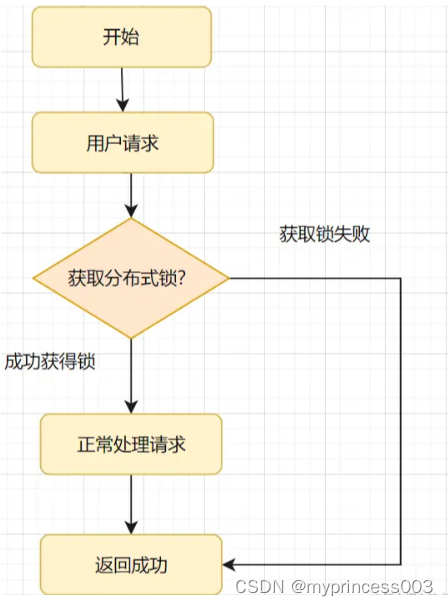
Windows系统下MMDeploy预编译包的使用
MMDeploy步入v1版本后安装/使用难度大幅下降,这里以部署MMDetection项目的Faster R-CNN模型为例,将PyTorch模型转换为ONNX进而转换为Engine模型,部署到TensorRT后端,实现高效推理,主要参考了官方文档。
说明:制作本教程时,MMDeploy版本是v1.2.0
本机环境
-
Windows 11
-
Powershell 7
-
Visual Studio 2019
-
CUDA版本:11.7
-
CUDNN版本:8.6
-
Python版本:3.8
-
PyTorch版本:1.13.1
-
TensorRT版本:v8.5.3.1
-
mmdeploy版本:v1.2.0
-
mmdet版本:v3.0.0
1. 准备环境
每一步网上教程比较多,不多描述
-
安装
Visual Studio 2019,勾选C++桌面开发,一定要选中Win10 SDK,貌似现在还不支持VS2022 -
安装CUDA&CUDNN
- 注意版本对应关系
- 一定要先安装VS2019,否则
visual studio Integration无法安装成功,后面会报错 - 默认安装选项即可,如果不是默认安装,一定要勾选
visual studio Integration
-
Anaconda3/MiniConda3
安装完毕后,创建一个环境
conda create -n faster-rcnn-deploy python=3.8 -y conda activate faster-rcnn-deploy -
安装GPU版本的PyTorch
pip install torch==1.13.1+cu117 torchvision==0.14.1+cu117 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu117 -
安装OpenCV-Python
pip install opencv-python
2. 安装TensorRT
登录官网下载即可,这里直接给出我用的链接
https://developer.nvidia.com/downloads/compute/machine-learning/tensorrt/secure/8.5.3/zip/TensorRT-8.5.3.1.Windows10.x86_64.cuda-11.8.cudnn8.6.zip
下载完成后,解压,进入解压的文件夹
-
新建一个用户/系统变量
TENSORRT_DIR,值为当前目录 -
然后重启powershell,激活环境,此时可用
$env:TENSORRT访问TensorRT安装目录 -
将
$env:TENSORRT_DIR\lib加入PATH路径 -
然后重启powershell,激活环境
-
安装对应python版本的wheel包
pip install $env:TENSORRT_DIR\python\tensorrt-8.5.3.1-cp38-none-win_amd64.whl -
安装pycuda
pip install pycuda
3. 安装mmdeploy及runtime
-
mmdeploy:模型转换API
-
runtime:模型推理API
pip install mmdeploy==1.2.0 pip install mmdeploy-runtime-gpu==1.2.0
4. 克隆MMDeploy仓库
新建一个文件夹,后面所有的仓库/文件均放在此目录下
克隆mmdeploy仓库主要是需要用到里面的配置文件
git clone -b main https://github.com/open-mmlab/mmdeploy.git
5. 安装MMDetection
需要先安装MMCV:
pip install -U openmim
mim install "mmcv>=2.0.0rc2"
克隆并编译安装mmdet:
git clone https://github.com/open-mmlab/mmdetection.git
cd mmdetection
git checkout v3.0.0
pip install -v -e .
cd ..
4. 进行转换
文件目录如下:
./faster-rcnn-deploy/
├── app.py
├── checkpoints
├── convert.py
├── infer.py
├── mmdeploy
├── mmdeploy_model
├── mmdetection
├── output_detection.png
└── tmp.py
-
部署配置文件:
mmdeploy/configs/mmdet/detection/detection_tensorrt-fp16_dynamic-320x320-1344x1344.py -
模型配置文件:
mmdetection/configs/faster_rcnn/faster-rcnn_r50_fpn_1x_coco.py -
模型权重文件:
checkpoints/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth,这里是用的openmmlab训练好的权重,粘贴到浏览器,或者可以通过windows下的 wget 下载:wget -P checkpoints https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth -
测试图片文件:
mmdetection/demo/demo.jpg -
保存目录:
mmdeploy_model/faster-rcnn-deploy-fp16
convert.py内容如下:
from mmdeploy.apis import torch2onnx
from mmdeploy.apis.tensorrt import onnx2tensorrt
from mmdeploy.backend.sdk.export_info import export2SDK
import os
img = "mmdetection/demo/demo.jpg"
work_dir = "mmdeploy_model/faster-rcnn-deploy-fp16"
save_file = "end2end.onnx"
deploy_cfg = "mmdeploy/configs/mmdet/detection/detection_tensorrt-fp16_dynamic-320x320-1344x1344.py"
model_cfg = "mmdetection/configs/faster_rcnn/faster-rcnn_r50_fpn_1x_coco.py"
model_checkpoint = "checkpoints/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth"
device = "cuda"
# 1. convert model to IR(onnx)
torch2onnx(img, work_dir, save_file, deploy_cfg, model_cfg, model_checkpoint, device)
# 2. convert IR to tensorrt
onnx_model = os.path.join(work_dir, save_file)
save_file = "end2end.engine"
model_id = 0
device = "cuda"
onnx2tensorrt(work_dir, save_file, model_id, deploy_cfg, onnx_model, device)
# 3. extract pipeline info for sdk use (dump-info)
export2SDK(deploy_cfg, model_cfg, work_dir, pth=model_checkpoint, device=device)
运行结果:
[08/30/2023-17:36:13] [TRT] [I] [MemUsageChange] TensorRT-managed allocation in building engine: CPU +84, GPU +109, now: CPU 84, GPU 109 (MiB)
5. 推理测试
infer.py内容如下:
from mmdeploy.apis import inference_model
deploy_cfg = "mmdeploy/configs/mmdet/detection/detection_tensorrt-fp16_dynamic-320x320-1344x1344.py"
model_cfg = "mmdetection/configs/faster_rcnn/faster-rcnn_r50_fpn_1x_coco.py"
backend_files = ["mmdeploy_model/faster-rcnn-fp16/end2end.engine"]
img = "mmdetection/demo/demo.jpg"
device = "cuda"
result = inference_model(model_cfg, deploy_cfg, backend_files, img, device)
print(result)
运行结果:
08/30 17:42:43 - mmengine - INFO - Successfully loaded tensorrt plugins from F:\miniconda3\envs\faster-rcnn-deploy\lib\site-packages\mmdeploy\lib\mmdeploy_tensorrt_ops.dll
08/30 17:42:43 - mmengine - INFO - Successfully loaded tensorrt plugins from F:\miniconda3\envs\faster-rcnn-deploy\lib\site-packages\mmdeploy\lib\mmdeploy_tensorrt_ops.dll
...
...
inference_model每调用一次就会加载一次模型,效率很低,只是用来测试模型可用性,不能用在生产环境。要高效使用模型,可以集成Detector到自己的应用程序里面,一次加载,多次推理。如下:
6. 集成检测器到自己的应用中
app.py内容如下:
from mmdeploy_runtime import Detector
import cv2
# 读取图片
img = cv2.imread("mmdetection/demo/demo.jpg")
# 创建检测器
detector = Detector(
model_path="mmdeploy_model/faster-rcnn-deploy-fp16",
device_name="cuda",
device_id=0,
)
# 执行推理
bboxes, labels, _ = detector(img)
# 使用阈值过滤推理结果,并绘制到原图中
indices = [i for i in range(len(bboxes))]
for index, bbox, label_id in zip(indices, bboxes, labels):
[left, top, right, bottom], score = bbox[0:4].astype(int), bbox[4]
if score < 0.3:
continue
cv2.rectangle(img, (left, top), (right, bottom), (0, 255, 0))
cv2.imwrite("output_detection.png", img)
调用这个API可以将训练的深度学习模型无缝集成到web后端里面,一次加载,多次推理
原图:

推理检测后: