DataWhale 机器学习夏令营第三期
- 学习记录二 (2023.08.23)——可视化分析
- 1.赛题理解
- 2. 数据可视化分析
- 2.1 用户维度特征分布分析
- 2.2 时间特征分布分析
DataWhale 机器学习夏令营第三期
——用户新增预测挑战赛
学习记录二 (2023.08.23)——可视化分析
2023.08.17
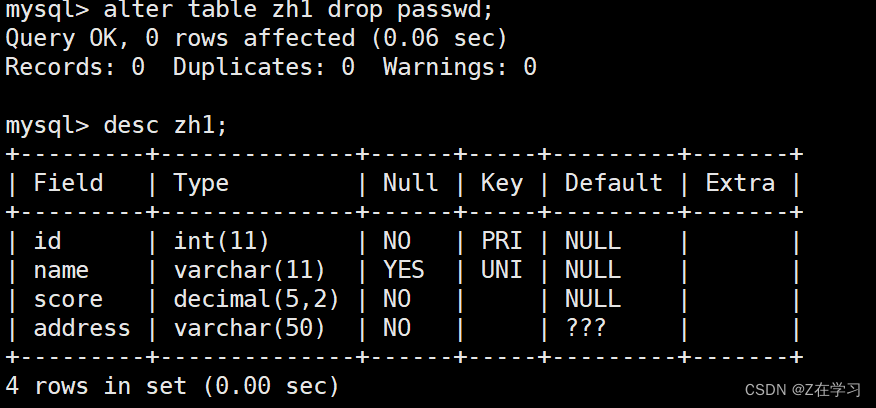
已跑通baseline,换为lightgbm基线,不加任何特征线上得分0.52214;
添加baseline特征,线上得分0.78176;
暴力衍生特征并微调模型参数,线上得分0.86068
2023.08.23
数据分析、衍生特征:0.87488
衍生特征、模型调参:0.89817
交流分享视频:
【DataWhale“用户新增预测挑战赛”交流分享-哔哩哔哩】 https://b23.tv/zZMLtFG
1.赛题理解

这次比赛特征主要可以分为以下三个维度:
- 行为维度:
eid、udmapudmap的key处理成了类别特征
- 时间维度:
common_ts- 进行了时间戳特征的提取:
day,hour,minute
- 进行了时间戳特征的提取:
- 用户维度:
x1~x8
2. 数据可视化分析
使用以下代码绘制前还需做一些设置,具体可以参考如下链接:
https://www.kaggle.com/code/jcaliz/ps-s03e02-a-complete-eda/notebook
该notebook内提供了丰富的可视化分析代码和思路,值得参考。
绘制代码:
def plot_cate_large(col):
data_to_plot = (
all_df.groupby('set')[col]
.value_counts(True)*100
)
fig, ax = plt.subplots(figsize=(10, 6))
sns.barplot(
data=data_to_plot.rename('Percent').reset_index(),
hue='set', x=col, y='Percent', ax=ax,
orient='v',
hue_order=['train', 'test']
)
x_ticklabels = [x.get_text() for x in ax.get_xticklabels()]
# Secondary axis to show mean of target
ax2 = ax.twinx()
scatter_data = all_df.groupby(col)['target'].mean()
scatter_data.index = scatter_data.index.astype(str)
ax2.plot(
x_ticklabels,
scatter_data.loc[x_ticklabels],
linestyle='', marker='.', color=colors[4],
markersize=15
)
ax2.set_ylim([0, 1])
# Set x-axis tick labels every 5th value
x_ticks_indices = range(0, len(x_ticklabels), 5)
ax.set_xticks(x_ticks_indices)
ax.set_xticklabels(x_ticklabels[::5], rotation=45, ha='right')
# titles
ax.set_title(f'{col}')
ax.set_ylabel('Percent')
ax.set_xlabel(col)
# remove axes to show only one at the end
handles = []
labels = []
if ax.get_legend() is not None:
handles += ax.get_legend().legendHandles
labels += [x.get_text() for x in ax.get_legend().get_texts()]
else:
handles += ax.get_legend_handles_labels()[0]
labels += ax.get_legend_handles_labels()[1]
ax.legend().remove()
plt.legend(handles, labels, loc='upper center', bbox_to_anchor=(0.5, 1.08), fontsize=12)
plt.tight_layout()
plt.show()
2.1 用户维度特征分布分析
可视化分析说明:
- 研究离散变量
['eid', 'x3', 'x4', 'x5‘,'x1', 'x2', 'x6','x7', 'x8'']的分布,蓝色是训练集,黄色是验证集,分布基本一致 - 粉色的点是训练集下每个类别每种取值的target的均值,也就是
target=1的占比
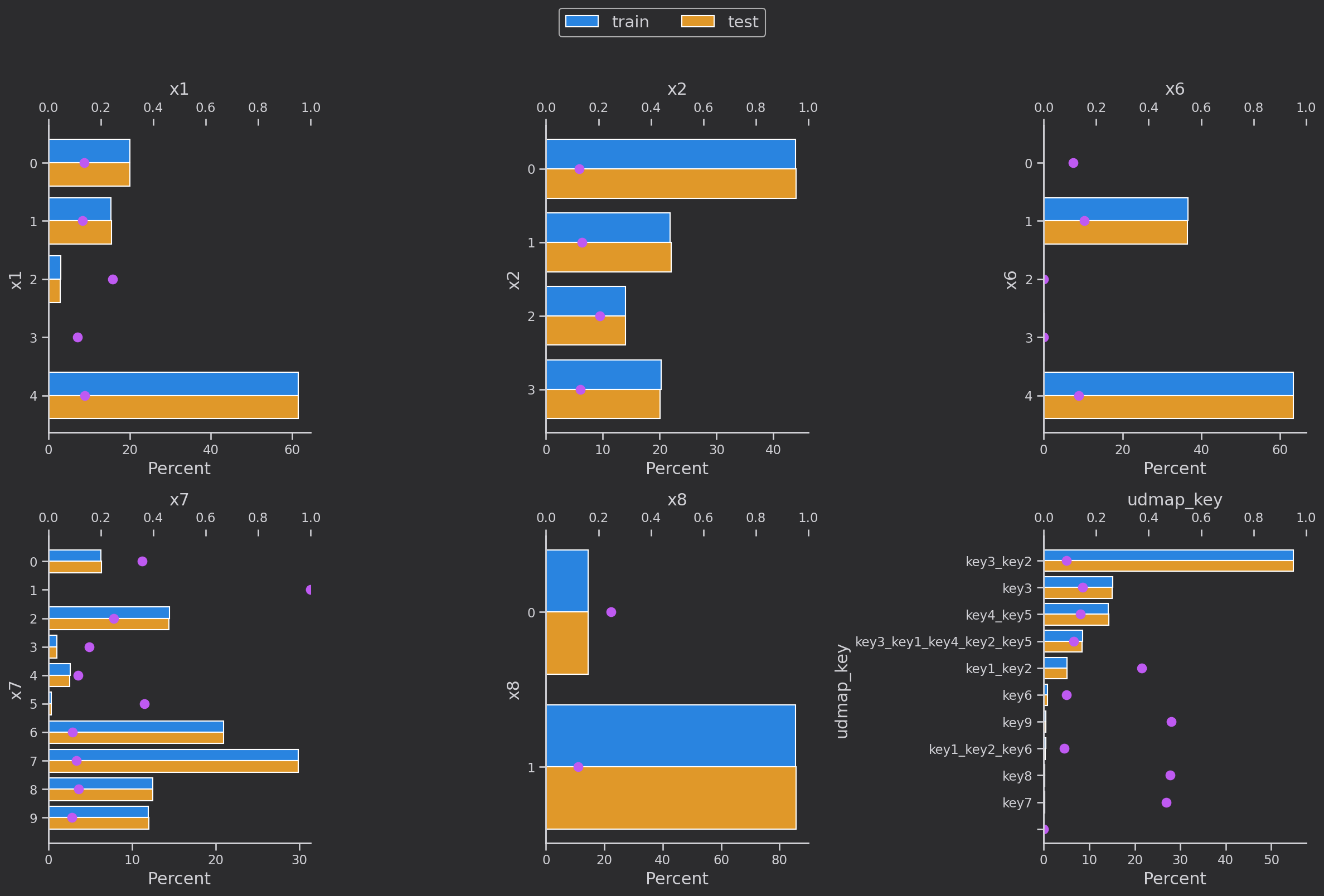
该图主要分析类别数较少的离散变量:
- 训练集和测试集分布比较均匀
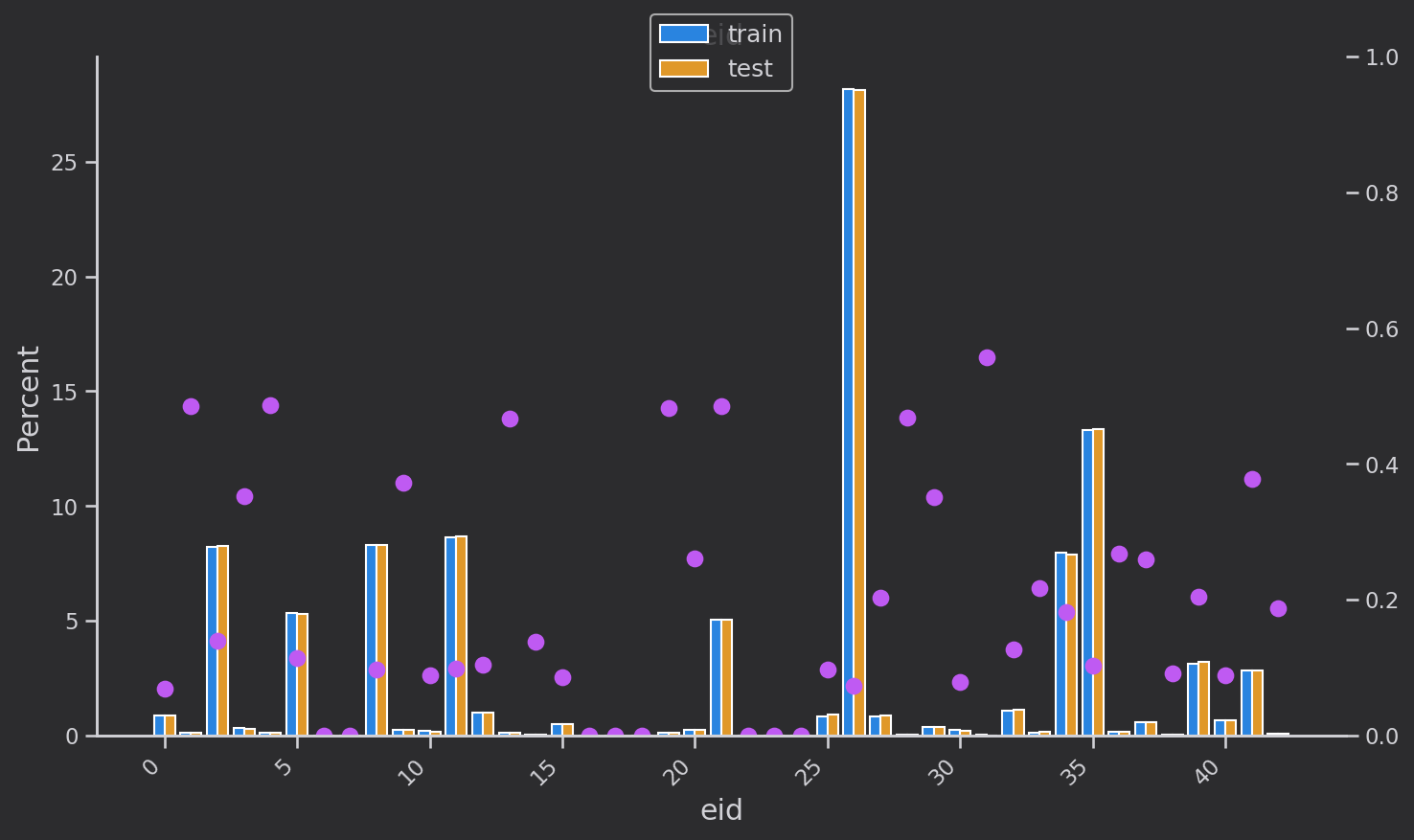
x1主要集中在x1=4,x2分布比较均匀,x6基本集中在1和4两个值,x7分布比较均匀,可能是一个关键特征x8可能是性别特征,特征重要性较低udmap_key为提取出的特征,存在缺失值
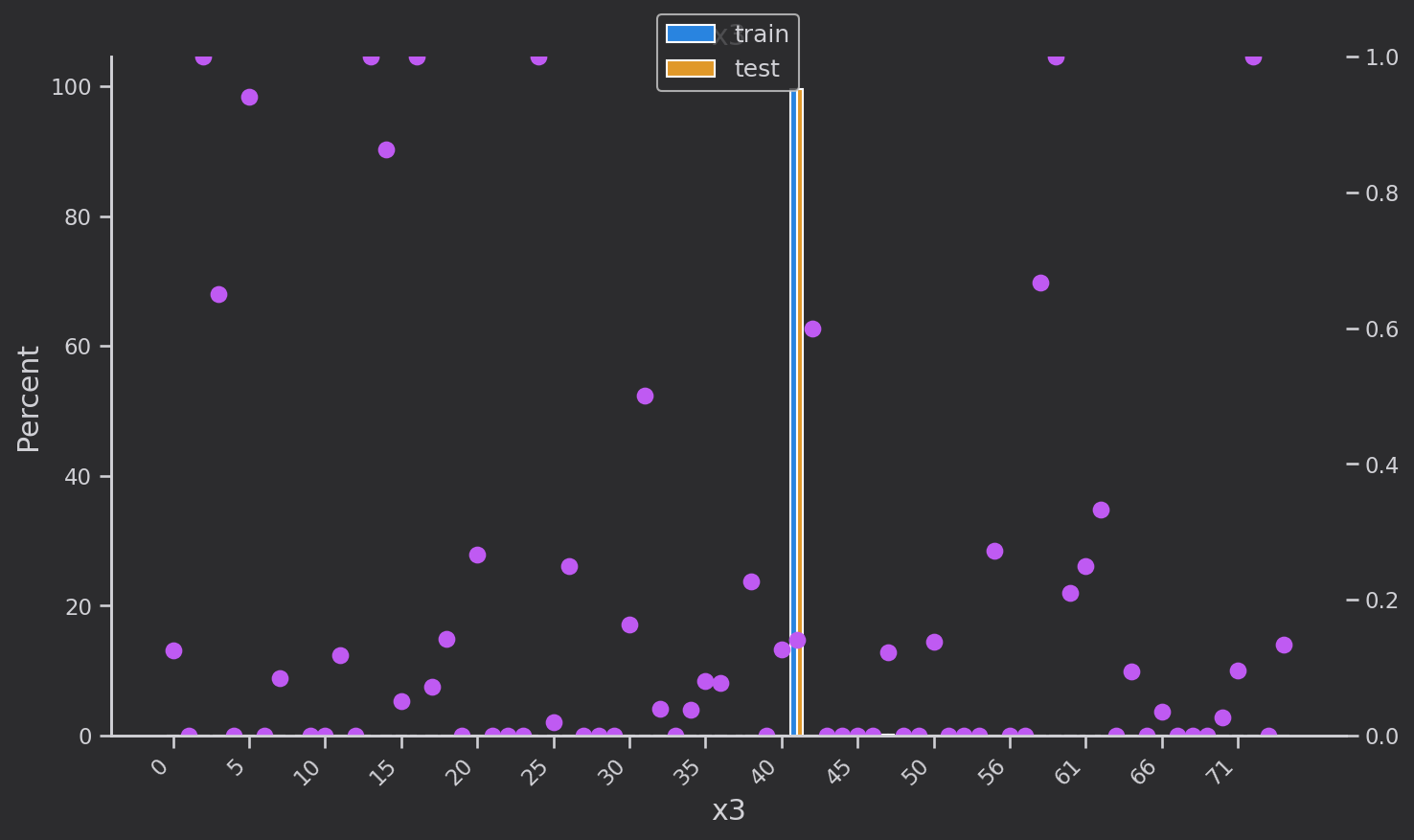
x3主要集中在41下,占比太大,特征重要性很低
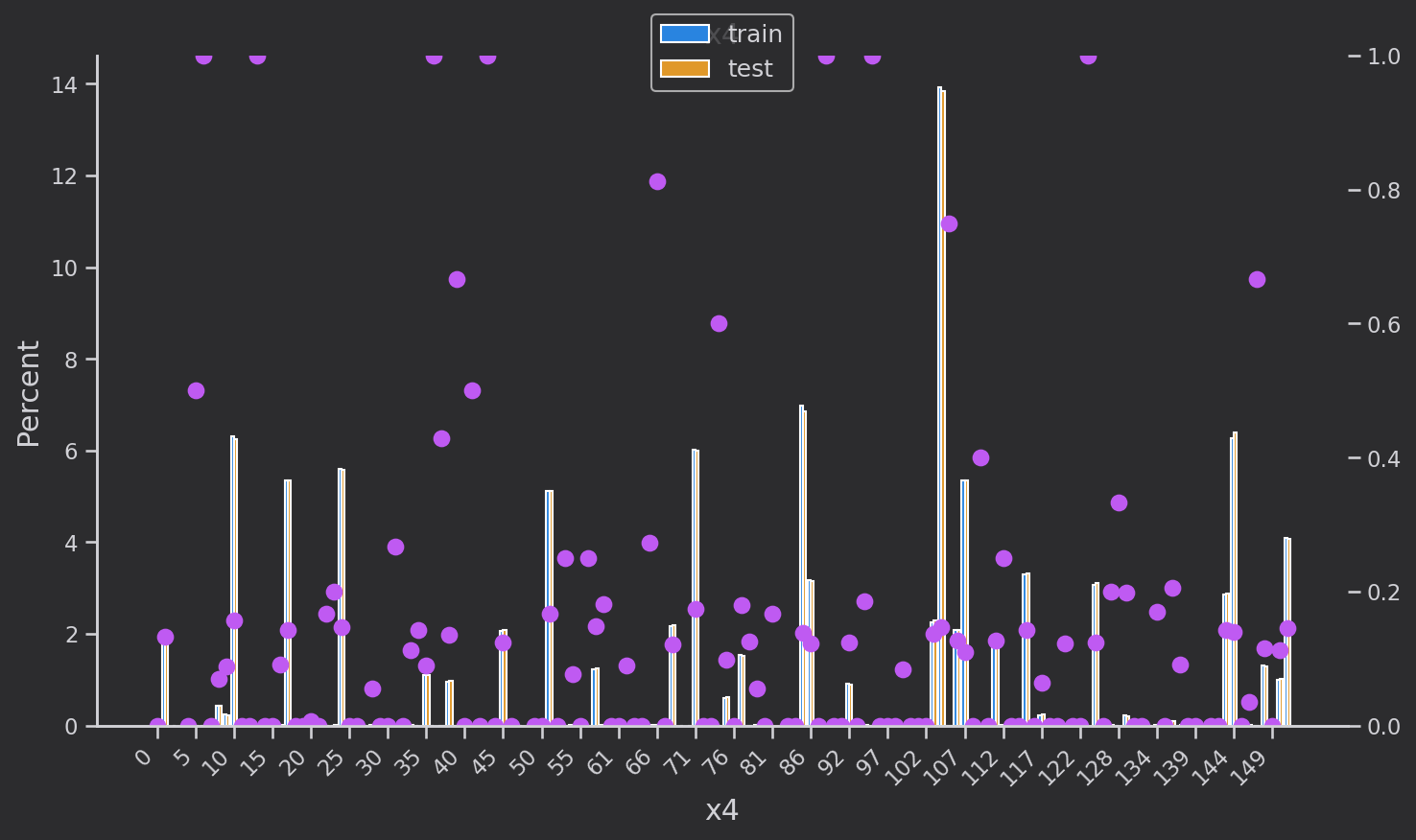
x4中各个类别下target的分布变化较大,可能是一个关键特征
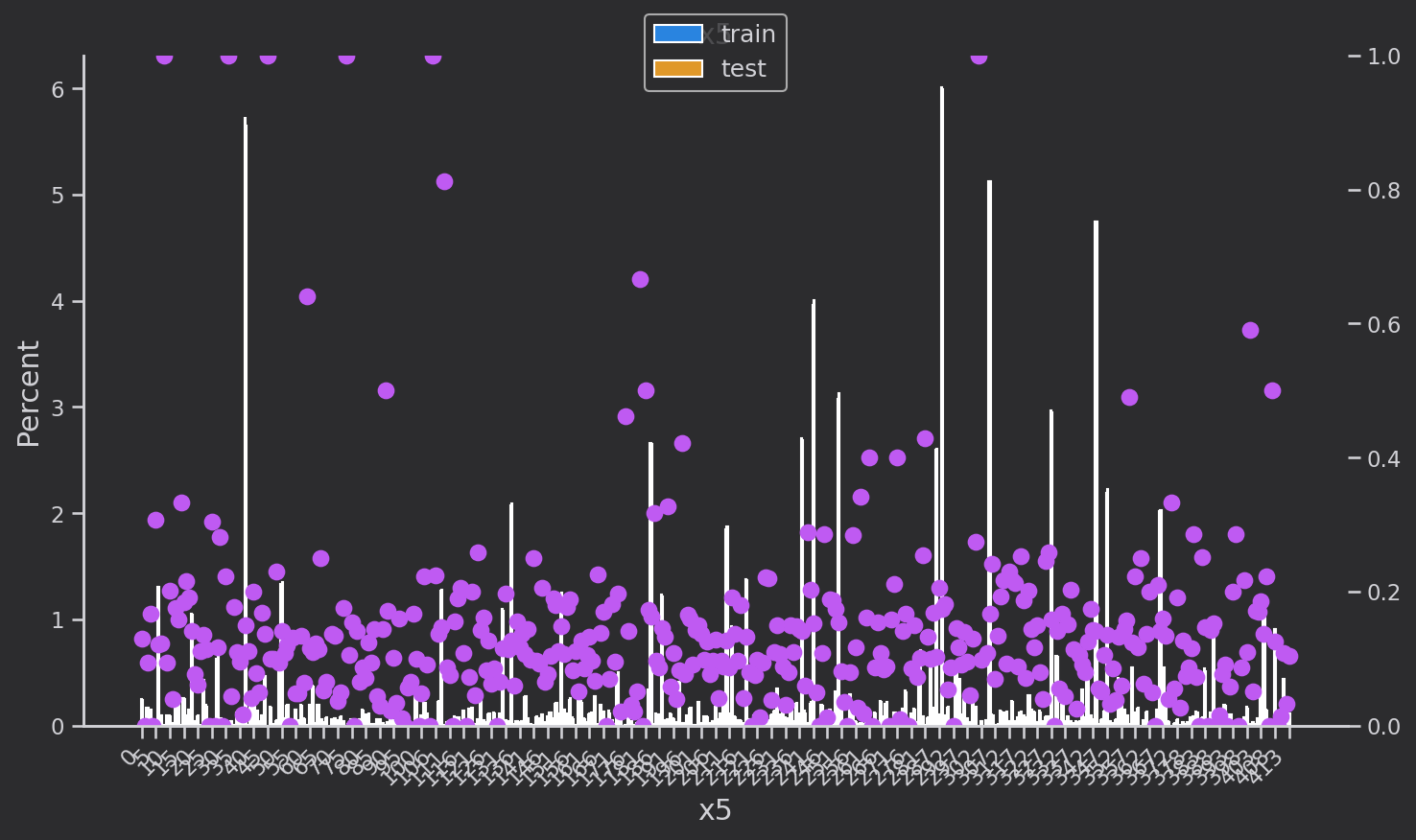
x5中各个类别同x4,target的分布变化较大,可能是一个关键特征,但特征数量太多在衍生特征时需要注意避免产生稀疏性
2.2 时间特征分布分析
主要绘制了common_ts中 day 和 hour 的变化情况
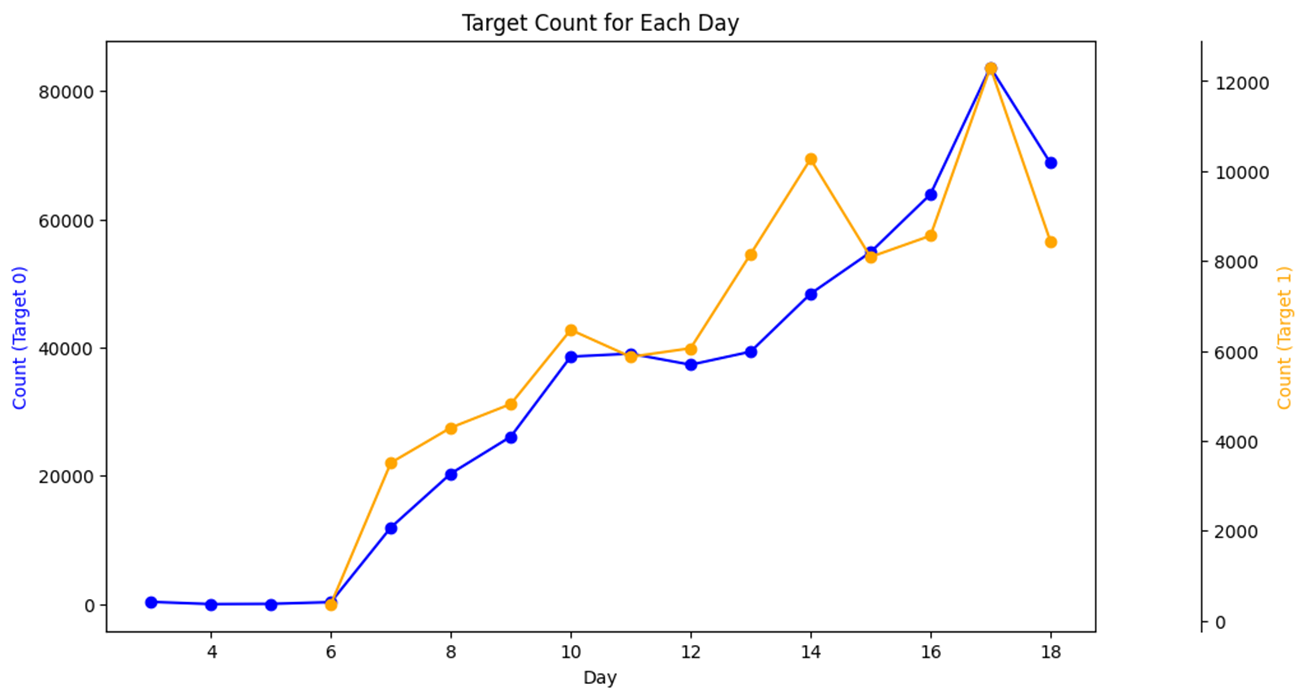
day的值和用户增长有很大的关系,可以发现在10、14和17新用户有明显的增长- 老用户对应也呈现出增长趋势
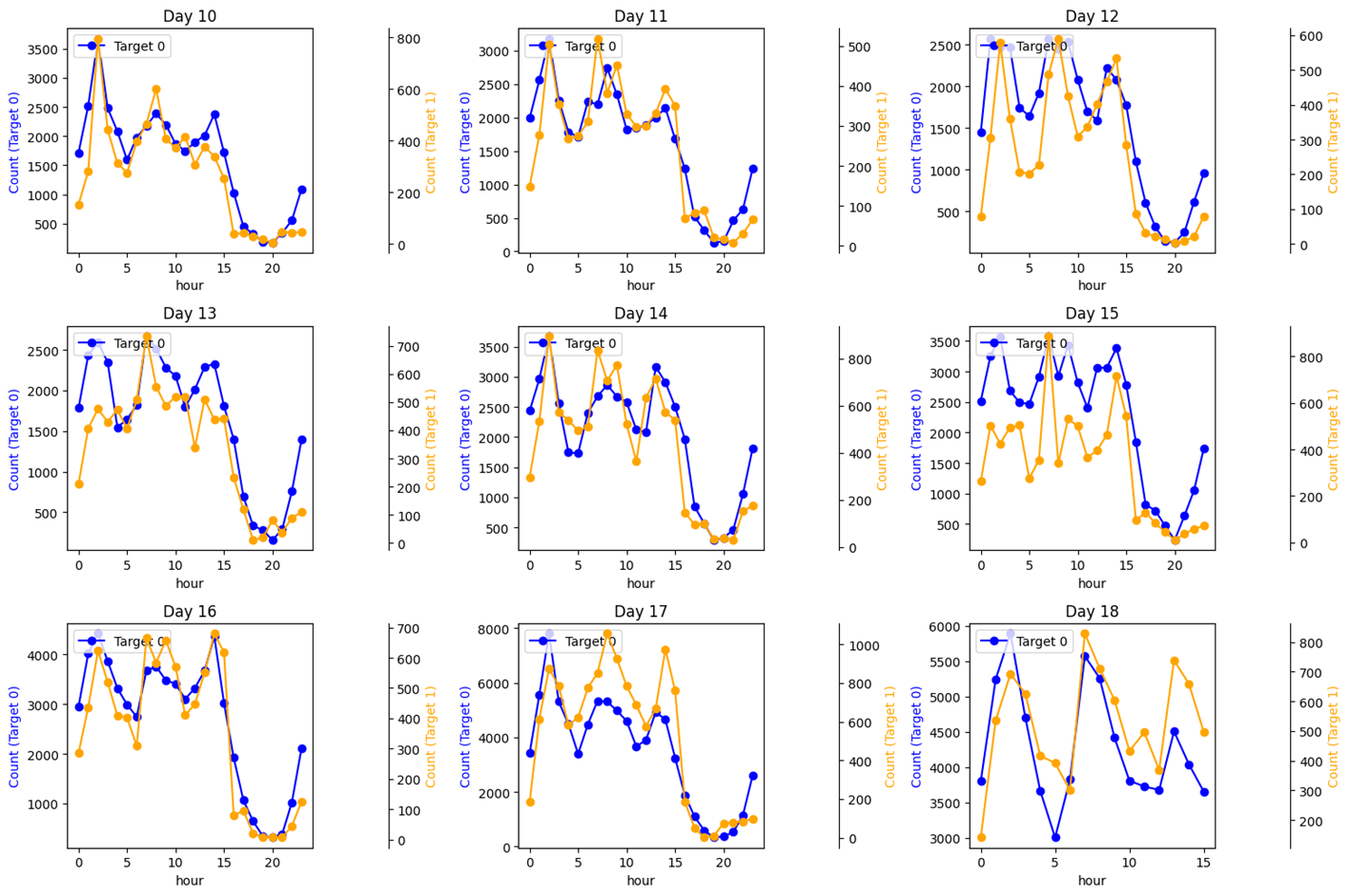
绘制了从day=10到day=18的新老用户变化情况 - 新老用户的数量在每天的各个时间段呈现基本相同的趋势
- 进一步观察原始数据可以发现,三个峰的出现是因为在该三个时间段数据量较其他时间段多
- 可以进一步绘制出各个时间段人数占全天人数的占比图来进一步分析数据