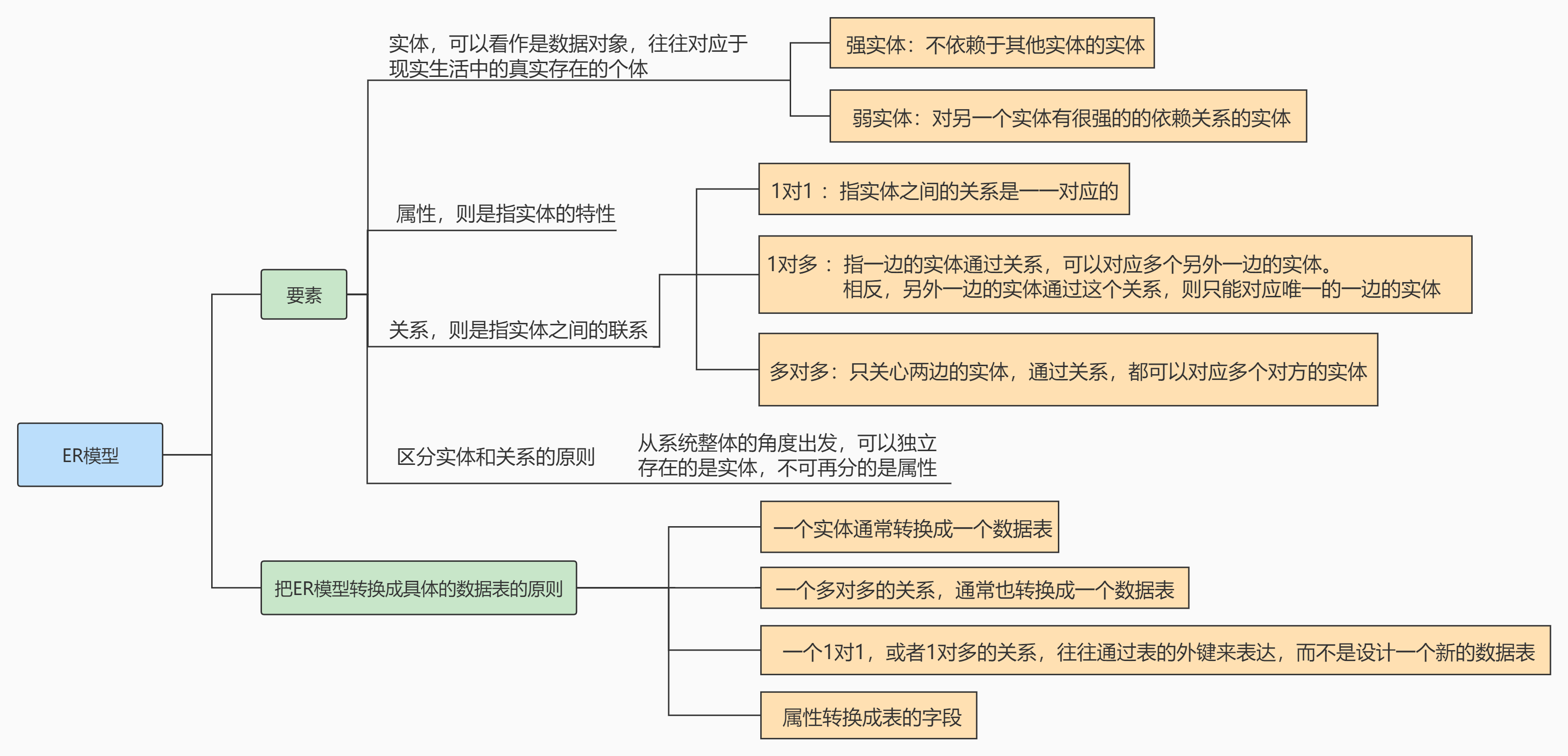
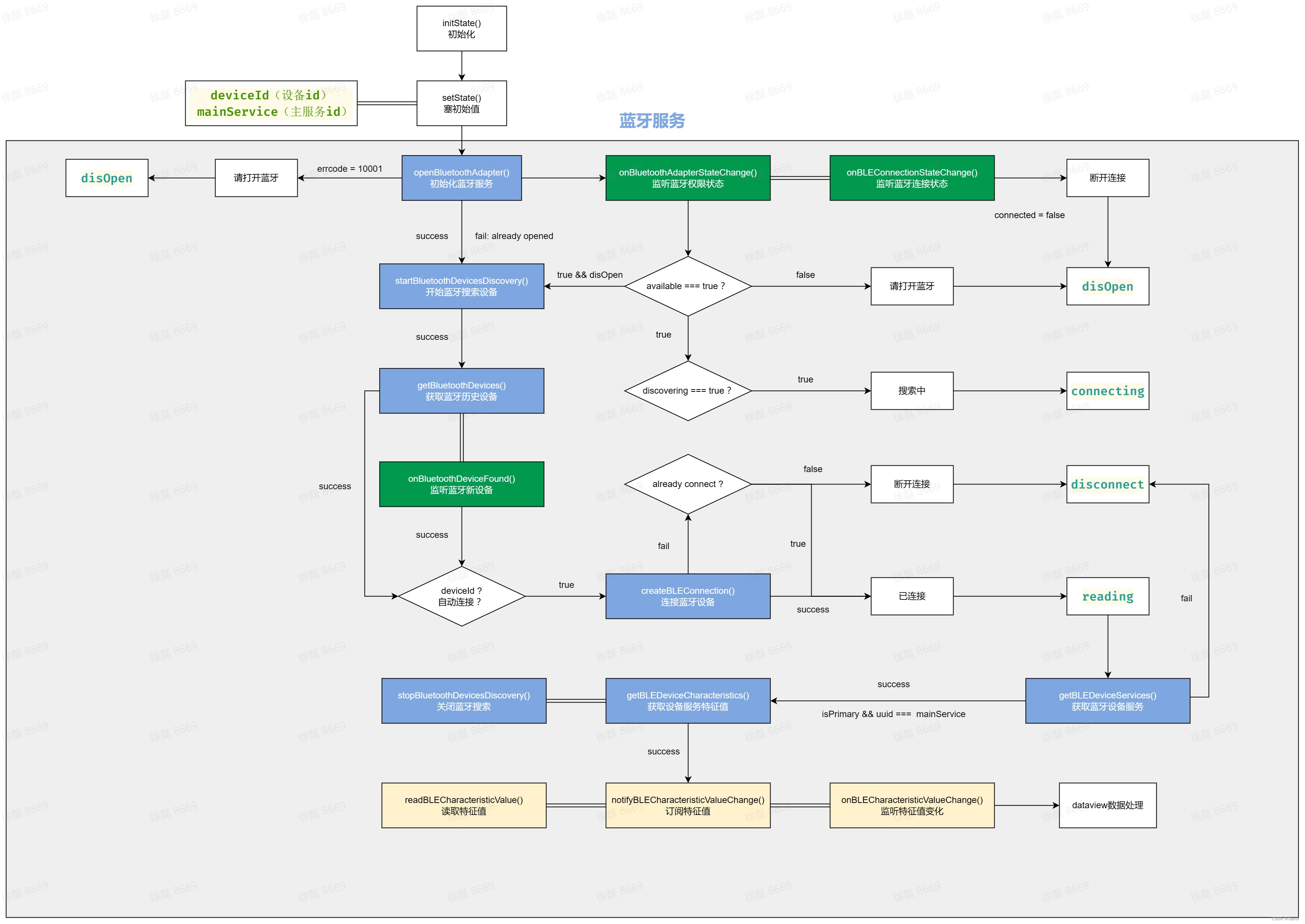
项目来源是GitHub上面刘老师做的一个基于知识医疗图谱的问答机器人,本文主要关注点放在建立知识图谱这一侧。这个项目并且将数据集也开源了放在dict和data文件夹下,让我觉得真的很难得,得给老师一个star!
https://github.com/liuhuanyong/QASystemOnMedicalKG
data_spider.py
首先是数据获取阶段,解读刘老师的爬虫项目。
import urllib.request
import urllib.parse
from lxml import etree
import pymongo
import re
class CrimeSpider:
def __init__(self):
self.conn = pymongo.MongoClient()
self.db = self.conn['medical']
self.col = self.db['data']
'''根据url,请求html'''
def get_html(self, url):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/51.0.2704.63 Safari/537.36'}
req = urllib.request.Request(url=url, headers=headers)
res = urllib.request.urlopen(req)
html = res.read().decode('gbk')
return html
'''url解析'''
def url_parser(self, content):
selector = etree.HTML(content)
urls = ['http://www.anliguan.com' + i for i in selector.xpath('//h2[@class="item-title"]/a/@href')]
return urls
'''测试'''
def spider_main(self):
for page in range(1, 11000):
try:
basic_url = 'http://jib.xywy.com/il_sii/gaishu/%s.htm'%page
cause_url = 'http://jib.xywy.com/il_sii/cause/%s.htm'%page
prevent_url = 'http://jib.xywy.com/il_sii/prevent/%s.htm'%page
symptom_url = 'http://jib.xywy.com/il_sii/symptom/%s.htm'%page
inspect_url = 'http://jib.xywy.com/il_sii/inspect/%s.htm'%page
treat_url = 'http://jib.xywy.com/il_sii/treat/%s.htm'%page
food_url = 'http://jib.xywy.com/il_sii/food/%s.htm'%page
drug_url = 'http://jib.xywy.com/il_sii/drug/%s.htm'%page
data = {}
data['url'] = basic_url
data['basic_info'] = self.basicinfo_spider(basic_url)
data['cause_info'] = self.common_spider(cause_url)
data['prevent_info'] = self.common_spider(prevent_url)
data['symptom_info'] = self.symptom_spider(symptom_url)
data['inspect_info'] = self.inspect_spider(inspect_url)
data['treat_info'] = self.treat_spider(treat_url)
data['food_info'] = self.food_spider(food_url)
data['drug_info'] = self.drug_spider(drug_url)
print(page, basic_url)
self.col.insert(data)
except Exception as e:
print(e, page)
return
'''基本信息解析'''
def basicinfo_spider(self, url):
html = self.get_html(url)
selector = etree.HTML(html)
title = selector.xpath('//title/text()')[0]
category = selector.xpath('//div[@class="wrap mt10 nav-bar"]/a/text()')
desc = selector.xpath('//div[@class="jib-articl-con jib-lh-articl"]/p/text()')
ps = selector.xpath('//div[@class="mt20 articl-know"]/p')
infobox = []
for p in ps:
info = p.xpath('string(.)').replace('\r','').replace('\n','').replace('\xa0', '').replace(' ', '').replace('\t','')
infobox.append(info)
basic_data = {}
basic_data['category'] = category
basic_data['name'] = title.split('的简介')[0]
basic_data['desc'] = desc
basic_data['attributes'] = infobox
return basic_data
'''treat_infobox治疗解析'''
def treat_spider(self, url):
html = self.get_html(url)
selector = etree.HTML(html)
ps = selector.xpath('//div[starts-with(@class,"mt20 articl-know")]/p')
infobox = []
for p in ps:
info = p.xpath('string(.)').replace('\r','').replace('\n','').replace('\xa0', '').replace(' ', '').replace('\t','')
infobox.append(info)
return infobox
'''treat_infobox治疗解析'''
def drug_spider(self, url):
html = self.get_html(url)
selector = etree.HTML(html)
drugs = [i.replace('\n','').replace('\t', '').replace(' ','') for i in selector.xpath('//div[@class="fl drug-pic-rec mr30"]/p/a/text()')]
return drugs
'''food治疗解析'''
def food_spider(self, url):
html = self.get_html(url)
selector = etree.HTML(html)
divs = selector.xpath('//div[@class="diet-img clearfix mt20"]')
try:
food_data = {}
food_data['good'] = divs[0].xpath('./div/p/text()')
food_data['bad'] = divs[1].xpath('./div/p/text()')
food_data['recommand'] = divs[2].xpath('./div/p/text()')
except:
return {}
return food_data
'''症状信息解析'''
def symptom_spider(self, url):
html = self.get_html(url)
selector = etree.HTML(html)
symptoms = selector.xpath('//a[@class="gre" ]/text()')
ps = selector.xpath('//p')
detail = []
for p in ps:
info = p.xpath('string(.)').replace('\r','').replace('\n','').replace('\xa0', '').replace(' ', '').replace('\t','')
detail.append(info)
symptoms_data = {}
symptoms_data['symptoms'] = symptoms
symptoms_data['symptoms_detail'] = detail
return symptoms, detail
'''检查信息解析'''
def inspect_spider(self, url):
html = self.get_html(url)
selector = etree.HTML(html)
inspects = selector.xpath('//li[@class="check-item"]/a/@href')
return inspects
'''通用解析模块'''
def common_spider(self, url):
html = self.get_html(url)
selector = etree.HTML(html)
ps = selector.xpath('//p')
infobox = []
for p in ps:
info = p.xpath('string(.)').replace('\r', '').replace('\n', '').replace('\xa0', '').replace(' ','').replace('\t', '')
if info:
infobox.append(info)
return '\n'.join(infobox)
'''检查项抓取模块'''
def inspect_crawl(self):
for page in range(1, 3685):
try:
url = 'http://jck.xywy.com/jc_%s.html'%page
html = self.get_html(url)
data = {}
data['url']= url
data['html'] = html
self.db['jc'].insert(data)
print(url)
except Exception as e:
print(e)
handler = CrimeSpider()
handler.inspect_crawl()在这请忽略类的名称叫CrimeSpider,这是因为刘老师之前还做了一个完整的和司法案件有关的知识图谱,加上爬虫之间大同小异,改一改就能爬取另外一个网站。对于该爬虫文件我不做过多解读,详细情况可以参照本人另一篇博客。
https://blog.csdn.net/chen_nnn/article/details/122979611
这里我们主要关注一下,刘老师爬取的网站的情况,从代码中可以看出数据的原网站是寻医问药网的疾病百科。
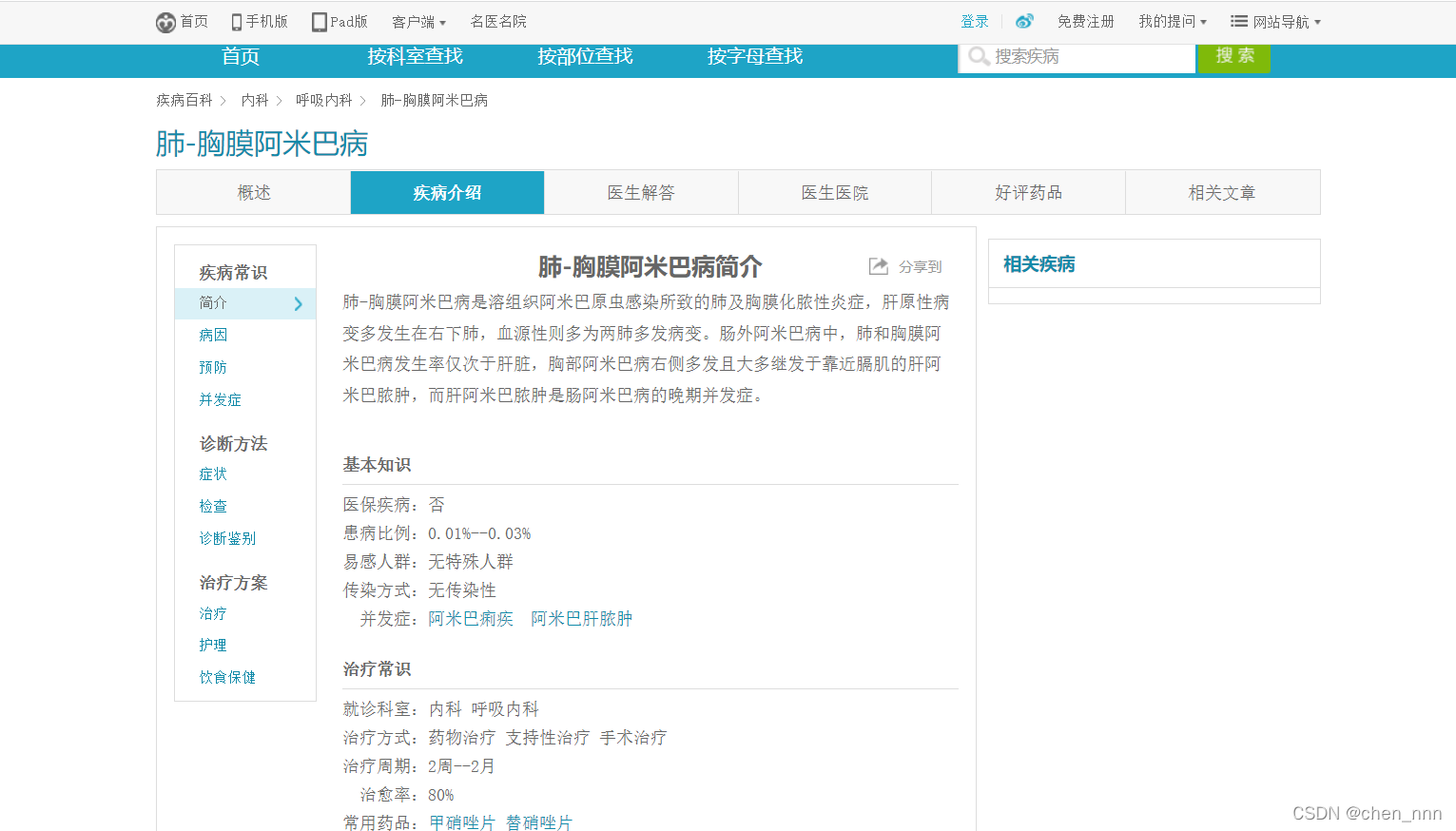
可以看到该网站的疾病百科从HTML的角度来看,结构较为清晰,比较适合爬取,之后的数据处理的工作量可以大大减少。爬虫将所有与该疾病相关的信息都进行爬取和存储,最终一共爬取了8807条和疾病有关的数据,里面的数据存储的结构如下。

build_data.py
该文件是将爬虫爬取到的数据进行规整,实现上图所示的结构。
MedicalGraph类:
import pymongo
from lxml import etree
import os
from max_cut import *
class MedicalGraph:
def __init__(self):
self.conn = pymongo.MongoClient()#'''建立无用户名密码连接'''
cur_dir = '/'.join(os.path.abspath(__file__).split('/')[:-1])
self.db = self.conn['medical']
self.col = self.db['data']
first_words = [i.strip() for i in open(os.path.join(cur_dir, 'first_name.txt'))]
alphabets = ['a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','t','u','v','w','x','y', 'z']
nums = ['1','2','3','4','5','6','7','8','9','0']
self.stop_words = first_words + alphabets + nums
self.key_dict = {
'医保疾病' : 'yibao_status',
"患病比例" : "get_prob",
"易感人群" : "easy_get",
"传染方式" : "get_way",
"就诊科室" : "cure_department",
"治疗方式" : "cure_way",
"治疗周期" : "cure_lasttime",
"治愈率" : "cured_prob",
'药品明细': 'drug_detail',
'药品推荐': 'recommand_drug',
'推荐': 'recommand_eat',
'忌食': 'not_eat',
'宜食': 'do_eat',
'症状': 'symptom',
'检查': 'check',
'成因': 'cause',
'预防措施': 'prevent',
'所属类别': 'category',
'简介': 'desc',
'名称': 'name',
'常用药品' : 'common_drug',
'治疗费用': 'cost_money',
'并发症': 'acompany'
}
self.cuter = CutWords()pymongo是一个方便使用数据库的库函数,首先按照刘老师注释所言,建立一个无用户名密码连接,然后定义一个指针变量,该变量使用os.path.abspath(只有当在脚本中执行的时候,os.path.abspath(__file__)才会起作用,因为该命令是获取的当前执行脚本的完整路径,如果在交互模式或者terminate 终端中运行会报没有__file__这个错误。)获取绝对路径。然后再获取该路径下的first_name.txt中的内容,构建一个first_words变量(os.path.join的作用是:连接两个或更多的路径名组件1.如果各组件名首字母不包含’/’,则函数会自动加上2.如果有一个组件是一个绝对路径,则在它之前的所有组件均会被舍弃3.如果最后一个组件为空,则生成的路径以一个’/’分隔符结尾)。
但是这个first_name.txt里面的内容却并没有在文件中给出,所以我们也不知道是以一个怎样的逻辑,但是我们有了最后构建好的json文件,所以这部分我们就当做背景知识的学习。
collect_medical():
def collect_medical(self):
cates = []
inspects = []
count = 0
for item in self.col.find():
data = {}
basic_info = item['basic_info']
name = basic_info['name']
if not name:
continue
# 基本信息
data['名称'] = name
data['简介'] = '\n'.join(basic_info['desc']).replace('\r\n\t', '').replace('\r\n\n\n','').replace(' ','').replace('\r\n','\n')
category = basic_info['category']
data['所属类别'] = category
cates += category
attributes = basic_info['attributes']
# 成因及预防
data['预防措施'] = item['prevent_info']
data['成因'] = item['cause_info']
# 并发症
data['症状'] = list(set([i for i in item["symptom_info"][0] if i[0] not in self.stop_words]))
for attr in attributes:
attr_pair = attr.split(':')
if len(attr_pair) == 2:
key = attr_pair[0]
value = attr_pair[1]
data[key] = value
# 检查
inspects = item['inspect_info']
jcs = []
for inspect in inspects:
jc_name = self.get_inspect(inspect)
if jc_name:
jcs.append(jc_name)
data['检查'] = jcs
# 食物
food_info = item['food_info']
if food_info:
data['宜食'] = food_info['good']
data['忌食'] = food_info['bad']
data['推荐'] = food_info['recommand']
# 药品
drug_info = item['drug_info']
data['药品推荐'] = list(set([i.split('(')[-1].replace(')','') for i in drug_info]))
data['药品明细'] = drug_info
data_modify = {}
for attr, value in data.items():
attr_en = self.key_dict.get(attr)
if attr_en:
data_modify[attr_en] = value
if attr_en in ['yibao_status', 'get_prob', 'easy_get', 'get_way', "cure_lasttime", "cured_prob"]:
data_modify[attr_en] = value.replace(' ','').replace('\t','')
elif attr_en in ['cure_department', 'cure_way', 'common_drug']:
data_modify[attr_en] = [i for i in value.split(' ') if i]
elif attr_en in ['acompany']:
acompany = [i for i in self.cuter.max_biward_cut(data_modify[attr_en]) if len(i) > 1]
data_modify[attr_en] = acompany
try:
self.db['medical'].insert(data_modify)
count += 1
print(count)
except Exception as e:
print(e)
returnfind() 方法检测字符串中是否包含子字符串 str ,如果指定 beg(开始) 和 end(结束) 范围,则检查是否包含在指定范围内,如果指定范围内如果包含指定索引值,返回的是索引值在字符串中的起始位置。如果不包含索引值,返回-1。item和basic_info都以字典的形式储存数据。
由于在该for循环中,定义了data字典,之后将有关该疾病的各种信息以键值对的形式存储到字典当中。首先是名称、简介信息(需要对其做一些修正然后才能保存)、疾病类别、预防措施、成因、症状。然后对于其他信息格式如XXX:XXX也同样进行存储,在冒号之后还有并列的情况之后处理。对于inspects中包含多个项目,在data['检查']下以列表的形式存储。最后是食物和药品。将这一切都存储到data中去后,在最后我们对data的格式进行最后一次修正,使用之前设定好的英文名。然后将其保存到数据库当中。
get_inspect():
def get_inspect(self, url):
res = self.db['jc'].find_one({'url':url})
if not res:
return ''
else:
return res['name']待续
知识图谱基础代码构建(医疗向)_chen_nnn的博客-CSDN博客_构建知识图谱代码