文章目录
- 0 Abstract
- 1 Introduction
- 2 Related Work
- 3 Method
- 3.1 Transformer
- 3.2 Relationship Representation
- 3.3 Spatio-Temporal Transformer
- 3.3.1 Spatial Encoder
- 3.3.2 Frame Encoding
- 3.3.3 Temporal Decoder
- 3.4 Loss Function
- 3.5 Graph Generation Strategies
- 4 Experiments
- 4.1 Dataset and Evaluation Metrics
- 4.2 Technical Details
- 4.3 Quantitative Results and Comparison
- 4.4 Temporal Dependency Analysis
- 4.5 Ablation Study
- 4.6 Qualitative Results
- 5 Conclusion
0 Abstract
动态场景图生成的目标是在给定的视频中生成场景图。与静态图片的场景图生成相比之下,它由于动态关系和时间依赖,能够获得更丰富的语义解释。本文提出STTran,包含了spatial encoder和temporal decoder
- spatial encoder:对输入的每一帧提取空间上下文以及视觉关系。
- temporal decoder:以spatial encoder的输出作为输入,从而捕获帧与帧之间的时间依赖关系,并推理动态关系。
STTran能适用于不同时长的视频,尤其是能对长视频能有不错的效果。我们的方法在Action Genome(AG) benchmark数据集上验证,实现了动态场景图生成的SOTA,并对每个模块做了消融实验。
Contributions
- 提出了一个新的框架STTran,对每帧的空间上下文进行编码,并对帧之间时间依赖的视觉关系表征进行解码。
- 不同于大多数相关工作,提出了一个新的策略去生成动态场景图。
- 验证了时间依赖会对关系预测有积极影响,模型提高了视频理解的性能,最终在AG数据集上实现SOTA。
1 Introduction

图1 图片和视频的场景图生成之间的区别
动态场景图生成会利用spatial context和temporal dependencies,每个不同颜色的节点表示不同物体
静态场景图生成是基于一个object detector生成object proposals,然后再推断它们之间的关系以及对象类别。然而,对象不一定在视频序列中是连续的,任意两个对象的关系会随着它们的运动而变化,我们称之为dynamic,因此,静态场景图生成方法无法直接用于动态场景。
2 Related Work
- Scene Graph Generation
- 概念:场景图生成最早在图像检索中提出来,它是一种基于图的表示,描述对象之间的交互,节点表示对象,而边表示关系。
- 应用:图像检索、图像捕获、视觉问答VQA,以及图像生成。
- 不足:现实生活中普遍会出现多样化的交互关系,而大多数任务默认edge预测为single-label分类。这些方法往往是针对静态图像设计的,而为了扩展到视频,Ji等人根据分解视频中的活动,收集了大量的动态场景图,并提高了视频动作识别的SOTA。
- Transformer for Computer Vision
- 在NLP任务上,尤其是大规模预训练语言模型,如GPT、BERT。
- 在视觉-语言任务上,例如image captioning、VQA、Caption-Based Image Retrieval和Visual Commonsense Reasoning(VCR)。最近,提出了DERT用于目标检测和全景分割。
- Transformer用来挖掘视觉信息,取代了传统的CNN backbone。
- 它的核心机制是self-attention building block,通过有选择地关注输入点进行预测,从而捕获不同输入点之间的context和每个点的表征。
- 然而,以前方法都聚焦于学习单张图片中的spatial context,而temporal dependencies在视频理解中是十分重要的。
- Action Transformer中利用了transformer实现了spatio-temporal representations,参考了I3D模型,然后在RPN网络提供的RoI中池化,对视频片段进行人的行为识别。
- 每帧的特征是由CNN backbone提取出来的,输入至transformer encoder,去学习视频序列的时间信息。
- Spatial-Temporal Networks
- Spatial-temporal信息是视频理解的关键,最流行的方法是基于RNN/LSTM的、基于3D ConvNets的框架。
- 基于RNN/LSTM的框架:对每帧按顺序提取特征,并学习时间信息。
- 基于3D ConvNets的框架:利用输入序列的时间维度,扩展了传统的2D卷积(height和width)
- 本工作中,我们不仅利用transformer去学习对象之间的空间context,还学习了帧与帧之间的时间依赖,从而推断随着时间变化的动态关系。
- Spatial-temporal信息是视频理解的关键,最流行的方法是基于RNN/LSTM的、基于3D ConvNets的框架。
3 Method
动态场景图是基于静态场景图的,有一个额外的索引t表示随时间变化的关系。transformer的两个特性:
- 结构是包裹不变的(permutation-invariant)。
- 序列与位置编码兼容。
我们提出一个新模型STTran,能够利用视频中的时空上下文。
3.1 Transformer
Transformer最早由Vaswani提出,它由一叠基于点积注意的多头transformer精炼层组成,每一层中的输入是 X ∈ R N × D X∈R^{N×D} X∈RN×D,N个entityD个维度,通过线性变换为queries( Q = X W Q , W Q ∈ R D × D q Q=XW_Q, W_Q∈R^{D×D_q} Q=XWQ,WQ∈RD×Dq),keys( K = X W K , W K ∈ R D × D k K=XW_K,W_K∈R^{D×D_k} K=XWK,WK∈RD×Dk)以及values( V = X W V , W V ∈ R D × D v V=XW_V,W_V∈R^{D×D_v} V=XWV,WV∈RD×Dv)
注意:
D
q
,
D
k
,
D
v
D_q,D_k,D_v
Dq,Dk,Dv通常在实现中相同,每个entity都通过点积attetion与其他entity进行细化,定义如下:
A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
S
o
f
t
m
a
x
(
Q
K
T
D
k
)
V
Attention(Q,K,V)=Softmax(\frac{QK^T}{\sqrt{D_k}})V
Attention(Q,K,V)=Softmax(DkQKT)V
为了提高attention层的性能,应用的多头注意力定义为:
M
u
l
t
i
H
e
a
d
(
Q
,
K
,
V
)
=
C
o
n
c
a
t
(
h
1
,
.
.
.
,
h
h
)
W
O
MultiHead(Q,K,V)=Concat(h_1,...,h_h)W_O
MultiHead(Q,K,V)=Concat(h1,...,hh)WO
h i = A t t e n t i o n ( X W Q , X W K , X W V i ) h_i=Attention(XW_Q,XW_K,XW_{V_i}) hi=Attention(XWQ,XWK,XWVi)
一个完整的自注意力层包含了如上的self-attention模块,之后是一个残差连接的归一化层和一个前馈层。
后续自注意力层简称为 A t t ( . ) Att(.) Att(.)
本工作中,我们设计了一个时空transformer,探索单帧的空间context、序列的时间dependencies。
3.2 Relationship Representation
我们使用Faster R-CNN作为backbone,对
T
T
T帧的视频
V
=
[
I
1
,
I
2
,
.
.
.
,
I
T
]
V=[I_1,I_2,...,I_T]
V=[I1,I2,...,IT],时间为t时的帧表示为
I
t
I_t
It,detector提取的视觉特征为
{
v
t
1
,
.
.
.
,
v
t
N
(
t
)
}
∈
R
2048
\{v_t^1,...,v_t^{N(t)}\}∈R^{2048}
{vt1,...,vtN(t)}∈R2048,bounding boxes为
{
b
t
1
,
.
.
.
,
b
t
N
(
t
)
}
\{b_t^1,...,b_t^{N(t)}\}
{bt1,...,btN(t)},对象种类分布为
{
d
t
1
,
.
.
.
,
d
t
N
(
t
)
}
\{d_t^1,...,d_t^{N(t)}\}
{dt1,...,dtN(t)},其中
N
(
t
)
N(t)
N(t)表示该帧下对象的数量。在每帧的
N
(
t
)
N(t)
N(t)个对象之间有一组关系向量
R
t
=
{
r
t
1
,
.
.
.
,
r
t
K
(
t
)
}
R_t=\{r_t^1,...,r_t^{K(t)}\}
Rt={rt1,...,rtK(t)},第i和j个对象之间的
r
t
k
r_t^k
rtk关系对应的表征向量
x
t
k
x_t^k
xtk包含了视觉外观、空间信息、和语义嵌入,公式如下:
x
t
k
=
<
W
s
v
t
i
,
W
o
v
t
j
,
W
u
ϕ
(
u
t
i
,
j
⊕
f
b
o
x
(
b
t
i
,
b
t
j
)
)
,
s
t
i
,
s
t
j
>
x_t^k=<W_sv_t^i,W_ov_t^j,W_u\phi(u_t^{i,j}⊕f_{box}(b_t^i,b_t^j)),s_t^i,s_t^j>
xtk=<Wsvti,Wovtj,Wuϕ(uti,j⊕fbox(bti,btj)),sti,stj>
其中,
<
,
>
<,>
<,>表示连接操作,
ϕ
\phi
ϕ表示扁平操作、
⊕
⊕
⊕表示逐元素加法,
W
s
,
W
o
∈
R
2048
×
512
,
W
u
∈
R
12544
×
512
W_s,W_o∈R^{2048×512},W_u∈R^{12544×512}
Ws,Wo∈R2048×512,Wu∈R12544×512表示维度压缩的线性矩阵。
u
t
i
,
j
∈
R
256
×
7
×
7
u_t^{i,j}∈R^{256×7×7}
uti,j∈R256×7×7表示RoIAlign计算出的union box的特征图,而
f
b
o
x
f_{box}
fbox是一个将subject和object的bbox转换成一个完整的特征(与
u
t
i
,
j
u_t^{i,j}
uti,j形状一致),语义嵌入向量
s
t
i
∈
R
200
s_t^i∈R^{200}
sti∈R200由subject和object的对象类别决定。关系表征在时空transformer中交换了spatial和temporal信息。
3.3 Spatio-Temporal Transformer

ST-transformer依然保持着encoder-decoder架构,不同的是,此处的encoder和decoder会处理更具体的任务。
3.3.1 Spatial Encoder
Spatial Encoder集中在每一帧的空间上下文,其输入是单个的
X
t
=
{
x
t
1
,
x
t
2
,
.
.
.
,
x
t
K
(
t
)
}
X_t=\{x_t^1,x_t^2,...,x_t^{K(t)}\}
Xt={xt1,xt2,...,xtK(t)},queries
Q
Q
Q、keys
K
K
K和values
V
V
V在第n个encoder层中共享着相同的输入和输出,表示为:
X
T
(
n
)
=
A
t
t
e
n
c
.
(
Q
=
K
=
V
=
X
t
(
n
−
1
)
)
X_T^{(n)}=Att_{enc.}(Q=K=V=X_t^{(n-1)})
XT(n)=Attenc.(Q=K=V=Xt(n−1))
这个encoder由N个自注意力层
A
t
t
e
n
c
.
Att_{enc.}
Attenc.依次堆叠组成,第n-1层的输出作为第n层的输入。为了简便,我们下面不讨论superscript n。不像大多数transformer方法,由于帧之间的关系直观上是平行的,因此我们没有将额外的positional encoding集成到inputs里面去。隐藏关系表中的空间信息在self-attention机制中起着关键作用。encoder statcks最后的输出会作为Temporal decoder的输入。
3.3.2 Frame Encoding
在temporal decoder介绍之前,先介绍一下frame encoding。没有卷积和递推,序列顺序的知识(例如位置编码)必须嵌入transformer的input。与word position和pixel position不同,我们定制了frame encodings,在关系表征中注入了时间位置。帧编码 R f R_f Rf是由学到的embedding参数所构建的,因为嵌入向量的数量(取决于Temporal Decoder的窗口大小)是稳定且相对较小的: E f = [ e 1 , . . . , e η ∈ R ] E_f=[e_1,...,e_\eta∈R^] Ef=[e1,...,eη∈R],其中 e 1 , . . . , e η ∈ R 1936 e_1,...,e_\eta∈R^{1936} e1,...,eη∈R1936是学到的相同长度为 x t k x_t^k xtk的向量。
广泛使用的正弦编码在table 5中尽心了对比,我们使用的拥有更好性能的learned encoding,窗口大小 η \eta η是固定的,因此视频长度不会影响到frame encoding的长度。
3.3.3 Temporal Decoder
通过temporal decoder捕获帧之间的时间依赖,计算量和内存消耗都急剧提高,但有用信息很容易被大量无关表示压倒。在本文中,我们采用一个滑动窗口用于批处理视频帧,以至于消息在相邻帧之间传递,从而避免了与远处帧发生干扰。
我们temporal decoder的自注意力层与spatial encoder
A
t
t
e
n
c
.
(
)
Att_{enc.}()
Attenc.()相同,即masked multi-head self-attention layers被移除。滑动窗口
η
\eta
η在空间上下文表示
[
X
1
,
.
.
,
X
T
]
[X_1,..,X_T]
[X1,..,XT]的序列上执行,第i个生成的输入批次表示为:
Z
i
=
[
X
i
,
.
.
.
,
X
i
+
η
−
1
]
,
i
∈
{
1
,
.
.
.
,
T
−
η
+
1
}
Z_i=[X_i,...,X_{i+\eta-1}],i∈\{1,...,T-\eta+1\}
Zi=[Xi,...,Xi+η−1],i∈{1,...,T−η+1}
其中窗口大小
η
≤
T
\eta≤T
η≤T,
T
T
T是视频长度。
这个decoder是由N个堆叠的相同self-attention layer
A
t
t
d
e
c
(
)
Att_{dec}()
Attdec()组成的。第一层如下“
Q
=
K
=
Z
i
+
E
f
,
V
=
Z
i
,
Z
i
^
=
A
t
t
d
e
c
.
(
Q
,
K
,
V
)
Q=K=Z_i+E_f, \\ V=Z_i, \\ \hat{Z_i}=Att_{dec.}(Q,K,V)
Q=K=Zi+Ef,V=Zi,Zi^=Attdec.(Q,K,V)
如上第一行公式,同样的encoder也被添加到关系表征中,与Queries和Keys放在同一个框架中。最后一个decoder层的输出将作为最终的预测结果。由于滑动窗口,每个帧的关系会在不同的batch中有多种多样的表征。本文中我们选择最早在窗口中出现的表征。
3.4 Loss Function
我们采用multiple linear transformer的来推断精炼表征与不同类型的关系(如注意力、空间、接触)。事实上,两个对象之间的同种关系在语义上不是唯一的,例如同义动作person-holding-broom和person-touching-broom。因此,我们使用multi-label margin loss function去进行谓词分类:
L
p
(
r
,
P
+
,
P
−
)
=
∑
p
∈
P
+
∑
q
∈
P
−
m
a
x
(
0
,
1
−
ϕ
(
r
,
p
)
+
ϕ
(
r
,
q
)
)
L_p(r,P^+,P^-)=\sum_{p∈P^+}\sum_{q∈P^-}max(0,1-\phi(r,p)+\phi(r,q))
Lp(r,P+,P−)=p∈P+∑q∈P−∑max(0,1−ϕ(r,p)+ϕ(r,q))
其中,一个人-物对
r
r
r,
P
+
P^+
P+是已标记的谓词,而
P
−
P^-
P−是一组不在标注内的谓词。
ϕ
(
r
,
p
)
\phi(r,p)
ϕ(r,p)表示计算出的第p个谓词的置信度。
在训练过程中,物体类别分布是由两个全连接层(ReLU激活函数+批量归一化)计算得到的, L o L_o Lo使用的是标准交叉熵损失,完整的损失函数为: L t o t a l = L p + L o L_{total}=L_p+L_o Ltotal=Lp+Lo
3.5 Graph Generation Strategies
以前的工作中,生成场景图有两种经典策略:
- With Constraint
- 只允许每个subject-object对最多只有一个谓词
- 更加严格,表明了模型预测最重要关系的能力,但它与multi-label任务是不兼容的。
- No Constraint
- 允许每个subject-object有多个谓词。
- 反映多标签预测能力,能容忍多个财产导致生成的场景图中出现错误信息。
为了能够使生成的场景图更接近Ground Truth,我们提出了一个新的策略叫做Semi Constraint,允许一个subject-object对有多重谓词,如person-holding-food、person-eating-food
如果关系的置信度高于阈值,则相应谓词被视为正谓词。在测试时,每个关系三元组的得分计算如下:
s
r
e
l
=
s
s
u
b
⋅
s
p
⋅
s
o
b
j
s_{rel}=s_{sub}·s_p·s_{obj}
srel=ssub⋅sp⋅sobj
其中三者分别是subject、predicate和object的置信度。
4 Experiments
4.1 Dataset and Evaluation Metrics
Dataset:Action Genome(AG)基于Charades数据集,35个object类别(不包括person)共有476229个bbox,25个关系类别共有1715568个实例,标注在234253帧中。
25种关系可以分为三种类型:
- attention关系
- spatial关系
- contact关系
AG种有135484个subject-object对被标记为多重spatial关系(如door-in front of-person、door-on the side of-person),多重contact关系(如person-eating-food、person-holding-food)
Evaluation Metrics:我们遵循图片场景图生成的三个标准任务进行评估
-
predicate classification (PREDCLS)
给定ground truth的labels和bbox,预测subject-object对的谓词label。
-
scene graph classification (SG-CLS)
对ground truth bbox进行分类,预测关系label。
-
scene graph detection (SGDET)
检测目标并预测关系label。(若预测的box与ground truth bbox的IoU大于0.5,则目标检测结果正确)
三个任务均由Recall@K(K=[10,20,50]) 指标,分别按照With Constraint、Semi Constraint和No Constraint进行评估。默认设置Semi Constraint的关系置信度阈值为0.9
4.2 Technical Details
目标检测的backbone采用的是基于ResNet101的FasterRCNN,我们在Action Genome训练集上训练一个检测器,得到24.6的mAP(0.5 IoU的COCO指标)。该检测器用于所有baselines进行公平对比,训练场景图生成模型时的参数(包括RPN)均固定,每个类别的NMS的IoU阈值为0.4,能够减少region proposals。
我们利用AdamW优化器,初始学习率为 1 e − 5 1e^{-5} 1e−5,批量大小为1,训练我们的模型。梯度剪切的maximal norm为5,窗口大小$ \eta 为 2 ,步长为 1 。 s p a t i a l e n c o d e r 包含一层,而 t e m p o r a l d e o c o d e r 包含了 3 个迭代层。 e n c o d e r 和 d e c o d e r 种的自注意力模块有 8 个 h e a d s , 为2,步长为1。spatial encoder包含一层,而temporal deocoder包含了3个迭代层。encoder和decoder种的自注意力模块有8个heads, 为2,步长为1。spatialencoder包含一层,而temporaldeocoder包含了3个迭代层。encoder和decoder种的自注意力模块有8个heads,d_{model}=1936, dropout=0.1$,前馈网络将 1936-d 输入投射到 2048-d,然后在 ReLU 激活后再次投射到 1936-d。
4.3 Quantitative Results and Comparison


表1,2对比了我们的模型在三种约束下均实现了SOTA,所有的方法均使用相同的object detector,提供了相同的feature maps和region proposals。
4.4 Temporal Dependency Analysis
以前基于图片的场景图生成相比,动态场景图有额外的temporal dependencies,接下来讨论一下它是如何提高关系推理的,并验证我们的利用了它的方法。
为了探索temporal dependencies的效果,我们迁移广泛使用的循环网络LSTM,如下图3所示。在将特征向量转入最终分类器之前,代表视频中各种关系的整个向量被组织成一个序列,并由 LSTM 进行处理。

我们随机选取1/3的视频打乱或者翻转,与不打乱或者翻转的情况对比,如下所示,打乱或者翻转会导致最后的结果较差。

4.5 Ablation Study
在STTran种,包含了Spatial Encoder和Temporal Decoder两个模块,以及通过Frame Encoding整合了temporal position到关系表征中(在Temporal Decoder模块中),为了验证哪个部分对模型性能影响最大,进行了相应的消融实验,如下表所示:

如下图所示,没有temporal dependencies时,spatial encoder会误检为person-touching-food,而不是正确的person-eating-food。

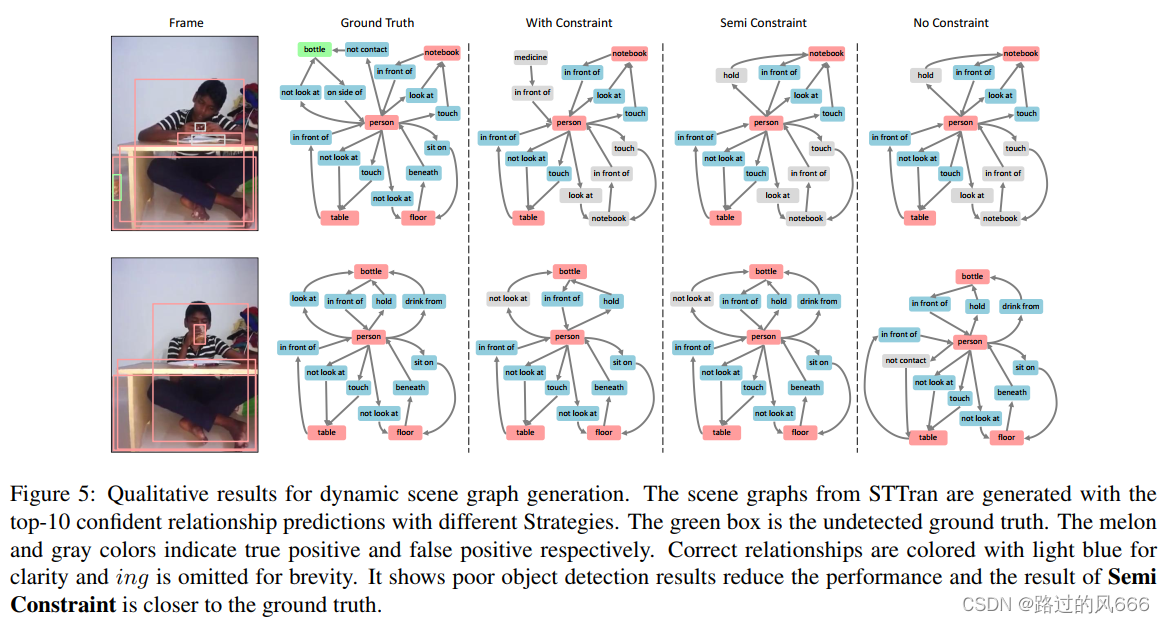
4.6 Qualitative Results
如下五列图片分别是RGB frame、Ground Truth生成的场景图、top-10可信的关系预测结果在三种策略下生成的场景图(With / Semi / No Constraint)。灰色表示False Positive、瓜色表示Truth Positive、绿色box表示未被detector检测出。
With Constraint只允许每对subject-object有一个类型的关系,而No Constraint中的person-not contacting-bottle取代了attention relationship。
注:下面两帧不是相邻的,因为人的IoU小于0.5。
5 Conclusion
- 提出了STTran,针对动态场景图生成,其中的encoder提取每帧的spatial context,decoder捕获帧与帧之间的temporal dependencies。
- 与以往单标签loss不同的是,我们利用一个multi-label margin loss并采用一个新的场景图生成策略。
- 几个实验都演示了temporal context对关系预测是有积极影响的,在AG数据集上的动态场景图生成任务上获得了SOTA。