1.光伏电池缺陷数据集介绍
背景:太阳能作为一种极具吸引力的替代电力能源,太阳能光伏电池(即光伏电池)是太阳能发电系统的基础,一般情况下,电池中的各类缺陷会直接影响到光伏电池的光电转化效率和使用寿命。太阳能电池片组件作为太阳能开发利用的主要载体,其质量保证包括很多环节,其中,太阳能电池片的焊接则是其中最为关键的一环,电池片的焊接质量直接会影响组件性能。为了保证焊接质量,对太阳能电池片的焊前检测也是必不可少的。
数据集大小:原始219张,数据扩展2倍至657张,类别classes = ["crackle","invalid"],按照8:1:1进行数据集随机生成。
1.1数据集划分
通过split_train_val.py得到trainval.txt、val.txt、test.txt
# coding:utf-8
import os
import random
import argparse
parser = argparse.ArgumentParser()
#xml文件的地址,根据自己的数据进行修改 xml一般存放在Annotations下
parser.add_argument('--xml_path', default='Annotations', type=str, help='input xml label path')
#数据集的划分,地址选择自己数据下的ImageSets/Main
parser.add_argument('--txt_path', default='ImageSets/Main', type=str, help='output txt label path')
opt = parser.parse_args()
trainval_percent = 0.9
train_percent = 0.8
xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
num = len(total_xml)
list_index = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list_index, tv)
train = random.sample(trainval, tr)
file_trainval = open(txtsavepath + '/trainval.txt', 'w')
file_test = open(txtsavepath + '/test.txt', 'w')
file_train = open(txtsavepath + '/train.txt', 'w')
file_val = open(txtsavepath + '/val.txt', 'w')
for i in list_index:
name = total_xml[i][:-4] + '\n'
if i in trainval:
file_trainval.write(name)
if i in train:
file_train.write(name)
else:
file_val.write(name)
else:
file_test.write(name)
file_trainval.close()
file_train.close()
file_val.close()
file_test.close()1.2 通过voc_label.py得到适合yolov8训练需要的
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
from os import getcwd
sets = ['train', 'val']
classes = ["crackle","invalid"] # 改成自己的类别
abs_path = os.getcwd()
print(abs_path)
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(image_id):
in_file = open('Annotations/%s.xml' % (image_id), encoding='UTF-8')
out_file = open('labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
#difficult = obj.find('Difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for image_set in sets:
if not os.path.exists('labels/'):
os.makedirs('labels/')
image_ids = open('ImageSets/Main/%s.txt' % (image_set)).read().strip().split()
list_file = open('%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write(abs_path + '/images/%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file.close()1.3生成内容如下

2.训练结果分析
原始yolov8结果
mAP@0.5为0.919

YOLOv8n summary (fused): 168 layers, 3006038 parameters, 0 gradients, 8.1 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 4/4 [00:10<00:00, 2.67s/it]
all 119 269 0.887 0.839 0.919 0.634
crackle 119 191 0.837 0.807 0.867 0.558
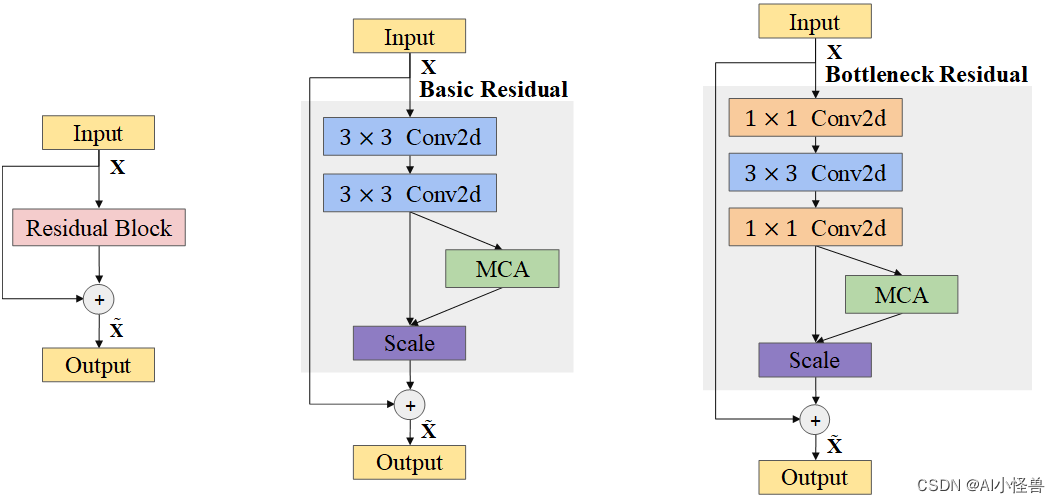
invalid 119 78 0.937 0.872 0.972 0.7112.1 多维协作注意模块MCA
独家全网首发MCA
YoloV8改进:原创独家首发 | 多维协作注意模块MCA,暴力涨点,效果秒杀ECA、SRM、CBAM等 | 即插即用系列_AI小怪兽的博客-CSDN博客
实验结果:
mAP@0.5原始为0.919提升至0.930
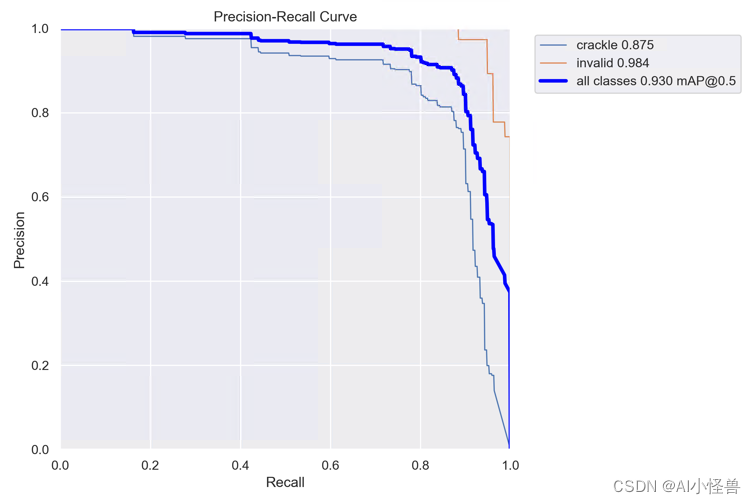
YOLOv8_MCALayer summary (fused): 181 layers, 3006048 parameters, 0 gradients, 8.1 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 4/4 [00:04<00:00, 1.12s/it]
all 119 269 0.909 0.875 0.93 0.663
crackle 119 191 0.851 0.801 0.875 0.564
invalid 119 78 0.967 0.949 0.984 0.763
Speed: 0.3ms preprocess, 3.9ms inference, 0.0ms loss, 6.8ms postprocess per image2.2 动态蛇形卷积(Dynamic Snake Convolution)
关注到管状结构细长连续的特点,并利用这一信息在神经网络以下三个阶段同时增强感知:特征提取、特征融合和损失约束。分别设计了动态蛇形卷积(Dynamic Snake Convolution),多视角特征融合策略与连续性拓扑约束损失。

实验结果:
mAP@0.5原始为0.919提升至0.930
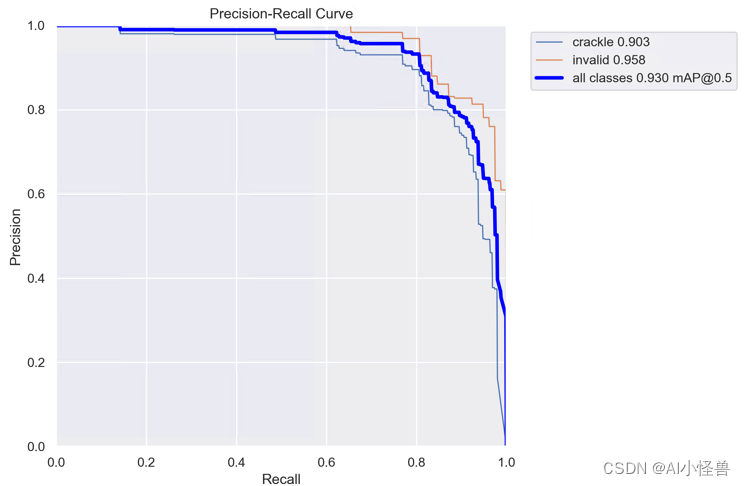
首发Yolov8涨点神器:动态蛇形卷积(Dynamic Snake Convolution),实现暴力涨点 | ICCV2023_AI小怪兽的博客-CSDN博客
2.3 MCA+DSC组合

实验结果:
mAP@0.5原始为0.919提升至0.934
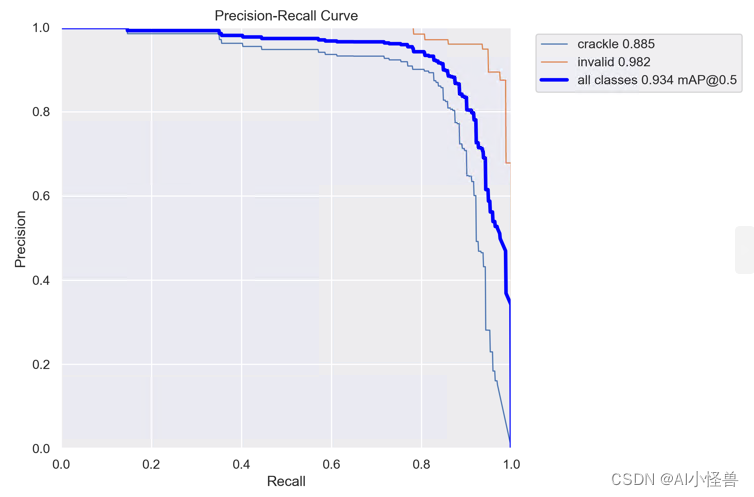
YOLOv8n-C2f-DySnakeConv-MCALayer summary: 262 layers, 3425904 parameters, 0 gradients, 8.7 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 4/4 [00:04<00:00, 1.03s/it]
all 119 269 0.907 0.893 0.934 0.637
crackle 119 191 0.869 0.838 0.885 0.537
invalid 119 78 0.946 0.949 0.982 0.737源码详见:
https://cv2023.blog.csdn.net/article/details/132850295