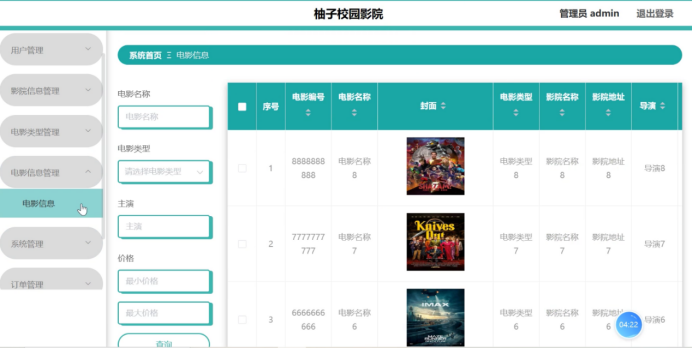
Central cache
threadcache是每个线程独享,而centralcache是多线程共享,需要加锁(桶锁)一个桶一个锁
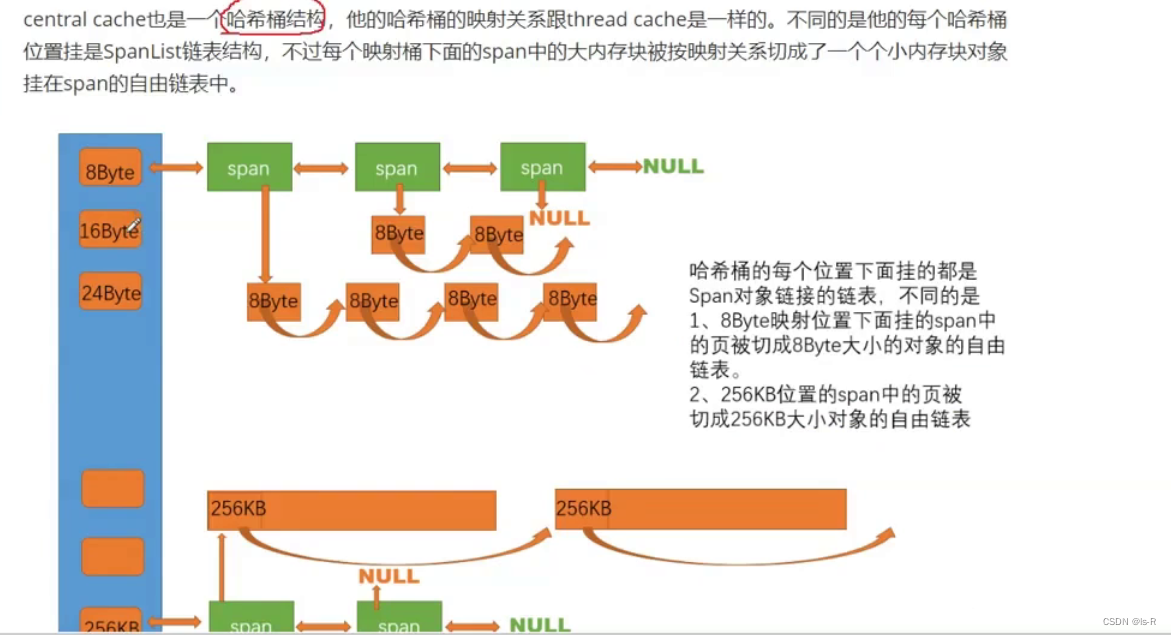

解决外碎片问题:内碎片:申请大小超过实际大小;外碎片:空间碎片不连续,导致无法申请大块空间
span
在存储管理中,"span"是一个术语,用于描述连续的内存块或磁盘块的范围。
在内存管理中,一个span通常是一系列连续的内存页或内存块,它们被分配给一个进程或数据结构。一个span的大小可以根据需求而变化,通常是以页的大小为单位进行分配。
在磁盘管理中,一个span通常是一系列连续的磁盘块,它们被分配给一个文件或数据结构。一个span的大小可以根据需求而变化,通常是以磁盘块的大小为单位进行分配。
使用span的好处是可以提高内存或磁盘的利用率,避免了碎片化的问题。通过分配连续的span,可以更有效地利用存储资源,并提高数据的读写性能。

span设计成双向链表 带头双向循环,插入删除更加高效
32位机器和64位机器的页数不同!!!!!!!!!
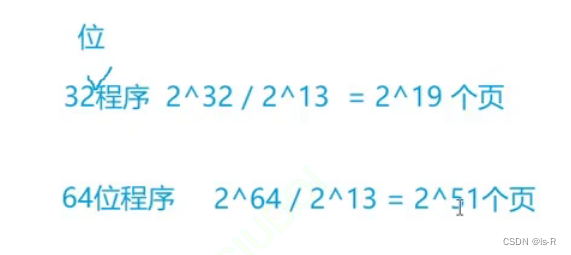
使用条件编译在预处理阶段解决
#ifdef _WIN32
typedef size_t PAGE_ID;
#elif _WIN64
typedef unsigned long long PAGE_ID;
#endif
但是在64位下还是会有问题

所有要调换顺序
#ifdef _WIN64
typedef unsigned long long PAGE_ID;
#elif _WIN32
typedef size_t PAGE_ID;
#endif
// 管理多个连续页大块内存跨度结构
struct Span
{
PAGE_ID _pageId = 0; // 大块内存起始页的页号
size_t _n = 0; // 页的数量
Span* _next = nullptr; // 双向链表结构
Span* _prev = nullptr;
size_t _useCount = 0; // 切好小块内存,被分配给thread cache的计数
void* _freeList = nullptr; // 切好的小块内存的自由链表
};
// 带头双向循环链表
class SpanList
{
public:
SpanList()
{
_head = new Span;
_head->_next = _head;
_head->_prev = _head;
}
Span* Begin()
{
return _head->_next;
}
Span* End()
{
return _head;
}
bool Empty()
{
return _head->_next == _head;
}
void PushFront(Span* span)
{
Insert(Begin(), span);
}
Span* PopFront()
{
Span* front = _head->_next;
Erase(front);
return front;
}
void Insert(Span* pos, Span* newSpan)
{
assert(pos);
assert(newSpan);
Span* prev = pos->_prev;
// prev newspan pos
prev->_next = newSpan;
newSpan->_prev = prev;
newSpan->_next = pos;
pos->_prev = newSpan;
}
void Erase(Span* pos)
{
assert(pos);
assert(pos != _head); //不能删除哨兵位
Span* prev = pos->_prev;
Span* next = pos->_next;
prev->_next = next;
next->_prev = prev;
//不去删除,因为空间是要还给下一层
}
private:
Span* _head;
public:
std::mutex _mtx; // 桶锁
};
CentralCache类
只能有一个,所以采用单例模式
// 单例模式
class CentralCache
{
public:
static CentralCache* GetInstance()
{
return &_sInst;
}
// 获取一个非空的span
Span* GetOneSpan(SpanList& list, size_t byte_size);
// 从中心缓存获取一定数量的对象给thread cache
size_t FetchRangeObj(void*& start, void*& end, size_t batchNum, size_t size);
private:
SpanList _spanLists[NFREELIST];
private:
CentralCache()
{}
CentralCache(const CentralCache&) = delete;
static CentralCache _sInst;
};
threadcache从centralcache中获取span
首先明确一次获取的数量
// 一次thread cache从中心缓存获取多少个
static size_t NumMoveSize(size_t size)
{
assert(size > 0);
// [2, 512],一次批量移动多少个对象的(慢启动)上限值
// 小对象一次批量上限高
// 小对象一次批量上限低
int num = MAX_BYTES / size;
if (num < 2)
num = 2;
if (num > 512)
num = 512;
return num;
}
实现获取,逐步递增。获取一个时直接返回就行,不是一个时先将其串联起来再返回头
void* ThreadCache::FetchFromCentralCache(size_t index, size_t size)
{
// 慢开始反馈调节算法
// 1、最开始不会一次向central cache一次批量要太多,因为要太多了可能用不完
// 2、如果你不要这个size大小内存需求,那么batchNum就会不断增长,直到上限
// 3、size越大,一次向central cache要的batchNum就越小
// 4、size越小,一次向central cache要的batchNum就越大
size_t batchNum = min(_freeLists[index].MaxSize(), SizeClass::NumMoveSize(size));
if (_freeLists[index].MaxSize() == batchNum)
{
_freeLists[index].MaxSize() += 1;
}
void* start = nullptr;
void* end = nullptr;
size_t actualNum = CentralCache::GetInstance()->FetchRangeObj(start, end, batchNum, size);
assert(actualNum > 0);
if (actualNum == 1)
{
assert(start == end);
return start;
}
else
{
_freeLists[index].PushRange(NextObj(start), end);
return start;
}
}
完善自由链表
//管理切分好的小对象的自由链表
class FreeList
{
public:
void Push(void* obj)
{
assert(obj);
// 头插
//*(void**)obj = _freeList;
NextObj(obj) = _freeList;
_freeList = obj;
}
void PushRange(void* start, void* end)
{
NextObj(end) = _freeList;
_freeList = start;
}
void* Pop()
{
assert(_freeList);
// 头删
void* obj = _freeList;
_freeList = NextObj(obj);
return obj;
}
bool Empty()
{
return _freeList == nullptr;
}
size_t& MaxSize()
{
return _maxSize;
}
private:
void* _freeList;
size_t _maxSize = 1;
};
实现FetchRangobj
// 从中心缓存获取一定数量的对象给thread cache
size_t CentralCache::FetchRangeObj(void*& start, void*& end, size_t batchNum, size_t size)
{
size_t index = SizeClass::Index(size);
_spanLists[index]._mtx.lock();
Span* span = GetOneSpan(_spanLists[index], size);
assert(span);
assert(span->_freeList);
// 从span中获取batchNum个对象
// 如果不够batchNum个,有多少拿多少
start = span->_freeList;
end = start;
size_t i = 0;
size_t actualNum = 1;
while (i < batchNum - 1 && NextObj(end) != nullptr)
{
end = NextObj(end);
++i;
++actualNum;
}
span->_freeList = NextObj(end);
NextObj(end) = nullptr;
span->_useCount += actualNum;
_spanLists[index]._mtx.unlock();
return actualNum;
}
![[LitCTF 2023]Follow me and hack me](https://img-blog.csdnimg.cn/2faf50b6b17c4555bcd647bf59c5f6c6.png)




![[Machine Learning] decision tree 决策树](https://img-blog.csdnimg.cn/d0cc975332dd4992825ed3a0835a8b31.png)