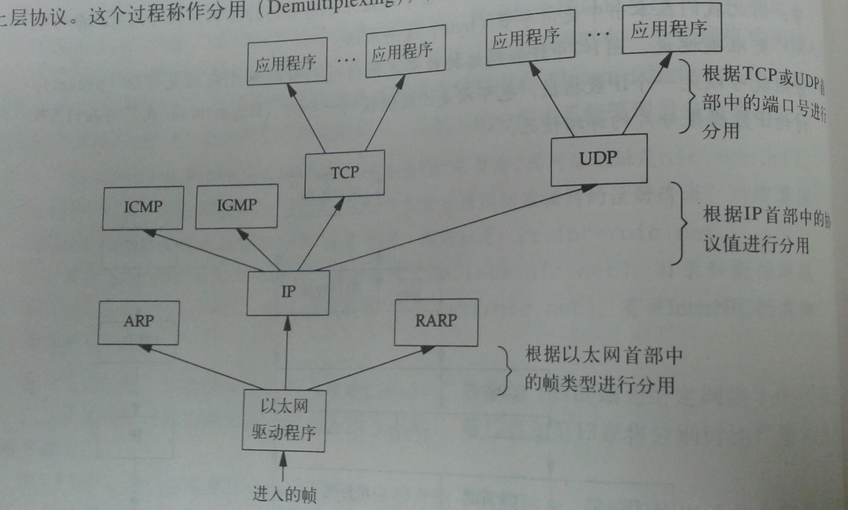
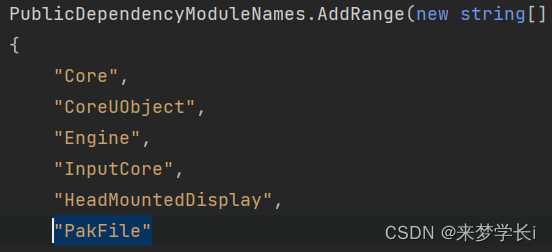
html代码
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<a href="./img/1.jpg">图片</a>
<!--这个下载效果是download实现的,文件名不建议中文,会影响第三个超链接的名字正常显示-(具体我也不知道,本人刚开始用的中文,但是第三个链接名字一直有问题,后改成0.jpg,第三个超链接正常才显示文件)-->
<a href="./img/1.jpg" download="0.jpg">图片</a>
<!--这个下载效果是java后台实现的,参数为虚拟目录加访问路径名在加个参数filename等于文件名,切记参数filename与后台参数保持一致-->
<!--filename后面文件名可以为任意文件,前提是路径要和后台代码/img/路径保持一致,即在img文件夹内任意格式文件均可下载,这里只演示图片下载-->
<a href="/xiaoji/wjxz01?filename=1.jpg">图片</a>
<a href="/xiaoji/wjxz01?filename=1.mp4">视频</a>
</body>
</html>
点击第一个超链接会直接跳转图片路径并显示图片(其他格式可能会直接下载(浏览器解析不出来就会直接下载))
点击第二个超链接会有以下效果(询问对文件操作,是否下载和另存路径)
点击第三个超链接效果效果和第二个一样,只是使用后台代码实现的
切记:第三个链接在谷歌浏览器还是直接下载的,建议用ME或者IE浏览器可以看到效果
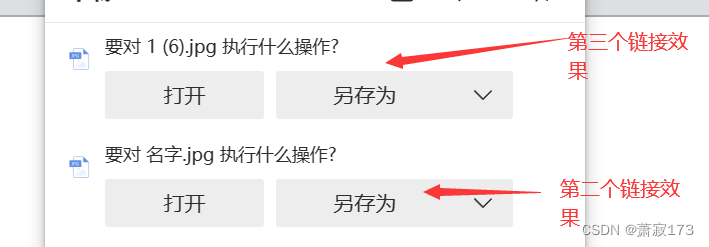
简单来说就是使用后台代码做一个download的下载并询问操作的效果
前端代码在上面,下面为后台代码(往下看,工具类之后有完整代码)
中文文件名乱码问题解决
例如:
<a href="/xiaoji/wjxz01?filename=你好.jpg">图片</a>
就会出现以下效果:下载时文件名乱码

解决思路:
1. 获取客户端使用的浏览器版本信息
2. 根据不同的版本信息,设置filename的编码方式不同
提供以下工具类(使用不同浏览器就使用不同的编码格式)
package cn.itcast.utils;
import sun.misc.BASE64Encoder;
import java.io.UnsupportedEncodingException;
import java.net.URLEncoder;
public class DownLoadUtils {
public static String getFileName(String agent, String filename) throws UnsupportedEncodingException {
if (agent.contains("MSIE")) {
// IE浏览器
filename = URLEncoder.encode(filename, "utf-8");
filename = filename.replace("+", " ");
} else if (agent.contains("Firefox")) {
// 火狐浏览器
BASE64Encoder base64Encoder = new BASE64Encoder();
filename = "=?utf-8?B?" + base64Encoder.encode(filename.getBytes("utf-8")) + "?=";
} else {
// 其它浏览器
filename = URLEncoder.encode(filename, "utf-8");
}
return filename;
}
}
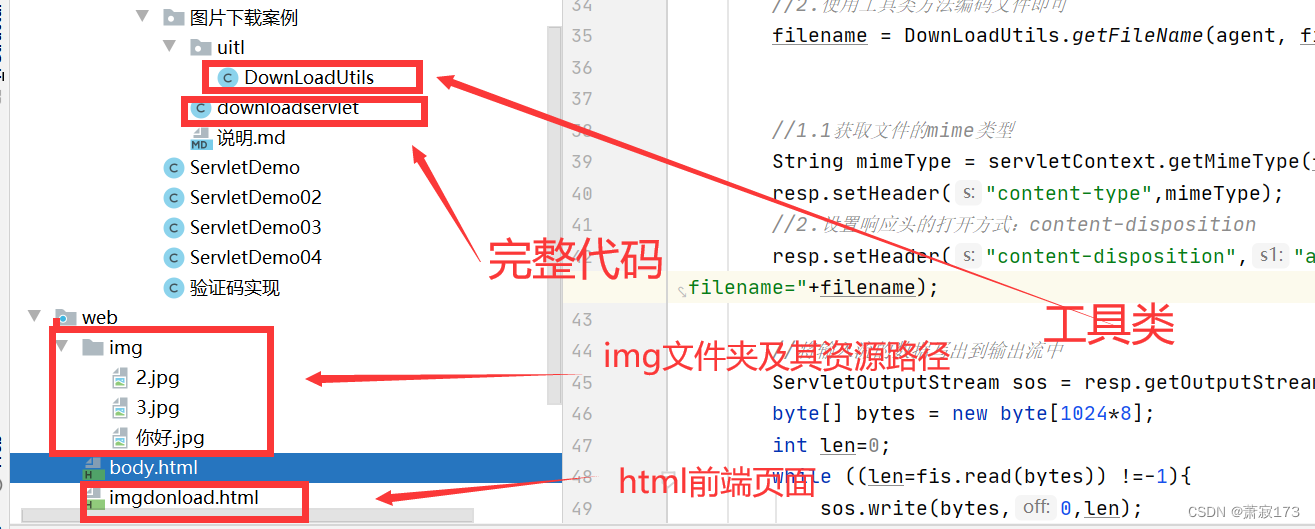
完整代码实现(java代码,引入上面工具类和前端网页还有准备好的img文件夹)
package com.jwz.servlet.图片下载案例;
import com.jwz.servlet.图片下载案例.uitl.DownLoadUtils;
import javax.servlet.ServletContext;
import javax.servlet.ServletException;
import javax.servlet.ServletOutputStream;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
@WebServlet("/wjxz01")
public class downloadservlet extends HttpServlet {
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
//获取请求参数,文件名称
String filename = req.getParameter("filename");
//使用字节输入流加载文件进内存
//1.找到文件服务器路径
ServletContext servletContext = this.getServletContext();
String realPath = servletContext.getRealPath("/img/" + filename);
//2.用字节流关联
FileInputStream fis = new FileInputStream(realPath);
//设置response的响应头
//1.设置响应头类型content-type
//解决中文文件名问题
//1.获取user-agent请求头
String agent = req.getHeader("user-agent");
//2.使用工具类方法编码文件即可
filename = DownLoadUtils.getFileName(agent, filename);
//1.1获取文件的mime类型
String mimeType = servletContext.getMimeType(filename);
resp.setHeader("content-type",mimeType);
//2.设置响应头的打开方式:content-disposition
resp.setHeader("content-disposition","attachment;filename="+filename);
//将输入流的数据写出到输出流中
ServletOutputStream sos = resp.getOutputStream();
byte[] bytes = new byte[1024*8];
int len=0;
while ((len=fis.read(bytes)) !=-1){
sos.write(bytes,0,len);
}
fis.close();
}
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
this.doPost(req,resp);
}
}
乱码问题解决

最后附上本人项目结构(只需要关心img文件夹和html路径即可,在web下)