一、背景
首先需要掌握 Spark DAG、stage、task的相关概念
Spark的job、stage和task的机制论述 - 知乎
task数量和rdd 分区数相关
二、任务慢的原因分析
找到运行时间比较长的stage
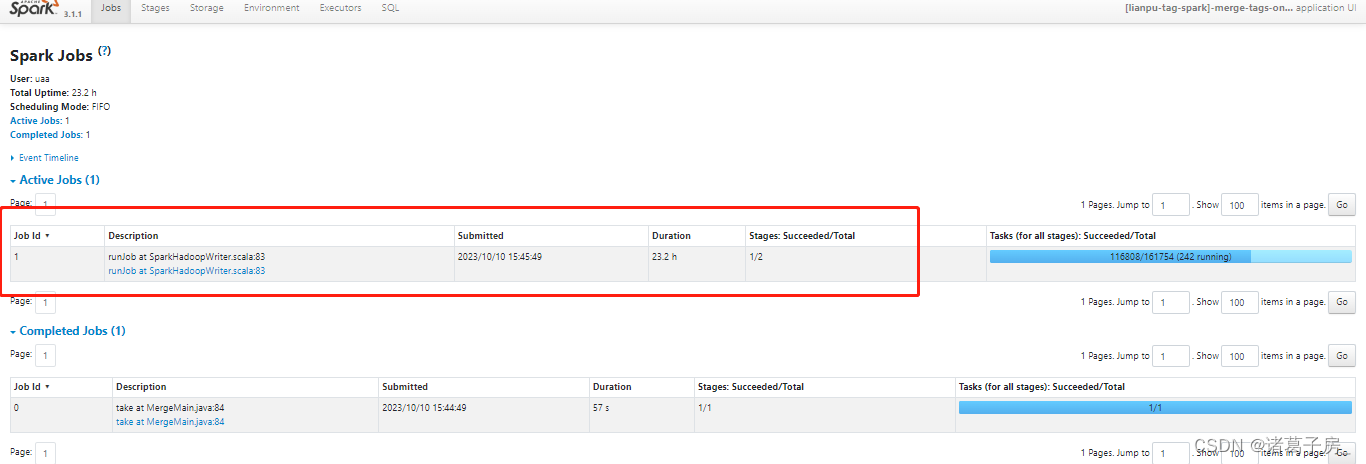
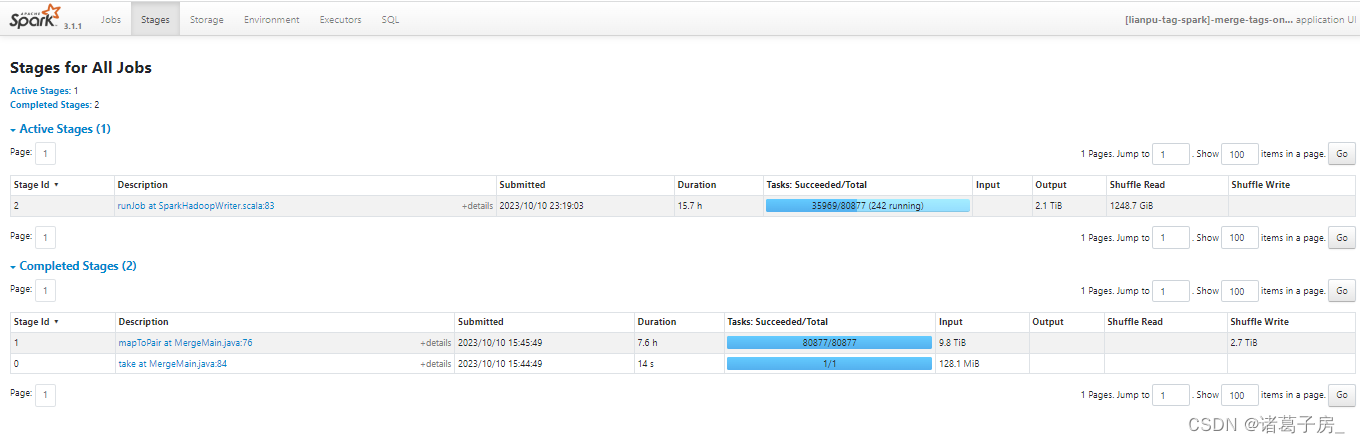
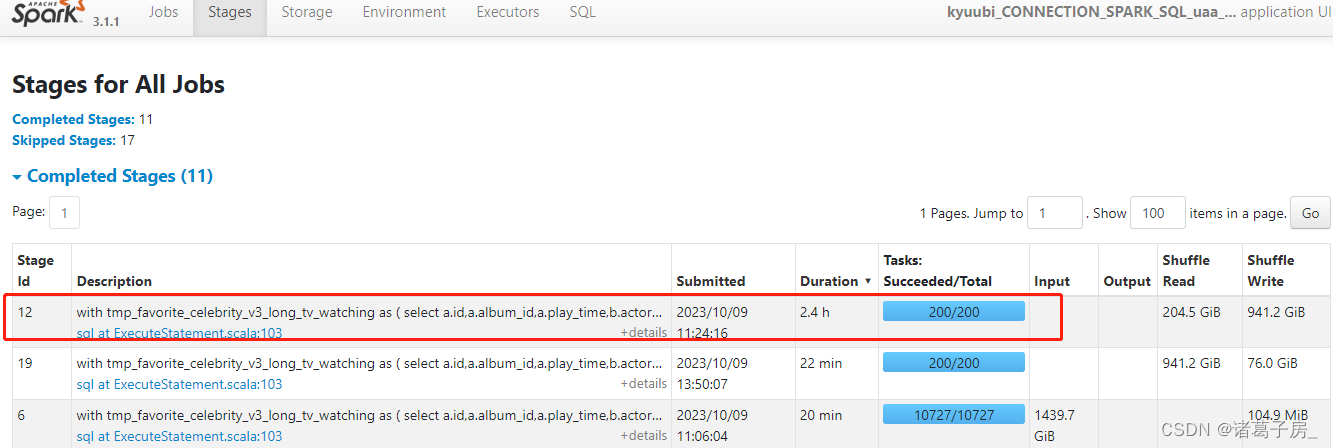
再进去看里面的task
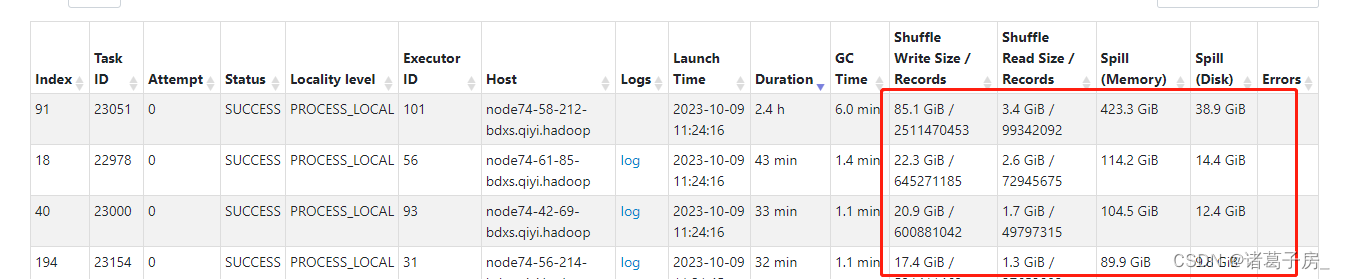
可以看到某个task 读取的数据量明显比其他task 较大。
如果是sql 任务进入到 SQL 页面看到 对应的执行卡在哪里,然后分析,如下图是hash id、actor_name,可以看到是group by 数据有倾斜。
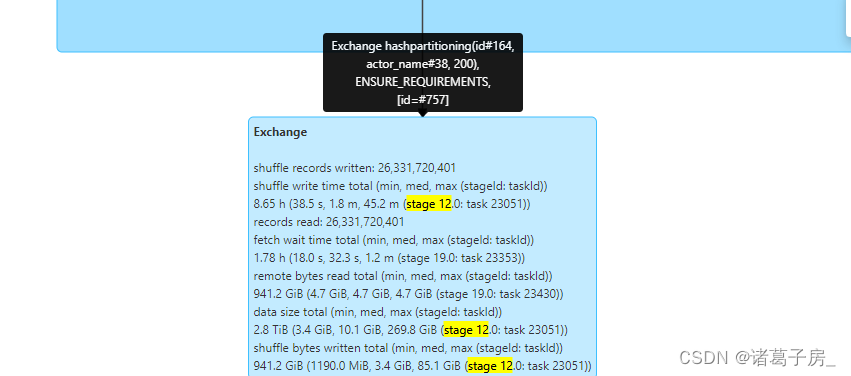
group by 数据倾斜问题,可以参考hive group by 数据倾斜问题同样处理思路。
https://zhugezifang.blog.csdn.net/article/details/127447167





![[GWCTF 2019]你的名字 - SSTI注入(waf绕过)](https://img-blog.csdnimg.cn/f5e36bfa050849ac87ce6dae6cad226c.png)