背景:
接上一篇文章,ProcessWindowFunction 结合自定义触发器会有状态过大的问题,本文就使用AggregateFunction结合自定义触发器来实现,这样就不会导致状态过大的问题了
AggregateFunction结合自定义触发器实现
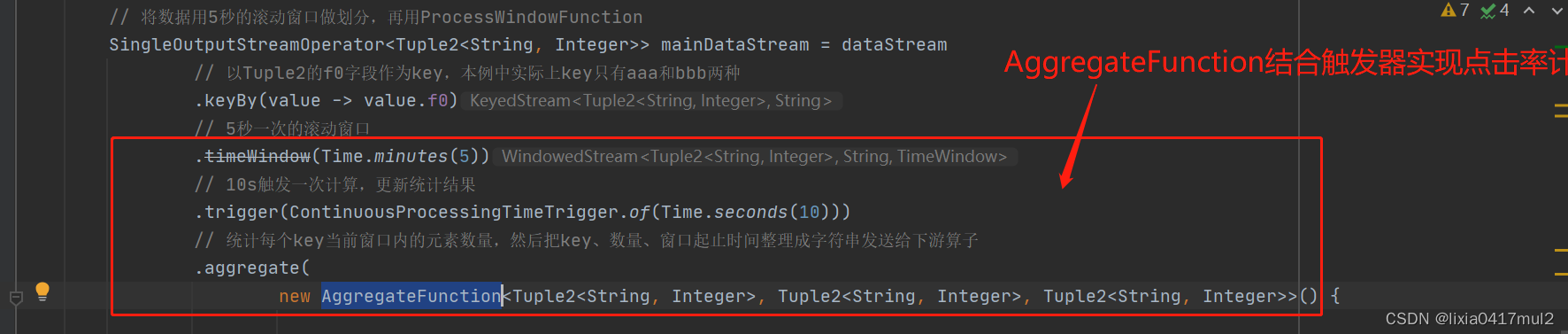
flink对于每个窗口只需要维护一个状态:不像ProcessWindowFunction那样需要把窗口内收到的所有消息都作为状态存储起来
完整代码参见:
package wikiedits.func;
import java.text.SimpleDateFormat;
import java.util.Date;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.triggers.ContinuousProcessingTimeTrigger;
public class AggregateFunctionAndTiggerDemo {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 使用处理时间
env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);
env.enableCheckpointing(60000, CheckpointingMode.EXACTLY_ONCE);
env.setStateBackend(new FsStateBackend("file:///D:/tmp/flink/checkpoint/aggregatetrigger"));
// 并行度为1
env.setParallelism(1);
// 设置数据源,一共三个元素
DataStream<Tuple2<String, Integer>> dataStream = env.addSource(new SourceFunction<Tuple2<String, Integer>>() {
@Override
public void run(SourceContext<Tuple2<String, Integer>> ctx) throws Exception {
int xxxNum = 0;
int yyyNum = 0;
for (int i = 1; i < Integer.MAX_VALUE; i++) {
// 只有XXX和YYY两种name
String name = (0 == i % 2) ? "XXX" : "YYY";
// 更新aaa和bbb元素的总数
if (0 == i % 2) {
xxxNum++;
} else {
yyyNum++;
}
// 使用当前时间作为时间戳
long timeStamp = System.currentTimeMillis();
// 将数据和时间戳打印出来,用来验证数据
if (xxxNum % 2000 == 0) {
System.out.println(String.format("source,%s, %s, XXX total : %d, YYY total : %d\n", name,
time(timeStamp), xxxNum, yyyNum));
}
// 发射一个元素,并且戴上了时间戳
ctx.collectWithTimestamp(new Tuple2<String, Integer>(name, 1), timeStamp);
// 每发射一次就延时1秒
Thread.sleep(1);
}
}
@Override
public void cancel() {}
});
// 将数据用5秒的滚动窗口做划分,再用ProcessWindowFunction
SingleOutputStreamOperator<Tuple2<String, Integer>> mainDataStream = dataStream
// 以Tuple2的f0字段作为key,本例中实际上key只有aaa和bbb两种
.keyBy(value -> value.f0)
// 5秒一次的滚动窗口
.timeWindow(Time.minutes(5))
// 10s触发一次计算,更新统计结果
.trigger(ContinuousProcessingTimeTrigger.of(Time.seconds(10)))
// 统计每个key当前窗口内的元素数量,然后把key、数量、窗口起止时间整理成字符串发送给下游算子
.aggregate(
new AggregateFunction<Tuple2<String, Integer>, Tuple2<String, Integer>, Tuple2<String, Integer>>() {
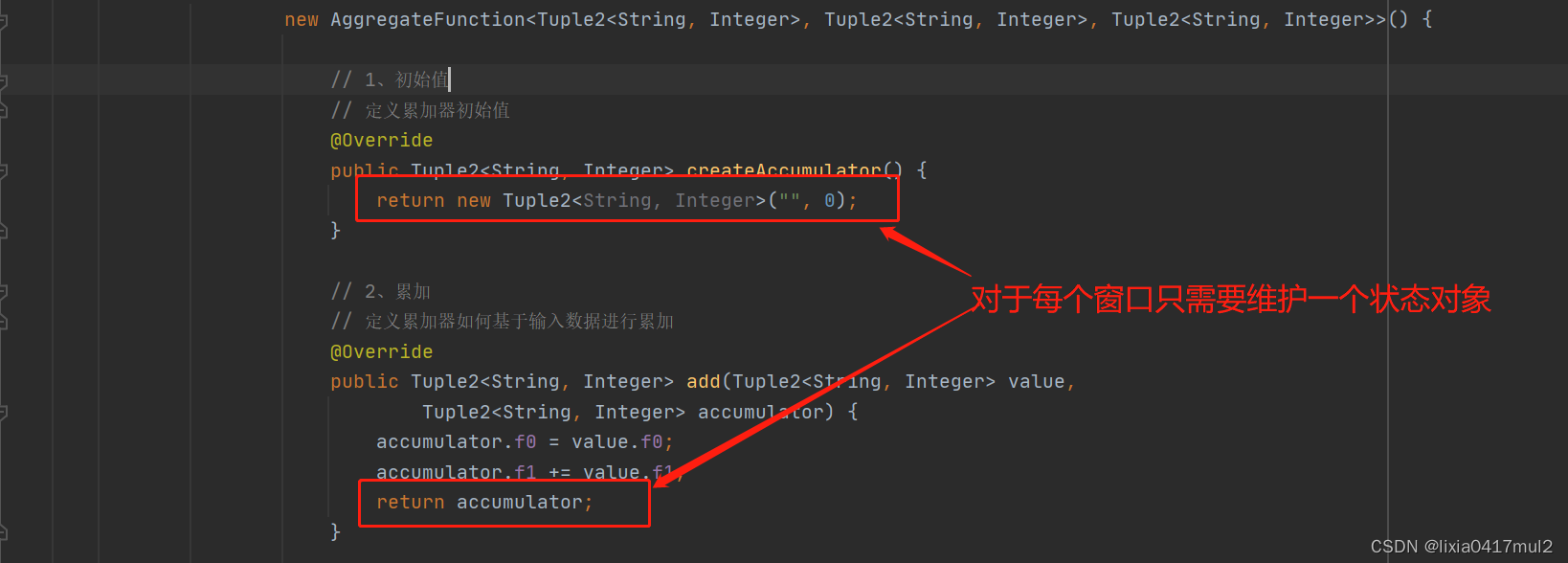
// 1、初始值
// 定义累加器初始值
@Override
public Tuple2<String, Integer> createAccumulator() {
return new Tuple2<String, Integer>("", 0);
}
// 2、累加
// 定义累加器如何基于输入数据进行累加
@Override
public Tuple2<String, Integer> add(Tuple2<String, Integer> value,
Tuple2<String, Integer> accumulator) {
accumulator.f0 = value.f0;
accumulator.f1 += value.f1;
return accumulator;
}
// 3、合并
// 定义累加器如何和State中的累加器进行合并
@Override
public Tuple2<String, Integer> merge(Tuple2<String, Integer> acc1,
Tuple2<String, Integer> acc2) {
acc1.f1 += acc2.f1;
return acc1;
}
// 4、输出
// 定义如何输出数据
@Override
public Tuple2<String, Integer> getResult(Tuple2<String, Integer> accumulator) {
return accumulator;
}
});
// 打印结果,通过分析打印信息,检查ProcessWindowFunction中可以处理所有key的整个窗口的数据
mainDataStream.print();
env.execute("processfunction demo : processwindowfunction");
}
public static String time(long timeStamp) {
return new SimpleDateFormat("yyyy-MM-dd hh:mm:ss").format(new Date(timeStamp));
}
}
通过这种方式我们就可以做到统计某个页面一天内至今为止的点击率,每10s输出一次点击率的结果,并且不会引起状态膨胀的问题
参考文献:
https://www.cnblogs.com/Springmoon-venn/p/13667023.html