Tippecanoe安装使用
介绍
tippecanoe是mapbox官方提供的一个开源矢量切片工具,用C++语言编写的。
Tippecanoe 的目标是为您的数据制作一个与比例无关的视图,以便在从整个世界到单个建筑物的任何级别上,您都可以看到数据的密度和纹理,而不是通过删除所谓的不重要的特征进行简化或聚类或聚合它们。
目前软件默认安装,只能支持macos或者linux系统。
tippecanoe官网
安装
MacOS安装
在 OSX 上安装 tippecanoe 的最简单方法是使用Homebrew:
brew install tippecanoe
Linux源码安装
这里以Centos7为例
安装相关依赖
yum install -y gcc gcc-c++ automake autoconf libtool make sqlite-devel.x86_64 zlib-devel
源码安装
从官网下载安装包,上传到服务器
# 编译
make
# 安装
make install
查看版本
tippecanoe -v
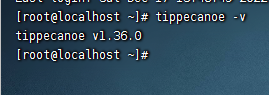
至此tippecanoe安装完成
windows安装
参考地址
使用
tippecanoe进行切片的时候推荐使用GeoJson格式的原始数据
矢量转GeoJSon的方式有很多,可以使用QGIS转换或者使用ogr2ogr。
tippecanoe进行切片最后生成的就是pbf格式。一种是散列状态的pbf,一种是mbtiles格式的SQLlite文件。推荐使用mbtiles格式。
切片后的数据是3857坐标系的
生成mbtiles格式
tippecanoe -zg -Bg -o /point/output/million/point.mbtiles --drop-densest-as-needed --extend-zooms-if-still-dropping /point/geo_point_one_million.geojson

生成后的文件可以使用GeoServer来发布数据。


生成散列的pbf格式
tippecanoe -zg -e /point/output/million2 --drop-densest-as-needed --extend-zooms-if-still-dropping /point/geo_point_one_million.geojson
生成散列数据可以考虑使用NGINX等服务器来发布
参数设置
有很多选择。-o 很多时候,除了output之外,您不想使用它们中的任何一个.mbtiles来命名输出文件,并且可能不想-f删除已经存在的具有该名称的文件。
如果您不确定适合您数据的 maxzoom 是多少,我们-zg会根据特征密度为您猜测一个。
Tippecanoe 通常会在低于 maxzoom 的缩放下丢弃一小部分点特征,以防止低缩放图块变得太大。如果您有一个较小的数据集,其中所有点都适合而不会丢失任何一个,请使用-r1保留所有点。如果您确实想要点下降,但您仍然希望瓷砖比想象的更密集-zg ,请使用-B将 basezoom 设置为低于 maxzoom。
如果尽管进行了上述设置,您的某些图块还是显得太大,您通常会希望--drop-densest-as-needed在每个缩放级别上删除任何必要的功能部分,以使该缩放级别的图块正常工作。
如果您的功能有很多属性,-y请只保留您真正需要的属性。
如果您的输入格式为换行符分隔的 GeoJSON,请使用它-P来加快输入解析速度。
输出瓦片集
-o文件.mbtiles或--output=文件.mbtiles:命名输出文件。-edirectory或--output-to-directory= directory:将图块写入指定目录而不是 mbtiles 文件。-f或者--force:删除 mbtiles 文件,如果它已经存在而不是给出错误-F或--allow-existing:如果元数据或切片表已存在或无法设置元数据字段,则继续(不删除现有数据)。你可能不想使用它。
瓦片集描述和归属
-nname或--name=name:tileset 的人类可读名称(默认 file.json)-Atext或--attribution=text:属性 (HTML) 将与使用此 tileset 数据的地图一起显示。-Ndescription或--description=description:tileset 的描述(默认文件 .mbtiles)
输入文件和图层名称
- name
.json或name.geojson:将命名的 GeoJSON 输入文件读入名为name的图层。 - name
.json.gz或name.geojson.gz:将命名的 gzip 压缩 GeoJSON 输入文件读入名为name的层中。 - name
.geobuf:将命名的 Geobuf 输入文件读入名为name的图层。 - name
.csv:将命名的 CSV 输入文件读入名为name的层中。 -lname或--layer=name:使用指定的图层名称,而不是从输入文件名或输出 tileset 中派生名称。如果指定了多个输入文件,这些文件将全部合并到单个命名层中,即使它们尝试使用-L.-Lname:file.json或--named-layer=name:file.json:为单个文件指定图层名称。如果您的 shell 支持它,您可以使用-Lname:<(cat dir/*.json)之类的子 shell 重定向来为流式输入的输出指定层名称。-L{layer-json}或--named-layer={layer-json}:通过 JSON 对象指定输入文件和图层选项。JSON 对象必须包含一个"file"键来指定要读取的文件名。(如果"file"键是空字符串,则表示从标准输入流中读取。)它还可能包含一个"layer"字段来指定图层的名称,和/或一个"description"字段来指定图层在 tileset 元数据中的描述,以及/ 或"format"要指定的字段csv或geobuf文件格式(如果从name. 例子:
tippecanoe -z5 -o world.mbtiles -L'{"file":"ne_10m_admin_0_countries.json", "layer":"countries", "description":"Natural Earth countries"}'
CSV 输入文件目前仅支持点几何,来自名为latitude、longitude、lat、lon、long、lng、x或的列y。
输入的并行处理
-P或者--read-parallel:使用多个线程一次读取每个 GeoJSON 输入文件的不同部分。这仅在输入是行分隔的 JSON 并且每个功能都在其自己的行上时才有效,因为它对功能周围的顶级结构一无所知。否则可能会产生虚假的“EOF”错误消息。如果输入是可以映射到内存的命名文件而不是只能顺序读取的流,则性能会更好。
如果输入文件以RFC 8142记录分隔符开头,将自动调用输入的并行处理,在记录分隔符处拆分,而不是在所有换行符处拆分。
如果输入文件是 Geobuf 格式,并行处理也会自动进行。
输入投影
-s投影或--projection=投影:指定输入数据的投影。当前支持的是EPSG:4326(WGS84,默认)和EPSG:3857(Web Mercator)。一般来说,如果可能的话,您应该为您的输入文件使用 WGS84。
缩放级别
-zzoom或--maximum-zoom=zoom:Maxzoom:生成图块的最高缩放级别(默认为 14)-zg或--maximum-zoom=g:根据特征间距猜猜什么是合理的 maxzoom。-Zzoom或--minimum-zoom=zoom:Minzoom:生成图块的最低缩放级别(默认为 0)-ae或--extend-zooms-if-still-dropping:如果在该缩放级别仍删除功能,则增加 maxzoom。通常仅适用于最大缩放级别的详细信息和简化选项将同时适用于最初指定的最大缩放级别和超出该级别的任何添加级别。-Rzoom/x/y或--one-tile=zoom/x/y:设置 minzoom 和 maxzoom 以缩放并仅生成该缩放级别的单个指定图块。
如果您知道您希望表示数据的精度,或相应打印地图的地图比例尺,则此表显示了 -z在您使用默认-d详细信息 12 时对应于各种选项的近似精度和比例尺:
| 缩放级别 | 精度(英尺) | 精度(米) | 地图比例尺 |
|---|---|---|---|
-z0 | 32000 英尺 | 10000米 | 1:320,000,000 |
-z1 | 16000 英尺 | 5000米 | 1:160,000,000 |
-z2 | 8000 英尺 | 2500米 | 1:80,000,000 |
-z3 | 4000 英尺 | 1250 米 | 1:40,000,000 |
-z4 | 2000 英尺 | 600米 | 1:20,000,000 |
-z5 | 1000 英尺 | 300米 | 1:10,000,000 |
-z6 | 500 英尺 | 150 米 | 1:5,000,000 |
-z7 | 250 英尺 | 80 米 | 1:2,500,000 |
-z8 | 125 英尺 | 40米 | 1:1,250,000 |
-z9 | 64 英尺 | 20米 | 1:640,000 |
-z10 | 32 英尺 | 10米 | 1:320,000 |
-z11 | 16 英尺 | 5米 | 1:160,000 |
-z12 | 8 英尺 | 2米 | 1:80,000 |
-z13 | 4 英尺 | 1米 | 1:40,000 |
-z14 | 2 英尺 | 0.5米 | 1:20,000 |
-z15 | 1 英尺 | 0.25米 | 1:10,000 |
-z16 | 6 英寸 | 15 厘米 | 1:5000 |
-z17 | 3 英寸 | 8 厘米 | 1:2500 |
-z18 | 1.5 英寸 | 4 厘米 | 1:1250 |
-z19 | 0.8 英寸 | 2 厘米 | 1:600 |
-z20 | 0.4 英寸 | 1 厘米 | 1:300 |
-z21 | 0.2 英寸 | 0.5 厘米 | 1:150 |
-z22 | 0.1 英寸 | 0.25 厘米 | 1:75 |
平铺分辨率
-ddetail或--full-detail=detail:最大缩放级别的细节(默认 12,对于 2^12=4096 的平铺分辨率)-Ddetail或--low-detail=detail:较低缩放级别的细节(默认 12,对于 2^12=4096 的平铺分辨率)-mdetail或--minimum-detail=detail:如果瓷砖在常规细节处太大,它将尝试的最小细节(默认为 7)
所有内部数学都是根据 32 位图块坐标系完成的,因此地球大小的 1/(2^32),或大约 1 厘米,是最小的可区分距离。如果maxzoom + detail > 32,则与使用较小的maxzoom或detail相比,不会获得额外的分辨率。
过滤特征属性
-xname或--exclude=name:从所有功能中排除命名属性。您可以指定多个-x选项以排除多个属性。(不要在单个 . 中用逗号分隔名称-x。)-yname或--include=name:包括所有功能中的命名属性,不包括所有未明确命名的属性。您可以指定多个-y选项以明确包含多个属性。(不要在单个 . 中用逗号分隔名称-y。)-X或--exclude-all:排除所有属性并仅编码几何图形
修改要素属性
-Tattribute:type或--attribute-type=attribute:type:将命名的特征属性强制为指定类型。类型可以是、string、或。如果类型是,则(或者,如果是数字,则等)、、或空字符串的原始属性变为,否则变为。如果类型为or且原始属性为非数字,则变为. 如果类型是并且原始属性是浮点数,则将其四舍五入为最接近的整数。float``int``bool``bool``0``0.0``false``null``false``true``float``int``0``int-Yattribute:description或--attribute-description=attribute:description:将descriptiontileset 元数据中的指定属性设置为description而不是通常的String,Number, 或Boolean.-Eattribute:operation或--accumulate-attribute=attribute:operation:保留已删除、按需合并或集群的特征中的命名属性。**操作可以是 ,sum,product,mean,max,min,concat或comma来指定命名属性如何累积到幸存的要素中的同名属性上。-peor--empty-csv-columns-are-null:将空 CSV 列视为空值而不是空字符串。-aI或--convert-stringified-ids-to-numbers:如果要素 ID 是数字的字符串表示形式,则将其转换为普通数字以用作要素 ID。--use-attribute-for-id=name:使用具有指定名称的属性,就像它被指定为功能 ID 一样。(如果此属性是字符串化数字,您还必须使用-aI将其转换为数字。)
按属性过滤要素
-jfilter or--feature-filter= filter:根据每层过滤器检查功能(如Mapbox GL 样式规范中所定义),并且仅包括匹配的功能。层中未指定过滤器的任何要素都将通过。图层过滤器"*"适用于所有图层。特殊变量$zoom指的是当前缩放级别。-Jfilter-file或--feature-filter-file= filter-file:类似-j,但从文件中读取过滤器。
示例:查找低scalerank但高的自然地球国家LABELRANK:
tippecanoe -z5 -o filtered.mbtiles -j '{ "ne_10m_admin_0_countries": [ "all", [ "<", "scalerank", 3 ], [ ">", "LABELRANK", 5 ] ] }' ne_10m_admin_0_countries.geojson
示例:在低缩放级别仅保留主要的 TIGER 道路:
tippecanoe -o roads.mbtiles -j '{ "*": [ "any", [ ">=", "$zoom", 11 ], [ "in", "MTFCC", "S1100", "S1200" ] ] }' tl_2015_06001_roads.json
Tippecanoe 还接受 , 形式的表达式[ "attribute-filter", name, expression ]来过滤单个特征属性而不是整个特征。例如,您可以通过执行以下操作排除低缩放级别的道路名称
tippecanoe -o roads.mbtiles -j '{ "*": [ "attribute-filter", "FULLNAME", [ ">=", "$zoom", 9 ] ] }' tl_2015_06001_roads.json
表达式attribute-filter本身总是被认为是求值到true(换句话说,保留特征而不是丢弃它)。如果您想使用多个attribute-filter表达式,或使用其他表达式从同一图层中删除要素,请将它们包含在一个all表达式中,以便对它们进行评估。
按缩放级别删除固定比例的功能
-rrate或--drop-rate=rate:在低于 basezoom 的缩放级别下点被丢弃的速率(默认 2.5)。如果您使用-rg,它会猜测一个下降率,该下降率将在最密集的图块中保留最多 50,000 个特征。您还可以指定一个带有-rg宽度的标记宽度,以允许最密集的图块中较少的特征来补偿较大的标记,或者指定-rf数字以允许最密集的图块中的最多数量的特征。-Bzoom或--base-zoom=zoom:基本缩放,所有点都包含在图块中的级别(默认最大缩放)。如果您使用-Bg,它会猜测将在最密集的图块中保留最多 50,000 个要素的缩放级别。您还可以指定一个带有-Bg宽度的标记宽度,以允许最密集的图块中较少的特征来补偿较大的标记,或者指定-Bf数字以允许最密集的图块中的最多数量的特征。-al或--drop-lines:让“点”在较低的缩放下下降也适用于线条-ap或--drop-polygons:让“点”在较低的缩放下下降也适用于多边形-Kdistance或--cluster-distance=distance:聚类点(与 一样--cluster-densest-as-needed,但没有实验发现过程)大约在彼此的距离内。单位是标称 256 像素图块内的图块坐标,因此最大值 255 只允许每个图块一个特征。大约 10 的值可能适合典型的标记大小。行为见--cluster-densest-as-needed下文。
删除一小部分功能以保持在图块大小限制以下
-as或--drop-densest-as-needed:如果图块太大,请尝试通过增加要素之间的最小间距将其减小到 500K 以下。发现的间距适用于整个缩放级别。-ad或--drop-fraction-as-needed:从每个缩放级别动态删除部分功能,以将大图块保持在 500K 大小限制以下。(这类似于-pd但适用于整个缩放级别,而不是每个图块。)-an或--drop-smallest-as-needed:从每个缩放级别动态删除最小的要素(物理上最小:最短的线或最小的多边形),以将大图块保持在 500K 大小限制以下。此选项不适用于点要素。-aN或--coalesce-smallest-as-needed:将每个缩放级别的最小要素(物理上最小:最短的线或最小的多边形)动态组合到附近的其他要素中,以将大图块保持在 500K 大小限制以下。此选项不适用于点要素,并且可能对 LineStrings 帮助不大。它主要用于多边形,以保持多边形覆盖的完整原始区域,同时仍然以某种方式减少要素数量。小多边形的属性不会保留在组合要素中(通过 除外--accumulate-attribute),只会保留它们的几何形状。此外,嵌套多边形合并到的多边形不一定是直接封闭的要素。-aD或--coalesce-densest-as-needed:将每个缩放级别中最密集的特征动态组合到附近的其他特征中,以将大图块保持在 500K 大小限制以下。(同样,主要用于多边形。)-aS或--coalesce-fraction-as-needed:将每个缩放级别的一小部分要素动态组合到附近的其他要素中,以将大图块保持在 500K 大小限制以下。(同样,主要用于多边形。)-pd或--force-feature-limit:从大图块中动态删除部分特征,以将它们保持在 500K 大小限制以下。它在瓷砖边界处可能看起来很难看。(这类似于-ad但单独应用于每个图块,而不是整个缩放级别。)您可能不想使用它。-aC或--cluster-densest-as-needed:如果图块太大,请尝试通过增加要素之间的最小间距并从每组中保留一个占位符要素来减小其大小。剩余的要素将被赋予一个"clustered": true属性以指示它代表一个集群,一个"point_count"属性以指示被集群到其中的要素的数量,以及一个"sqrt_point_count"属性以指示要素的相对宽度以表示该集群。如果被聚类的特征是点,代表特征将位于原始点位置的平均值;否则,将保留原始特征之一作为代表。
丢弃紧密重叠的特征
-ggamma或--gamma=_gamma_:丢弃特别密集的点的速率(默认为 0,无效果)。伽马值为 2 会将相距小于一个像素的点的数量减少到其原始数量的平方根。-aG或--increase-gamma-as-needed:如果图块太大,请尝试通过增加-g伽玛将其减小到 500K 以下。发现的伽玛适用于整个缩放级别。您可能想--drop-densest-as-needed改用。
线和多边形简化
-Sscale或--simplification=scale:将线和多边形简化的容差乘以scale。标准容差试图将线或多边形保持在其正确位置的一个分块单元内。您可能最多可以达到 10 个左右,而不会出现太大的明显差异。-psor--no-line-simplification: 不要简化线和多边形-pS或--simplify-only-low-zooms:不要在最大缩放下简化线和多边形(但在较低的缩放下进行简化)-pn或--no-simplification-of-shared-nodes:不要简化出现在多个要素中或在同一要素内多次使用的远离节点,这样相交的道路就不会丢失交叉点节点。--coalesce(如果您还使用or ,这将无效--detect-shared-borders。)-pt或--no-tiny-polygon-reduction:不要将非常小的多边形面积组合成代表它们组合面积的小正方形。
尝试改善共享多边形边界
-ab或者--detect-shared-borders: 以TopoJSON的方式,检测多个多边形之间共享的边界,并在每个多边形中进行相同的简化。这比单独考虑每个多边形需要更多的时间和内存。-aL或--grid-low-zooms:在maxzoom以下的所有缩放级别,将所有线和多边形对齐到阶梯网格,而不是允许对角线。您还需要指定平铺分辨率,可能是-D8. 此选项提供了一种在低缩放下显示连续宗地、网格化或分箱数据的方法,而不会用微小的多边形覆盖图块,因为要素要么被拉伸到网格单元,要么完全丢失,具体取决于它们在原始数据。你可能不想使用它。
控制裁剪到图块边界
-bpixels或--buffer=pixels:从相邻图块复制特征的缓冲区大小。单位是“屏幕像素”——图块宽度或高度的 1/256。(默认 5)-pc或--no-clipping:不要将要素裁剪到图块的大小。如果某个要素与图块的边界或缓冲区完全重叠,则会将其完全包含在内。注意:这会产生非常大的图块集,尤其是对于大的多边形。-pD或--no-duplication:与 一样--no-clipping,每个要素都完好无损地包括在内,而不是切割到图块边界。此外,它仅包含在每个缩放级别的单个图块中,而不是可能包含在多个副本中。瓦片集的客户端必须检查相邻的瓦片(可能相距一定距离)以确保它们具有所有功能。
对每个图块中的要素重新排序
-pi或--preserve-input-order:保留要素的原始输入顺序作为绘制顺序,而不是按地理顺序。(这是作为在最后恢复原始顺序而实现的,因此落点仍然是地理上的,这意味着它也撤消了-ao)。-acor--coalesce:合并具有相同属性的连续特征。如果您有许多具有相同属性的小多边形并且您想将它们合并在一起,这将很有用。-ao或--reorder:重新排序要素,将具有相同属性的要素按顺序排列(而不是空间上大致相邻的要素),以尝试使它们合并。如果您使用--coalesce.-ar或--reverse:尝试反转线条的方向,使它们更好地合并和压缩。你可能不想使用它。-ah或--hilbert: 将特征置于希尔伯特曲线顺序而不是通常的 Z 顺序。这提高了空间相邻要素顺序相邻的可能性,并且应该改进密度计算和空间合并。它最终应该是默认值。
添加计算属性
-ag或--calculate-feature-density:向每个要素添加一个新属性 ,tippecanoe_feature_density以记录要素在图块的该区域中的间隔密度。您可以在样式中使用此属性以在点密集的地方产生发光效果。它的范围可以从最稀疏区域的 0 到最密集区域的 255。-ai或:向每个尚无的特征--generate-ids添加一个id(特征 ID,而不是名为 的属性)。id目前无法保证所id添加的功能在运行之间保持稳定,或者不会与手动分配的功能 ID 发生冲突。Tippecanoe 的未来版本可能会更改分配 ID 的机制。
尝试纠正错误的源几何
-awor--detect-longitude-wraparound:检测特征中的连续点何时跳到世界的另一边,并尝试修复几何体。-pw或--use-source-polygon-winding:不遵循 GeoJSON 多边形环顺序,而是使用源数据中的原始多边形缠绕来区分内部(顺时针)和外部(逆时针)多边形环。-pW或--reverse-source-polygon-winding:不遵循 GeoJSON 多边形环顺序,而是使用与源数据中原始多边形缠绕相反的方式来区分内部(逆时针)和外部(顺时针)多边形环。--clip-bounding-box=minlon,minlat,maxlon,maxlat:将所有特征裁剪到指定的边界框。
设置或禁用图块大小限制
-Mbytes或--maximum-tile-bytes=bytes:使用指定的字节数作为最大压缩图块大小而不是 500K。-Ofeatures或--maximum-tile-features=features:使用指定数量的特征作为图块中的最大值,而不是 200,000。-pf或--no-feature-limit:不要将切片限制为 200,000 个要素-pk或--no-tile-size-limit:不要将图块限制为 500K 字节-pC或--no-tile-compression:不压缩 PBF 矢量切片数据。如果您从渲染器收到“Unimplemented type 3”错误消息,可能是因为它期望使用此选项的未压缩切片而不是普通的 gzip 压缩切片。-pgor--no-tile-stats: 不要tilestats在 tileset 元数据中生成行。没有tilestats的上传将需要更长的时间来处理。--tile-stats-attributes-limit=count:包括tilestats最多count个属性的信息,而不是默认的 1000 个。--tile-stats-sample-values-limit=count:tilestats根据计数值而不是默认的 1000 计算属性统计信息。--tile-stats-values-limit=count:报告计数唯一属性值tilestats而不是默认的 100。
临时存储
-t目录或--temporary-directory=目录:将临时文件放在目录中。如果您不指定,它将使用/tmp.
进度指示器
-q或者--quiet:安静地工作,而不是报告进度或警告消息-Qor--no-progress-indicator: 不报告进度,但仍然给出警告-Useconds或--progress-interval=seconds:不要比指定的秒数更频繁地报告进度。-v或者--version: 报告 Tippecanoe 的版本号
过滤器
-Ccommand或--prefilter=command:指定要在开始组装每个图块时运行的 shell 过滤器命令-ccommand或--postfilter=command:指定在组装每个图块结束时运行的 shell 过滤器命令
前置和后置过滤器命令允许您在创建每个图块时对其特征进行可选的过滤或转换。它们是 shell 命令,以缩放级别、X 和 Y 作为$1、$2和$3参数运行。Tippecanoe 的未来版本可能会为更多上下文添加额外的参数。
这些特性作为标准输入上一系列以换行符分隔的 GeoJSON 对象提供给过滤器,并tippecanoe期望从过滤器的标准输出中读取另一组 GeoJSON 特性。
在进行线简化、多边形拓扑修复、伽马计算、动态特征删除或其他内部处理之前,预过滤器以最高分辨率接收特征。后置过滤器在简化、清理和删除之后以分块分辨率接收特征。
图层名称作为tippecanoe要素元素的一部分提供,必须传递才能将要素保留在正确的图层中。在预过滤器的情况下,tippecanoe元素还可能包含index、sequence、extent和dropped,元素,必须通过这些元素才能进行 、 和 等 --drop-densest-as-needed内部--drop-smallest-as-needed操作--preserve-input-order。
例子:
- 制作 Natural Earth 国家的 tileset 以缩放级别 5,并将 GeoJSON 功能复制到
tiles/z/x/y.geojson目录层次结构中的文件。
tippecanoe -o countries.mbtiles -z5 -C 'mkdir -p tiles/$1/$2; tee tiles/$1/$2/$3.geojson' ne_10m_admin_0_countries.json
- 制作 Natural Earth 国家的瓦片集以缩放级别 5,但仅包括与德国边界框相交的瓦片。(该
limit-tiles-to-bbox脚本位于 Tippecanoe 源目录中。)
tippecanoe -o countries.mbtiles -z5 -C './filters/limit-tiles-to-bbox 5.8662 47.2702 15.0421 55.0581 $*' ne_10m_admin_0_countries.json
- 在 Tippecanoe County 制作 TIGER 道路的图块集,除了主要和次要道路(由 TIGER 分类)之外的所有道路都在缩放级别 11 以下。
tippecanoe -o roads.mbtiles -c 'if [ $1 -lt 11 ]; then grep "\"MTFCC\": \"S1[12]00\""; else cat; fi' tl_2016_18157_roads.json