您是否曾经遇到这样的情况?每天早上或业务活动高峰期,大量用户涌入报表平台或数据应用,希望查看特定业务领域的最新指标或趋势。这些用户可能会基于庞大的数据集进行大量类似的聚合查询,造成集群的 CPU 负载持续攀升,从而导致查询性能不断下滑。
针对这种高并发且呈现一定规律的查询,是否存在一种方法可以让集群在处理时智能地“精简计算量”呢?
1、StarRocks Query Cache(查询缓存)
为了解决这一问题, StarRocks 研发了 Query Cache(查询缓存)。它的作用是将本地聚合的中间结果缓存在内存中,以供后续复用。 当执行查询时,StarRocks 会优先检查 Query Cache。如果发现相同查询语义的结果已经存在于缓存中,就可以直接复用这些中间结果,避免重复计算,从而节省了磁盘访问和部分计算开销,有效提升查询性能。
值得注意的是,Query Cache 并不是 Result Cache,它缓存的是查询过程中的聚合中间结果而不是最终结果, 因此大大提升了缓存的命中率。即便对于不完全一致的查询,也能起到加速作用。据测试结果显示,在高并发场景下,Query Cache 可以将查询效率提高 3 至 17 倍, 从而有效减轻集群的负载压力,提供更快速的查询响应时间,使得整个系统在高峰期依然能够保持高性能运行。
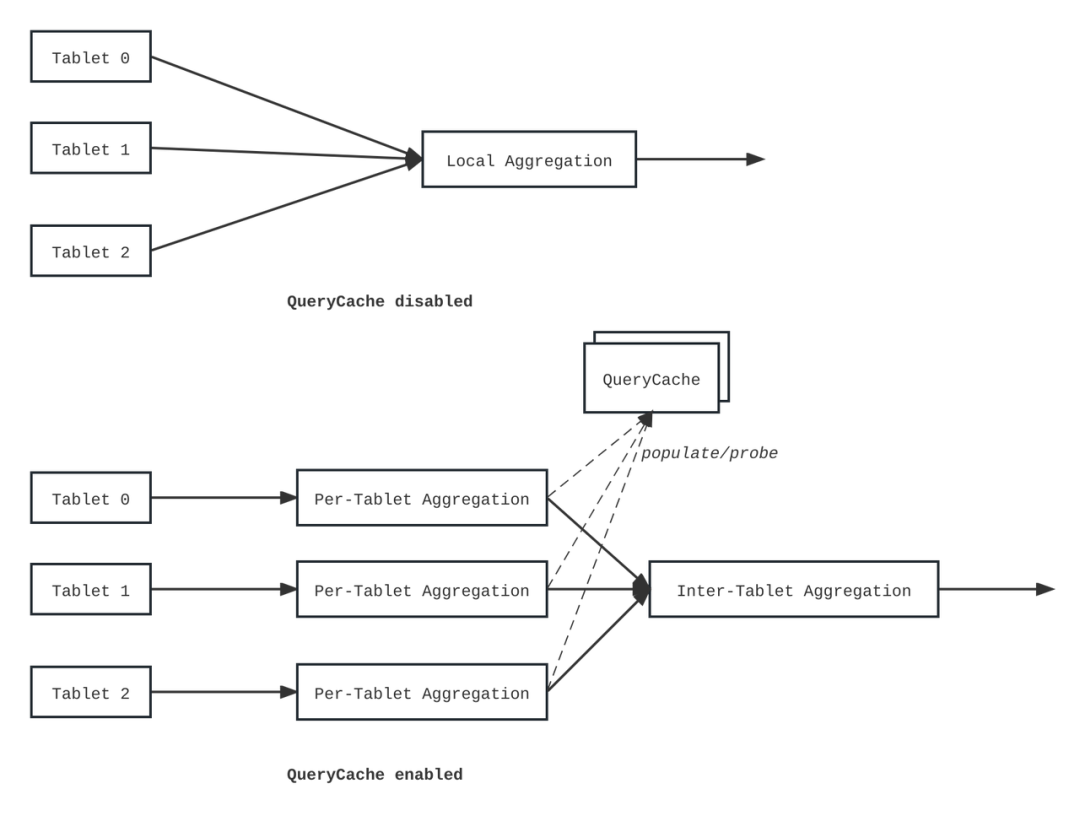
(Query Cache 机制)
2、面向更多场景设计,最大限度提升缓存复用率
StarRocks 的 Query Cache 在设计时就考虑了如何能够让缓存的信息最大程度得到复用。整体来讲,下列三个场景均可以利用到 Query Cache:
- 语义等价的查询
- 扫描分区重合的查询:基于谓词的查询拆分
- 仅涉及追加写入(无删除及更新)数据的查询:多版本缓存能力
(1)语义等价的查询

类似上图的例子,左图的子查询与右图在语义上是等价的,因此在执行了其中一个后,另一个查询就可以复用缓存中的结果加速查询。
语义等价还包含非常多的场景,更多例子请见:(https://docs.starrocks.io/zh-cn/latest/using_starrocks/query_cache)#语义等价的查询
(2)扫描分区重合的查询:基于谓词的查询拆分
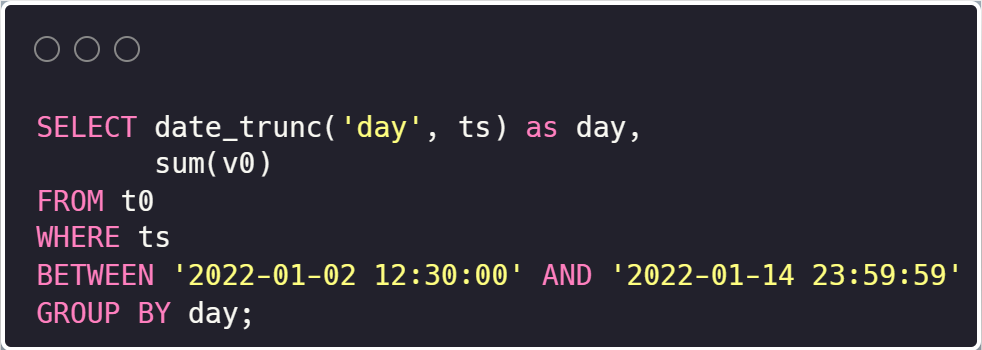

在上图的两个查询中,ts 是分区列,查询仅在分区列的筛选区间上有区别,并且其中一部分区间是重叠的。在执行任意查询时,StarRocks 会将谓词中的区间按照分区来切割,并按照分区级别缓存聚合中间结果。在下次执行时,就可以复用有重叠的分区结果,达到查询加速的效果。
更多例子请见:
https://docs.starrocks.io/zh-cn/latest/using_starrocks/query_cache#扫描分区重合的查询
(3)仅涉及追加写入数据的查询:多版本缓存能力
除了上述在不同查询中尽可能复用 Cache,还有一类场景需要考虑:如果数据变化了该如何应对?Query Cache 可以在只有追加写入(append)的场景下被复用。
总体来说,随着数据导入,Tablet 会产生新的版本,进而导致 Query Cache 中缓存结果的 Tablet 版本落后于实际的 Tablet 版本。这时候,多版本 Cache 机制会尝试把 Query Cache 中缓存的结果与磁盘上存储的增量数据合并,确保新查询能够获取到最新版本的 Tablet 数据。
更多例子请见:https://docs.starrocks.io/zh-cn/latest/using_starrocks/query_cache#仅涉及追加写入数据的查询
3、在这些场景上,Query Cache 能事半功倍
根据上面的讲解,可以看出相比基于结果的 Result Cache,基于聚合中间结果的 Query Cache 能够被更大程度地利用。因而 Query Cache 就更适用于以下的查询场景:
- 聚合类查询执行比较频繁,包含针对宽表的聚合查询与星型模型 JOIN 后的聚合查询
- 两个语言相似的查询,但允许不完全相同
- 数据只会追加写入,没有更新操作
这样的查询特征在很多场景中都很常见,例如:
- 监控或报表平台: 数据集会随着时间的推移逐渐增加,而且用户会对不同时间段的数据汇总结果感兴趣
- 面向用户的高并发分析: 包含按照特定维度指标进行汇总的查询
在这些场景中,Query Cache 可以通过重复使用查询的中间结果,避免重复计算,加快查询的响应速度。同时,由于缓存机制的使用,系统的可扩展性也得到了提升,从而可以更好地处理高并发的查询请求,为用户提供更好的体验。
4、最佳实践
为了更高效地利用 Query Cache,建表时需要根据查询设置合理的分区策略,并选择合适的数据分布方式, 包括:
- 选择一个单独的 date/datetime 类型的列为分区列。 这个列的数据最好随着导入单调增加,并且查询会基于该列进行区间筛选。
- 选择合适的分区大小。 因为随着导入,最近的分区数据很有可能会经常变动,从而导致缓存失效。因此过大或过小的分区都会影响缓存的命中率。
- 确保分桶数量在数十个左右。 如果分桶数量过小,那么当 BE 需要处理的 Tablet 数量小于 pipeline_dop 参数的取值时,Query Cache 无法生效。
并且,因为每个 BE 节点在内存中维护自己的本地缓存,只要 BE 节点上有查询所需的副本数据,查询就可以被分配给该 BE。所以,为了能够最大程度地应用到 Cache,查询应该至少执行与副本数(replication_num)相同的次数。不过,Query Cache 也并不是只有在完全加载后才起作用。
5、如何使用 Query Cache
在这一节我们将用通过一个简单的例子来展示 StarRocks Query Cache 是如何工作的。
(1)准备工作
Query Cache 默认情况下是禁用的。您可以通过会话变量来启用它。 在例子中我们在单个 BE 集群中创建一副本的表,为了使 Query Cache 能够发挥作用,也需要对 pipeline_dop 进行调整。为了确认 Query Cache 的使用情况,还需要打开 Profile。
--打开 Query Cache
set enable_query_cache=true;
--因为只有1副本,因此调整 pipeline dop 为1
set pipeline_dop=1;
--打开 Query Profile
set is_report_success = true;
set enable_profile = true;
建表和导入语句请见:https://docs.starrocks.io/zh-cn/3.1/using_starrocks/query_cache#数据集
(2)示例查询
接下来我们将用一个简单的例子来激活 Query Cache 并查看它的使用情况。
首先我们执行第一个基础查询:
-- Q1: 基础查询
SELECT
date_trunc('hour', ts) AS hour,
k0,
sum(v1) AS __c_0
FROM
t0
WHERE
ts between '2022-01-03 00:00:00'
and '2022-01-03 23:59:59'
GROUP BY
date_trunc('hour', ts),
k0;
执行后我们查看 BE 的缓存情况。其usage相关指标被填充,说明 Query Cache 已经被填充:
curl http://127.0.0.1:8040/api/query_cache/stat
{
"capacity": 536870912,
"usage": 3889,
"usage_ratio": 0.000007243826985359192,
"lookup_count": 42,
"hit_count": 0,
"hit_ratio": 0.0
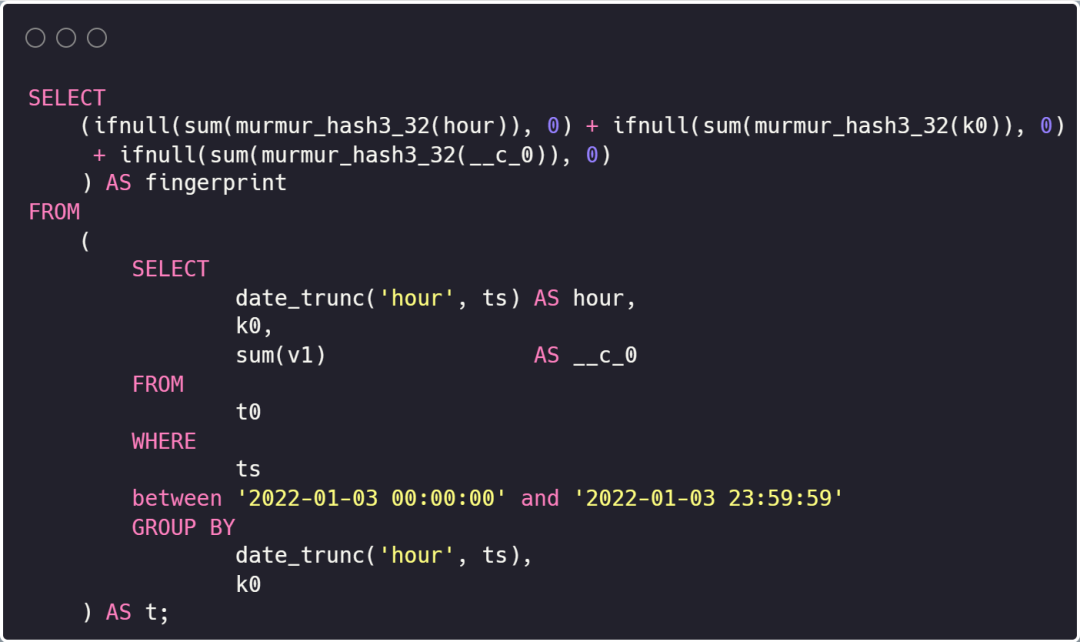
接下来执行语义等价的查询:
-- Q2: 语义等价的查询
SELECT
(
ifnull(sum(murmur_hash3_32(hour)), 0) + ifnull(sum(murmur_hash3_32(k0)), 0) + ifnull(sum(murmur_hash3_32(__c_0)), 0)
) AS fingerprint
FROM
(
SELECT
date_trunc('hour', ts) AS hour,
k0,
sum(v1) AS __c_0
FROM
t0
WHERE
ts between '2022-01-03 00:00:00'
and '2022-01-03 23:59:59'
GROUP BY
date_trunc('hour', ts),
k0
) AS t;
执行后我们继续查看 BE 的缓存情况。这里可以看到,Query Cache 被命中:
curl http://127.0.0.1:8040/api/query_cache/stat
{
"capacity": 536870912,
"usage": 3889,
"usage_ratio": 0.000007243826985359192,
"lookup_count": 44,
"hit_count": 2,
"hit_ratio": 0.045454545454545459
进一步分析此次查询的 Profile。可以发现 Profile 中出现 Cache 节点,Populate 相关指标均为 0,说明没有新的聚合结果被缓存;并且 Scan 节点的 RawRowsRead 指标为 0,说明实际并没有读取数据:
-- Cache节点populate相关指标均为0
- CachePopulateBytes: 0.00
- CachePopulateChunkNum: 0
- CachePopulateRowNum: 0
- CachePopulateTabletNum: 0
-- Scan节点RawRowsRead为0
- RawRowsRead: 0M (0)
6、性能报告
尽管 StarRocks 的 Query Cache 不是 Result Cache,但是重复利用中间计算结果仍然可以带来很大的性能提升。这不仅适用于聚合查询,还能加速 JOIN 操作。现在让我们来看一些性能数据。为简单起见,我们将结果表示为 RT 比率,即查询延迟的 no_cache/cache_hit 比率。
注意,下方所有测试中 Query Cache 均已经被充分加载。
(1)宽表测试
| 硬件 | 3 x (CPU: 16cores, 内存: 64GB) |
|---|---|
| 数据集 | SSB 100GB 宽表 |
| 并发量 | 10 |
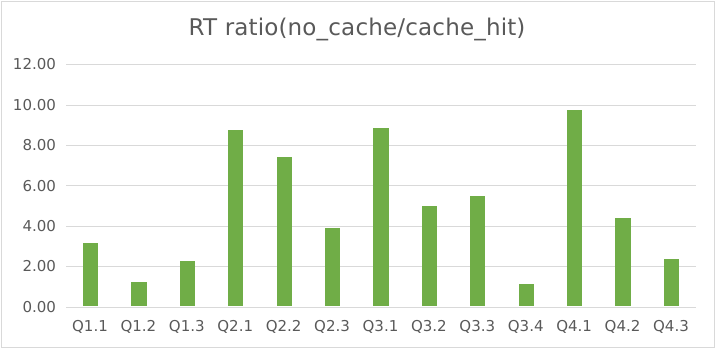
(Query Cache vs. 冷查询)
可以看到,在 10 并发的单表聚合查询中,Query Cache 命中可以带来高达 10 倍的性能提升。
(2)星型模型测试
| 硬件 | 3 x (CPU: 16cores, 内存: 64GB) |
|---|---|
| 数据集 | SSB 100GB 多表 |
| 并发量 | 10 |
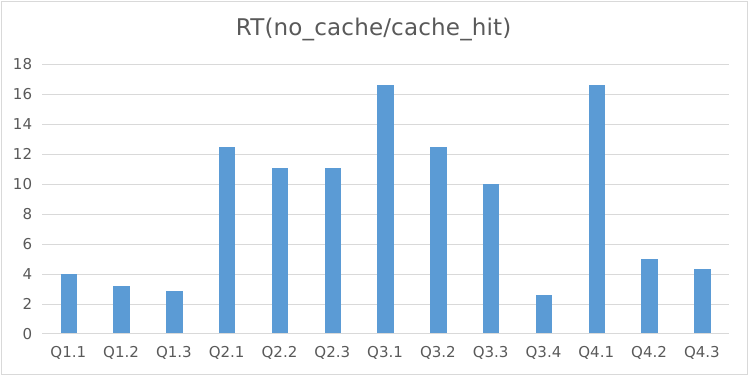
可以看到,在 10 并发的多表聚合查询中,Query Cache 命中可以带来高达 17 倍的性能提升。
7、总结
Query Cache 可以极大地提升聚合查询的性能。通过将本地聚合的中间结果存储在内存中,Query Cache 可以避免对类似于先前查询的新查询进行不必要的磁盘访问和计算。Query Cache 还可以处理不完全相同的查询和数据,这使得它比 Result Cache 更加灵活。在高并发场景中,许多用户在大型复杂数据集上运行类似的查询时,Query Cache 尤其有用。借助 Query Cache,StarRocks 可以为聚合查询提供快速而准确的结果,节省时间和资源,并实现更好的可扩展性。
💬 Query Cache 讨论专区
为了帮助用户更好的使用 query cache,社区在论坛上开了一个相关的讨论帖,欢迎来分享你们都是怎么使用 query cache,或是使用过程中遇到了什么问题。性能提升的招式,大家都学起来!👉🏻 https://forum.mirrorship.cn/t/topic/8468
参考资料 https://docs.starrocks.io/zh-cn/latest/using_starrocks/query_cache