文章目录
- 1.状态(State)
- 2.动作(Action)
- 3.智能体(Agent)
- 4.策略(Policy)
- 5.奖励(Reward)
- 6.状态转移(State transition)
- 7.智能体与环境交互(Interacts with the environment)
- 8.强化学习随机性的两个来源(Randomness in RL)
- 8.1.动作具有随机性(Actions have randomness)
- 8.2.状态转移具有随机性(State transition have randomness)
1.状态(State)
超级玛丽游戏中,观测到的这一帧画面就是一个 状态(State)。

2.动作(Action)
玛丽做的动作:向左、向右、向上即为 动作(Action)。
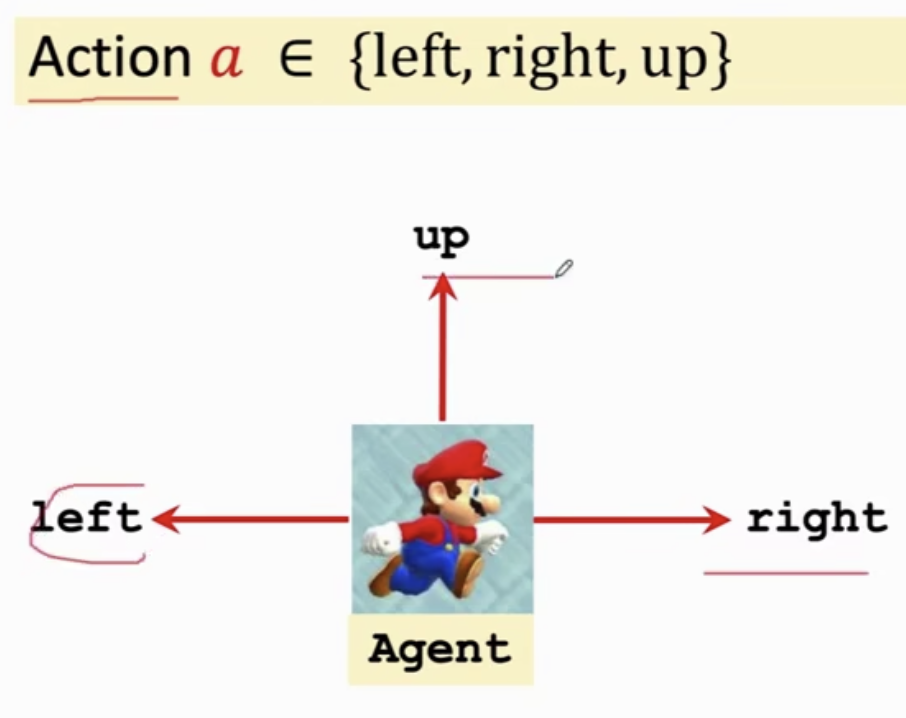
3.智能体(Agent)
动作是由谁做的,谁就是 智能体(Agent)。自动驾驶中,汽车就是智能体;机器人控制中,机器人就是智能体;超级玛丽游戏中,玛丽就是智能体。
4.策略(Policy)
策略( Policy
π
\pi
π)的含义就是,根据观测到的状态,做出动作的方案,
π
(
a
∣
s
)
\pi(a|s)
π(a∣s) 的含义是在状态
s
s
s 是采取动作
a
a
a 的概率密度函数PDF。

5.奖励(Reward)
强化学习的目标就是尽可能的获得更多的 奖励(Reward)。

6.状态转移(State transition)
当智能体做出一个动作,状态会发生变化(从旧的状态变成新的状态)。我们就可以说状态发生的转移。状态转移可以是确定的,也可以是随机的。
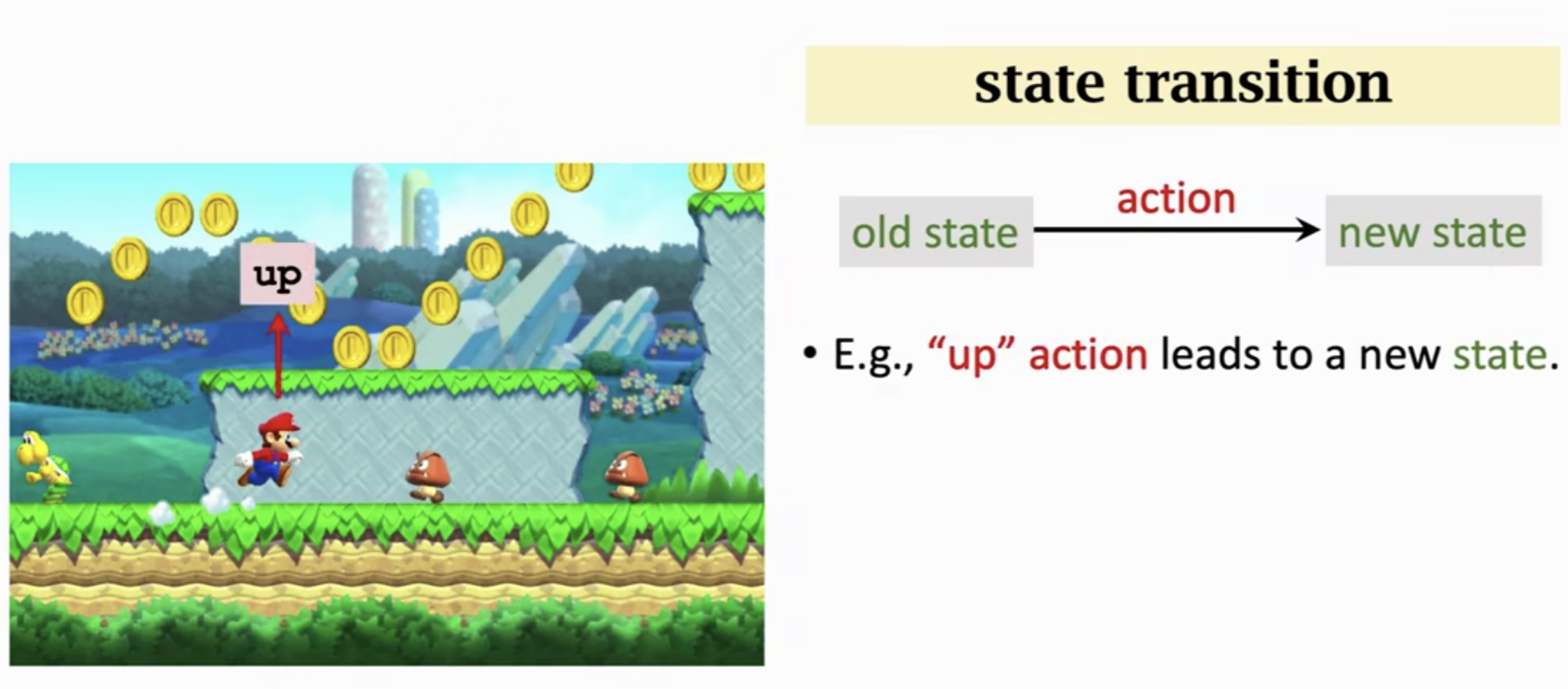
状态转移函数
p
(
s
′
∣
s
,
a
)
p(s' | s, a)
p(s′∣s,a) 的公式:
p ( s ′ ∣ s , a ) = P ( S ′ = s ′ ∣ S = s , A = a ) p(s' | s, a)=\mathbb{P}(S' = s' | S=s, A=a) p(s′∣s,a)=P(S′=s′∣S=s,A=a)
含义为: p ( s ′ ∣ s , a ) p(s' | s, a) p(s′∣s,a) 表示在状态 s s s 时,采取动作 a a a ,跳转到新的状态 s ′ s' s′ 的概率。
7.智能体与环境交互(Interacts with the environment)
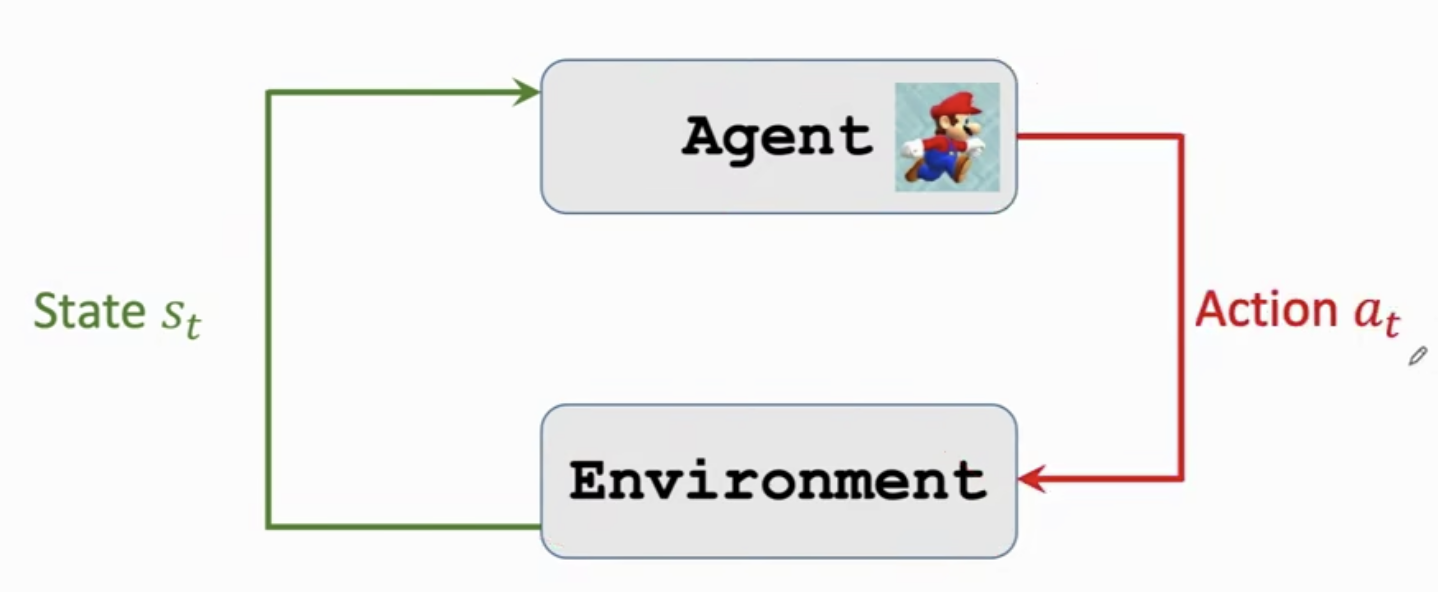
步骤一: 智能体观测到环境的状态
s
t
s_t
st,然后做出动作
a
t
a_t
at
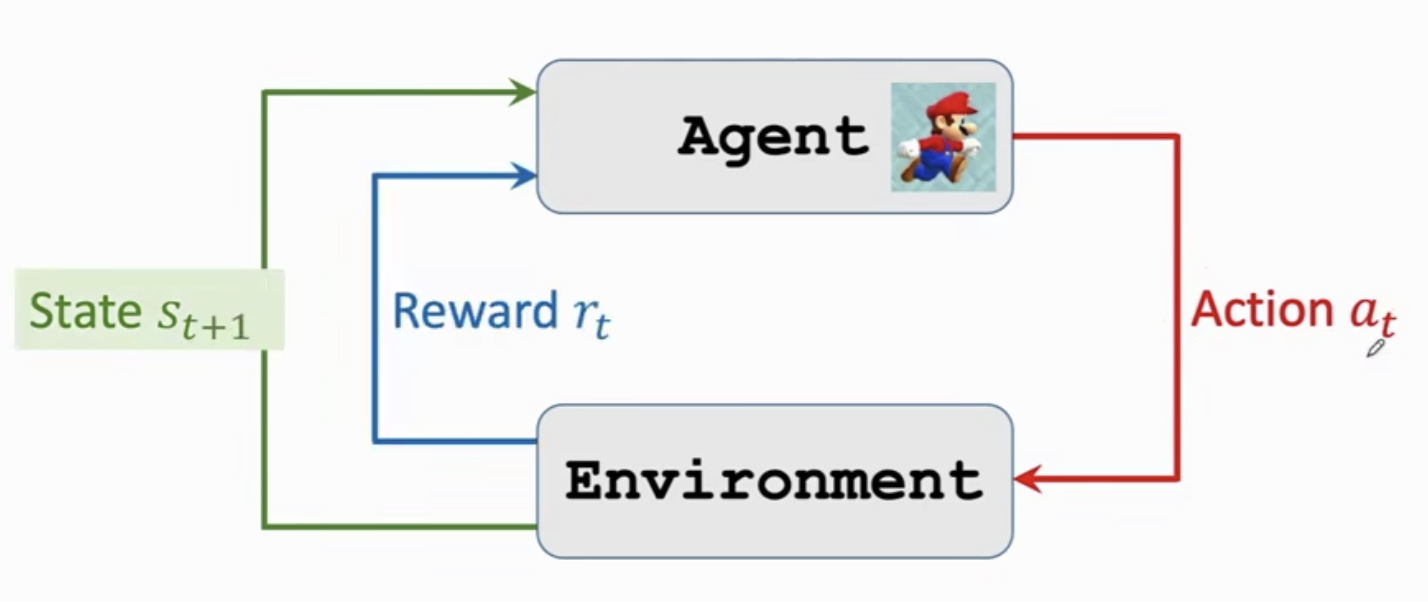
步骤二: 由于智能体做出了动作
a
t
a_t
at,环境的状态发生了变化,变成了
s
t
+
1
s_{t+1}
st+1;同时由于智能体做出的动作
a
t
a_t
at, 获得了一个奖励
r
t
r_t
rt。
8.强化学习随机性的两个来源(Randomness in RL)
8.1.动作具有随机性(Actions have randomness)

8.2.状态转移具有随机性(State transition have randomness)