文章目录
- 前言
- 需求
- 环境准备
- 单线程处理
- 多线程处理
- 总结
前言
开发中,我们经常会遇到处理批量数据,最后把处理成功和失败的数据结果记录下来。普通方法一个循环就可以搞定这个需求,但是面临大量数据单个线程去处理可能面临很大的瓶颈,同时也无法最大发挥CPU的性能。这时候你可能会说:多线程我也没用过 天天工作CRUD,我只会个 hello world。接下来我们模拟一个需求,看看并发编程中有那些需要注意的点,相信看完这篇文章你一定有所收获👊👊
需求
模拟2001条数据,对每条数据进行处理,并记录最后处理成功和失败的结果
环境准备
@Data
public class Person {
// id
private int id;
// 性别
private String gender;
// 名称
private String name;
}
/**
* 模拟导入数据库
* @param person 处理的对象
* @return 是否成功
*/
private boolean importData(Person person) {
// 模拟处理耗时,20-29ms随机数
int expend = (int) (Math.random() * 10) + 20;
try {
TimeUnit.MILLISECONDS.sleep(expend);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 性别为女的处理成功
if ("女".equals(person.getGender())) {
return true;
}
return false;
}
/**
* 获取初始化数据
*/
private List<Person> initData() {
List<Person> list = new ArrayList<>();
for (int i = 1; i <= 2001; i++) {
Person obj = new Person();
obj.setId(i);
obj.setGender(i % 2 == 0 ? "男" : "女");
obj.setName("老王-" + i);
list.add(obj);
}
return list;
}
单线程处理
@Test
public void main() {
List<Person> personList = initData();
long startTime = System.currentTimeMillis();
List<Person> successList = new ArrayList<>();
List<Person> errorList = new ArrayList<>();
for (Person person : personList) {
boolean state = importData(person);
if(state){
successList.add(person);
continue;
}
errorList.add(person);
}
long endTime = System.currentTimeMillis();
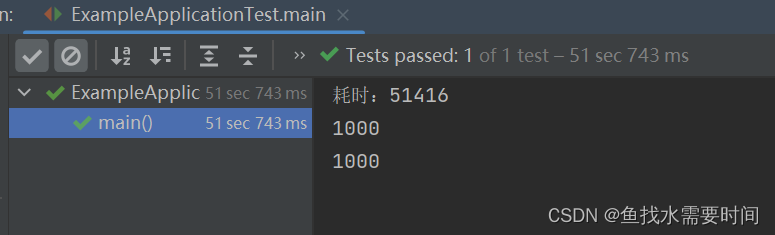
System.out.println("耗时:" + (endTime - startTime));
System.out.println(successList.size());
System.out.println(errorList.size());
}
非常的easy,性能也十分堪忧,总耗时大概等于单条数据处理时间×数据量,相信屏幕前的你不至于看不懂吧
多线程处理
其中代码都加了很多注释,防止自己忘记也方便大家理解查看
/**
* @description 定义线程池
*/
@Component
public class TaskExecutorConfig {
@Bean
public TaskExecutor taskExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
// 设置核心线程数
executor.setCorePoolSize(50);
// 设置最大线程数
executor.setMaxPoolSize(200);
// 设置队列容量
executor.setQueueCapacity(200);
// 设置线程活跃时间(秒)
executor.setKeepAliveSeconds(800);
// 设置默认线程名称
executor.setThreadNamePrefix("yzs-");
// 设置拒绝策略
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
// 等待所有任务结束后再关闭线程池
executor.setWaitForTasksToCompleteOnShutdown(true);
return executor;
}
}
CyclicBarrier 字面意思是循环栅栏,是一个同步的工具,能够允许一组线程去互相等待直到都到达了屏障,CyclicBarrier对于涉及到固定大小的线程是非常有用的,线程们必须相互等待。该屏障称之为循环屏障,是因为当等待屏障的线程被释放之后,该屏障能循环使用。
这里为什么采用CyclicBarrier来实现,因为多线程中它可以复用
@Resource
private TaskExecutor taskExecutor;
// 批次执行线程大小
int threadNum = 10;
@Test
public void main() throws InterruptedException {
List<Person> personList = initData();
if (CollectionUtils.isEmpty(personList)) {
return;
}
long startTime = System.currentTimeMillis();
AtomicInteger atomicInteger = new AtomicInteger(1);
// 定义栅栏
CyclicBarrier cyclicBarrier = new CyclicBarrier(threadNum, () -> {
System.out.println("第几次:" + atomicInteger.getAndIncrement());
});
// 处理成功的数据
List<Person> successList = new ArrayList<>();
// 处理错误的数据
List<Person> errorList = new ArrayList<>();
// 循环次数
int forNumber = personList.size() % threadNum == 0 ? personList.size() / threadNum : (personList.size() / threadNum) + 1;
// 计数器等于线程数,计时到每个线程都执行完成任务
CountDownLatch countDownLatch = new CountDownLatch(threadNum);
// 处理集合的索引,从0开始
AtomicInteger listIndex = new AtomicInteger();
for (int i = 0; i < threadNum; i++) {
taskExecutor.execute(() -> {
for (int j = 0; j < forNumber; j++) {
try {
if (listIndex.get() < personList.size()) {
// 这里不要先 getAndIncrement 再 get,多线程下会导致 get的值可能不是当前线程 ++ 后的,就会导致同一个索引的数据处理了多次
Person person = personList.get(listIndex.getAndIncrement());
boolean state = importData(person);
if (state) {
successList.add(person);
} else {
errorList.add(person);
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
// 确保每个线程都在屏障前等待
cyclicBarrier.await();
} catch (Exception e) {
e.printStackTrace();
}
}
}
// 每个线程执行完成后,计数器 -1
countDownLatch.countDown();
});
}
countDownLatch.await();
long endTime = System.currentTimeMillis();
System.out.println("总耗时" + (endTime - startTime));
System.out.println(successList.size());
System.out.println(errorList.size());
}
运行结果:
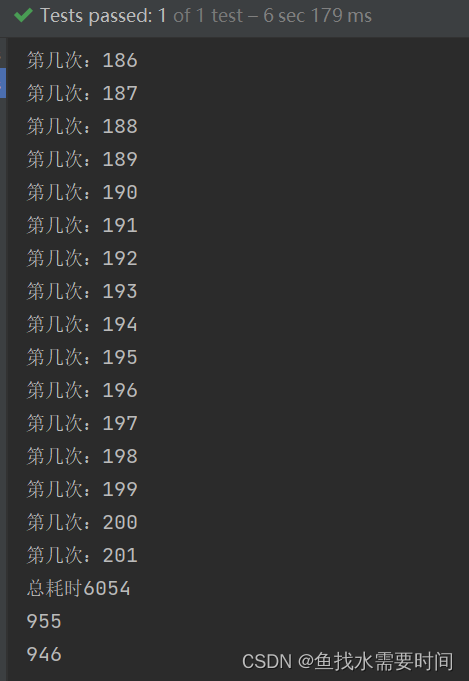
总体性能是提高了,但是 最后记录的数据量不够2001条呢???
这是因为List是非线程安全的,多个线程操作会产生数据安全问题
修改之后:
@Resource
private TaskExecutor taskExecutor;
// 批次执行线程大小
int threadNum = 10;
@Test
public void main() throws InterruptedException {
List<Person> personList = initData();
if (CollectionUtils.isEmpty(personList)) {
return;
}
long startTime = System.currentTimeMillis();
AtomicInteger atomicInteger = new AtomicInteger(1);
// 定义栅栏
CyclicBarrier cyclicBarrier = new CyclicBarrier(threadNum, () -> {
System.out.println("第几次:" + atomicInteger.getAndIncrement());
});
// 处理成功的数据
Vector<Person> successList = new Vector<>();
// 处理错误的数据
Vector<Person> errorList = new Vector<>();
// 循环次数
int forNumber = personList.size() % threadNum == 0 ? personList.size() / threadNum : (personList.size() / threadNum) + 1;
// 计数器等于线程数,计时到每个线程都执行完成任务
CountDownLatch countDownLatch = new CountDownLatch(threadNum);
// 处理集合的索引,从0开始
AtomicInteger listIndex = new AtomicInteger();
for (int i = 0; i < threadNum; i++) {
taskExecutor.execute(() -> {
for (int j = 0; j < forNumber; j++) {
try {
if (listIndex.get() < personList.size()) {
// 这里不要先 getAndIncrement 再 get,多线程下会导致 get的值可能不是当前线程 ++ 后的,就会导致同一个索引的数据处理了多次
Person person = personList.get(listIndex.getAndIncrement());
boolean state = importData(person);
if (state) {
successList.add(person);
} else {
errorList.add(person);
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
// 确保每个线程都在屏障前等待
cyclicBarrier.await();
} catch (Exception e) {
e.printStackTrace();
}
}
}
System.out.println(Thread.currentThread().getName());
// 每个线程执行完成后,计数器 -1
countDownLatch.countDown();
});
}
countDownLatch.await();
long endTime = System.currentTimeMillis();
System.out.println("总耗时" + (endTime - startTime));
System.out.println(successList.size());
System.out.println(errorList.size());
}
运行结果:
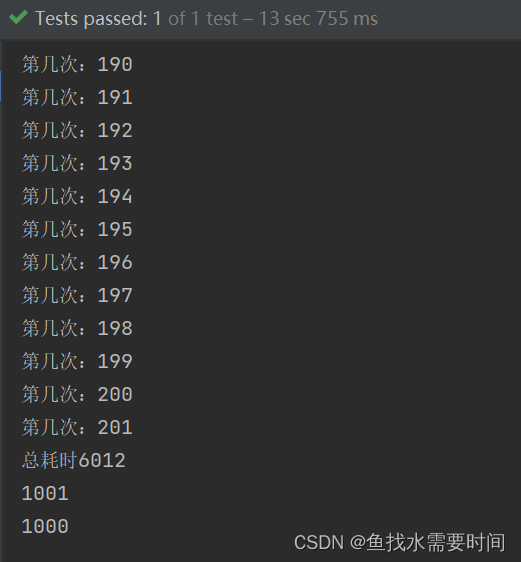
看看数据是否正确,按照数据处理的规则,id为奇数的性别为女,处理全部成功
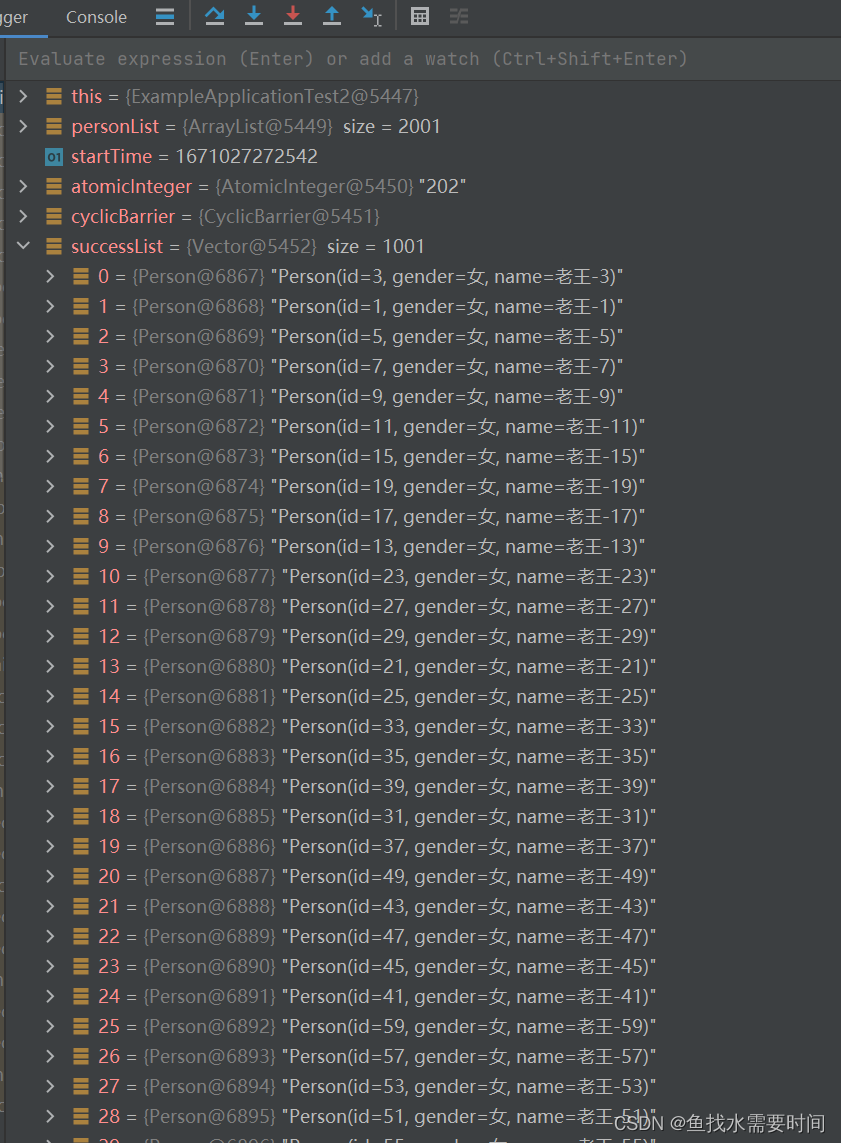
id为偶数的性别为男,处理全部失败
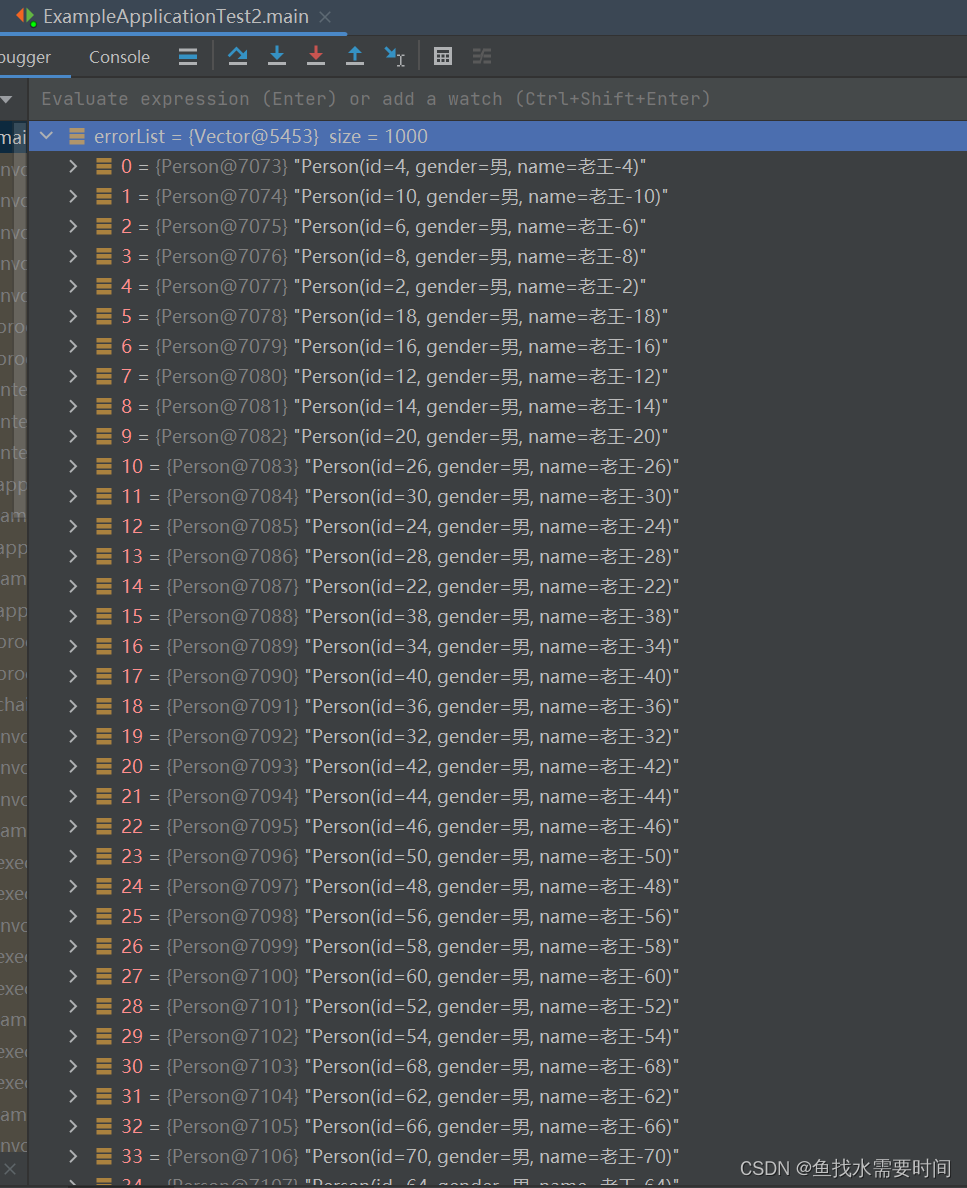
最后结果也正确。
总结
从单线程处理到多线程处理,把总体耗时从 51s优化到了6s,虽然开了十个线程同时去处理,但最终结果不是 51s除以10,这是因为线程的切换和CPU的调度也需要消耗一定的时间,线程数量不是越多越好。线程数需要根据实际情况、具体服务器CPU的核数 具体分析和反复测试,最终选取一个比较合适的数量。