分别为3ms .. 4ms 与 2ms .. 3ms。示意图如下所示:
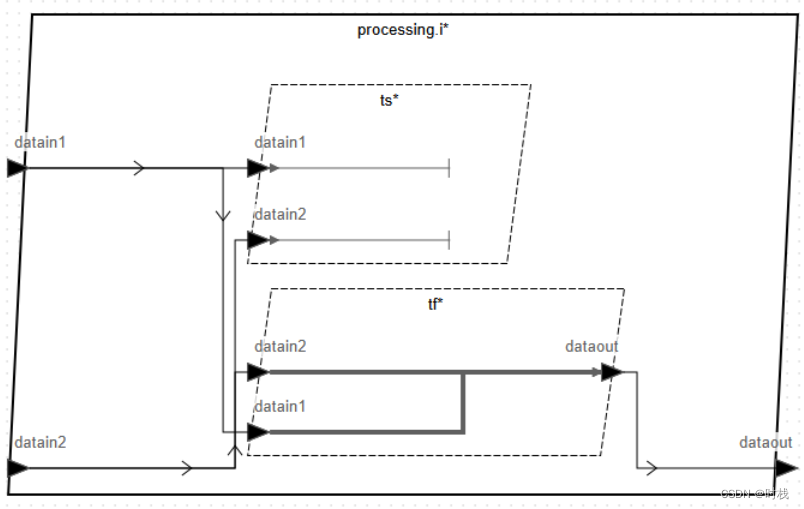
因此,该部分的进程和线程的代码如下:

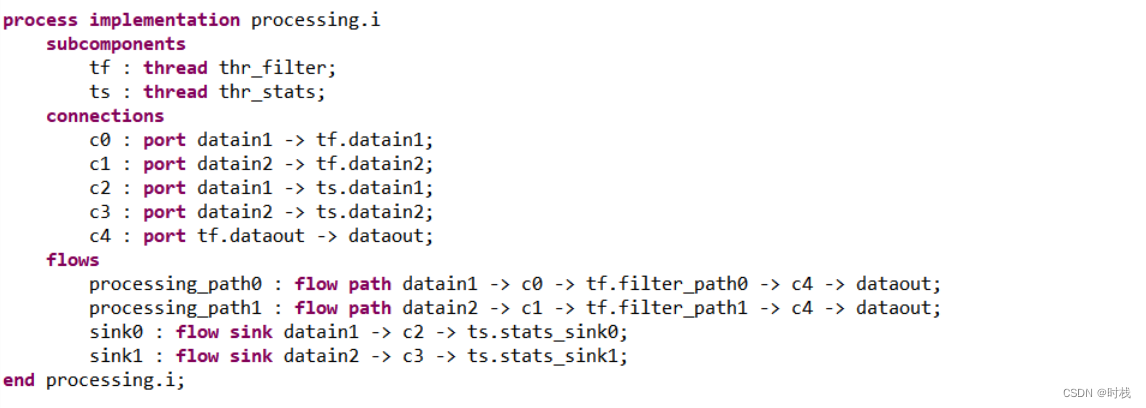
对驱动进程进行实现:该进程包含两个线程。线程tc包含一条流路径,流从一个输入端口输入,从一个输出端口输出。线程ts包含一个流汇,流从一个输入端口输入,终结于线程内部。两个线程的执行周期都为20ms,执行时长分别为1ms .. 3ms 与 1ms .. 2ms。示意图如下所示:
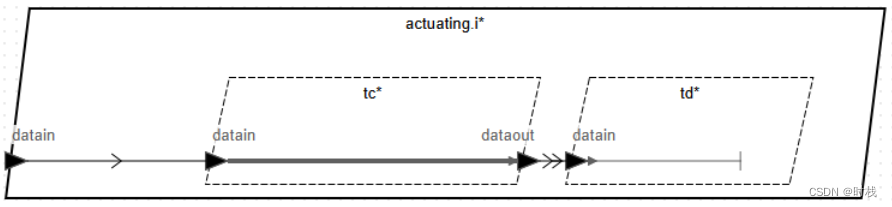
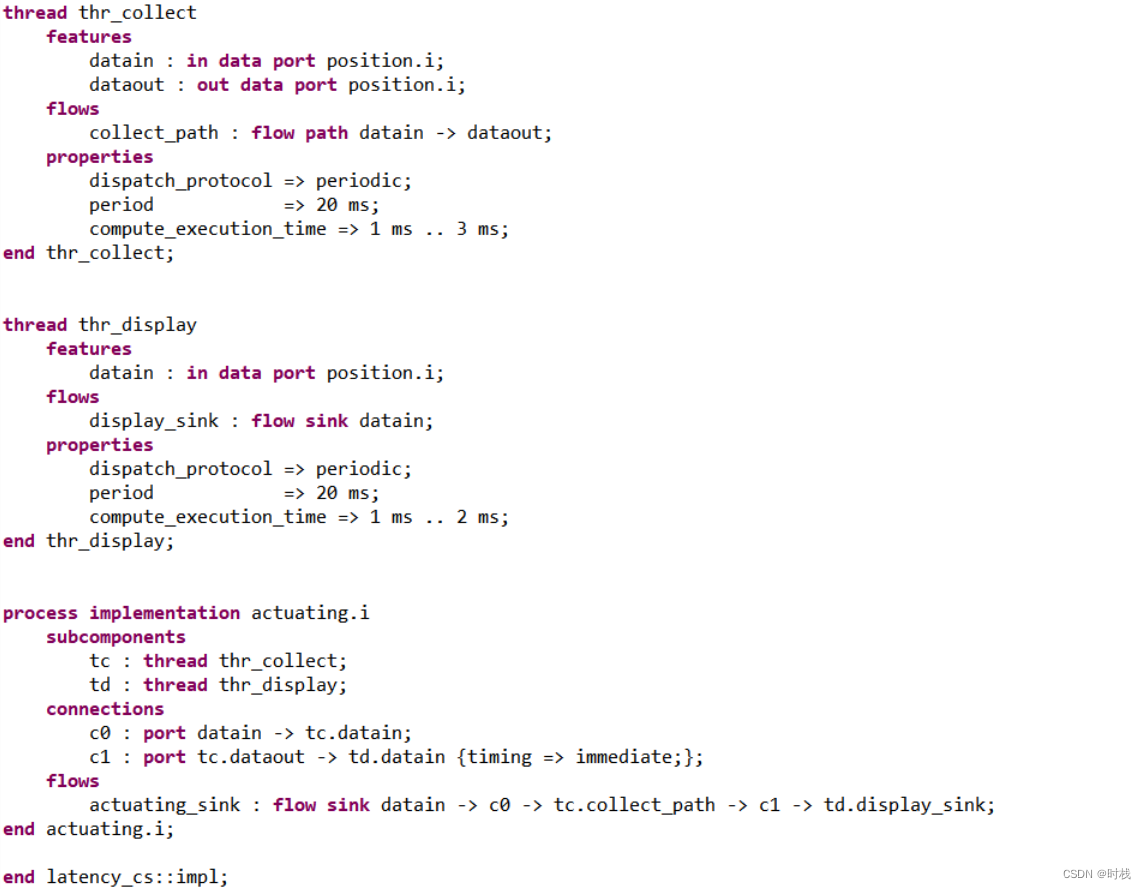
因此,该部分的进程和线程的代码如下:
六、硬件执行平台的实现(platform.aadl)
本系统的部署方式主要可以分为两类:分布式部署、集成部署。
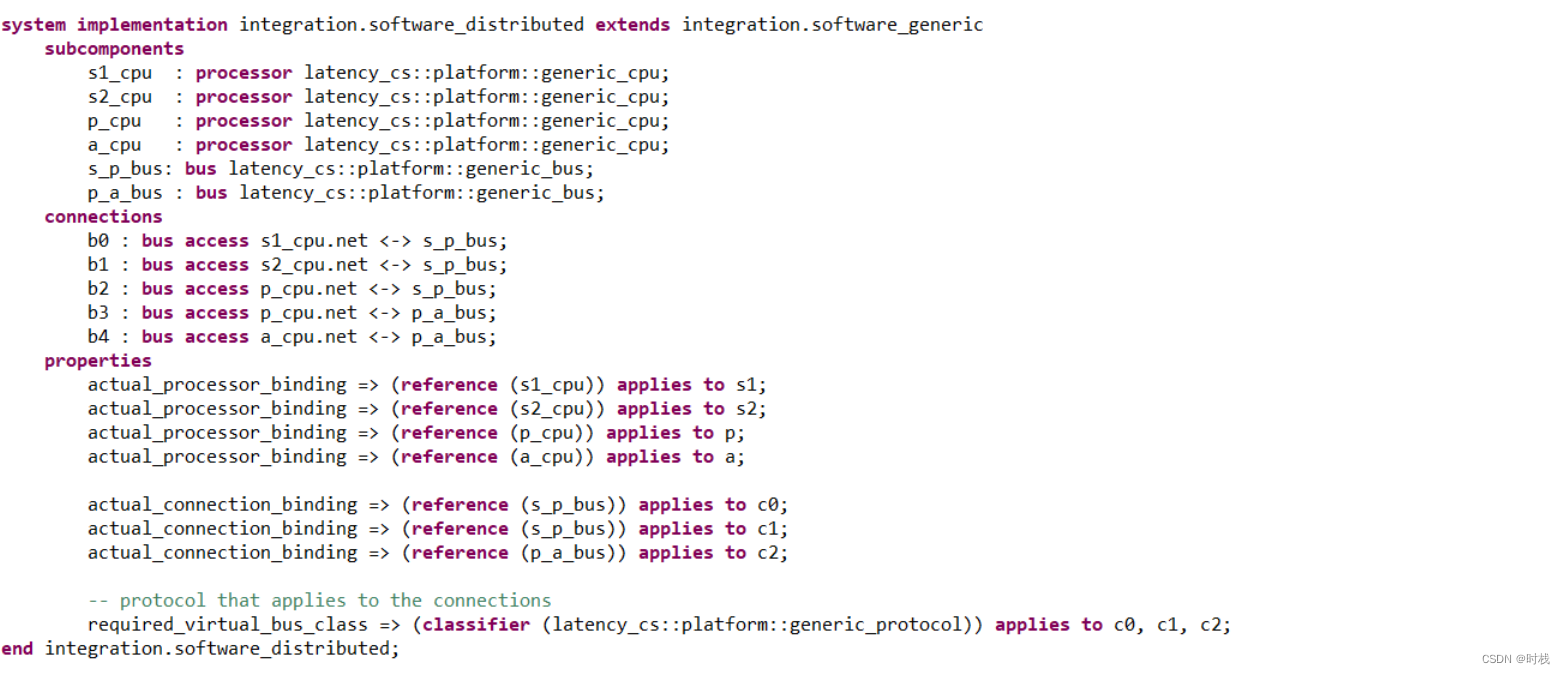
分布式部署是将每个进程分配给一个单独的处理器,这些处理器之间通过总线相关联。
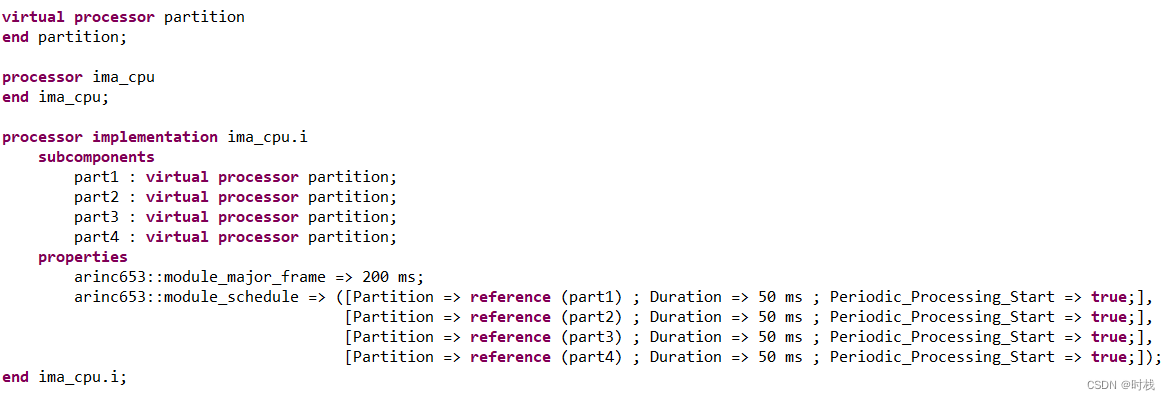
集成式部署是将一个处理器划分为若干虚拟处理器,并将虚拟处理器与对应操作系统分区绑定,进而可以将每个进程分配到这些互相隔离的分区上运行。(“分区”用于将实时操作系统中的不同任务和应用程序隔离开,以确保它们互不干扰)。
所以对硬件平台的建模将分为两个部分:对分布式部署的处理器建立模型(generic_cpu),对集成式部署的的处理器建立模型(ima_cpu)。
1. 分布式系统,其部署如下图所示:
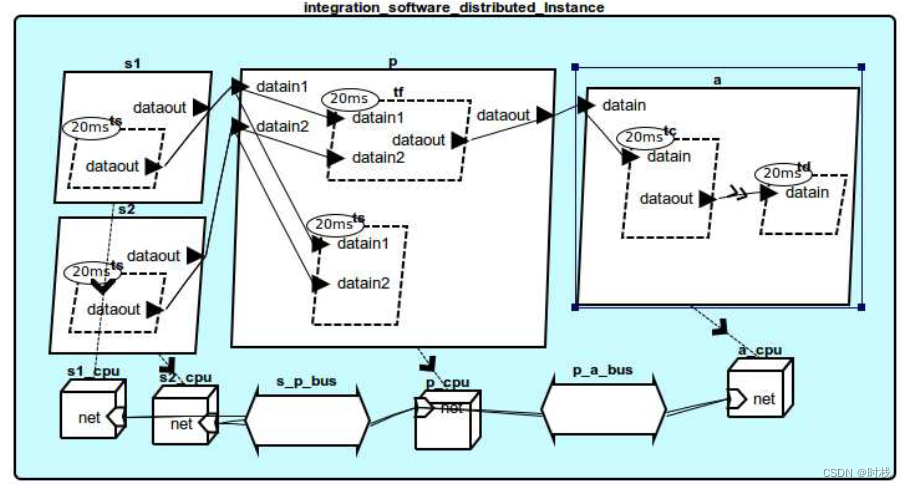
对于分布式系统,因为不同处理器(processor)需要使用总线通信,而对总线的访问需求需要在处理器的类型说明中进行定义。CPU与总线的连接是在系统实现内进行说明的。同时也需要完善对处理器中涉及总线的定义。除了对处理器和总线的定义之外,还需要对虚拟总线及相关的属性进行定义。代码如下:

2. 集成式系统,其部署如下图所示:
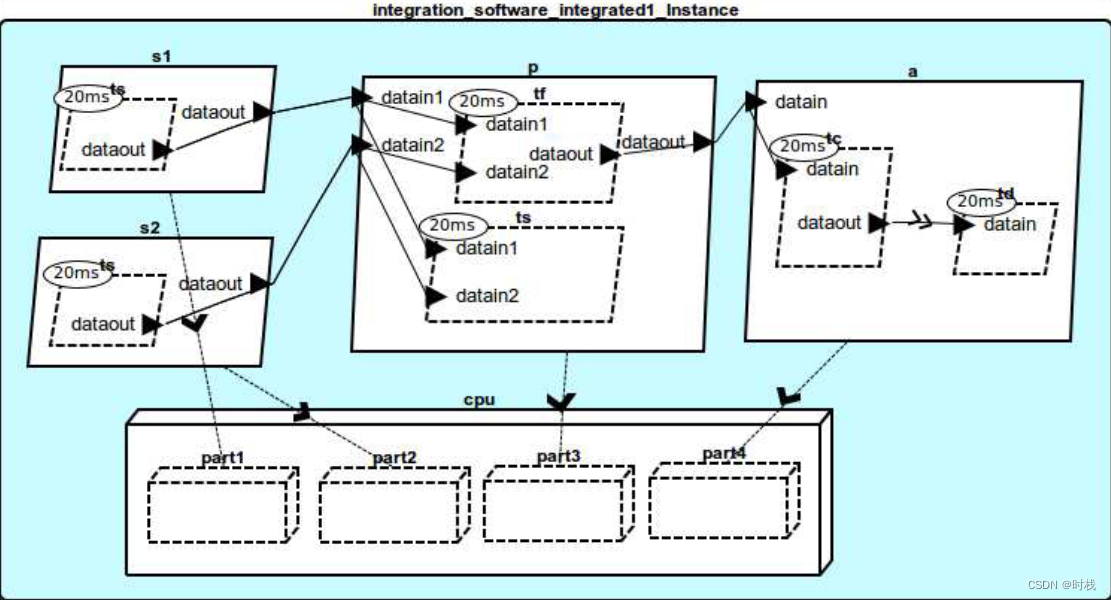
对于
集成式系统,需要对处理器和虚拟处理器进行定义。因为系统中有4个进程,所以需要在处理器的子组件中定义4个分区。同时在处理器的属性中对分区的主帧周期、调度顺序以及各个分区时长进行初步的定义:主帧周期为200ms,调度的顺序为part1、part2、part3、part4,每个分区的时长均为50ms。代码如下:
七、系统模型的构建(integration.aadl)
系统是软件、硬件执行平台和系统组件的各种各样的组合。可以针对不同的策略实现出多个不同的系统,然后可以根据实际的需求,在这多个候选系统中选择出最佳的系统实现。
在function.aadl中已经简单地定义了系统模块,系统的子组件均为abstract类型。在该部分中需要对系统模块进行进一步的细化完善,首先对软件部分进行完善,这将需要将系统的子组件类型由抽象类型细化为进程类型(在impl.aadl已经实现)。首先进行组件类型说明(继承functional中的integration),然后进行组件实现说明,代码如下:

在实现了系统的通用软件结构(integration.software_generic)之后,接下俩就可以将之部署到不同的系统中去了。
分布式部署,首先需要进行硬件组件的添加,然后对软硬件资源进行绑定。硬件组件的添加,需要在系统的子组件中为每一个进程添加一个处理器,也需要添加两个用于在检测和处理、处理和驱动之间传输数据的总线组件。添加完组件之后还需要对这些硬件组件进行连接(在connections中实现)。最后需要在属性(properties)中对软硬件系统进行绑定,代码如下所示:
对于集成式部署,仅仅需要在子组件中添加一个处理器组件就可以了。但是考虑到主帧的时长、每个分区的时长以及分区的调度顺序都可以进行改变,因此这里有集成式部署的三个不同的实现。
集成式部署的第一个实现,是按照之前定义的处理器分区规则进行的(主帧时长200ms,每个分区时长50ms),这里仅仅将软硬件组件进行绑定。代码实现如下:

集成式部署的第二个实现,在第一个实现的基础上,调整了主帧时长和各分区的时长。主帧时长被缩短为20ms,各分区时长也被重新定义为3ms、3ms、8ms、5ms,如下:

集成式部署的第三个实现,在第二个实现的基础上,调整了分区的调度顺序。将原本的[part1、part2、part3、part4]的顺序调整为[part3、part2、part4、part1],如下:

八、进行系统的端到端流延迟分析。
对分布式系统的端到端流延迟分析,首先对系统进行实例化:
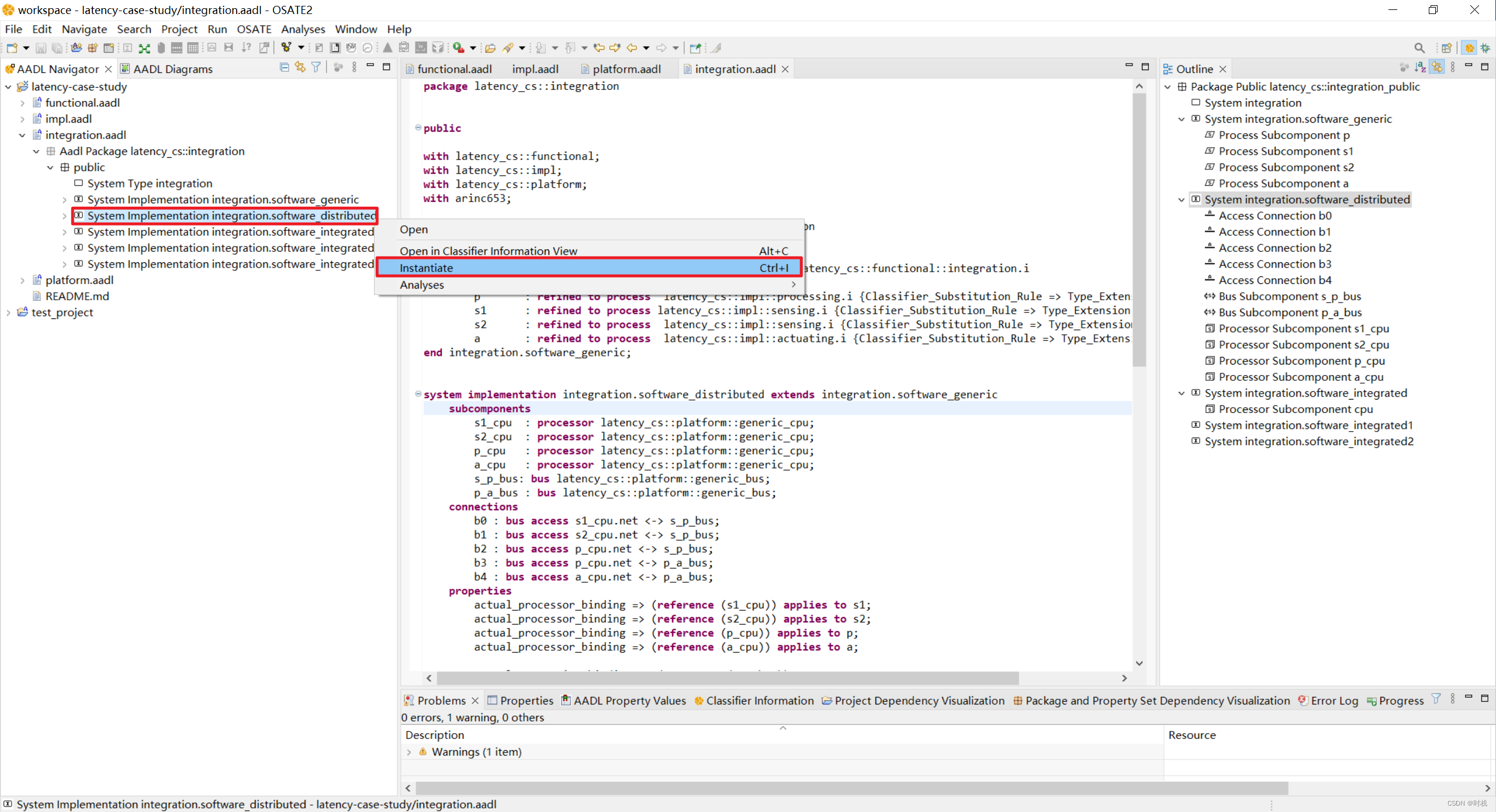
然后对其进行端到端流延迟分析。
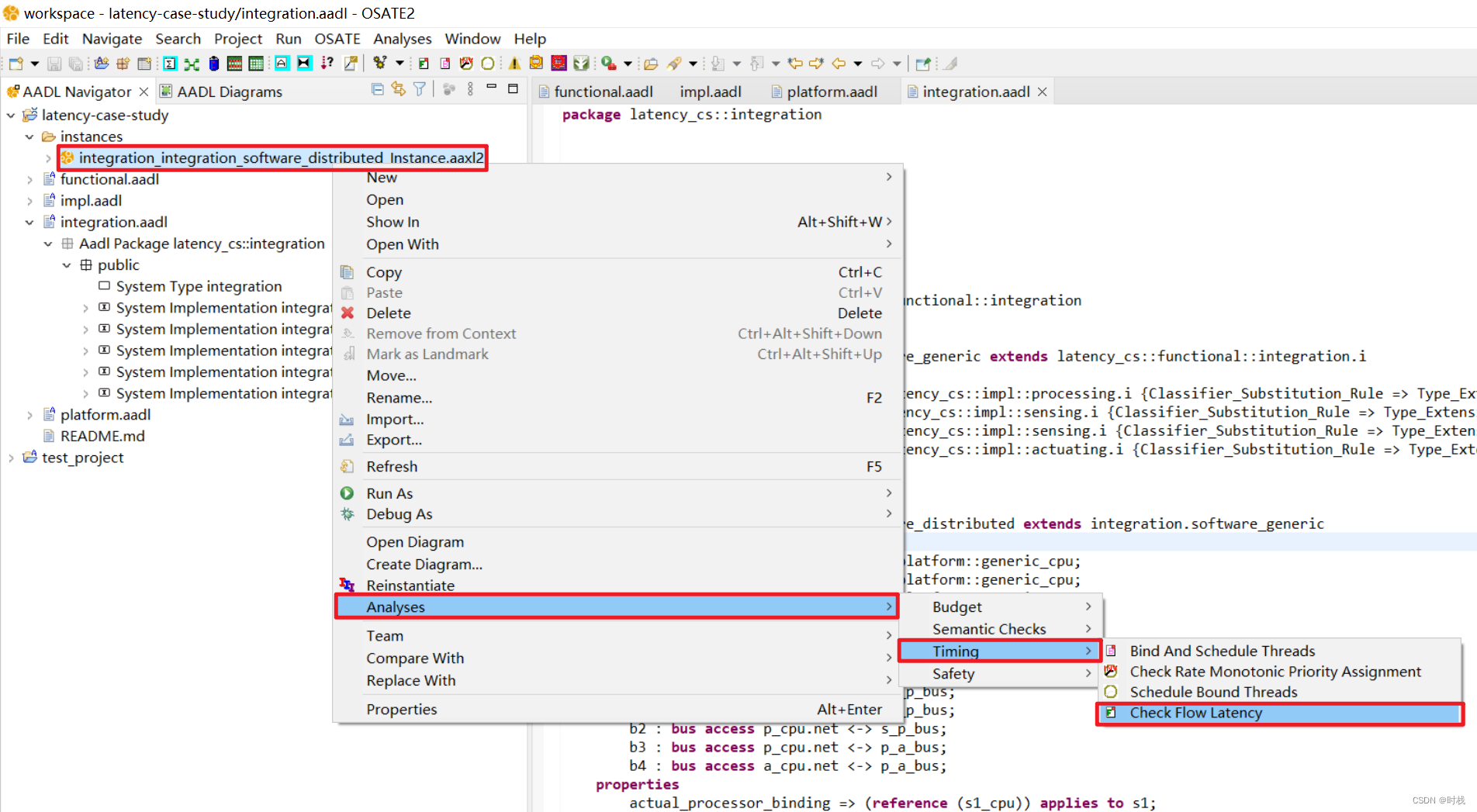
会发现没有任何流延迟分析报告被生成(当前使用的是最新版OSATE 2.12.0),可以通过查看Error log发现:NullPointerException 空指针异常。
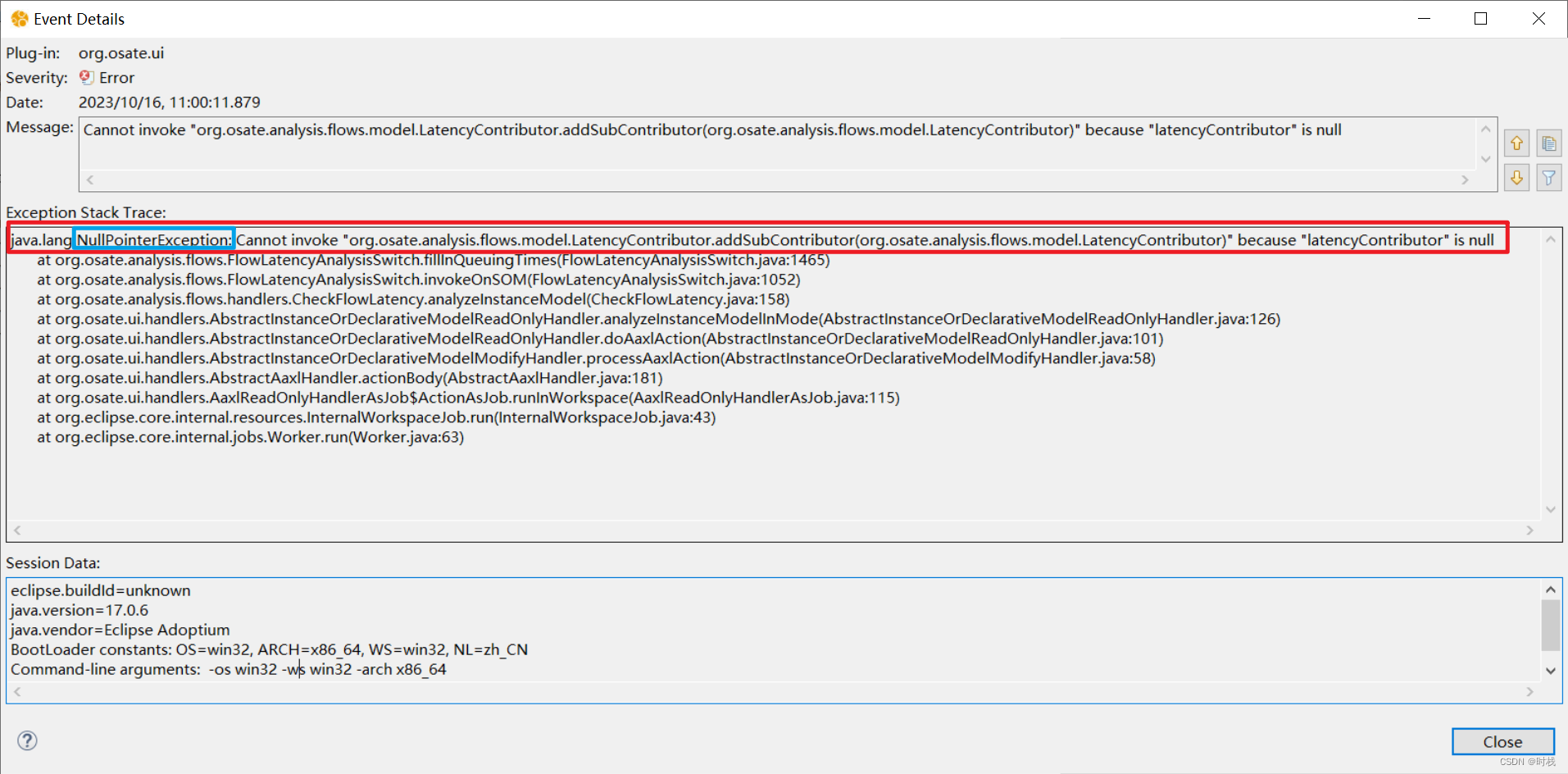
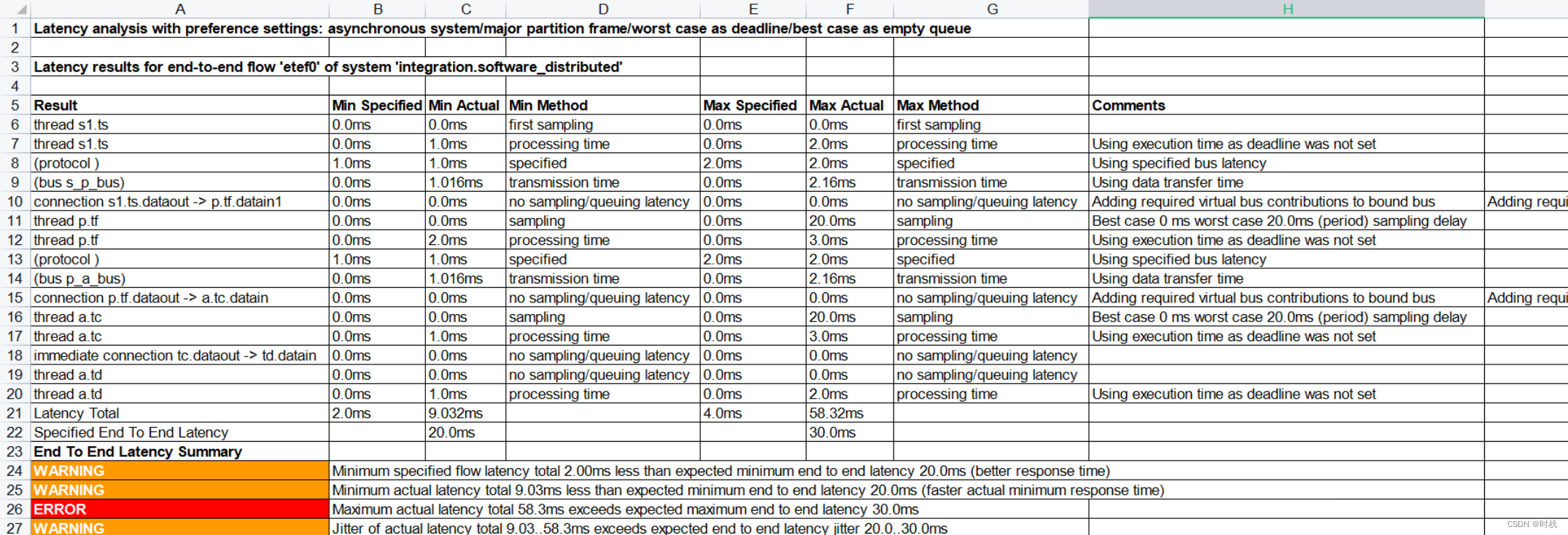
这可能是因为源代码版本与开源工具环境版本的兼容问题:对于OSATE 2.8及之后的版本,分布式系统均会出现该错误(集成式部署可以在OSATE 2.12.0中正常进行分析,这里仅仅是分布式系统的分析会出现问题),因此,在OSATE 2.7中进行流延迟分析,可以得到如下流延迟分析报告(etef0):
对集成式系统的端到端流延迟分析,也需要先对系统进行实例化。
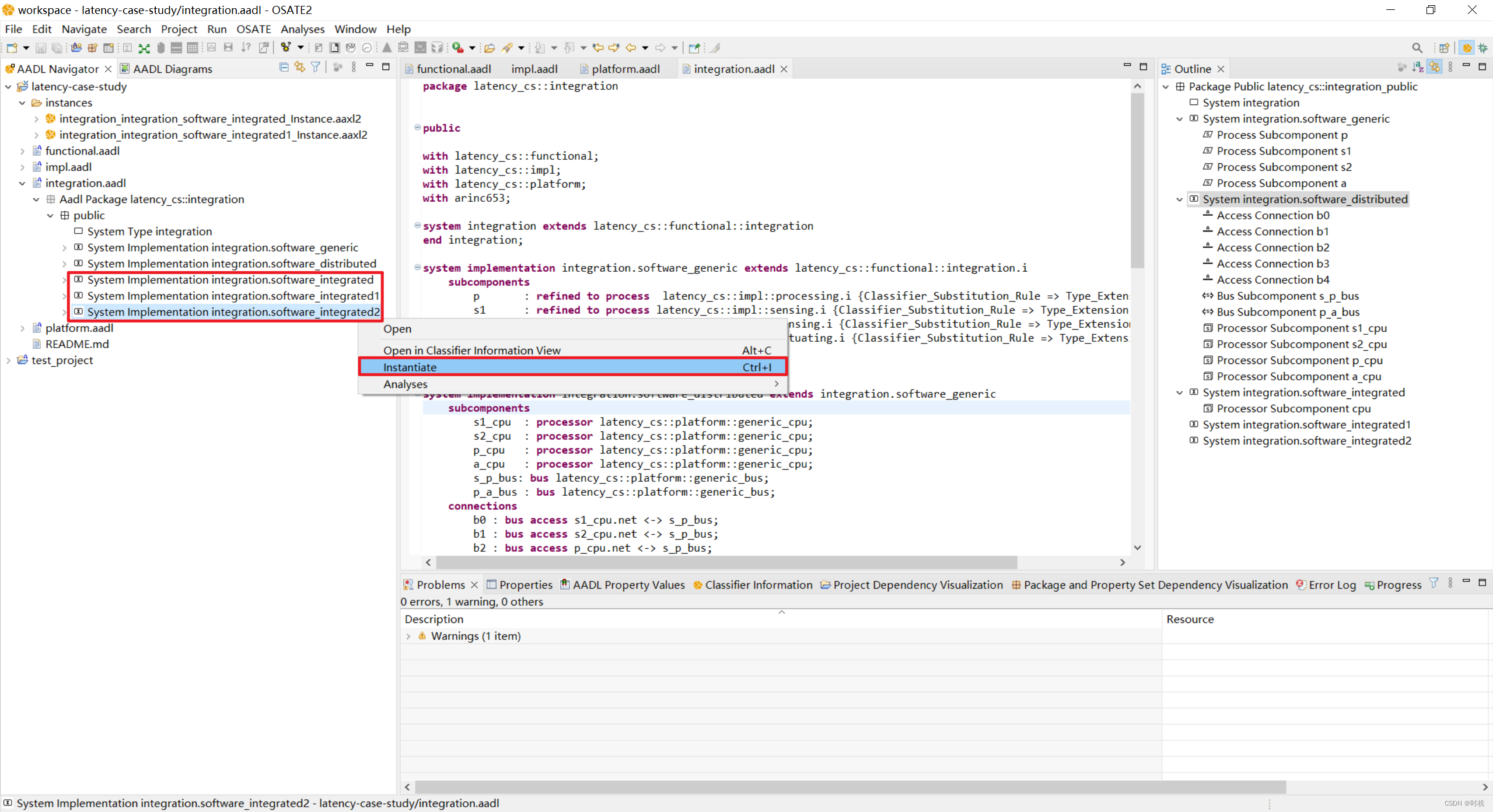
然后根据系统的特性,对其进行端到端流延迟分析。
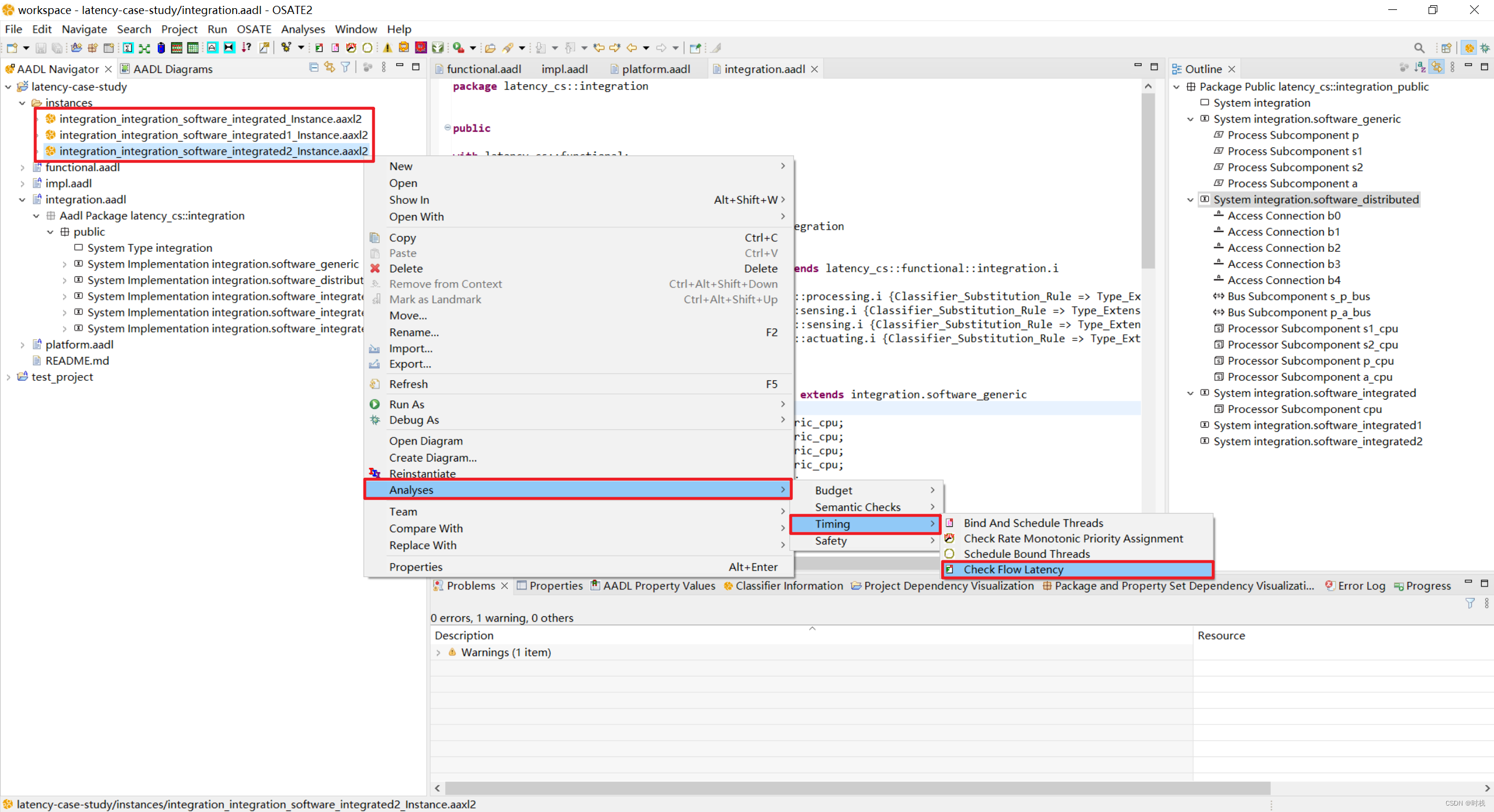
(流延迟分析配置,根据系统的属性进行选择)
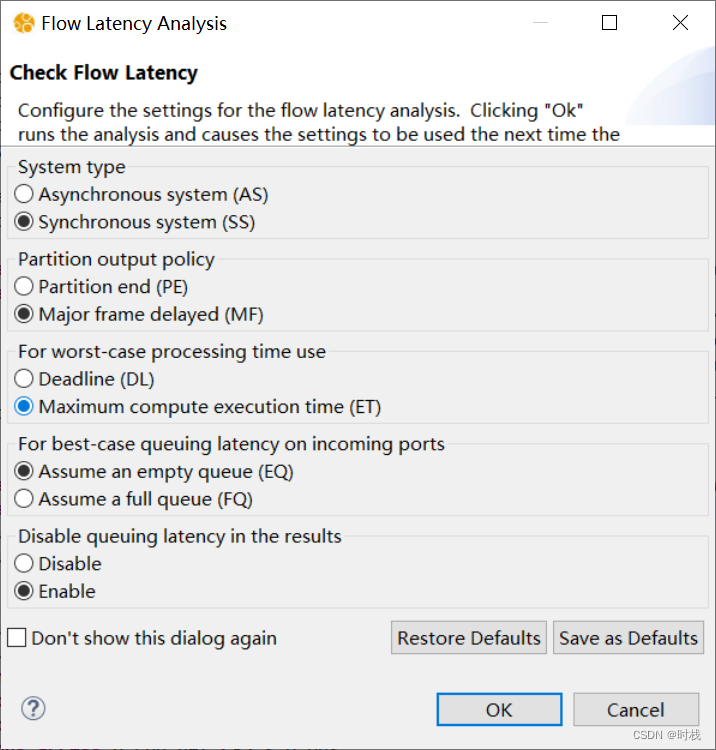
可以得到三个系统实现的流延迟分析报告(每个报告均以三种格式输出)
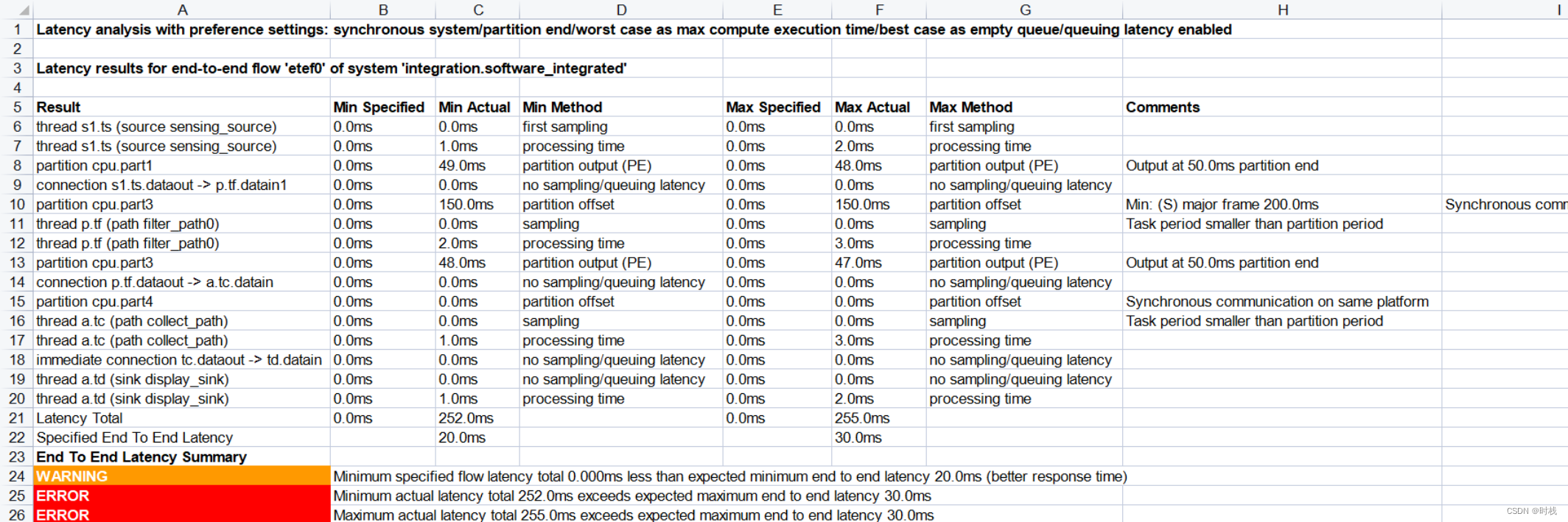
对于集成式系统的第一个实现(etef0):
对于集成式系统的第二个实现(etef0):
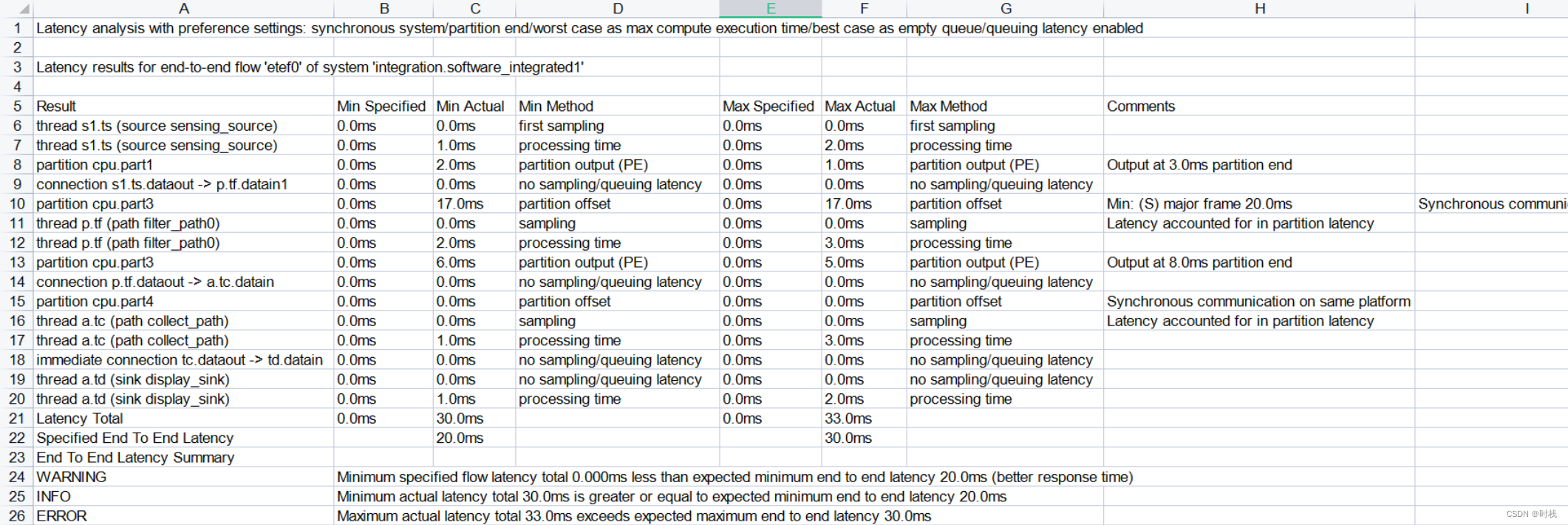
对于集成式系统的第三个实现(etef0):
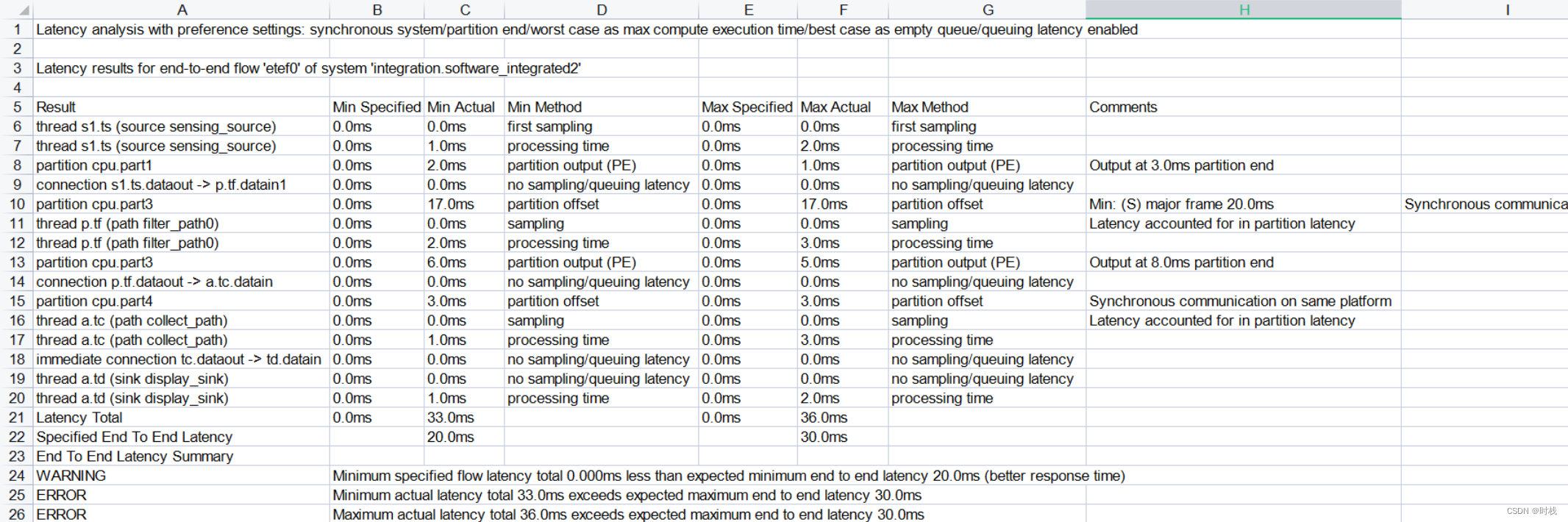
可以看到,不同的系统实现得到了三个不同的流延迟分析结果。三个系统实现的流延迟分析结果中,流延迟的范围分别为:252ms - 255ms、 30ms - 33ms、 33ms - 36ms。
如有不当或错误之处,恳请您的指正,谢谢!!!