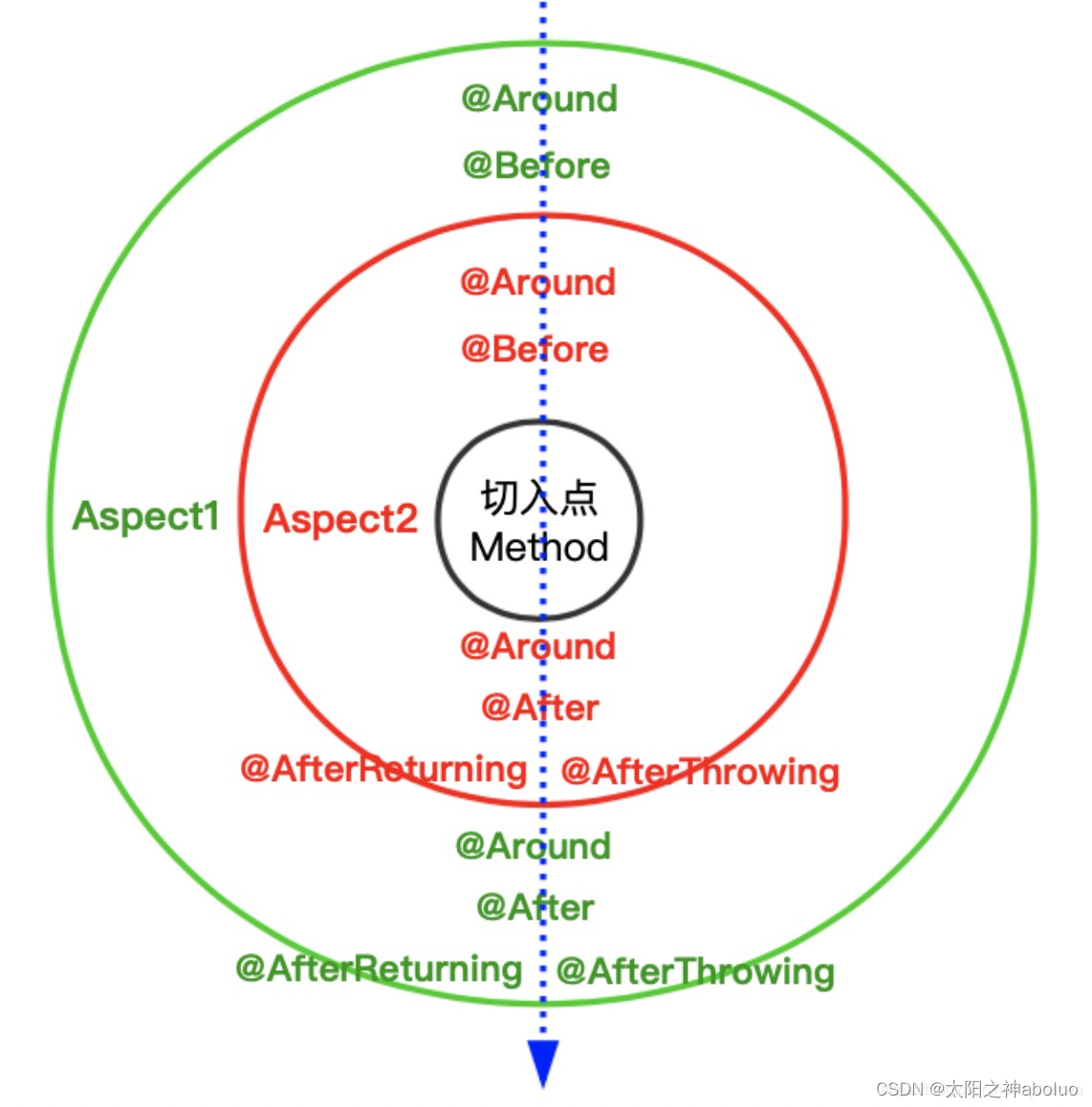
由于百川智能的内测模型是baichuan-53B,尽管模型大小不一致,为了方便,我们仍然选择百川智能baichuan-53B与ChatGLM-6B内测结果进行对比,其中ChatGLM-6B的结果来自https://github.com/THUDM/ChatGLM-6B,假设ChatGLM-6B的结果是可靠的,那么为了公平,百川智能baichuan-53B也使用这些Prompt进行测试。
百川智能baichuan-53B界面

内测地址:https://chat.baichuan-ai.com/home
测试内容从自我认知、提纲写作、文案写作、邮件写作助手、信息抽取、角色扮演、评论比较和旅游向导这八个角度进行测试对比。
核心结论:
1、关于自我认知方面,百川智能baichuan-53B比ChatGLM-6B内容更多一些,优点和缺点条理比较清晰;
2、在提纲写作方面,百川智能baichuan-53B没有准确理解ChatGLM的含义,而是找了一个语义相似的ChatGPT为关键词进行提纲撰写的;
3、在文案写作方面,两个模型都表现不错,百川智能baichuan-53B生成的10个新闻都带有双引号,猜测可能和训练数据有关;
4、在写邮件方面,两个模型都表现不错;
5、在信息抽取方面,百川智能baichuan-53B比ChatGLM-6B略胜一筹,提取的实体相对长一些;
6、在角色扮演方面,两个模型都表现不错,百川智能baichuan-53B在“汪!”的前面增加了前缀“【二哈的回应】”,猜测可能和训练数据有关;
7、在主观评论方面,两个都表现的比较理智和客观,没有模型个人观点,百川智能baichuan-53B条理更清晰一些;
8、在旅游向导方面,两个模型表现都不错
自我认知
ChatGLM-6B
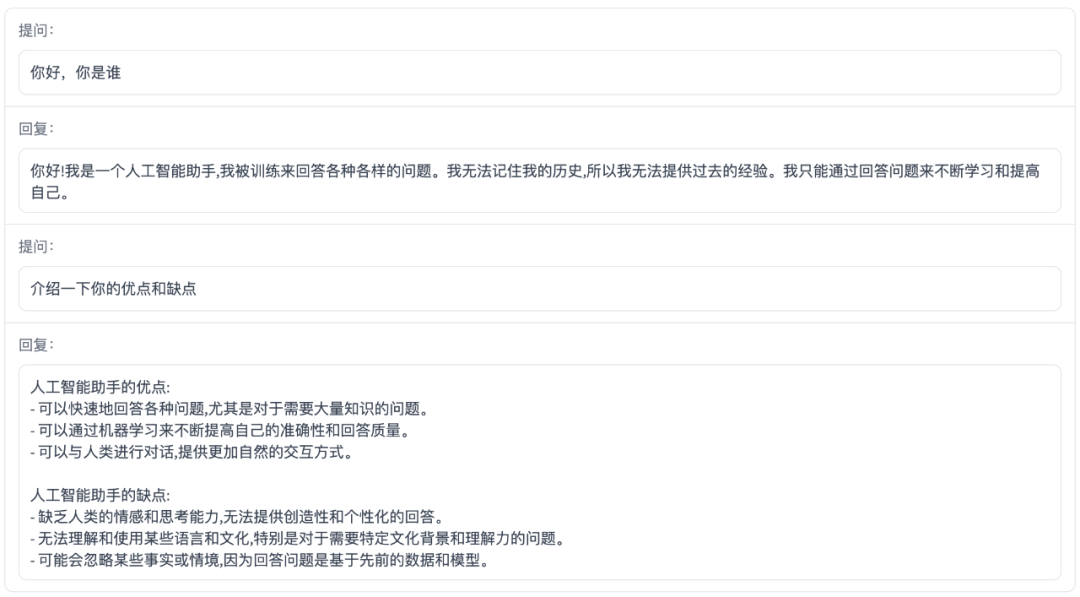
百川智能baichuan-53B

提纲写作
ChatGLM-6B
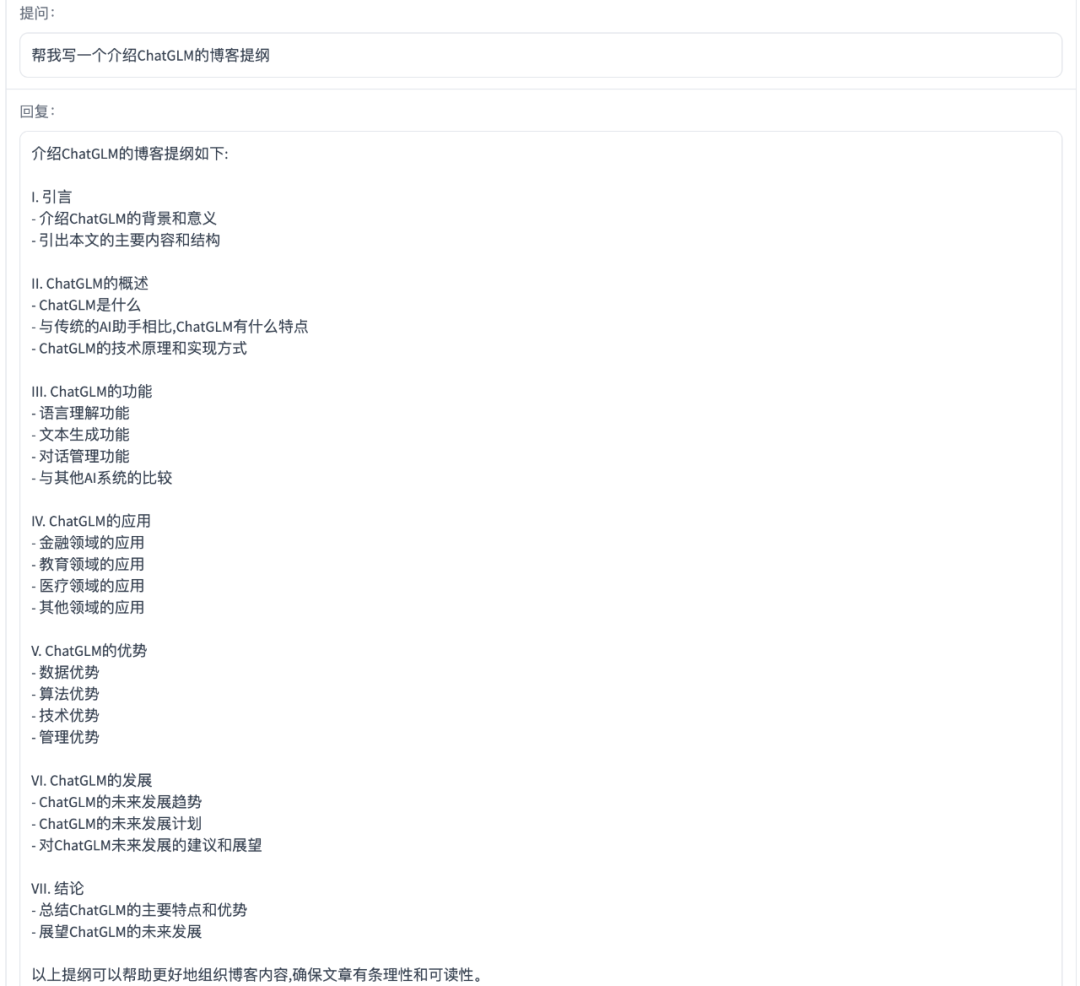
百川智能baichuan-53B


文案写作
ChatGLM-6B
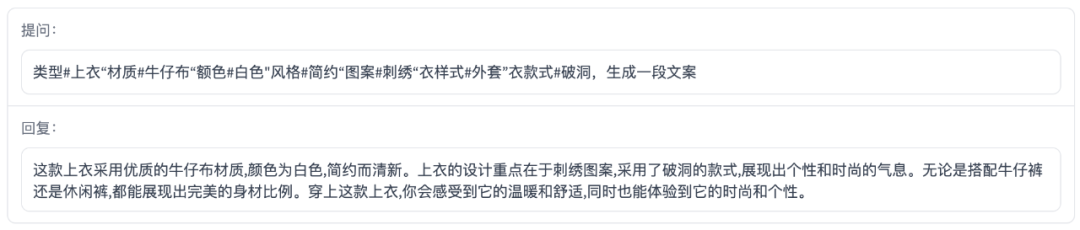

百川智能baichuan-53B


邮件写作助手
ChatGLM-6B

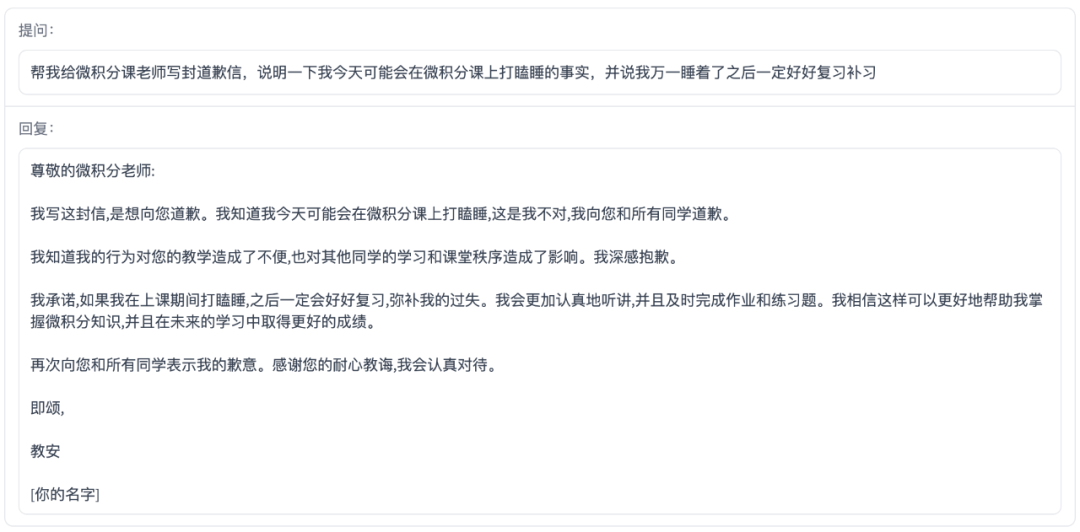
百川智能baichuan-53B


信息抽取
ChatGLM-6B
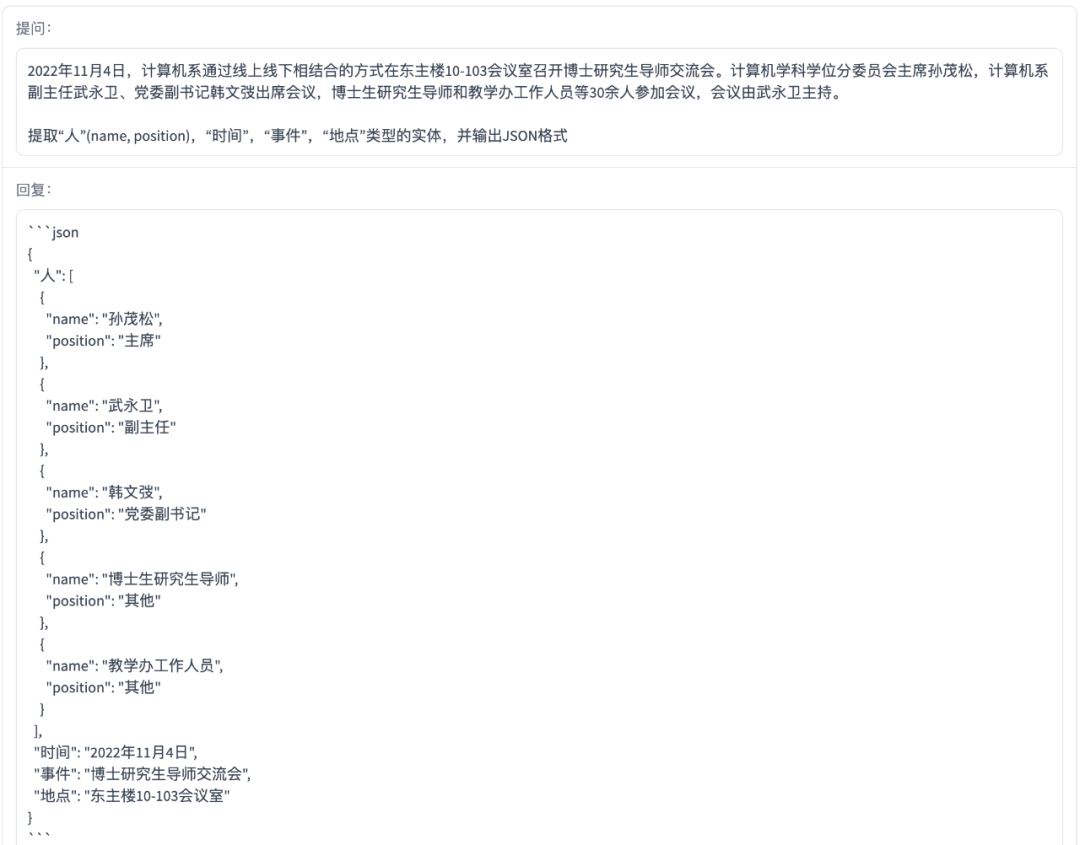
百川智能baichuan-53B

角色扮演
ChatGLM-6B

百川智能baichuan-53B

评论比较
ChatGLM-6B

百川智能baichuan-53B

旅游向导
ChatGLM-6B

百川智能baichuan-53B