前面3篇的优化思路是从硬件本身和函数库这些方向去加速, 本文则仅从代码本身的效率去考虑加速的方法。
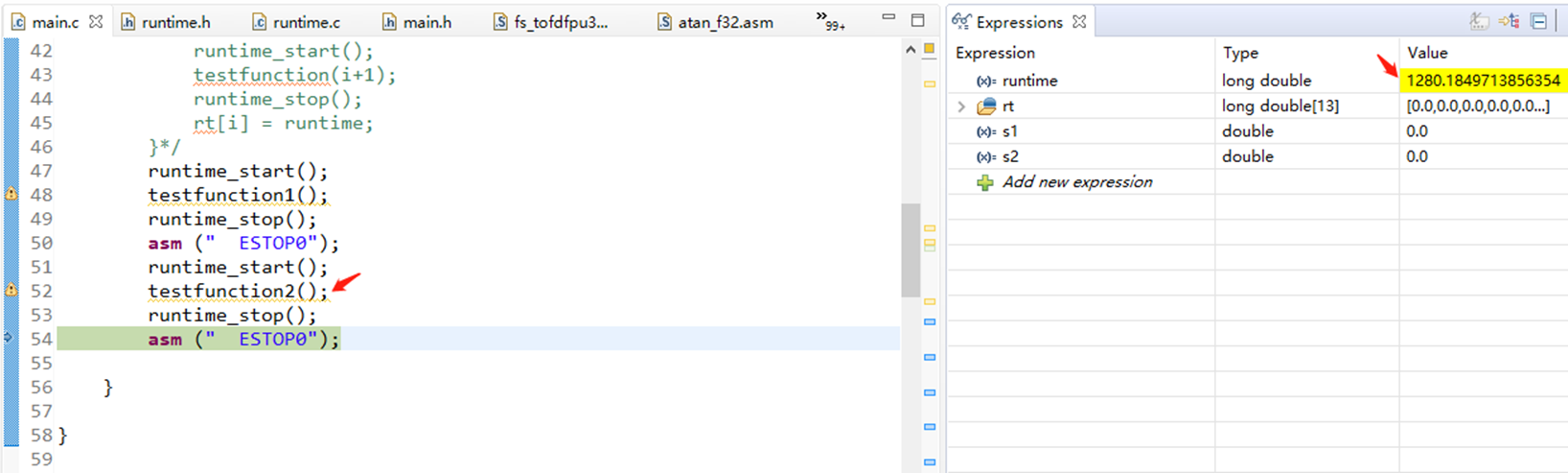
1、用全局变量比用局部变量快
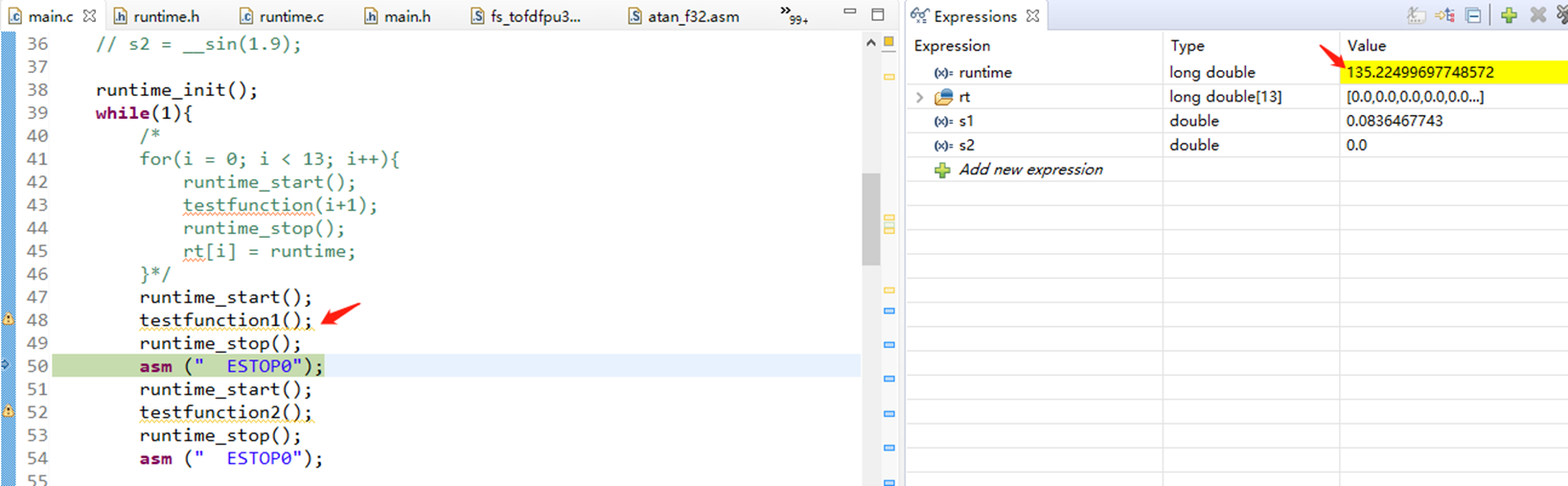
void testfunction1(){ // 局部变量
int i;
double s,a,b;
a = 1.023;
b = 12.23;
for(i = 0; i < 1000; i++){
s = __divf32(a,b);
}
}
int i1;
double s1,a1,b1;
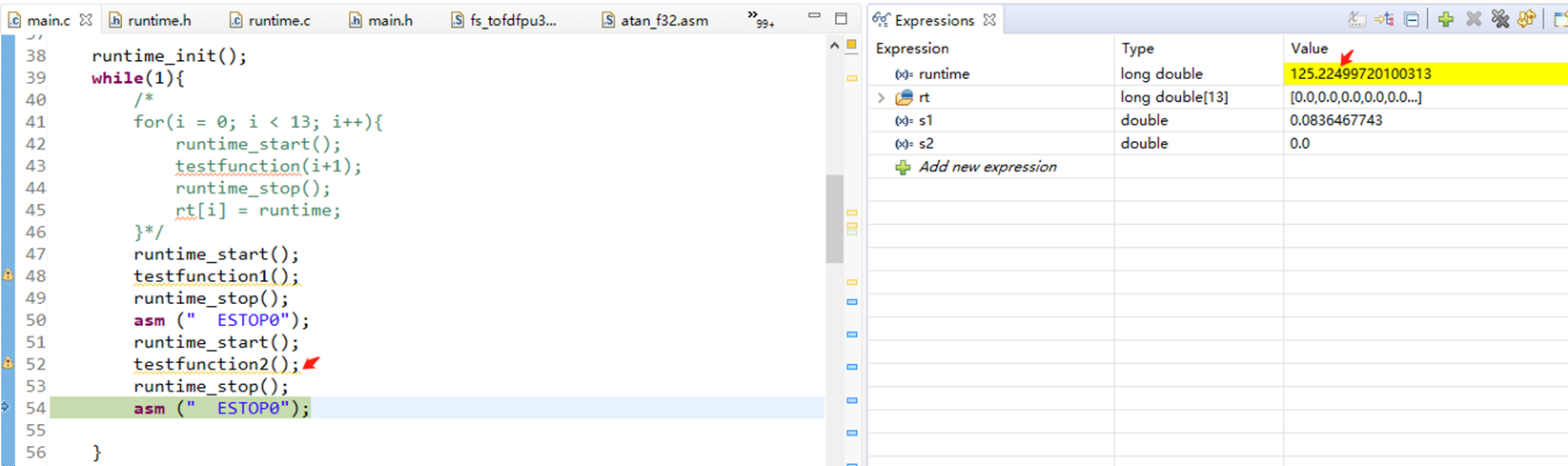
void testfunction2(){ // 全局变量
a1 = 1.023;
b1 = 12.23;
for(i1 = 0; i1 < 1000; i1++){
s1 = __divf32(a1,b1);
}
}
2、用指针增量操作代替数组下标寻址
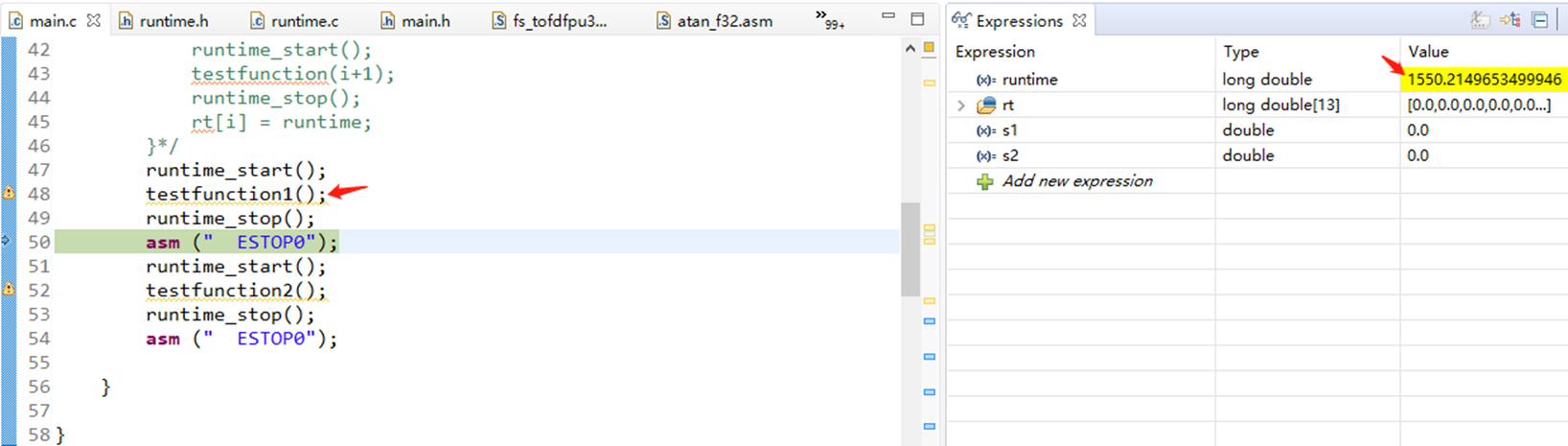
double a[10] = {0.1,0.2,0.3,0.4,0.5,0.1,0.2,0.3,0.4,0.5};
double *p = a;
void testfunction1(){ // 数组下标
int i,j;
double s;
for(i = 0; i < 1000; i++){
for(j = 0; j < 10; j++){
s = __sqrt(a[j]);
}
}
}
void testfunction2(){ // 指针增量
int i,j;
double s;
for(i = 0; i < 1000; i++){
p = a;
for(j = 0; j < 10; j++){
s = __sqrt(*p++);
}
}
}
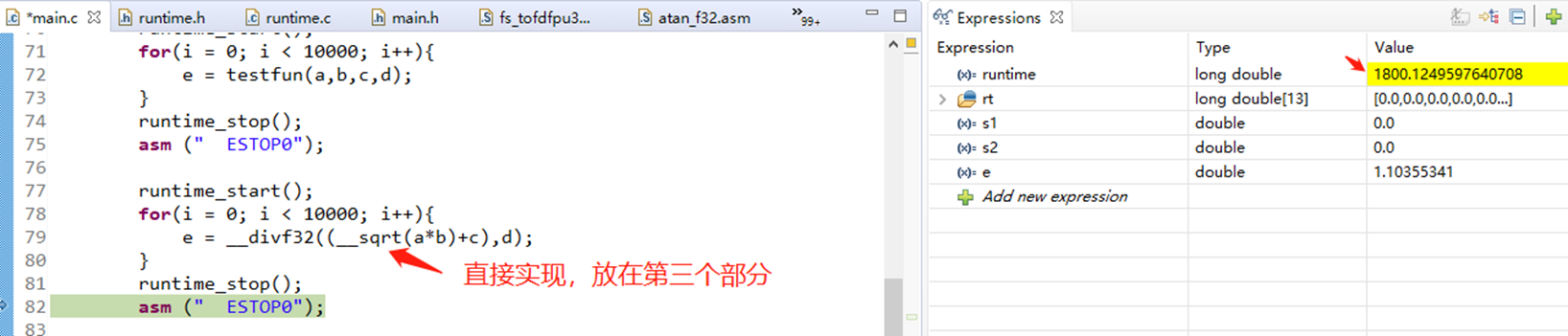
3、尽量少用函数,用宏函数或者直接实现来替代函数
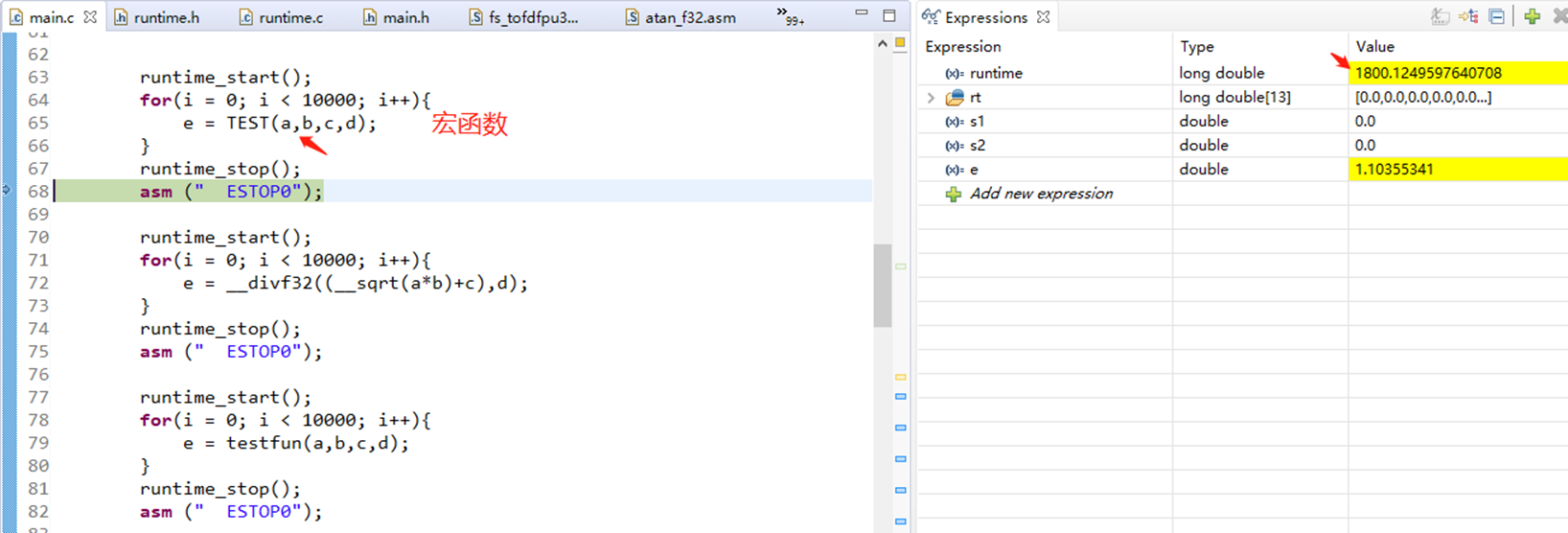
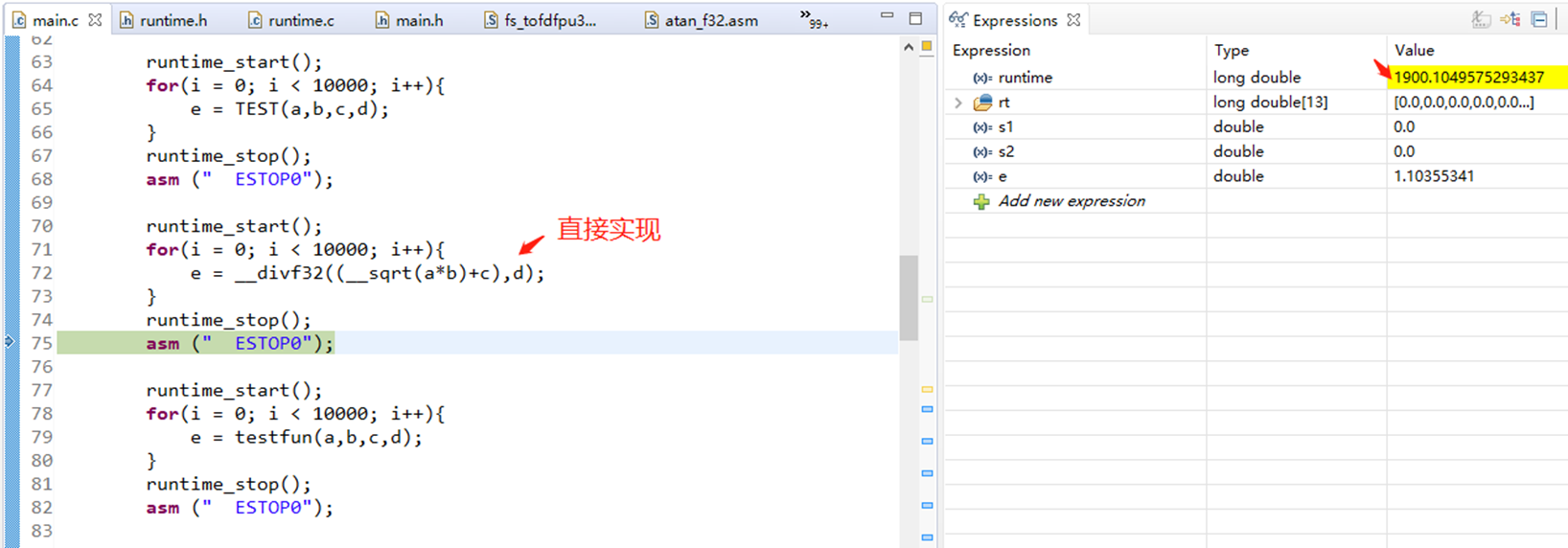
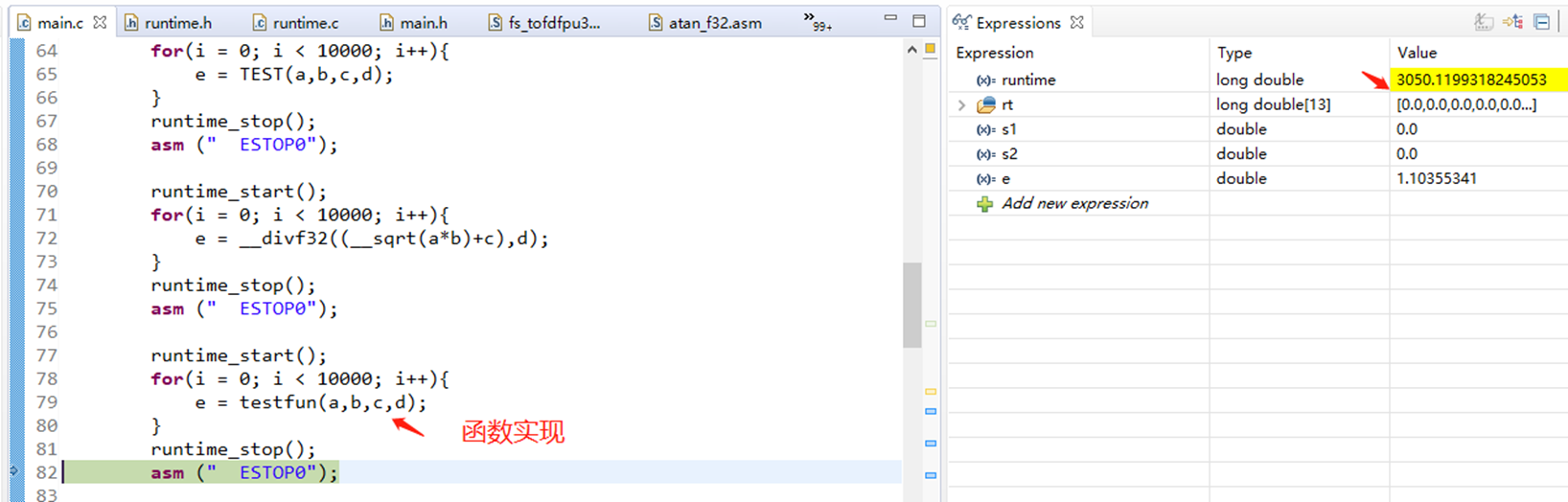
double a = 1.0;
double b = 2.0;
double c = 3.0;
double d = 4.0;
double e = 0;
#define TEST(a,b,c,d) (__divf32((__sqrt(a*b)+c),d))
double testfun(double a, double b,double c, double d){
return __divf32((__sqrt(a*b)+c),d);
}
注:直接实现和用宏定义的函数应该时间是一样或者说是很接近的,没有优劣之分。 1800和1900的差别应该是测试方法有些不可控因素导致的。如果把直接实现的代码放在第三个部分,它也1800us。
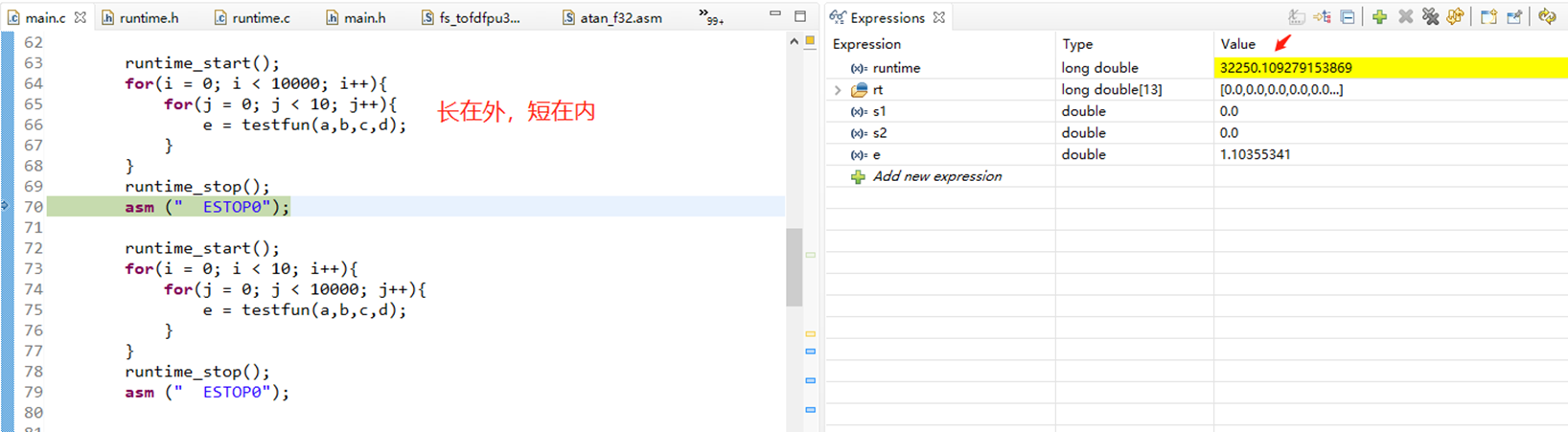
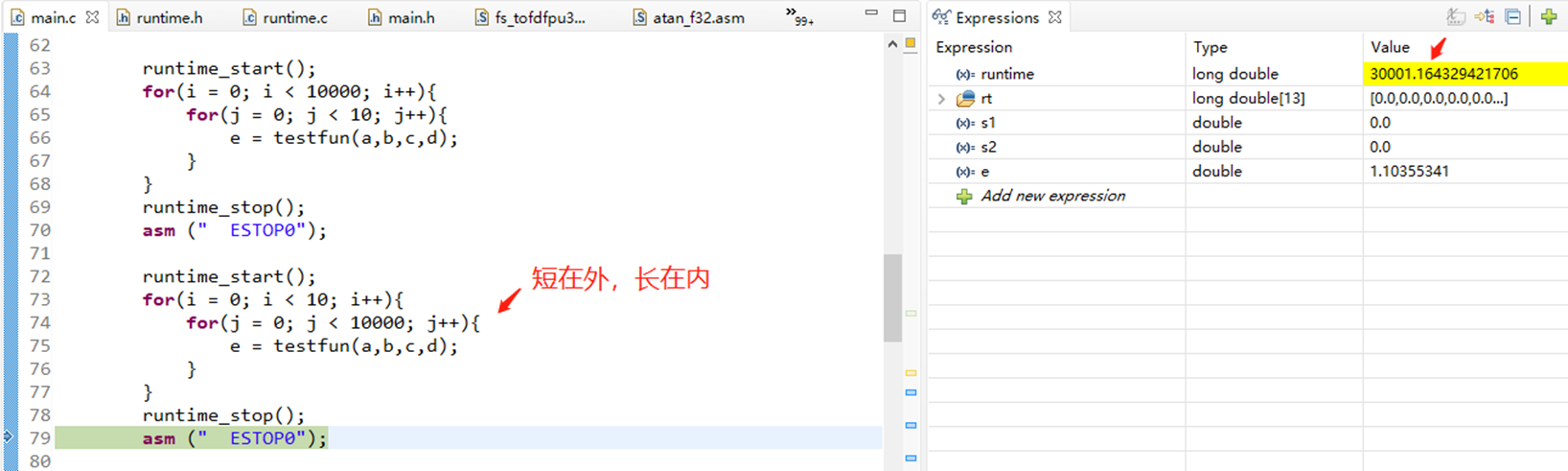
4 多重循环长循环放在内层,短循环放在外层
在系统的多重循环过程中,需要程序员将最长的循环内容设置在系统的最内层,同时需要将最短的循环内容设置在系统的最外层。这样,能够有效提升CPU的运行效率,促进CPU的跨切循环次数。
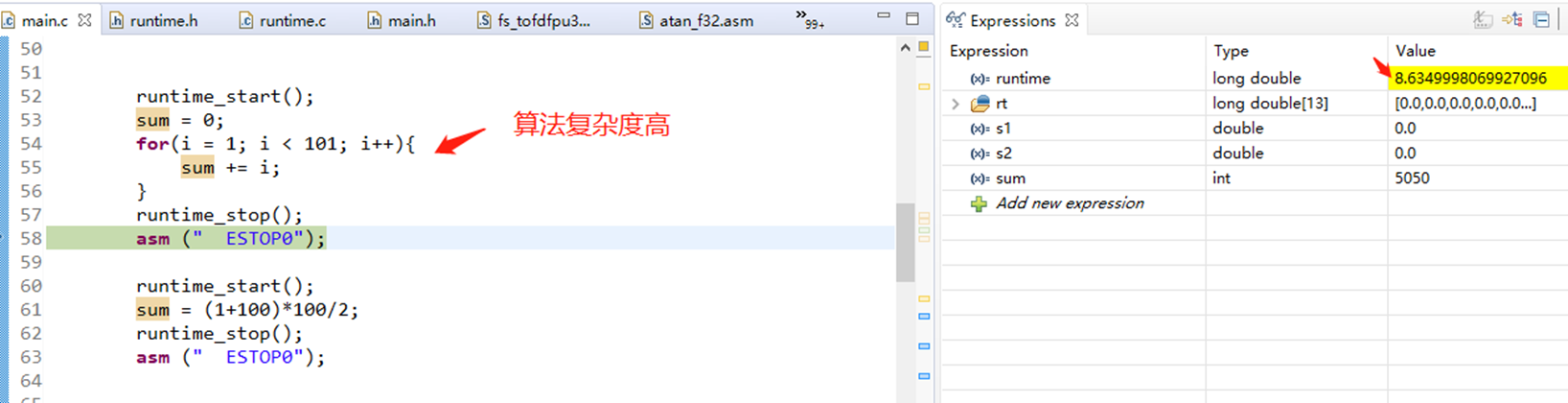
5 从算法本身的复杂度去优化
假设我要计算 1+2+…+100
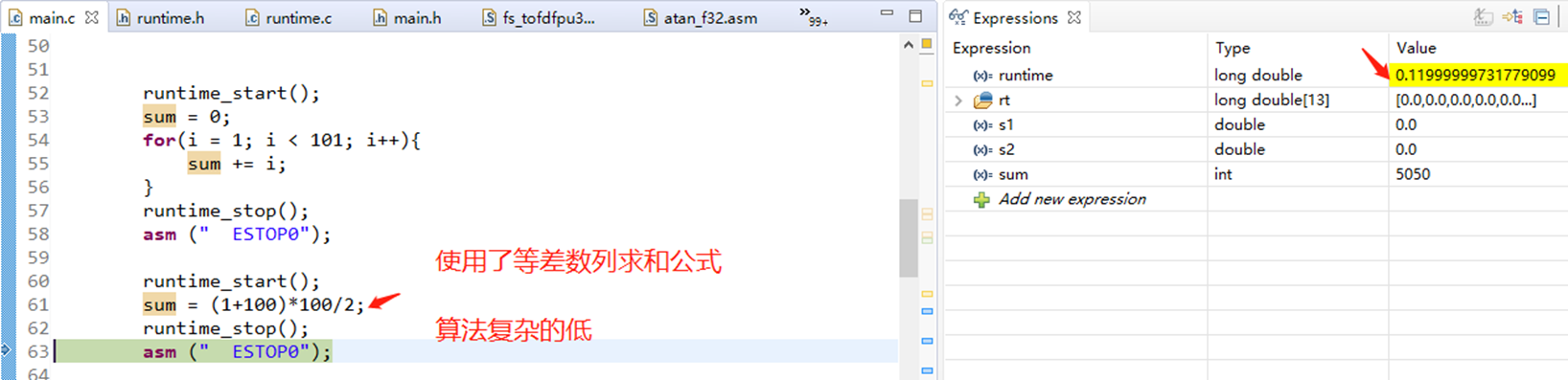
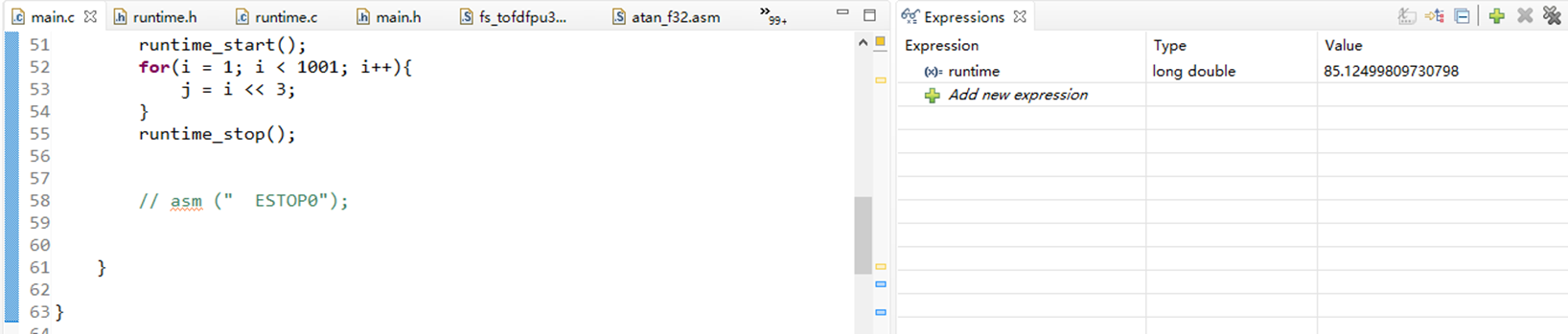
6 整数的乘除用位移运算替代
从DSP的测试结果来看,位移运算和乘法时间一模一样,根本没区别。不推荐使用。

7 通信优化
DSP经常会用到串口通信,串口发送主要优化思路是去掉多余的赋值语句和循环语句。

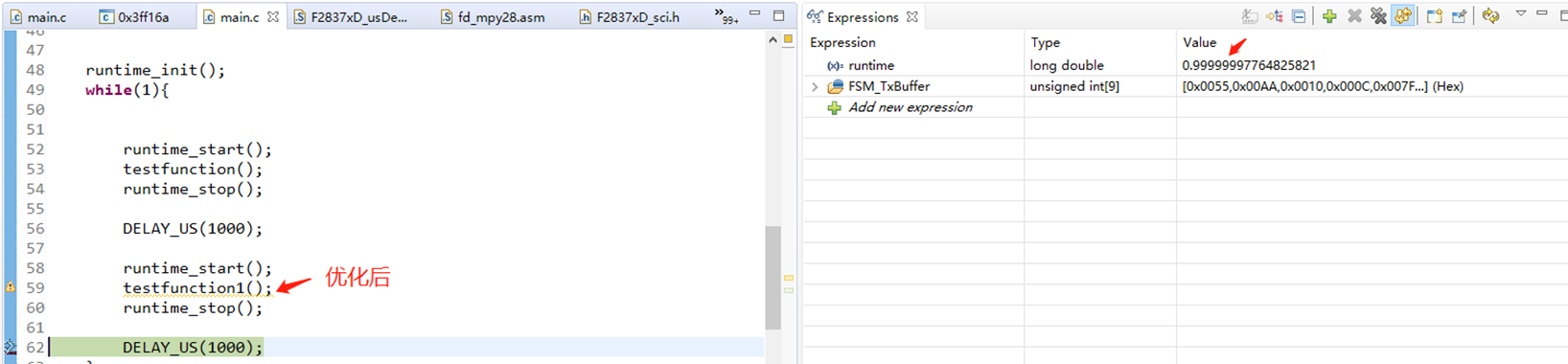
float fDrivex = 0.15;
float fDrivey = -0.3;
Uint16 FSM_TxBuffer[9]={0,0,0,0,0,0,0,0,0};
struct _FSM_com_struct_
{
Uint16 sHeader;
Uint16 controlmode;
int iEddyx;
int iEddyy;
Uint16 Check;
Uint16 tail;
}FSM_Tx_struct;
void testfunction(){ // 优化前
int i = 0;
FSM_Tx_struct.iEddyx = (int16)(fDrivex * 21333.33);
FSM_Tx_struct.iEddyy = (int16)(fDrivey * 21333.33);
FSM_TxBuffer[0] = 0x55;
FSM_TxBuffer[1] = 0xAA;
FSM_TxBuffer[2] = 0x10;
FSM_TxBuffer[8] = 0xCC;
FSM_TxBuffer[3] = ( (Uint16)(FSM_Tx_struct.iEddyx) >> 8);
FSM_TxBuffer[4] = ( (Uint16)(FSM_Tx_struct.iEddyx) & 0x00FF);
FSM_TxBuffer[5] = ( (Uint16)(FSM_Tx_struct.iEddyy) >> 8);
FSM_TxBuffer[6] = ( (Uint16)(FSM_Tx_struct.iEddyy) & 0x00FF);
FSM_TxBuffer[7] = 0xFF ^ FSM_TxBuffer[2] ^ FSM_TxBuffer[3] ^ FSM_TxBuffer[4] ^ FSM_TxBuffer[5] ^ FSM_TxBuffer[6];
for(i = 0; i < 9; i++)
{
ScicRegs.SCITXBUF.all = FSM_TxBuffer[i];
while (ScicRegs.SCICTL2.bit.TXRDY == 0);
}
}
float fDrivex = 0.15;
float fDrivey = -0.3;
Uint16 FSM_TxBuffer[9]={0,0,0,0,0,0,0,0,0};
struct _SCI_TX_struct_
{
int iEddyx;
int iEddyy;
};
struct _TxBUF_struct_
{
Uint16 Low:8;
Uint16 High:8;
};
union sciTxunion {
struct _TxBUF_struct_ TxBUF[2];
struct _SCI_TX_struct_ bit;
} FSM_Tx_union;
void testfunction1(){ // 优化后
FSM_Tx_union.bit.iEddyx = (int16)(fDrivex * 21333.33);
FSM_Tx_union.bit.iEddyy = (int16)(fDrivey * 21333.33);
ScicRegs.SCITXBUF.all = 0x55;
while (ScicRegs.SCICTL2.bit.TXRDY == 0);
ScicRegs.SCITXBUF.all = 0xAA;
while (ScicRegs.SCICTL2.bit.TXRDY == 0);
ScicRegs.SCITXBUF.all = 0x10;
while (ScicRegs.SCICTL2.bit.TXRDY == 0);
ScicRegs.SCITXBUF.all = FSM_Tx_union.TxBUF[0].High;
while (ScicRegs.SCICTL2.bit.TXRDY == 0);
ScicRegs.SCITXBUF.all = FSM_Tx_union.TxBUF[0].Low;
while (ScicRegs.SCICTL2.bit.TXRDY == 0);
ScicRegs.SCITXBUF.all = FSM_Tx_union.TxBUF[1].High;
while (ScicRegs.SCICTL2.bit.TXRDY == 0);
ScicRegs.SCITXBUF.all = FSM_Tx_union.TxBUF[1].Low;
while (ScicRegs.SCICTL2.bit.TXRDY == 0);
ScicRegs.SCITXBUF.all = 0xEF ^ FSM_Tx_union.TxBUF[0].High ^ FSM_Tx_union.TxBUF[0].Low ^ FSM_Tx_union.TxBUF[1].High ^ FSM_Tx_union.TxBUF[1].Low;
while (ScicRegs.SCICTL2.bit.TXRDY == 0);
ScicRegs.SCITXBUF.all = 0xCC;
while (ScicRegs.SCICTL2.bit.TXRDY == 0);
}
串口接收主要优化思路也是去掉多余的赋值语句,另外,去掉多余的逻辑判断。
// 优化前
interrupt void getScic(void){
int i = 0;
FSMRxCheck = 0xFF;
for(i = 0; i < 9; i++)
{
FSM_RxBuffer[i] = ScicRegs.SCIRXBUF.all;
if(i > 1 && i<7){
FSMRxCheck ^= FSM_RxBuffer[i];
}
}
FSMRxCheck = FSMRxCheck & 0x00FF;
FSM_Rx_Cnt = FSM_Rx_Cnt + 1;
ScicRegs.SCIFFRX.bit.RXFIFORESET = 0; // 0: Write 0 to reset the FIFO pointer to zero, and hold in reset.
ScicRegs.SCIFFRX.bit.RXFIFORESET = 1; // 1: Re-enable receive FIFO operation
ScicRegs.SCIFFRX.bit.RXFFINTCLR = 1; // 1: Write 1 to clear RXFFINT flag in bit 7
PieCtrlRegs.PIEACK.all = PIEACK_GROUP8; // Writing a 1 to the respective interrupt bit clears the bit and enables the PIE block to drive a pulse into
// the CPU interrupt input if an interrupt is pending for that group.
}
void getEddy(void){
FSM_Rx_struct.sHeader = ( FSM_RxBuffer[0] << 8 ) + FSM_RxBuffer[1];
FSM_Rx_struct.controlmode = FSM_RxBuffer[2];
FSM_Rx_struct.iEddyx = (int)( ( FSM_RxBuffer[3] << 8) + FSM_RxBuffer[4] );
FSM_Rx_struct.iEddyy = (int)( ( FSM_RxBuffer[5] << 8) + FSM_RxBuffer[6] );
FSM_Rx_struct.Check = FSM_RxBuffer[7];
FSM_Rx_struct.tail = FSM_RxBuffer[8];
if(FSM_Rx_struct.sHeader == 0x55AA && FSM_Rx_struct.tail == 0xCC && FSMRxCheck == FSM_Rx_struct.Check){
fEddyx = (float)FSM_Rx_struct.iEddyx * 0.000046875;
fEddyy = (float)FSM_Rx_struct.iEddyy * 0.000046875;
//asm (" ESTOP0");
}
}
// 优化后
Uint16 FSMRxCheck = 0x00FF;
interrupt void getScic(void){
int i = 0;
for(i = 0; i < 9; i++)
{
FSM_RxBuffer[i] = ScicRegs.SCIRXBUF.all;
if(i > 1 && i<7){
FSMRxCheck ^= FSM_RxBuffer[i];
}
}
DecodeEn = 1;
ScicRegs.SCIFFRX.bit.RXFIFORESET = 0; // 0: Write 0 to reset the FIFO pointer to zero, and hold in reset.
ScicRegs.SCIFFRX.bit.RXFIFORESET = 1; // 1: Re-enable receive FIFO operation
ScicRegs.SCIFFRX.bit.RXFFINTCLR = 1; // 1: Write 1 to clear RXFFINT flag in bit 7
PieCtrlRegs.PIEACK.all = PIEACK_GROUP8; // Writing a 1 to the respective interrupt bit clears the bit and enables the PIE block to drive a pulse into
// the CPU interrupt input if an interrupt is pending for that group.
}
void getEddy(void){
if( FSMRxCheck==FSM_RxBuffer[7] ){
fEddyx = (float)( (FSM_RxBuffer[3]<<8) + FSM_RxBuffer[4] ) * 0.000046875;
fEddyy = (float)( (FSM_RxBuffer[5]<<8) + FSM_RxBuffer[6] ) * 0.000046875;
FSMRxCheck = 0x00FF;
}
}
后续暂时是不会再写DSP算法加速的方法了。 感谢您的阅读,如果您还有什么优化的方法和思路,欢迎留言分享、收藏、点赞。