方案简介
HER (Hindsight Experience Replay) - 2017年
思想
HER(Hindsight Experience Replay)是一种特别设计用于解决稀疏奖励问题的强化学习算法。它主要用于那些具有高度稀疏奖励和延迟奖励的任务,特别是在连续动作空间中,如机械臂抓取、路径规划等。
工作原理
-
经验回放:HER在经验回放(Experience Replay)的基础上进行了扩展。经验回放是一种将过去的经验(状态、动作、奖励等)存储在一个回放缓冲区(Replay Buffer)中,以供后续训练的方法。 -
目标重标定:在每个回合结束后,HER会重新解释该回合中智能体的行为,将实际到达的状态作为新的目标,并据此重新计算奖励。 -
多样性:通过这种方式,HER实际上生成了多种不同目标下的经验,增加了训练样本的多样性,从而提高了样本效率。
适用范围
-
具有明确目标状态的任务(例如,机器人抓取、路径规划等)。 -
高度稀疏和延迟奖励的任务。 -
连续动作空间。
不适用范围
-
离散状态和动作空间
HER 主要设计用于连续状态空间,并且最有效的应用通常发生在这样的环境中。在离散状态和动作空间中,HER 可能不是最佳选择,因为在这些设置下其他方法(如表格学习或模型搜索)可能更有效。
2. 无明确目标的任务
HER 主要用于具有明确目标的任务,这些任务通常有一个状态或状态子集作为目标。对于没有明确目标的任务(比如,不是到达某个特定状态,而是最大化某种度量,如在平衡车问题中维持平衡),HER 可能不适用。
3. 完全观察不到的环境
在一些问题中,你可能无法观察到足够的信息来明确地定义一个“已经实现的目标”。在这些情况下,使用 HER 可能会很困难。
4. 高计算复杂性
HER 通常需要存储额外的转换和进行额外的学习步骤,这可能会增加算法的计算复杂性。对于计算资源有限的应用,这可能是一个问题。
5. 非稀疏奖励问题
虽然 HER 可以在非稀疏奖励设置下使用,但它可能不是最有效的解决方案,因为其他方法(如基于值的方法或策略梯度方法)可能更适合这种类型的问题。
6. 需要细致调优
根据问题的特性,HER 的有效性可能会受到如何采样“实现的目标”的影响。这可能需要进行大量的实验和调优,才能找到最有效的方式来使用 HER。
总体而言,尽管 HER 是一个非常有用的工具,但在选择是否使用它之前,最好先仔细考虑问题的特性和需求。
举例:在Atari游戏中的应用
-
不适用性:由于Atari游戏通常没有清晰定义的“目标状态”,HER在这类游戏中不太适用。HER更多地应用于那些有明确目标状态的任务,如机器人学习。 -
离散动作空间:Atari游戏大多在离散的动作空间中运行,而HER通常在连续的动作空间中表现得更好。
实现步骤
-
执行一个回合,收集 ** (s, a, r, s', g)**(状态、动作、奖励、新状态、目标)。 -
存储这些经验到经验回放缓冲区。 -
在回合结束后,选取一些实际达到的状态作为新的目标 ** g'**。 -
用新的目标 g'重新计算奖励,并生成新的经验 **(s, a, r', s', g')**。 -
将新生成的经验也存储到经验回放缓冲区。
目标如何设定
-
环境本身:像“抓取”或“推动”这样的任务通常有明确的目标状态,比如机械臂需要抓住某个物体。这些目标通常是由环境定义的。 -
任务定义:在多任务环境中,目标可能是动态分配的。例如,一个机器人可能有多个可选择的目标位置。 -
子任务:在分层或多任务学习中,子任务本身可能有各自的目标。 -
人为指定:在一些应用场景中,你可能需要人为地定义目标,尤其是在环境不直接提供目标的情况下。
ICM (Intrinsic Curiosity Module) - 2017年
思想
ICM 旨在通过生成内在奖励来促进智能体(agent)的探索行为。这些内在奖励是基于智能体对环境的模型(或预测)的不确定性或误差来计算的。简而言之,如果智能体无法准确地预测其动作的结果,那么该动作会得到高的内在奖励,以鼓励智能体进一步探索。
工作原理
ICM 主要由两部分组成:
前向模型(Forward Model)
-
作用:
-
状态预测:前向模型尝试从当前状态和执行的动作预测下一个状态(或其特征表示)。
-
内在奖励生成:当预测与实际观察到的下一个状态有误差时,该误差用作内在奖励。预测越不准确,误差越大,意味着该状态-动作对更值得探索,因此生成更高的内在奖励。
-
-
实际应用:
-
在环境中稀缺或完全没有外部奖励的情况下,前向模型的预测误差为代理提供了有用的探索信号。
-
逆向模型(Inverse Model)
-
作用: -
动作预测:逆向模型从当前状态 和下一个状态 预测应执行的动作 。 -
特征学习:通过逆向模型的训练,模型学习抽取对任务有用的状态特征,这有助于前向模型进行更有效的预测。
-
-
实际应用: -
逆向模型有助于学习状态表示,这是有效预测和决策所必需的。 -
两个模型合作生成内在奖励,并有助于在稀疏奖励和高度探索需求的环境中进行有效学习。逆向模型提供有关哪些状态特征对动作选择重要的信息,而前向模型使用这些特征以及执行的动作来生成内在奖励,从而推动探索。
-
适用范围
-
高维、连续状态空间 -
稀疏奖励问题 -
复杂、非明确目标的任务
不适用范围
-
确定性环境
在确定性(或接近确定性)环境中,模型很快就能准确预测下一个状态,从而导致内在奖励降为零或接近零。这在实际应用中可能导致不足够的探索。
2. 资源消耗
ICM 需要训练额外的环境模型并进行在线预测,这会增加计算成本。在资源受限的设置中,这可能是一个问题。
3. 无法处理多模态结果
对于一个给定的状态和动作,如果有多种可能的下一个状态(即,多模态分布),基于误差的内在奖励可能不是最佳选择,因为模型可能会对其中一个模态进行过度拟合。
4. 高噪音环境
在高噪音环境中,即使模型能很好地捕获环境的一般动态,预测误差也可能会很高。这可能会导致不合适或不相关的探索。
5. 奖励稀疏但明确的目标
对于具有明确目标和奖励稀疏性但不需要复杂探索策略的任务,使用 ICM 可能是过度设计。在这种情况下,简单的基于目标的方法或者传统的强化学习方法可能更有效。
6. 需要细致的调优
ICM 的效果可能会受到超参数(例如,内在与外在奖励的权重、模型结构等)的影响,需要花费大量时间进行调优。
7. 对于无模型任务不是最优
ICM 需要建立一个环境模型。对于一些无模型或者模型不易获取的复杂任务,这可能是一个限制。
总的来说,在选择使用 ICM 之前,最好先考虑任务和环境的具体需求和特性。这将帮助你判断 ICM 是否适用,以及如何可能需要调整或改进它以适应特定的应用场景。
实现步骤
-
模型初始化:初始化策略网络和环境模型网络。 -
数据收集:运行智能体以收集经验(状态、动作、下一状态)。 -
模型预测:使用当前的环境模型来预测下一个状态。 -
计算内在奖励:内在奖励是预测下一状态和实际下一状态之间的差异。 -
策略更新:用内在奖励和外在奖励(如果有的话)来更新策略。 -
模型更新:用收集的经验来更新环境模型。
效果
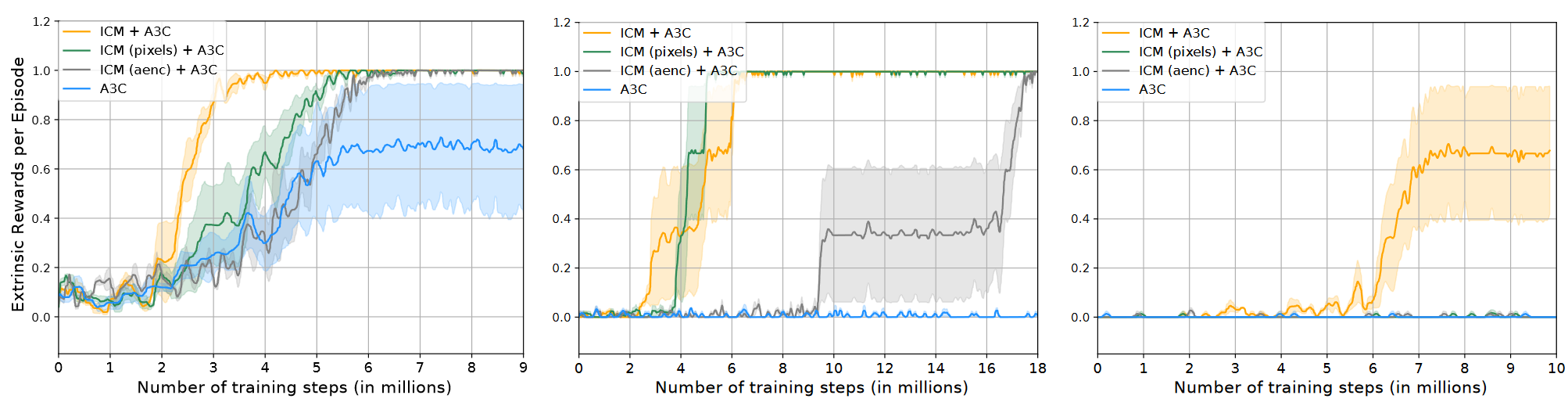
RND (Random Network Distillation) - 2018年
思想:
RND 也是用于生成内在奖励的算法,但其机制与 ICM 不同。RND 通过训练一个固定的随机网络(即“目标网络”)和一个可训练的网络(即“预测网络”),并使用两者之间的输出差异作为内在奖励。
工作原理:
-
目标网络与预测网络:初始化两个相同结构的网络。其中一个(目标网络)的权重是随机初始化并固定不变的,而另一个(预测网络)是可训练的。
-
内在奖励生成:在与环境交互过程中,智能体观察到的状态(或状态的某种特征)被送入这两个网络。内在奖励计算为两个网络输出之间的差异,通常使用平方误差。
-
预测网络更新:与环境交互产生的数据用于更新预测网络,以减小与目标网络之间的输出差异。
-
策略更新:使用内在奖励(可能与外在奖励一起)来更新智能体的策略。
适用范围:
-
奖励稀疏环境:当外在奖励非常少或者完全没有时。 -
高维和连续状态空间:适用于处理复杂的状态空间。 -
长期任务:适用于需要长期探索的任务。
不适用范围:
-
确定性或低复杂性环境:在这类环境中,内在奖励可能不够有用。 -
计算资源有限:RND 需要额外的网络和计算,可能不适用于计算资源有限的情况。 -
需要精确任务定义的环境:RND 鼓励探索,但可能不是最优的解决方案,如果任务有明确的目标或限制。
实现步骤:
-
初始化:创建并初始化目标网络和预测网络。 -
与环境交互:智能体与环境进行交互,收集状态和外在奖励。 -
计算内在奖励:使用目标网络和预测网络的输出来计算内在奖励。 -
更新预测网络:使用最新的数据来更新预测网络。 -
策略更新:根据内在奖励(和外在奖励)来更新智能体的策略。
通过这样的流程,RND 能够有效地驱动智能体在各种各样的环境中进行探索。
Go-Explore算法 - 2019年
思想
Go-Explore 的核心思想是解决探索与利用(exploration-exploitation)问题的一种新方法。该算法分为两个主要阶段:首先是一个“去探索(Go)”阶段,智能体被鼓励去探索新的、未访问过的状态;其次是一个“探究(Explore)”阶段,在这里,智能体从之前标记为“有趣”的状态出发进行更深一层的探索。
工作原理
-
Cell Representation: 将高维状态空间分解为低维的“单元(cells)”,通常通过一种哈希函数实现。 -
Go Phase: 智能体前往之前标记为有趣或未访问的单元。 -
Explore Phase: 从这些有趣的单元出发,智能体尝试执行随机动作以探索更多的状态空间。 -
Trajectory Collection: 记录到达有趣状态的轨迹。 -
Policy Improvement: 使用这些轨迹进行策略改进,通常使用像PPO或A3C这样的强化学习算法。
适用范围
Go-Explore 在处理具有高度稀疏奖励和大状态空间的环境方面表现出色。例如,在Atari游戏如Montezuma's Revenge中,它能够获得迄今为止最高的得分。
不适用范围
-
Stochastic Environments: 在高度随机或噪音很大的环境中,Go-Explore的效果可能会下降。 -
Real-Time Decision Making: 由于需要存储和回放轨迹,Go-Explore可能不适用于需要实时决策的应用。 -
Simple Tasks: 对于奖励信号丰富或状态空间小的任务,Go-Explore 可能是过度复杂的。
实现步骤
-
初始化单元格数据库和轨迹缓存。 -
使用随机策略进行初步探索,存储达到的单元和轨迹。 -
Go阶段: 从数据库中选择一个单元,使用保存的轨迹重新访问该单元。 -
Explore阶段: 从选定的单元开始,执行随机动作进行探索,更新单元数据库和轨迹缓存。 -
重复步骤3和4直到满足某种停止准则(例如,达到预定的迭代次数或得分)。 -
使用收集的轨迹进行策略优化。
Never Give Up (NGU) 算法 - 2019年
思想
NGU算法主要目标是解决强化学习中稀疏和非稳态奖励环境下的探索问题。其核心思想是通过使用一组内在奖励机制,以及自适应地调整这些机制,来鼓励智能体更加全面和高效地探索环境。
工作原理
-
多奖励信号: NGU使用一组内在奖励信号,而不仅仅是单一的奖励。 -
自适应调整: 通过观察智能体与环境的互动,NGU能自适应地调整各个内在奖励的权重。 -
时间尺度: 通过在不同时间尺度上观察奖励,算法能更好地理解短期和长期目标之间的关系。
适用范围
NGU在处理具有稀疏、延迟、或者非稳态奖励的复杂环境中表现良好。
不适用范围
-
简单任务: 在奖励信号丰富或者任务简单的环境中,NGU的复杂性可能是不必要的。 -
计算成本: 由于需要维护和计算多个内在奖励,这增加了算法的计算负担。
实现步骤
-
初始化一组内在奖励机制和其对应的权重。 -
在每个时间步,观察外部奖励以及内在奖励。 -
根据观察到的奖励和当前状态,用强化学习算法(如Q-learning或PPO)更新策略。 -
自适应地调整内在奖励的权重。 -
根据新的策略执行动作。 -
重复步骤2-5直至满足某个终止条件。
ICM与RND的对比
-
计算复杂性:ICM通常比RND更为计算密集,因为它需要训练一个用于状态转换预测的前向模型。 -
鲁棒性和泛化能力:RND通常被认为在面对更广泛或更复杂的状态空间时有更好的泛化能力。 -
可解释性:ICM的内在奖励基于模型的预测误差,这在某些情况下可能更容易解释。 -
环境依赖性:ICM在某些确定性环境中可能失效,因为一旦模型学会了准确预测,内在奖励就会消失。而RND则通常在这类环境中表现得更加稳健。 -
样本效率:通常,两者都比使用纯外在奖励更为样本高效,但具体哪个更高效可能取决于任务和实现细节。 -
实验结果:在一些标准测试环境(如Atari或Mujoco)中,两者都已被证明可以有效地解决稀疏奖励问题,但并没有一致的结论来证明哪一个算法在所有情况下都明显优于另一个。
本文由 mdnice 多平台发布