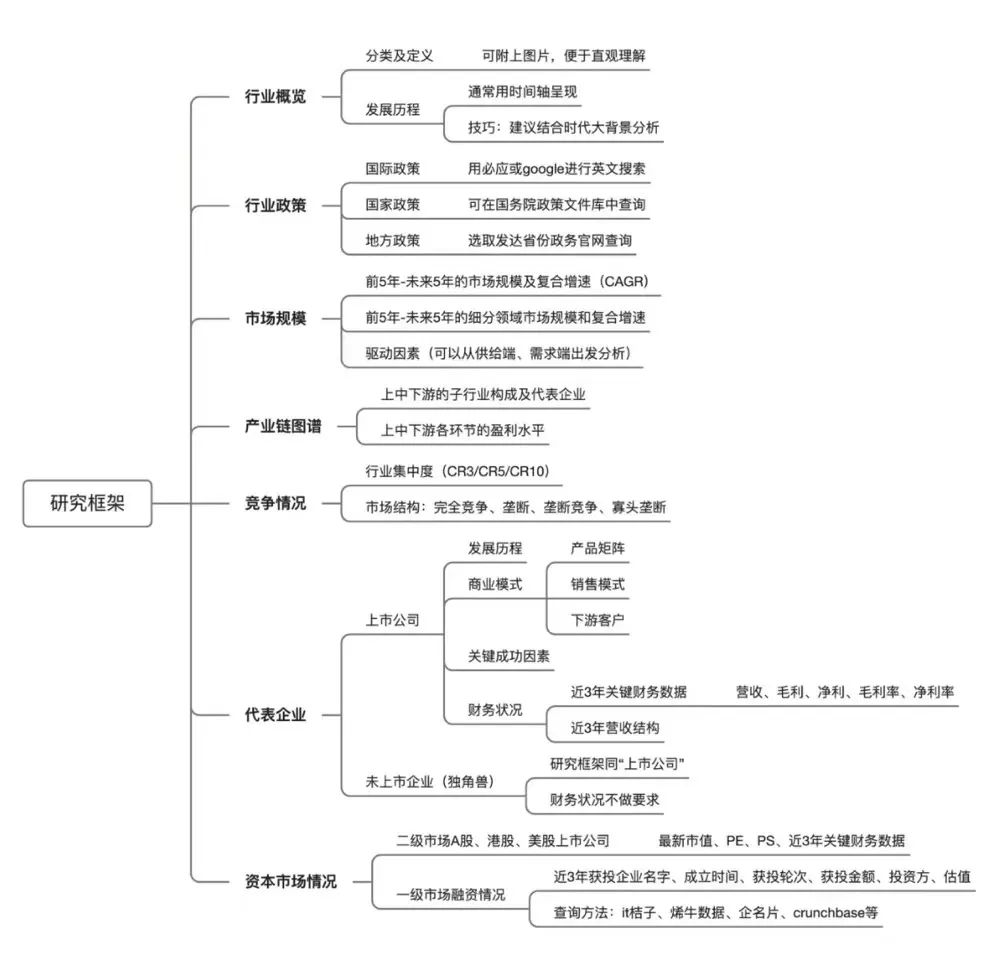
awk里边的函数分为内置函数和自定义函数。
内置函数有下边的几种:
算术函数(arithmetic)
字符串函数(string)
输入/输出函数和通用函数(input/output, and general)
自定义函数格式如下:
function 函数名(参数){
awk语句集
return awk变量
}
算术函数
| 函数名 | 功能 |
|---|---|
| atan2(x, y) | x/y的反正切,x和y以弧度为单位 |
| cos(x) | x的余弦,x以弧度为单位 |
| exp(x) | x的指数函数,exp是高等数学里以自然常数e为底的指数函数。exp(x)表示的是e的x次方 |
| int(x) | x的整数部分,取靠近零一侧的值 |
| log(x) | x的自然对数 |
| rand() | 比0大比1小的随机浮点值 |
| sin(x) | x的正弦,x以弧度为单位 |
| sqrt(x) | x的平方根 |
| srand(x) | 为计算随机数指定一个种子值 |
字符串函数
| 函数名 | 功能 |
|---|---|
| asort(s [,d ]) | 将数组 s 按数据元素值排序。索引值会被替换成表示新的排序顺序的连续数字。另外,如果指定了d,则排序后的数组会存储在数组d中 |
| asorti(s [,d ]) | 将数组 s 按索引值排序。生成的数组会将索引值作为数据元素值,用连续数字索引来表明排序顺序。另外如果指定了 d ,排序后的数组会存储在数组 d 中 |
| gensub(r , s , h [, t ]) | 查找变量$0 或目标字符串 t (如果提供了的话)来匹配正则表达式r 。如果 h 是一个以 g 或 G 开头的字符串,就用 s 替换掉匹配的文本。如果 h 是一个数字,它表示要替换掉第 h 处 r 匹配的地方 |
| gsub(r , s [,t ]) | 查找变量$0 或目标字符串t(如果提供了的话)来匹配正则表达式 r 。如果找到了,就全部替换成字符串 s |
| index(s , t ) | 返回字符串 t 在字符串 s 中的索引值,如果没找到的话返回0length([s ])返回字符串 s 的长度;如果没有指定的话,返回$0的长度 |
| match(s , r [,a ]) | 返回字符串 s 中正则表达式 r 出现位置的索引。如果指定了数组 a ,它会存储 s 中匹配正则表达式的那部分 |
| split(s , a [,r ]) | 将 s 用FS 字符或正则表达式 r (如果指定了的话)分开放到数组 a 中。返回字段的总数 |
| sprintf(format , variables ) | 用提供的 format 和 variables 返回一个类似于printf输出的字符串 |
| sub(r , s [,t ]) | 在变量$0 或目标字符串 t 中查找正则表达式r 的匹配。如果找到了,就用字符串 s 替换掉第一处匹配 |
| substr(s , i [,n ]) | 返回 s 中从索引值 i 开始的 n 个字符组成的子字符串。如果未提供 n ,则返回 s 剩下的部分 |
| tolower(s ) | 将 s 中的所有字符转换成小写 |
| toupper(s ) | 将 s 中的所有字符转换成大写 |
自定义函数
自定义函数需要在BEGIN例程之前进行定义,然后可以在BEGIN例程、主输入循环和END例程都可以使用。
awk 'function sum(a,b){return a+b}BEGIN{ print sum(3+7)}'定义了一个sum函数,返回两个数的值。

此文章为8月Day 13学习笔记,内容来源于极客时间《Linux 实战技能 100 讲》。

![[管理与领导-13]:IT基层管理者 - 激励 - 除了薪资奖金,还有哪些激励手段?](https://img-blog.csdnimg.cn/img_convert/2bf2c0229eeb1c50e46d981c9d70efdd.jpeg)