mybatis-plus 数据进行字段加解密入库,加密字段支持模糊搜索
前提介绍 (开发环境+需求)
1. 开发框架、环境
springboot+mybatis-plus+mysql5.7(oracle应该也是可以的,没有测试,但实现思路是都可以满足,懒得测oracle了,哈哈)
2. 需求介绍(背景)
需求很简单: 就是将数据存储到数据库,并且将敏感数据字段进行加密处理保存(比如:身份证,手机号,银行卡 等等)
需求也很变态:加密的数据要模糊搜素!!
如果需求不需要模糊搜素,直接加密入库就完事了,直接看这篇文章 mybatis-plus进行数据字段加密解密入库 ,就可以了!
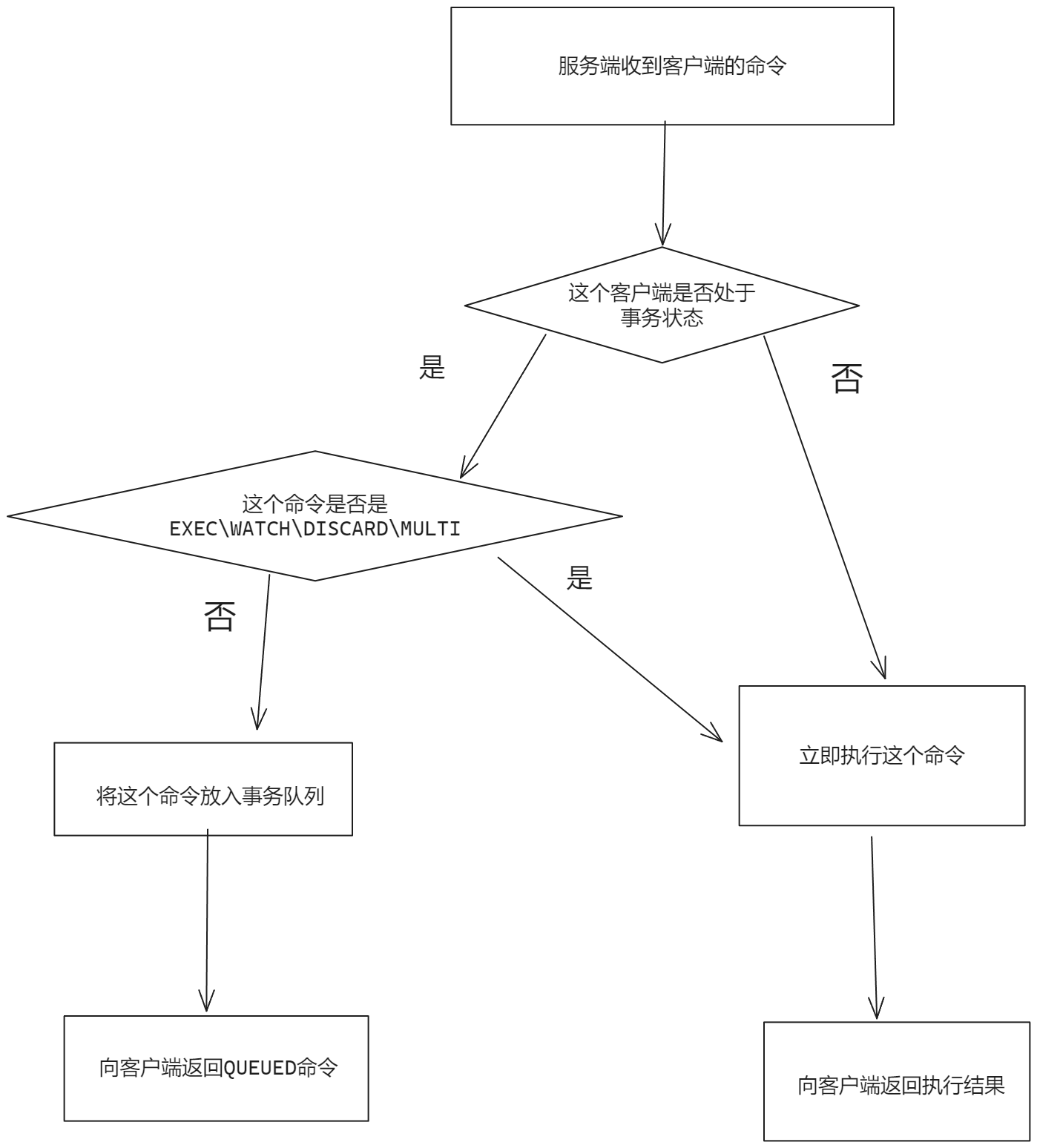
3.设计思路
个人 采用 映射表 分词的 方案进行处理的
mysql 创建 加密 模糊搜索字段 ,将字段加密进行分词处理,保存到 搜索映射表
分词这边采用 es 使用的ik分词器,原因就是:自己写一个分词是不可能的了,算法没那么牛逼 !! ,并且ik 分词器可以自定义词语进行分词
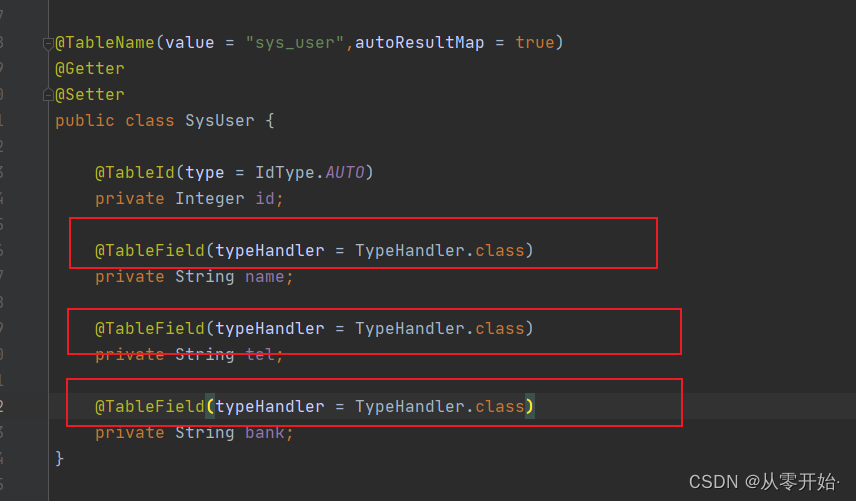
然后再使用 用 mybaitis-plus 自带的注解 @TableField(typeHandler = TypeHandler.class)

写一个 handle 类继承 BaseTypeHandler ,将数据进行加解密
大致思路是这样 !
4. 具体实现
4.1 . 依赖
<!-- ik分词器-->
<dependency>
<groupId>com.janeluo</groupId>
<artifactId>ikanalyzer</artifactId>
<version>2012_u6</version>
<exclusions>
<exclusion>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
</exclusion>
<exclusion>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
</exclusion>
<exclusion>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.12</version>
</dependency>
<!-- AES加密解密需要包-->
<dependency>
<groupId>commons-codec</groupId>
<artifactId>commons-codec</artifactId>
<version>1.15</version>
</dependency>
4.2 继承Mybatis的 BaseTypeHandler类,重写方法
package com.xiarp.encryptstorage.handler;
import com.xiarp.encryptstorage.util.AesUtil;
import org.apache.ibatis.type.BaseTypeHandler;
import org.apache.ibatis.type.JdbcType;
import java.sql.*;
/**
* @author xiarp
*/
public class TypeHandler extends BaseTypeHandler<String> {
@Override
public void setNonNullParameter(PreparedStatement ps, int i, String parameter, JdbcType jdbcType) throws SQLException {
ps.setString(i, AesUtil.encrypt(parameter));
}
@Override
public String getNullableResult(ResultSet rs, String columnName) throws SQLException {
return AesUtil.decrypt(rs.getString(columnName));
}
@Override
public String getNullableResult(ResultSet rs, int columnIndex) throws SQLException {
return AesUtil.decrypt(rs.getString(columnIndex));
}
@Override
public String getNullableResult(CallableStatement cs, int columnIndex) throws SQLException {
return AesUtil.decrypt(cs.getString(columnIndex));
}
}
4.3 AES 加密的工具类
package com.xiarp.encryptstorage.util;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.codec.binary.Base64;
import javax.crypto.Cipher;
import javax.crypto.spec.IvParameterSpec;
import javax.crypto.spec.SecretKeySpec;
/**
* aes 加密的工具类
* 1.存储 加密的秘钥key
* 2.实现 aes 加密
* 3.实现aes解密的功能
* @author xiarp
*/
@Slf4j
public class AesUtil {
/**
* 定义 aes 加密的key
* 密钥 必须是16位, 自定义,
* 如果不是16位, 则会出现InvalidKeyException: Illegal key size
* 解决方案有两种:
* 需要安装Java Cryptography Extension (JCE) Unlimited Strength Jurisdiction Policy Files(可以在Oracle下载).
* .设置设置key的长度为16个字母和数字的字符窜(128 Bit/8=16字符)就不报错了。
*/
private static final String KEY = "KEYBYACSJAVAZXLL";
/**
* 偏移量
*/
private static final int OFFSET = 16;
private static final String TRANSFORMATION = "AES/CBC/PKCS5Padding";
private static final String ALGORITHM = "AES";
/**
* 加密
* @param content content
* @return String
*/
public static String encrypt(String content) {
return encrypt(content, KEY);
}
/**
* 解密
*
* @param content content
* @return String
*/
public static String decrypt(String content) {
return decrypt(content, KEY);
}
/**
* 加密
*
* @param content 需要加密的内容
* @param key 加密密码
* @return String
*/
public static String encrypt(String content, String key) {
try {
SecretKeySpec skey = new SecretKeySpec(key.getBytes(), ALGORITHM);
IvParameterSpec iv = new IvParameterSpec(key.getBytes(), 0, OFFSET);
Cipher cipher = Cipher.getInstance(TRANSFORMATION);
//定义加密编码
String charset = "utf-8";
byte[] byteContent = content.getBytes(charset);
// 初始化
cipher.init(Cipher.ENCRYPT_MODE, skey, iv);
byte[] result = cipher.doFinal(byteContent);
// 加密
return new Base64().encodeToString(result);
} catch (Exception e) {
log.debug("加密失败:{}",e.getMessage());
}
return null;
}
/**
* AES(256)解密
*
* @param content 待解密内容
* @param key 解密密钥
* @return 解密之后
*/
public static String decrypt(String content, String key) {
try {
SecretKeySpec skey = new SecretKeySpec(key.getBytes(), ALGORITHM);
IvParameterSpec iv = new IvParameterSpec(key.getBytes(), 0, OFFSET);
Cipher cipher = Cipher.getInstance(TRANSFORMATION);
// 初始化
String charset = "utf-8";
cipher.init(Cipher.DECRYPT_MODE, skey, iv);
byte[] result = cipher.doFinal(new Base64().decode(content));
// 解密
return new String(result,charset);
} catch (Exception e) {
log.debug("解密失败:{}",e.getMessage());
}
return null;
}
}
4.4 分词器 工具类 (部分分词 + ik【可自定义扩展分词】)以及使用介绍
- 工具类
package com.xiarp.encryptstorage.util;
import cn.hutool.core.collection.ListUtil;
import cn.hutool.core.util.StrUtil;
import org.wltea.analyzer.core.IKSegmenter;
import org.wltea.analyzer.core.Lexeme;
import java.io.StringReader;
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
/**
* @author xiarp
*/
public class AnalyzerUtil {
/**
* ik
*
* @param str str
* @param length length
* @return List<String>
*/
public static List<String> ikSegmentationList(String str, Integer length) {
List<String> list = new LinkedList<>();
try {
if (StrUtil.isEmpty(str)) {
return ListUtil.empty();
}
StringReader stringReader = new StringReader(str);
IKSegmenter ik = new IKSegmenter(stringReader, false);
Lexeme le;
while ((le = ik.next()) != null) {
String lexemeText = le.getLexemeText();
if (lexemeText.length() >= length) {
list.add(lexemeText);
}
}
} catch (Exception e) {
e.printStackTrace();
}
return list;
}
/**
* 部分分词
*
* @param str str
* @param length length
* @return List<String>
*/
public static List<String> partSegmentationList(String str, Integer length) {
List<String> list = new ArrayList<>();
if (StrUtil.isEmpty(str)) {
return ListUtil.empty();
}
int strLength = str.length();
for (int startIndex = 0; startIndex <= strLength - length; startIndex++) {
String substring = str.substring(startIndex, startIndex + length);
list.add(substring);
}
return list;
}
}
- ik 分词器 配置文件+ 自定义扩展分词文件+ 不需要分词文件
文件1: IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IKAnalyzer扩展配置</comment>
<!--用户的扩展字典 -->
<entry key="ext_dict">extend.dic</entry>
<!--用户扩展停止词字典 -->
<entry key="ext_stopwords">stopword.dic</entry>
</properties>
文件2: extend.dic (扩展词典) ,没有使用是空白的
文件3: stopword.dic (扩展停止词典,不要这些 分词) 没有使用是空白的
文件全部创建在resources 下
4.4.1 分词器工具类使用解析,测试
ik 分词器 (智能分词)
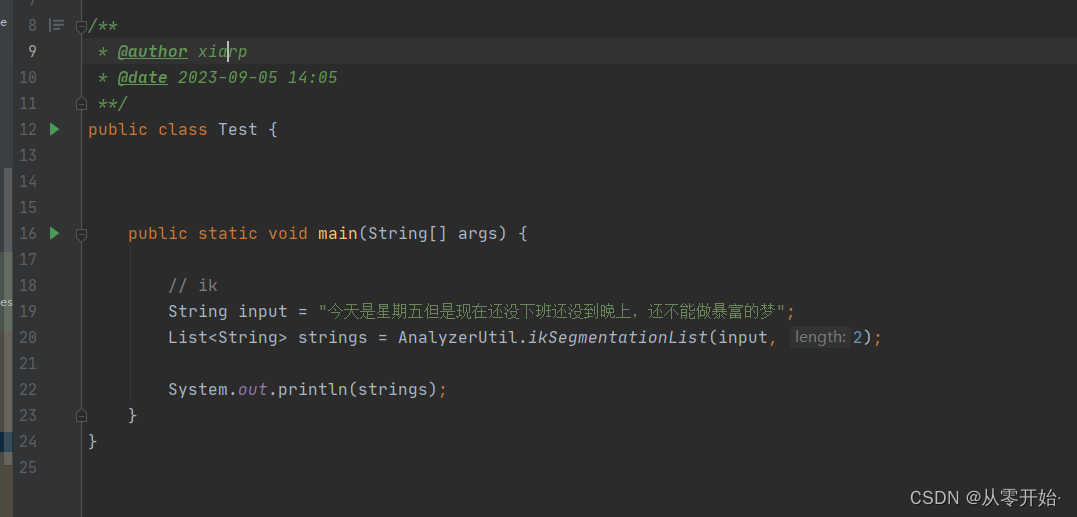

参数1: 需要分词的字符串,
参数2: 结果保留几个字符以上字符串

这边获取了 字符 >=2 的所有分词数据
扩展词典 :
现在我在 extend.dic (扩展词典) 文件中加上 “暴富的梦” 跟 “今天是星期五” ,看看结果
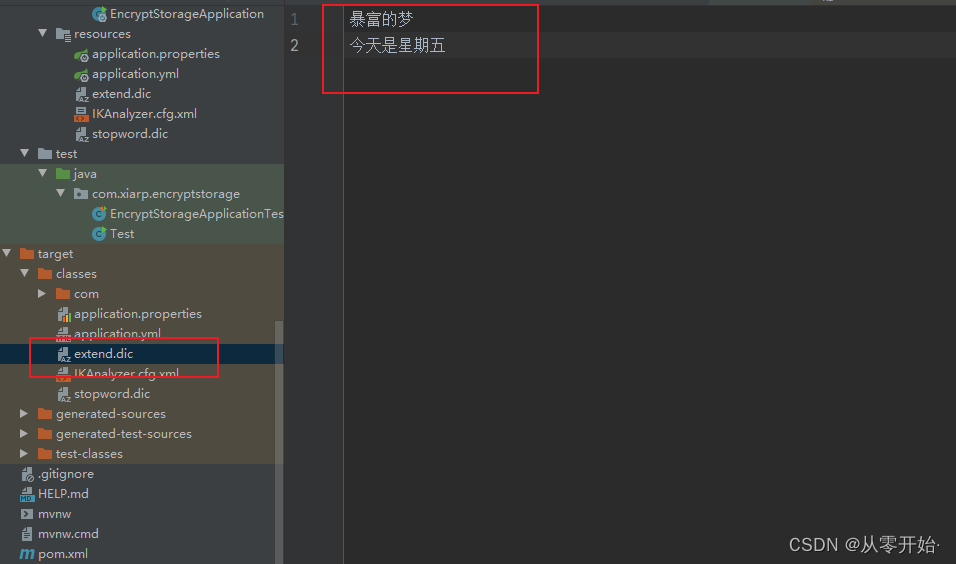
再次运行刚才测试代码 ,可以看到分词加进去了
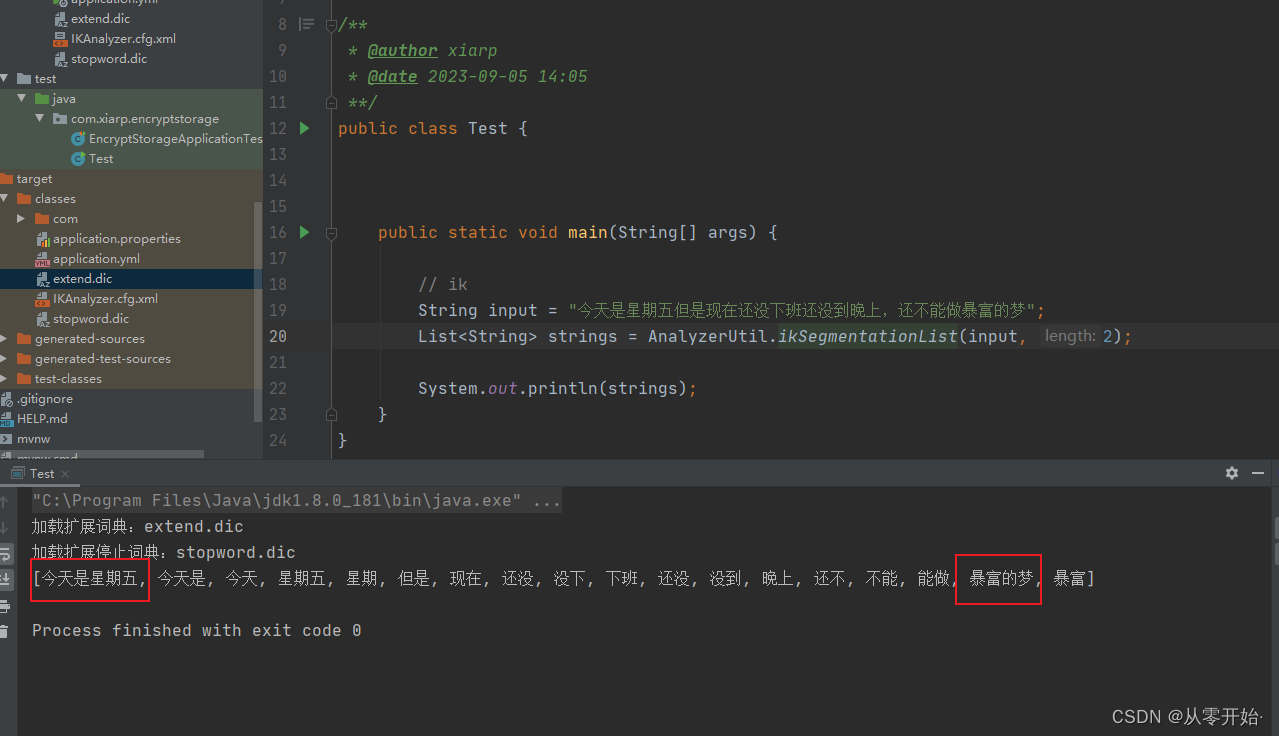
取消扩展词典:
就是这个词,不要出现,比如分词结果不要 “星期五” 这个词出现
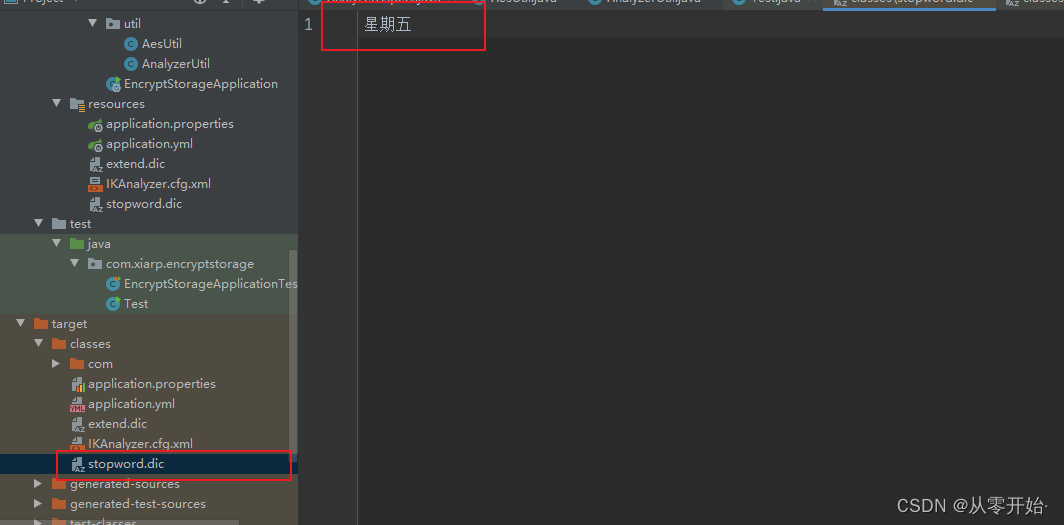
再次执行
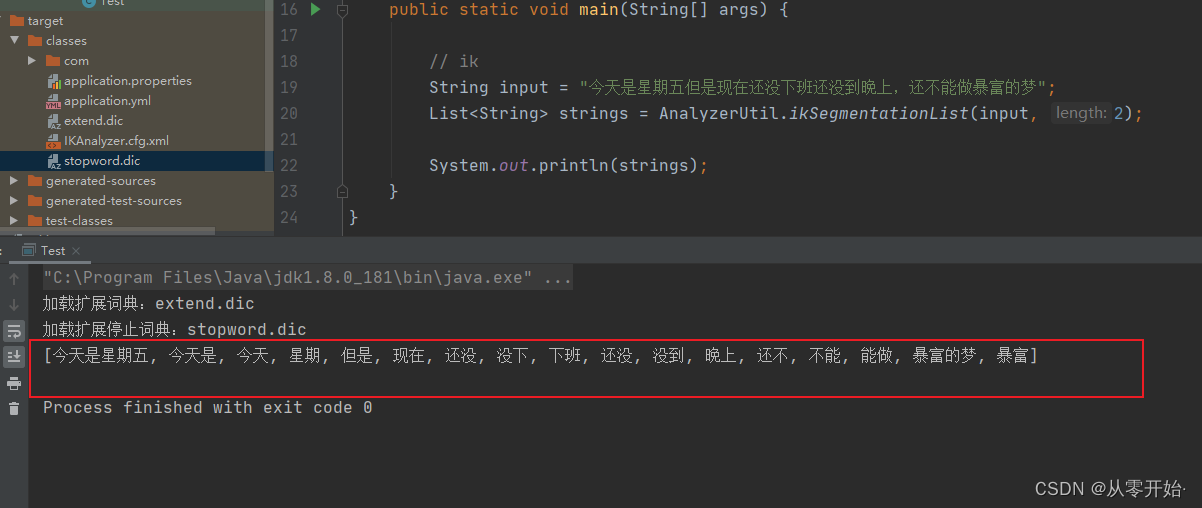
ik 分词用来分词手机号数字串类型的不太友好 (有处理方法,可以改ik 的工具类,这边就不改了,懒!),因此 可以 简单写了个 第二种方法,不知道叫什么,就叫部分分词了
参数同理
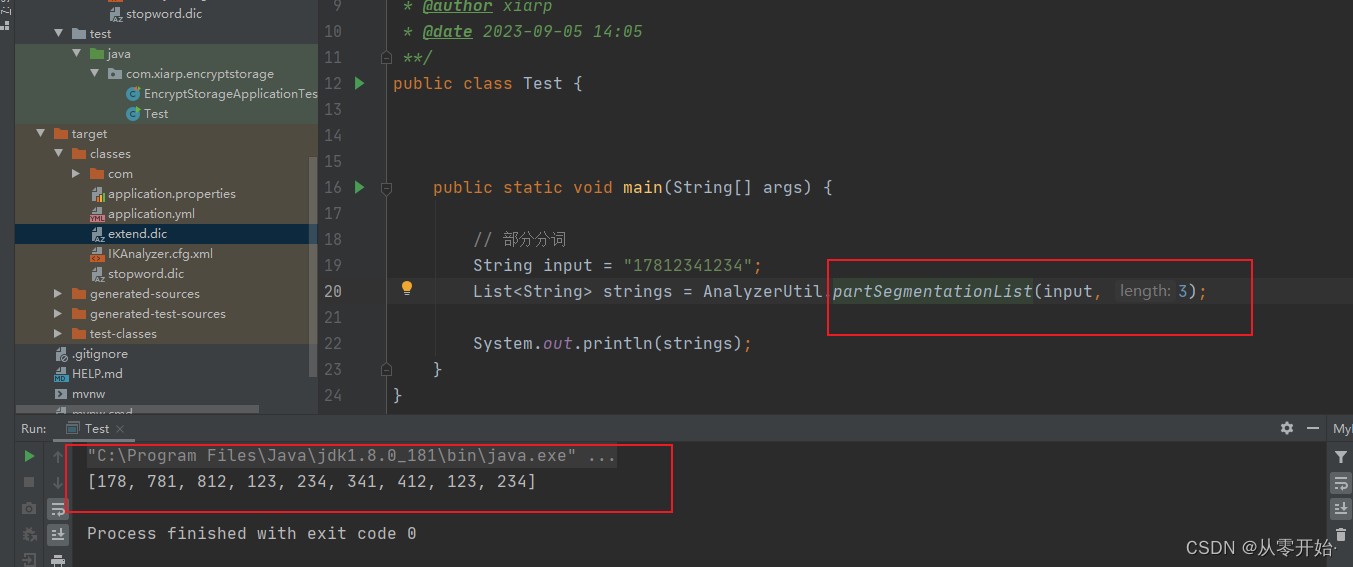
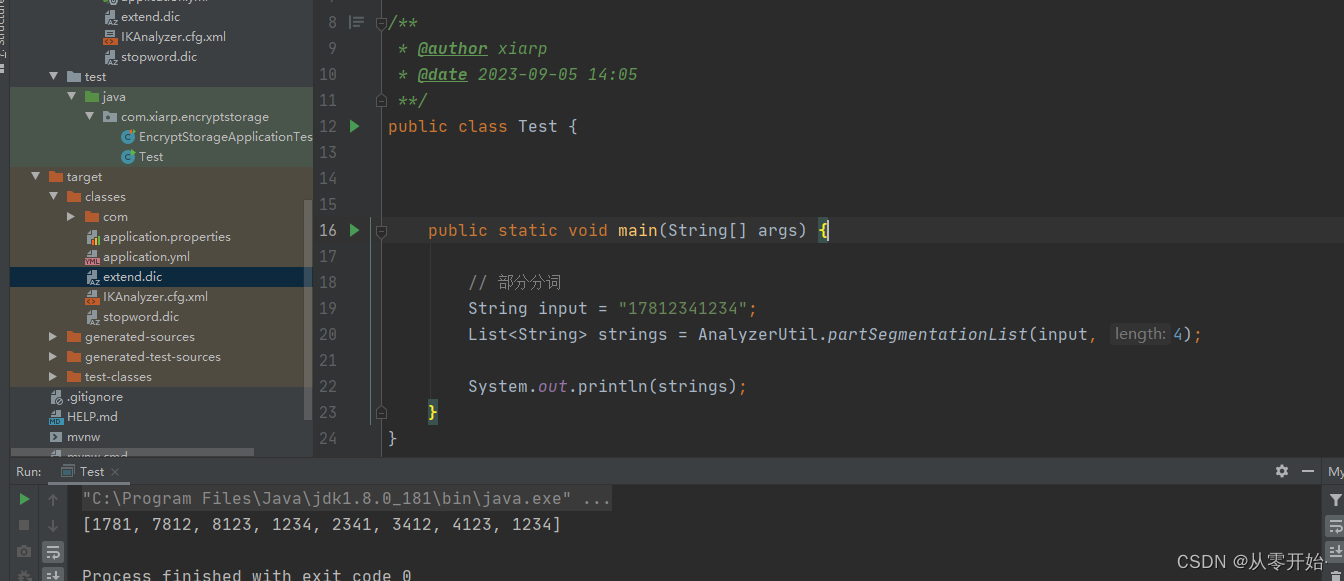
是按照,从第0位 开始 取三位,然后 从 第1 位开始取三位 。。。。。 以此类推,直到结束
【注意】:这边涉及到一个性能和安全问题,比如分词的字符长度设置的太长,加密又不安全,设置的太短,有影响性能,耗费的存储空间又多,因此,选择合适的分词长度 很重要 (数据量过小不用考虑)
就比如手机号就可以设置成 4 位,为一个分片,模糊搜索也可以说明 “请输入手机号后四位查询”
4.5 SQL 创建 分词 映射表(word_part_mapping) 以及模拟数据 用户(sys_user) 表
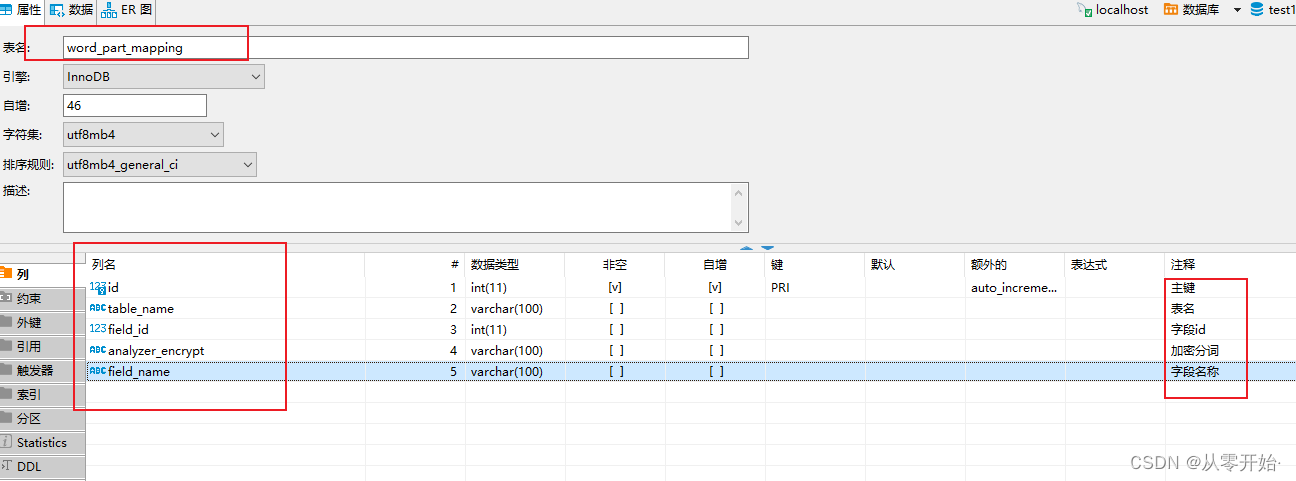
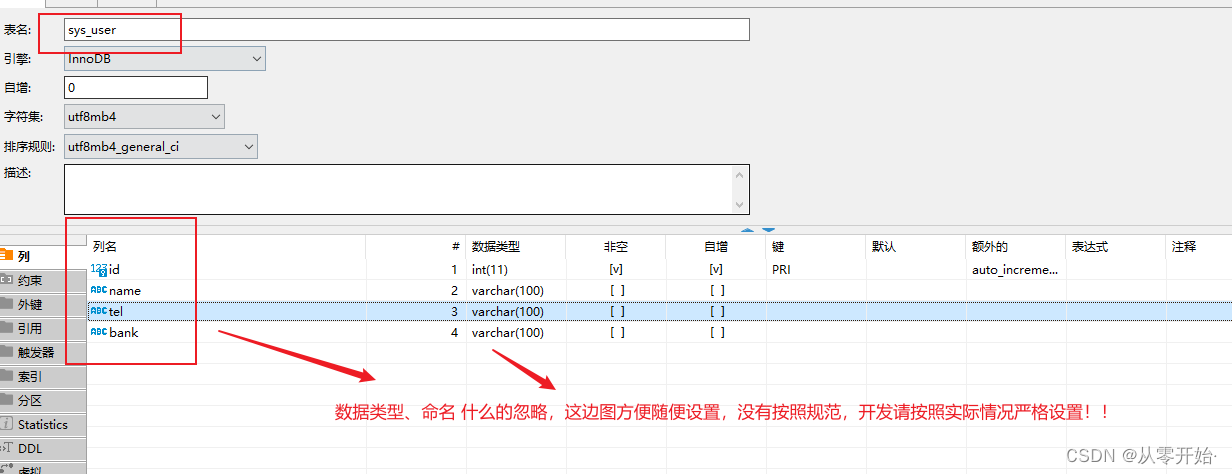
使用
对应需要加密实体类加上注解
简单模拟数据 新增 查询
新增数据 需加密字段分词处理逻辑 (映射表)
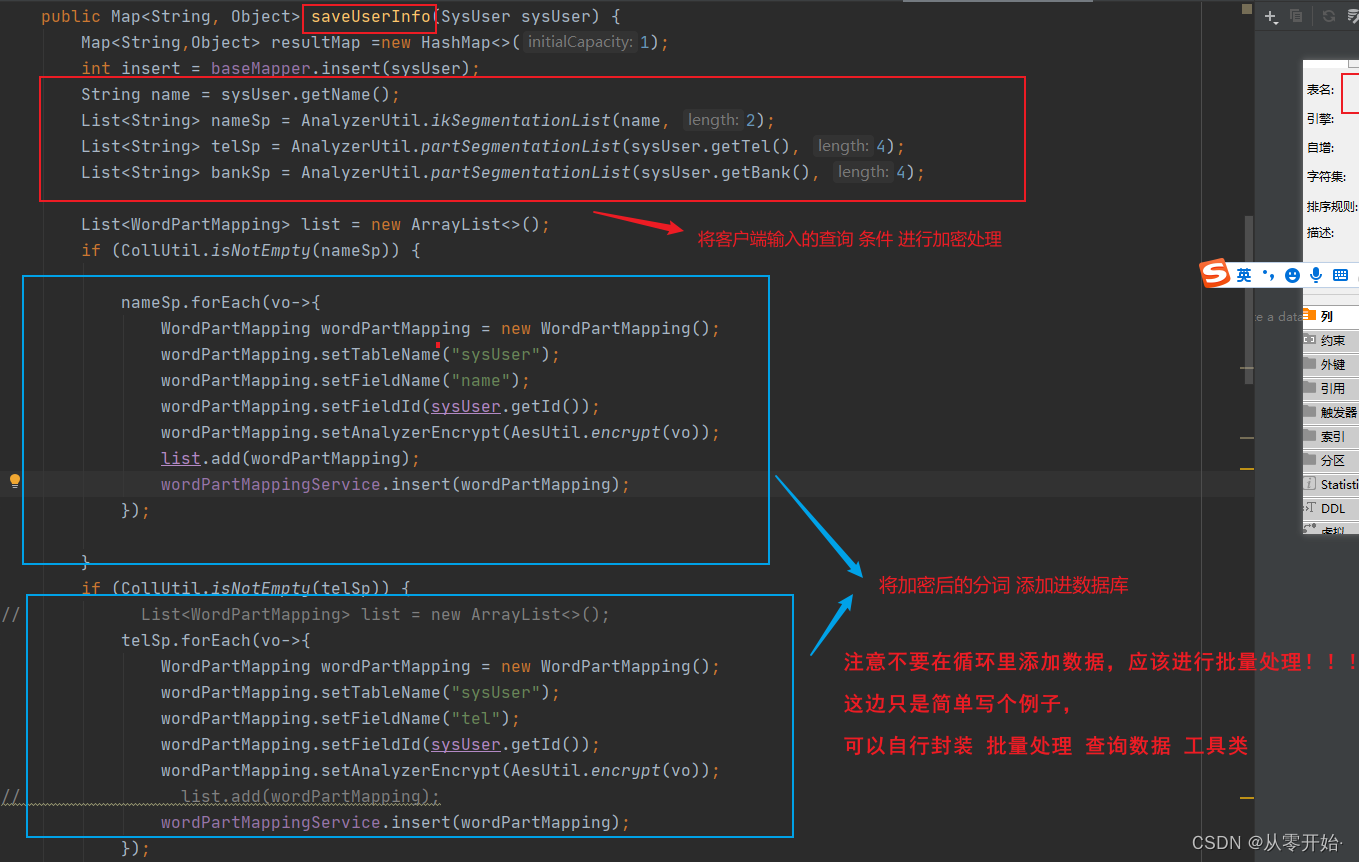
再提一句:不要再循环里添加数据,要批量!!!
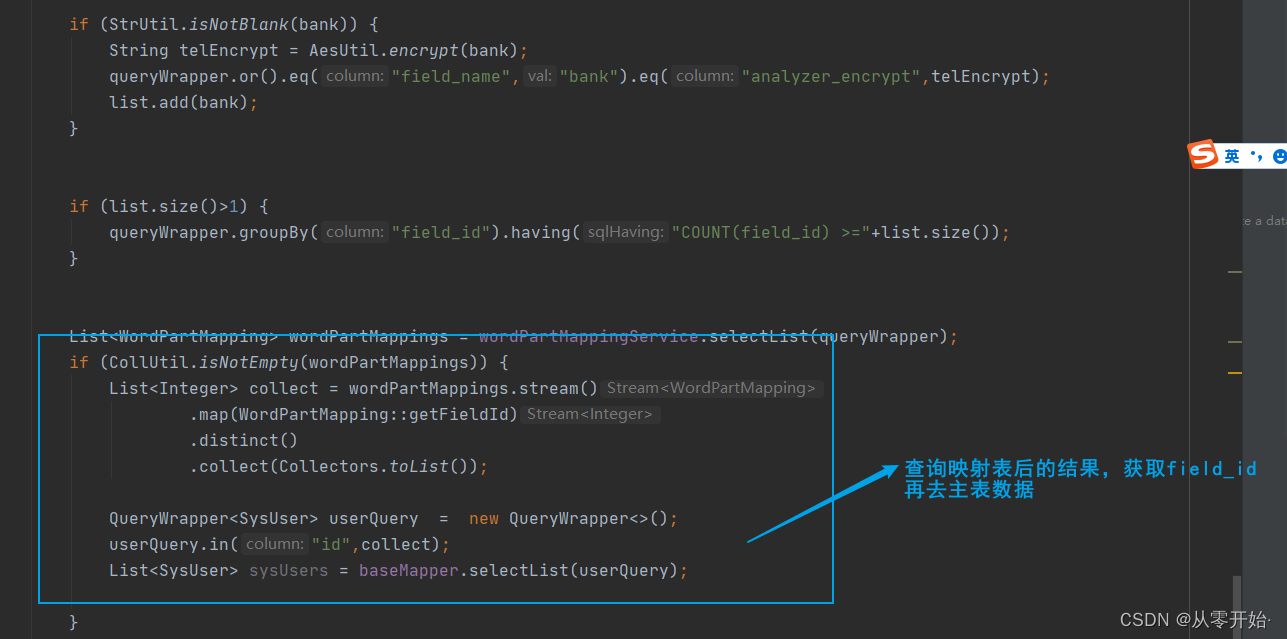
**查询 数据 **
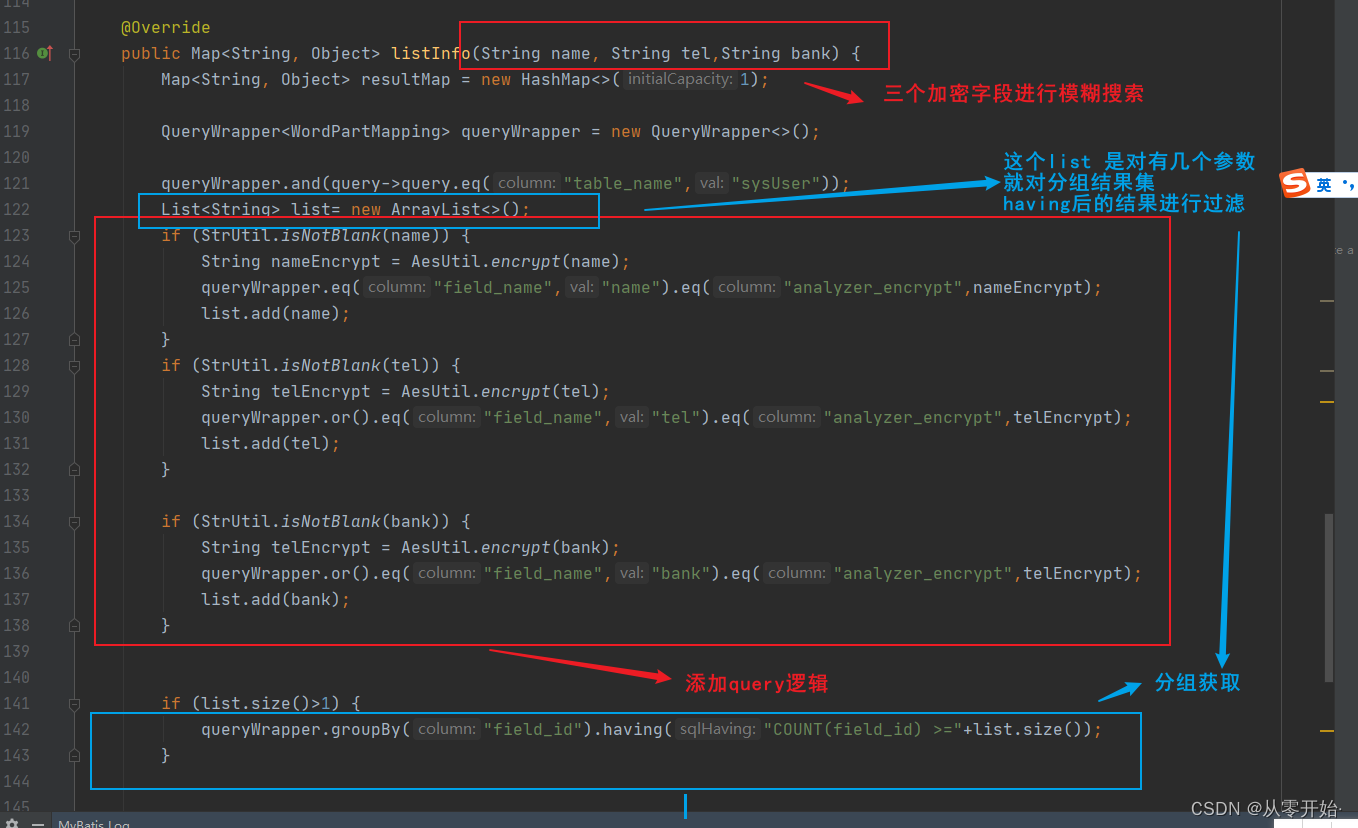
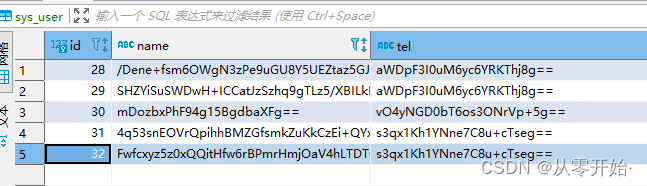
我向数据库中 添加了五条数据
以加密的形式存在
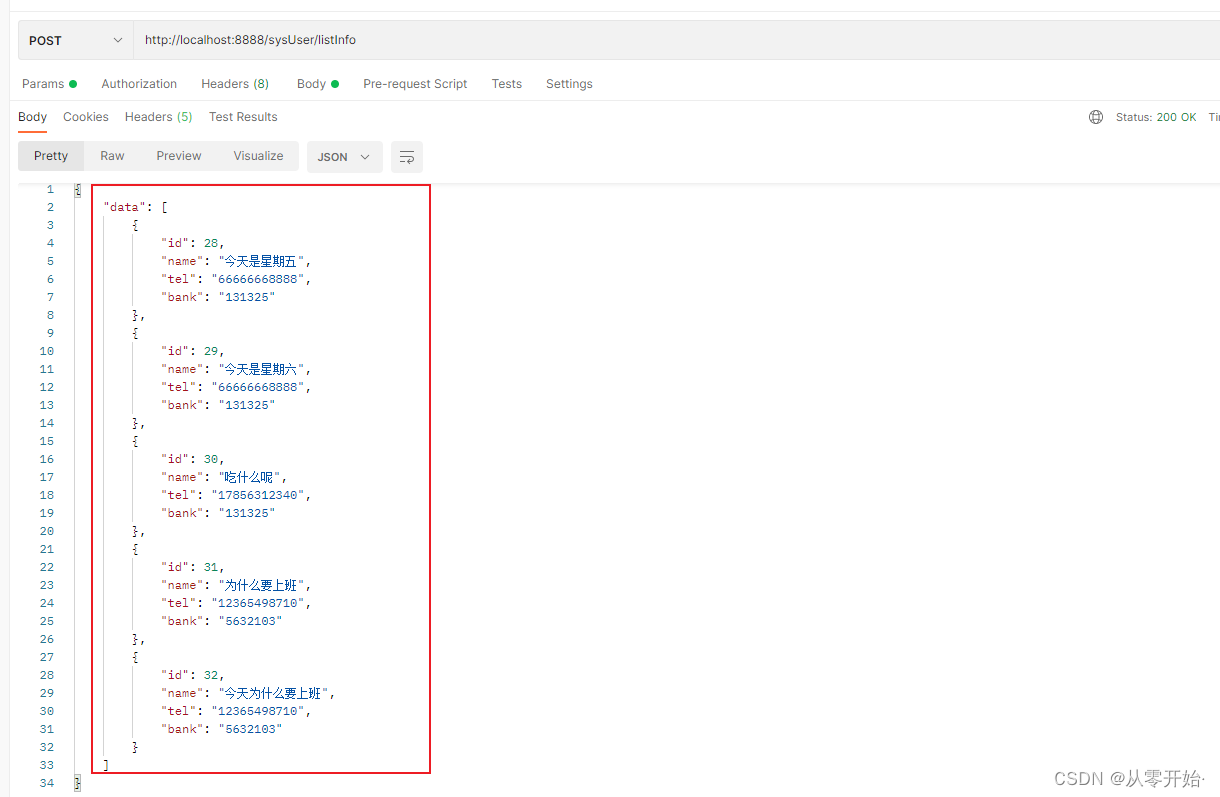
查询结果是明文【符合加密存储,明文输出要求】
模糊搜索
输入一个参数,输出三条数据,符合单模糊
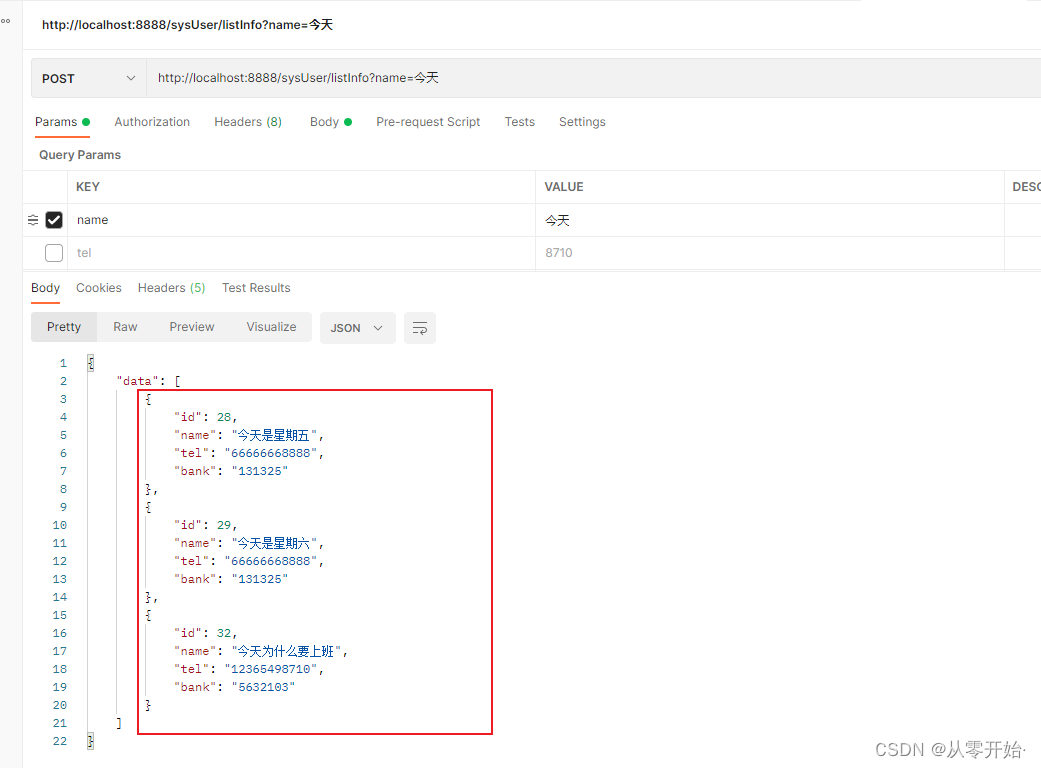
输入多个参数 ,输出符合的两条数据,符合 多模糊
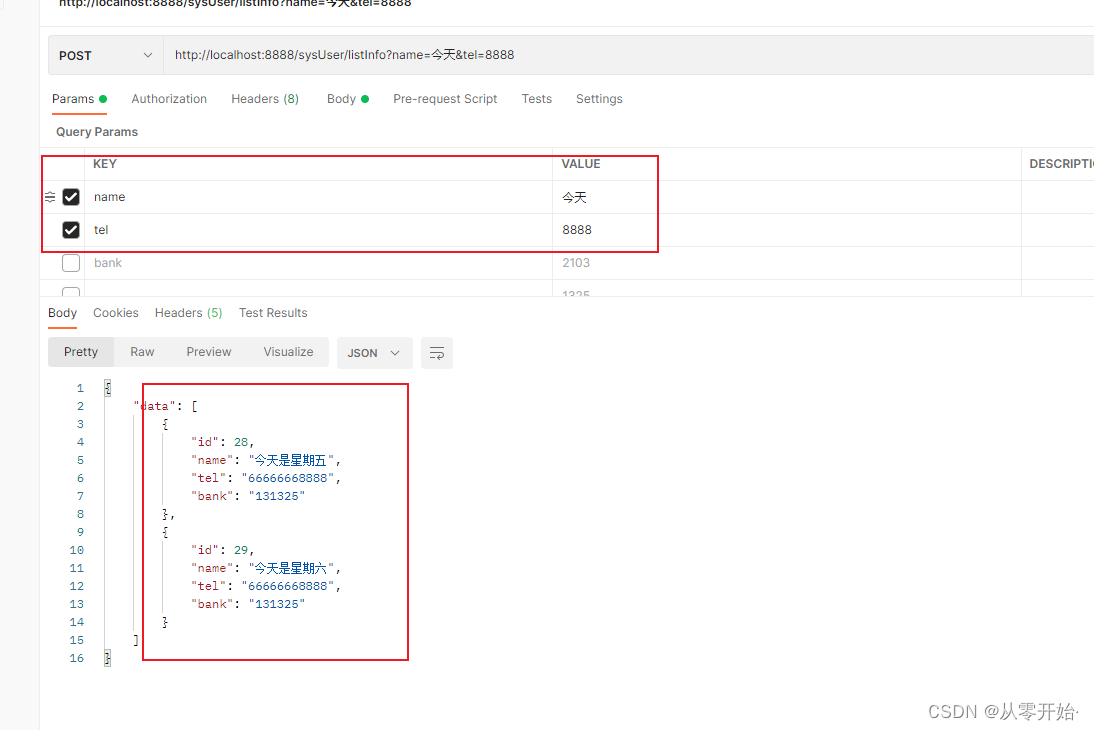

修改数据 直接看 这篇文章即可,一样的
注意一点是,修改到了敏感数据,需要先删除原先敏感数据的分词,重新分词进行添加!!,所以前边说的 批量添加分词映射表数据 可以 自己写一个工具类!!
文章有遗漏的工具类,或者有需要的其他信息,可以打在评论区!! 欢迎讨论指正,当然要是有更好的实现 方案,请指教!!!