本文通过ChnSentiCorp数据集介绍了文本分类任务过程,主要使用预训练语言模型bert-base-chinese直接在测试集上进行测试,也简要介绍了模型训练流程,不过最后没有保存训练好的模型。
一.任务和数据集介绍
1.任务
中文情感分类本质还是一个文本分类问题。
2.数据集
本文使用ChnSentiCorp情感分类数据集,每条数据中包括一句购物评价,以及一个标识,表明这条评价是一条好评还是一条差评。被评价的商品主要是书籍、酒店、计算机配件等。一些例子如下所示:

二.模型架构
基本思路是先特征抽取,然后进行下游任务。前者主要是RNN、LSTM、GRU、BERT、GPT、Transformers等模型,后者本质就是分类模型,比如全连接神经网络等。
三.实现代码
1.准备数据集
(1)使用编码工具
def load_encode_tool(pretrained_model_name_or_path):
# 加载编码工具bert-base-chinese
token = BertTokenizer.from_pretrained(Path(f'{pretrained_model_name_or_path}'))
# print(token)
return token
if __name__ == '__main__':
# 测试编码工具
pretrained_model_name_or_path = r'L:\20230713_HuggingFaceModel\bert-base-chinese'
token = load_encode_tool(pretrained_model_name_or_path)
print(token)
输出结果如下所示:
BertTokenizer(name_or_path='L:\20230713_HuggingFaceModel\bert-base-chinese', vocab_size=21128, model_max_length=1000000000000000019884624838656, is_fast=False, padding_side='right', truncation_side='right', special_tokens={'unk_token': '[UNK]', 'sep_token': '[SEP]', 'pad_token': '[PAD]', 'cls_token': '[CLS]', 'mask_token': '[MASK]'}, clean_up_tokenization_spaces=True)
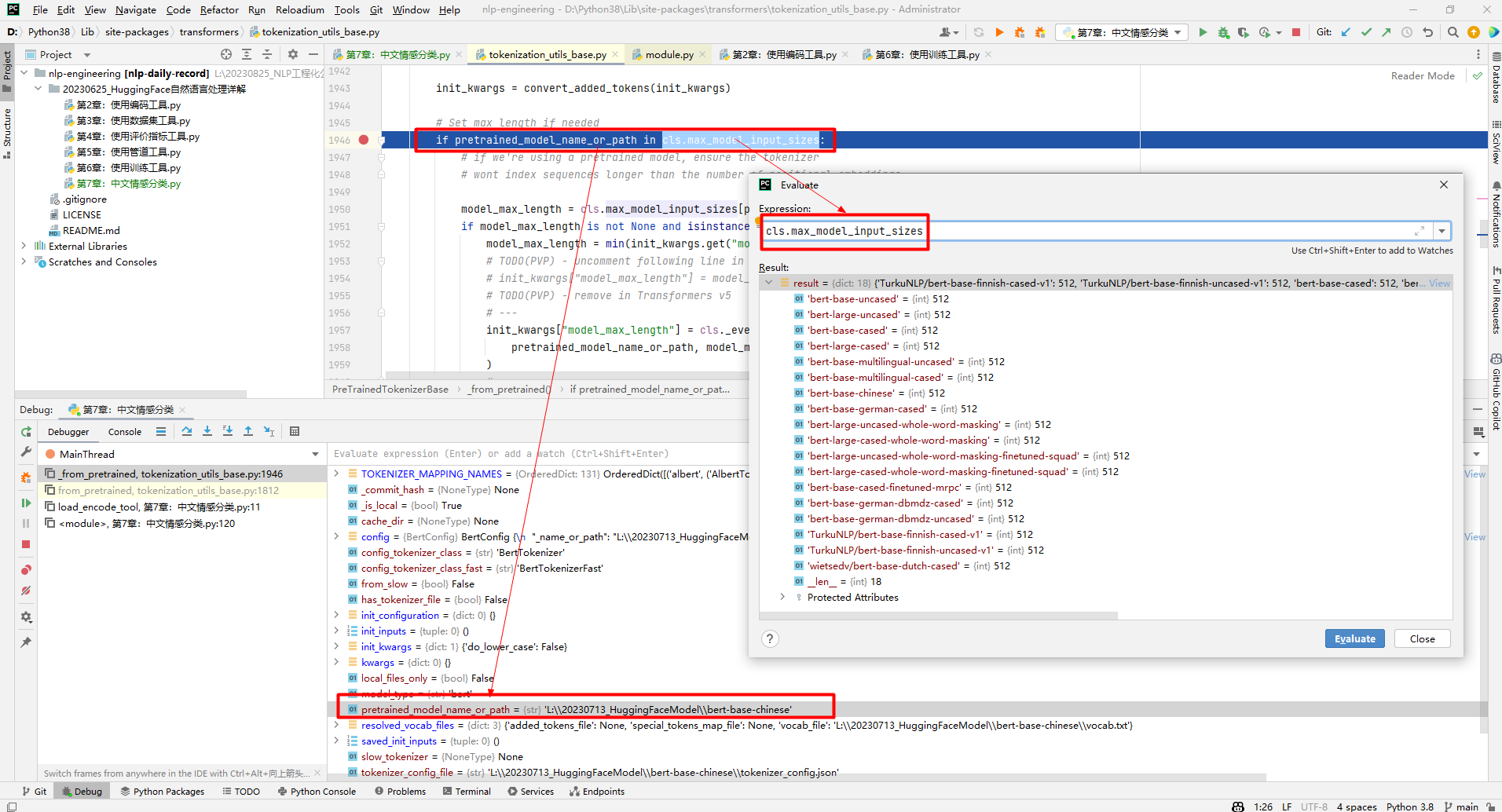
其中,vocab_size=21128表示bert-base-chinese模型的字典中有21128个词,特殊token主要是UNK、SEP、PAD、CLS、MASK。需要说明的是model_max_length,定义为self.model_max_length = model_max_length if model_max_length is not None else VERY_LARGE_INTEGER。因为从本地加载模型,不满足如下条件,所以给model_max_length赋了一个很大的数值,如下所示:
返回值token总的数据结构如下所示:

接下来测试编码工具如下所示:
if __name__ == '__main__':
# 测试编码工具
pretrained_model_name_or_path = r'L:\20230713_HuggingFaceModel\bert-base-chinese'
token = load_encode_tool(pretrained_model_name_or_path)
out = token.batch_encode_plus(
batch_text_or_text_pairs=['从明天起,做一个幸福的人。', '喂马,劈柴,周游世界。'],
truncation=True, # 是否截断
padding='max_length', # 是否填充
max_length=17, # 最大长度,如果不足,那么填充,如果超过,那么截断
return_tensors='pt', # 返回的类型
return_length=True # 返回长度
)
# 查看编码输出
for key, value in out.items():
print(key, value.shape)
# 把编码还原成文本
print(token.decode(out['input_ids'][0]))
输出结果如下所示:
input_ids torch.Size([2, 17])
[CLS] 从 明 天 起 , 做 一 个 幸 福 的 人 。 [SEP] [PAD] [PAD]
token_type_ids torch.Size([2, 17])
[CLS] 从 明 天 起 , 做 一 个 幸 福 的 人 。 [SEP] [PAD] [PAD]
length torch.Size([2])
[CLS] 从 明 天 起 , 做 一 个 幸 福 的 人 。 [SEP] [PAD] [PAD]
attention_mask torch.Size([2, 17])
[CLS] 从 明 天 起 , 做 一 个 幸 福 的 人 。 [SEP] [PAD] [PAD]
其中,out数据结构如下所示:

因此,out['input_ids'][0]表示第一个句子,token.decode(out['input_ids'][0])表示对第一个句子进行解码。input_ids、token_type_ids和attention_mask编码结果示意图如下所示:
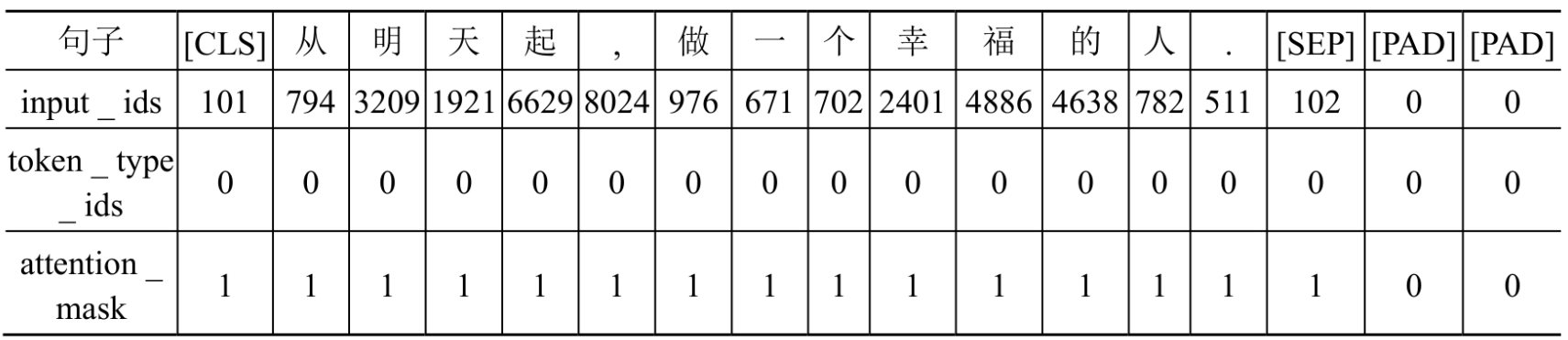
说明:bert-base-chinese编码工具是以字为词,即把每个字都作为一个词进行处理。如果对input_ids、token_type_ids和attention_mask物理意义不清楚的,那么参考使用编码工具。
(2)定义数据集
class Dataset(torch.utils.data.Dataset):
def __init__(self, split):
mode_name_or_path = r'L:\20230713_HuggingFaceModel\ChnSentiCorp'
self.dataset = load_from_disk(mode_name_or_path)[split]
def __len__(self):
return len(self.dataset)
def __getitem__(self, i):
text = self.dataset[i]['text']
label = self.dataset[i]['label']
return text, label
if __name__ == '__main__':
# 加载训练数据集
dataset = Dataset('train')
print(len(dataset), dataset[20])
输出结果如下所示:
9600 ('非常不错,服务很好,位于市中心区,交通方便,不过价格也高!', 1)

(3)定义计算设备
通常做深度学习都会有个N卡,设置CUDA如下所示:
device = 'cpu'
if torch.cuda.is_available():
device = 'cuda'
(4)定义数据整理函数
主要对输入data进行batch_encode_plus(),然后返回input_ids、attention_mask、token_type_ids和labels:
# 数据整理函数
def collate_fn(data):
sents = [i[0] for i in data]
labels = [i[1] for i in data]
# 编码
data = token.batch_encode_plus(batch_text_or_text_pairs=sents, truncation=True, padding='max_length', max_length=500, return_tensors='pt', return_length=True)
# input_ids:编码之后的数字
# attention_mask:补零的位置是0, 其他位置是1
input_ids = data['input_ids']
attention_mask = data['attention_mask']
token_type_ids = data['token_type_ids']
labels = torch.LongTensor(labels)
# 把数据移动到计算设备上
input_ids = input_ids.to(device)
attention_mask = attention_mask.to(device)
token_type_ids = token_type_ids.to(device)
labels = labels.to(device)
return input_ids, attention_mask, token_type_ids, labels
if __name__ == '__main__':
# 测试编码工具
pretrained_model_name_or_path = r'L:\20230713_HuggingFaceModel\bert-base-chinese'
token = load_encode_tool(pretrained_model_name_or_path)
# 定义计算设备
device = 'cpu'
if torch.cuda.is_available():
device = 'cuda'
# 测试数据整理函数
data = [
('你站在桥上看风景', 1),
('看风景的人在楼上看你', 0),
('明月装饰了你的窗子', 1),
('你装饰了别人的梦', 0),
]
input_ids, attention_mask, token_type_ids, labels = collate_fn(data)
print(input_ids.shape, attention_mask.shape, token_type_ids.shape, labels)
结果输出如下所示:
torch.Size([4, 500]) torch.Size([4, 500]) torch.Size([4, 500]) tensor([1, 0, 1, 0], device='cuda:0')
(5)定义数据集加载器
定义数据集加载器使用数据整理函数批量处理数据集中的数据如下所示:
loader = torch.utils.data.DataLoader(dataset=dataset, batch_size=16, collate_fn=collate_fn, shuffle=True, drop_last=True)
- dataset:如果数据集是train dataset,那么就是训练集数据加载器;如果数据集是test dataset,那么就是测试集数据加载器,上述定义的dataset是训练集数据加载器。
- batch_size=16:每个batch包括16条数据。
- collate_fn=collate_fn:使用的数据整理函数
- shuffle=True:打乱各个batch间的顺序,让数据随机
- drop_last=True:当剩余数据不足16条时,丢弃这些尾数
2.定义模型
(1)加载预训练模型
# 查看数据样例
for i, (input_ids, attention_mask, token_type_ids, labels) in enumerate(loader):
break
print(input_ids.shape, attention_mask.shape, token_type_ids.shape, labels)
pretrained_model_name_or_path = r'L:\20230713_HuggingFaceModel\bert-base-chinese'
pretrained = BertModel.from_pretrained(Path(f'{pretrained_model_name_or_path}'))
# 不训练预训练模型,不需要计算梯度
for param in pretrained.parameters():
param.requires_grad_(False)
pretrained.to(device)
out = pretrained(input_ids=input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids)
print(out.last_hidden_state.shape)
输出结果如下所示:
torch.Size([16, 500]) torch.Size([16, 500]) torch.Size([16, 500]) tensor([1, 1, 0, 1, 0, 0, 0, 1, 1, 0, 0, 1, 0, 0, 1, 0], device='cuda:0') #数据整理函数计算结果
torch.Size([16, 500, 768]) #16表示batch size,500表示句子包含词数,768表示向量维度
其中,out是BaseModelOutputWithPoolingAndCrossAttentions对象,包括last_hidden_state和pooler_output两个字段。数据结构如下所示:

(2)定义下游任务模型
该模型是权重为768×2的全连接神经网络,本质就是把768维向量转换为2维。计算过程就是通过模型提取特征矩阵(16×500×768),然后取第1个字[CLS]代表整个文本语义特征,用于下游分类任务等。如下所示:
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
self.fc = torch.nn.Linear(768, 2)
def forward(self, input_ids, attention_mask, token_type_ids):
# 使用预训练模型抽取数据特征
with torch.no_grad():
out = pretrained(input_ids=input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids)
# 对抽取的特征只取第1个字的结果做分类即可
out = self.fc(out.last_hidden_state[:, 0])
out = out.softmax(dim=1)
return out
3.训练和测试
(1)训练
def train():
# 定义优化器
optimizer = AdamW(model.parameters(), lr=5e-4)
# 定义1oss函数
criterion = torch.nn.CrossEntropyLoss()
# 定义学习率调节器
scheduler = get_scheduler(name='linear', num_warmup_steps=0, num_training_steps=len(loader), optimizer=optimizer)
# 将模型切换到训练模式
model.train()
# 按批次遍历训练集中的数据
for i, (input_ids, attention_mask, token_type_ids, labels) in enumerate(loader):
# 模型计算
out = model(input_ids=input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids)
# 计算loss并使用梯度下降法优化模型参数
loss = criterion(out, labels)
loss.backward()
optimizer.step()
scheduler.step()
optimizer.zero_grad()
# 输出各项数据的情况,便于观察
if i % 10 == 0:
out = out.argmax(dim=1)
accuracy = (out == labels).sum().item() / len(labels)
lr = optimizer.state_dict()['param_groups'][0]['lr']
print(i, loss.item(), lr, accuracy)
(2)测试
def test():
# 定义测试数据集加载器
loader_test = torch.utils.data.DataLoader(dataset=Dataset('test'), batch_size=32, collate_fn=collate_fn, shuffle=True, drop_last=True)
# 将下游任务模型切换到运行模式
model.eval()
correct = 0
total = 0
# 按批次遍历测试集中的数据
for i, (input_ids, attention_mask, token_type_ids, labels) in enumerate(loader_test):
# 计算5个批次即可,不需要全部遍历
if i == 5:
break
print(i)
# 计算
with torch.no_grad():
out = model(input_ids=input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids)
# 统计正确率
out = out.argmax(dim=1)
correct += (out == labels).sum().item()
total += len(labels)
print(correct / total)
在PyTorch中,model.train()和model.eval()是用于切换模型训练和评估模式的方法:
- model.train()方法:将模型切换到训练模式,这会启用一些特定的行为,例如梯度下降、权重更新等。在训练模式下,模型会使用训练数据对模型参数进行更新,以最小化损失函数。
- model.eval()方法:将模型切换到评估模式,这会禁用一些在训练模式下启用的行为,例如梯度下降、权重更新等。在评估模式下,模型通常用于对测试数据进行预测,以评估模型的性能。
- param.requires_grad_(False)方法:它和model.eval都可以关闭梯度计算,但两者区别在于param.requires_grad_(False)只关闭单个参数的梯度计算,而model.eval关闭整个模型的梯度计算。
参考文献:
[1]HuggingFace自然语言处理详解:基于BERT中文模型的任务实战
[2]https://huggingface.co/bert-base-chinese/tree/main

![读书笔记-《ON JAVA 中文版》-摘要23[第二十章 泛型-2]](https://img-blog.csdnimg.cn/c140d4cfa7aa43b083c25aae79eed135.gif)




![java八股文面试[多线程]——Synchronized的底层实现原理](https://img-blog.csdnimg.cn/ca21a0072cf44e23a5c218f32cd972c6.png)