NODOZE: Combatting Threat Alert Fatigue with Automated Provenance Triage
伊利诺伊大学芝加哥分校
Hassan W U, Guo S, Li D, et al. Nodoze: Combatting threat alert fatigue with automated provenance triage[C]//network and distributed systems security symposium. 2019.
目录
- 0. 摘要
- 1. 引言
- 2. 背景和动机
- A. 攻击实例
- B. 现有工具的局限性
- C. 目标
- 3. NODOZE 概述和方法
- 4. 威胁模型和假设
- 5. 问题定义
- A. 定义
- B. 问题描述
- 6. 算法
- A. 道路地图
- B. 异常分数传播
- C. IN 和 OUT 分数计算
- D. 异常评分归一化
- E. 路径融合
- F. 决策
- G. 时间复杂度
- 7. 实现
- A. 事件频率库
- B. 警报分类和图构建
- C. 可视化模块
- 8. 评估
0. 摘要
威胁警报疲劳”或信息过载问题:网络分析师会在大量错误警报的噪音中错过真正的攻击警报。
NODOZE 首先生成警报事件的因果关系图。然后,它根据相关事件在企业中之前发生的频率,为依赖图中的每条边分配一个异常分数。然后使用一种新颖的网络扩散算法沿着图的相邻边缘传播这些分数,并生成用于分类的聚合异常分数。
在美国 NEC 实验室部署并评估了 NODOZE,根据聚合异常分数始终将真实警报排名高于虚假警报,过引入异常分数的截止阈值,我们估计我们的系统将误报数量减少了 84%,每周为分析师节省 90 多个小时的调查时间。
生成的警报依赖关系图比传统工具生成的警报依赖关系图小两个数量级,而不会牺牲调查所需的重要信息。系统平均运行时开销较低,可以与任何威胁检测软件一起部署。
1. 引言
在许多情况下,如果调查人员只检查单个事件,则错误警报可能看起来与真实警报非常相似。例如,由于勒索软件和 ZIP 程序都在短时间内读写许多文件,因此仅检查单个进程行为的简单勒索软件检测器可以轻松地将 ZIP 归类为勒索软件。现有的 TDS 通常不会提供足够的有关警报的上下文信息。
数据来源分析是威胁警报疲劳问题的一种可能补救措施。数据来源可以通过重建导致警报的事件(向后跟踪)和警报事件的后果(前向跟踪)链来提供有关生成的警报的上下文信息,以更好地将良性系统事件与恶意事件区分开来。但利用数据来源对警报进行分类有两个关键限制:1) 劳动密集——使用现有技术仍然需要网络分析师手动评估每个警报的来源数据,以消除误报,以及2) 依赖爆炸问题——由于现代系统的复杂性,当前的来源跟踪技术将包括错误的依赖,因为输出事件被假定为因果依赖于所有先前的输入事件。
NODOZE 利用历史背景自动降低现有 TDS 的误报率。 NODOZE 通过解决上述现有起源分析技术的两个局限性来实现这一点:它是完全自动化的,并且可以在保持真实攻击场景的同时大大减少依赖图的大小。
起源图中每个事件的可疑性应根据图中相邻事件的可疑性进行调整。由另一个可疑进程创建的进程比由良性进程创建的进程更可疑。
我们的异常分数分配算法是一种没有训练阶段的无监督算法。为了给事件分配异常分数,NODOZE 构建了一个事件频率数据库,其中存储了企业中之前发生的所有事件的频率。在分配异常分数后,NODOZE 使用一种新颖的网络扩散算法来有效地传播和聚合警报依赖图的相邻边(事件)上的分数。最后,它为用于分类的候选警报生成一个聚合异常分数。
为了解决警报调查过程中的依赖爆炸问题,我们提出了行为执行分区的概念。这个想法是根据正常和异常行为对程序执行进行分区,并生成真实警报的最异常依赖图。
我们分别在 9K 和 4K 行 Java 代码中实现了 NODOZE 和事件频率数据库。在美国 NEC 实验室部署并评估了我们的系统。跨越 5 天的 10 亿个系统事件,生成了 364 个警报,包括 10 个 APT 攻击案例和 40 个最近的恶意软件模拟。NODOZE 通过将误报减少 84% 来提高现有 TDS 的准确性。
2. 背景和动机
使用一个攻击示例来说明 NODOZE 作为警报分类系统的有效性和实用性,包括两个方面:1)过滤掉误报以减少警报疲劳,以及 2)使用依赖图简明地解释真实警报加快警报调查过程。
A. 攻击实例
无知的工作人员下载了恶意软件,网络分析师下载诊断工具。二者皆产生了警报且无法区分。
略……,作者旨在说明单从警报来看,真实恶意行为的警报和误报没有区别。
网络分析师为什么要从网上下载诊断工具?不都是跑现场吗?
B. 现有工具的局限性
现有的来源追踪器与 TDS 结合用于警报分类和调查过程时会受到以下限制:
- 警报爆炸和依赖人工:
- 依赖爆炸:依赖性不准确主要是由长时间运行的进程引起的,这些进程在其生命周期内与许多主体/对象进行交互。现有方法将整个进程执行视为单个节点,以便所有输入/输出交互成为流程节点的边。这会导致相当大且不准确的图。
考虑我们示例依赖图中的 Internet Explorer IExplorer.exe 顶点,如图 2a 所示。当网络分析师试图找到下载的恶意软件文件 (springs.7zip) 和诊断工具文件 (collect-info.ps1) 的祖先时,他们将无法确定哪个传入 IP/套接字连接顶点与恶意软件文件相关,以及哪个属于诊断工具文件。
 依赖爆炸问题的先前解决方案建议将长时间运行的流程的执行划分为自治“单元”,以便在输入和输出事件之间提供更精确的因果依赖关系。但是,这些系统需要最终用户参与和通过源代码检测、使用典型工作负载训练应用程序运行以及修改内核来更改系统。由于专有软件和许可协议,代码检测在企业中通常是不可能的。此外,这些系统仅针对 Linux 实现,它们的设计不适用于像 Microsoft Windows 这样的商用现成操作系统。最后,获取异构大型企业中的典型应用程序工作负载实际上是不可行的。
依赖爆炸问题的先前解决方案建议将长时间运行的流程的执行划分为自治“单元”,以便在输入和输出事件之间提供更精确的因果依赖关系。但是,这些系统需要最终用户参与和通过源代码检测、使用典型工作负载训练应用程序运行以及修改内核来更改系统。由于专有软件和许可协议,代码检测在企业中通常是不可能的。此外,这些系统仅针对 Linux 实现,它们的设计不适用于像 Microsoft Windows 这样的商用现成操作系统。最后,获取异构大型企业中的典型应用程序工作负载实际上是不可行的。
C. 目标
- 警报减少:减少误报、漏报和不可操作的项目。
- 简洁的上下文警报:生成的威胁警报依赖图应该简洁完整。
- 通用性:应该独立于底层平台(例如 OS、VM 等)、应用程序和 TDS。
- 实用性:应该不需要任何终端系统更改,并且应该可以部署在任何现有的 TDS 上。
3. NODOZE 概述和方法

NODOZE 充当现有 TDS 的附加组件,以减少误报并提供生成的威胁警报的上下文解释。为了对警报进行分类,NODOZE 首先为生成的警报来源图中的每个事件分配一个异常分数。然后使用一种新颖的网络扩散算法来传播和聚合沿相邻事件的异常分数。最后,它为生成的警报生成一个聚合异常分数,用于分类。
在图 2a 中,有两个威胁警报事件由 E1 和 E2 注释,并用虚线箭头显示。单独查看这些警报事件,它们看起来很相似(都与重要的内部主机建立套接字连接)。然而,当我们使用后向和前向追踪来考虑每个警报事件的祖先和后代时,我们可以看到每个警报事件的行为都明显不同。
为了确定威胁警报是真正的攻击还是误报,NODOZE 使用异常分数来量化过去发生的相关事件的“罕见性”或转移概率。例如,警报事件 E1 的后代,即 dropper.exe → y.y.y.y:445 由几个更罕见的事件组成,即具有较低的转换概率。警报事件 E2 的祖先包含诊断事件,例如定期执行的 Tasklist 和 Ipconfig,以检查企业中计算机的健康状况。因此,E2 的总异常分数将大大低于 E2 的异常分数。
一旦 NODOZE 为警报事件分配了威胁分数,它从具有最高异常分数的依赖图中提取子图,真实警报 E1 的依赖图如图 2b 所示。虽然 IExplorer.exe 收到了多个套接字连接,但 NODOZE 只选择了罕见的 IP 地址 a.a.a.a(从中下载恶意软件的恶意网站)和 b.b.b.b,因为它们的异常分数高于其他正常套接字连接。
4. 威胁模型和假设
- 假设攻击者无法操纵或删除出处记录,即始终保持日志完整性
- 不考虑使用不通过系统调用接口的隐式流(侧通道)执行的攻击
- 不跟踪利用内核漏洞的攻击
- 假设底层 TDS 的检测率是完整的
- 假设至少有一个事件在 alert 的祖先或后代中是异常的,将其归类为真正的攻击
- 不考虑模仿攻击
5. 问题定义
A. 定义
- 依赖事件:经典三元组,主体客体和关系
- 依赖路径:依赖事件 Ea 的依赖路径 P 表示导致 Ea 的事件链和由 Ea 引发的事件链(即事件本身及其前后因果事件)。分为数据依赖和控制依赖


- 依赖图:
- 真正的警报依赖关系图:进行执行分区划分后的图,剔除掉了错误依赖。
B. 问题描述
给定 n 个警报事件列表
E
1
,
E
2
,
.
.
.
,
E
n
{E_1, E_2, ..., E_n}
E1,E2,...,En 和用户指定的阈值参数
τ
l
τ_l
τl 和
τ
d
τ_d
τd,我们的目标是根据它们的异常分数对这些警报进行排名,并过滤掉所有异常分数小于
τ
d
τ_d
τd 的警报作为误报。
6. 算法
A. 道路地图
分配异常分数的一种简单方法是使用过去发生的系统事件的频率,这样组织中罕见的事件被认为更异常。然而,有时这种假设可能不成立,因为攻击可能涉及经常发生的事件。因此,我们的目标是定义异常分数,而不是仅基于依赖路径中的单个事件,而是基于整个路径。
B. 异常分数传播
给定警报事件
E
α
E_α
Eα 的完整依赖图 G,我们找到
E
α
E_α
Eα 的所有长度为
τ
l
τ_l
τl 的依赖路径。为此,我们从警报事件开始以前后方式运行深度优先遍历,然后将这些后向和前向路径组合起来生成统一路径,以便每个统一路径都包含警报的祖先和后代因果事件。
为了计算异常分数,我们首先为给定的警报事件依赖图 G 构造一个 N × N 转移概率矩阵 M,其中 N 是 G 中的顶点总数。每个矩阵条目 Mε 由以下等式计算:
M
ε
=
p
r
o
b
a
b
i
l
i
t
y
(
ε
)
=
∣
F
r
e
q
(
ε
)
∣
∣
F
r
e
q
s
r
c
r
e
l
(
ε
)
∣
M_{\varepsilon}=probability(\varepsilon)=\frac{|Freq(\varepsilon)|}{|Freqsrc_rel(\varepsilon)|}
Mε=probability(ε)=∣Freqsrcrel(ε)∣∣Freq(ε)∣,其中
F
r
e
q
Freq
Freq 为发生次数。为了统计过去发生的事件的频率,我们建立了一个事件频率数据库,定期存储和更新整个企业的事件频率。
给定事件的转移概率告诉我们特定来源流向特定目的地的概率;然而,我们最终将通过图传播这个值,但是当我们这样做时,我们想要考虑从源流出的数据总量,以及流入目的地的数据总量。我们计算依赖图 G 中每个实体的 IN 和 OUT 分数向量。
最后,正则性得分 R S ( P ) RS(P) RS(P) 计算如下: R S ( P ) = ∏ i = 1 l I N ( S R C i ) × M ( ε i ) × O U T ( D S T i ) RS(P)=\prod\limits_{i=1}^{l}IN(SRC_i)\times M(\varepsilon_i)\times OUT(DST_i) RS(P)=i=1∏lIN(SRCi)×M(εi)×OUT(DSTi)异常分数为: A S ( P ) = 1 − R S ( P ) AS(P)=1-RS(P) AS(P)=1−RS(P)

C. IN 和 OUT 分数计算
我们根据每个实体的类型为每个实体填充 IN 和 OUT 分数。
- 进程实体:划分很多个时间窗口,如果时间窗口内没有新边加入,则视为稳定窗口,一个实体的IN分数和OUT分数均为稳定窗口与窗口总数之比。
I N ( v ) = ∣ T t o ′ ∣ ∣ T ∣ O U T ( v ) = ∣ T f r o m ′ ∣ ∣ T ∣ IN(v)=\frac{|T_{to}^{\prime}|}{|T|}\quad\quad OUT(v)=\frac{|T_{from}^{\prime}|}{|T|}\quad IN(v)=∣T∣∣Tto′∣OUT(v)=∣T∣∣Tfrom′∣ - 数据实体:数据实体主要是文件和网络链接。进一步细分为三类:临时文件、可执行文件和已知的恶意扩展。临时文件给很高的分,用先验知识给可执行文件、恶意扩展、恶意ip低分,其余实体0.5分
D. 异常评分归一化
由于单纯的叠加会导致长路径的分数高于短路径,所以引入一个衰减因子用以归一化。
R
S
(
P
)
=
∏
i
=
1
l
I
N
(
S
R
C
i
)
×
M
(
ε
i
)
×
O
U
T
(
D
S
T
i
)
×
α
RS(P)=\prod\limits_{i=1}^lIN(SRC_i)\times M(\varepsilon_i)\times OUT(DST_i)\times\alpha
RS(P)=i=1∏lIN(SRCi)×M(εi)×OUT(DSTi)×α
E. 路径融合
该步骤试图通过只包含具有高异常分数的依赖路径来构建一个准确的真正警报依赖图,通过合并,尽量减少路径的数量,进一步保证靠前的路径构建出来的子图包含大部分恶意行为。

F. 决策
NODOZE的主要目标是对给定时间线中的所有警报进行排序。然而,我们也可以计算一个决策或截断阈值τd,它可以用来确定候选威胁警报是真攻击还是高置信度的假警报。
G. 时间复杂度
每次根据给定警报进行两次固定深度的DFS,一次向前一次向后。时间复杂度为
O
(
∣
b
D
∣
\mathcal{O}(|b^{D}|
O(∣bD∣,取决于节点的分支数和搜索的深度。
7. 实现
Windows ETW + Linux Auditd、PostgreSQL database
a)事件频率数据库生成器,b)警报分类和图形生成器,以及c)可视化模块
A. 事件频率库
- 进程实体:进程路径、命令行参数、组标识gid
- 文件实体:抽象文件路径(删除特定用户信息)
- socket实体:保留外部地址,抽象内部地址
B. 警报分类和图构建
- 合并瞬时进程:有些进程的存在意义仅为唤起另一进程,这种情况将二者合并
- 合并相同套接字:由同一进程发起的相同地址的套接字合并
C. 可视化模块
使用GraphViz生成点格式的因果图,然后将点文件转换为html格式
8. 评估
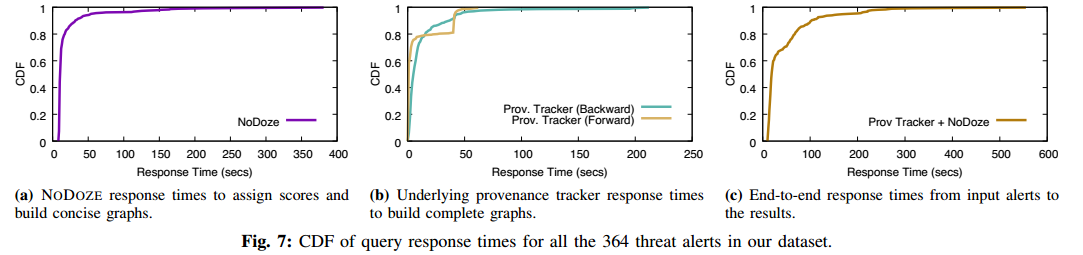
准确率:设定当设置阈值使得决策为100%检测真阳性时,假阳性为16%。换句话说,误报减少84%。


依赖图减少程度:减少两个数量级
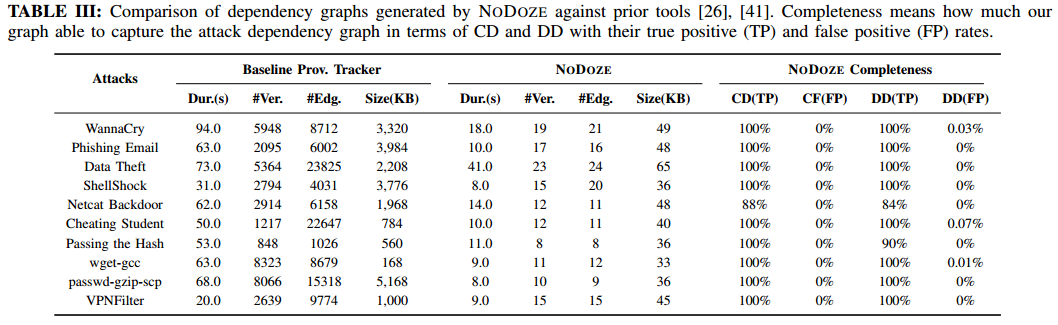
节省多少人工时间:假设每个假警报花20分钟,过滤掉84%,约90个小时。
运行开销: