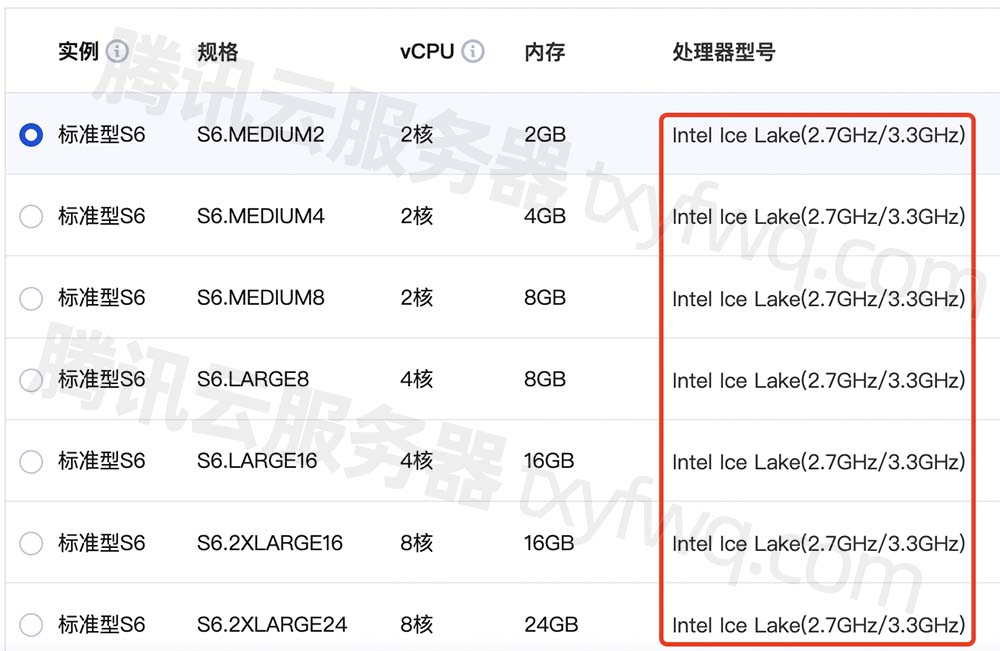
机器学习笔记之优化算法——关于二次上界引理
- 引言
- 回顾:
- 利普希兹连续
- 梯度下降法介绍
- 二次上界引理:介绍与作用
- 二次上界与最优步长之间的关系
- 二次上界引理证明过程
引言
本节将介绍二次上界的具体作用以及它的证明过程。
回顾:
利普希兹连续
在
Wolfe
\text{Wolfe}
Wolfe准则收敛性证明一节中简单介绍了利普希兹连续
(
Lipschitz Continuity
)
(\text{Lipschitz Continuity})
(Lipschitz Continuity)。其定义对应数学符号表达如下:
∀
x
,
x
^
∈
R
n
,
∃
L
:
s
.
t
.
∣
∣
f
(
x
)
−
f
(
x
^
)
∣
∣
≤
L
⋅
∣
∣
x
−
x
^
∣
∣
\forall x,\hat x \in \mathbb R^n , \exist \mathcal L: \quad s.t. ||f(x) - f(\hat x)|| \leq \mathcal L \cdot ||x - \hat x||
∀x,x^∈Rn,∃L:s.t.∣∣f(x)−f(x^)∣∣≤L⋅∣∣x−x^∣∣
如果函数
f
(
⋅
)
f(\cdot)
f(⋅)满足利普希兹连续,对上式进行简单变换可得到:
不等式左侧可使用拉格朗日中值定理进行进一步替换。
∃
ξ
∈
(
x
,
x
^
)
⇒
∣
∣
f
(
x
)
−
f
(
x
^
)
∣
∣
∣
∣
x
−
x
^
∣
∣
=
f
′
(
ξ
)
≤
L
\exist \xi \in (x,\hat x) \Rightarrow \frac{||f(x) - f(\hat x)||}{||x - \hat x||} = f'(\xi)\leq \mathcal L
∃ξ∈(x,x^)⇒∣∣x−x^∣∣∣∣f(x)−f(x^)∣∣=f′(ξ)≤L
这意味着:在函数
f
(
⋅
)
f(\cdot)
f(⋅)在定义域内的绝大部分点处的变化率存在上界,受到
L
\mathcal L
L的限制。
梯度下降法介绍
在梯度下降法铺垫:总体介绍一节中对梯度下降法进行了简单认识。首先,梯度下降法是一个典型的线搜索方法
(
Line Search Method
)
(\text{Line Search Method})
(Line Search Method)。其迭代过程对应数学符号表示如下:
x
k
+
1
=
x
k
+
α
k
⋅
P
k
x_{k+1} = x_k + \alpha_k \cdot \mathcal P_k
xk+1=xk+αk⋅Pk
- 其中
P
k
∈
R
n
\mathcal P_k \in \mathbb R^n
Pk∈Rn,描述数值解的更新方向,在梯度下降法中,它选择目标函数
f
(
⋅
)
f(\cdot)
f(⋅)在
x
k
x_k
xk处梯度的反方向
−
∇
f
(
x
k
)
- \nabla f(x_k)
−∇f(xk)作为更新方向,也称最速下降方向:
P k = − ∇ f ( x k ) \mathcal P_k = -\nabla f(x_k) Pk=−∇f(xk) - 而 α k \alpha_k αk表示步长。基于步长的选择方式分为精确搜索与非精确搜索两类。关于非精确搜索——通过迭代获取数值解序列并以此近似最优步长的方法详见:
本节将介绍梯度下降法中使用精确搜索求解最优步长,以及精确搜索的限制条件——二次上界引理。
二次上界引理:介绍与作用
在求解梯度下降法的精确步长过程中,关于目标函数
f
(
⋅
)
f(\cdot)
f(⋅),在其定义域内可微的基础上增加一个条件:目标函数的梯度函数
∇
f
(
⋅
)
\nabla f(\cdot)
∇f(⋅)满足利普希兹连续。
如果是梯度函数
∇
f
(
⋅
)
\nabla f(\cdot)
∇f(⋅)满足利普希兹连续,根据上面的格式,可以得到:
∇
2
f
(
⋅
)
≤
L
\nabla^2 f(\cdot) \leq \mathcal L
∇2f(⋅)≤L
而二阶梯度描述的是梯度
∇
f
(
⋅
)
\nabla f(\cdot)
∇f(⋅)的变化量。这意味着:关于
∇
f
(
⋅
)
\nabla f(\cdot)
∇f(⋅)的变化情况不会过于剧烈。相反,如果
∇
f
(
⋅
)
\nabla f(\cdot)
∇f(⋅)的变化情况过于剧烈:即便迭代过程中极小的一次更新,对应函数结果的变化也极大,例如:
f
(
x
)
=
1
x
\begin{aligned}f(x) = \frac{1}{x}\end{aligned}
f(x)=x1在
x
∈
(
0
,
1
]
x \in (0,1]
x∈(0,1]区间内
∇
f
(
⋅
)
\nabla f(\cdot)
∇f(⋅)的变化情况。从而在迭代过程中,可能出现梯度爆炸的现象。
基于上述条件,可以得到结论:函数
f
(
⋅
)
f(\cdot)
f(⋅)存在二次上界。其数学符号表示为:
∀
x
,
y
∈
R
n
⇒
f
(
y
)
≤
f
(
x
)
+
[
∇
f
(
x
)
]
T
⋅
(
y
−
x
)
+
L
2
∣
∣
y
−
x
∣
∣
2
\forall x,y \in \mathbb R^n \Rightarrow f(y) \leq f(x) + [\nabla f(x)]^T \cdot (y-x) + \frac{\mathcal L}{2}||y - x||^2
∀x,y∈Rn⇒f(y)≤f(x)+[∇f(x)]T⋅(y−x)+2L∣∣y−x∣∣2
我们之前仅知道函数梯度
∇
f
(
⋅
)
\nabla f(\cdot)
∇f(⋅)的变化率存在上界对其进行约束,但可通过该结论求出该上界的精确结果。
首先通过图像观察该结论各部分的具体意义:

很明显,这仅是一个一维变量对应的函数结果
(
R
↦
R
)
(\mathbb R \mapsto\mathbb R)
(R↦R),其中蓝色虚线箭头表示
f
(
y
)
f(y)
f(y);黑色虚线箭头表示
f
(
x
)
+
[
∇
f
(
x
)
]
T
⋅
(
y
−
x
)
f(x) + [\nabla f(x)]^T \cdot (y - x)
f(x)+[∇f(x)]T⋅(y−x)。在上述结论中,两者之间的差距(绿色实线)不会无限大下去,而是存在一个上界约束这个差距:
f
(
y
)
−
[
f
(
x
)
+
[
∇
f
(
x
)
]
T
⋅
(
y
−
x
)
]
≤
L
2
∣
∣
y
−
x
∣
∣
2
f(y) - [f(x) + [\nabla f(x)]^T \cdot (y-x)] \leq \frac{\mathcal L}{2}||y -x||^2
f(y)−[f(x)+[∇f(x)]T⋅(y−x)]≤2L∣∣y−x∣∣2
假如这个差距结果远远大于
L
2
∣
∣
y
−
x
∣
∣
2
\begin{aligned}\frac{\mathcal L}{2}||y -x||^2\end{aligned}
2L∣∣y−x∣∣2。例如:

从图像中可以明显看到,如果
f
(
y
)
f(y)
f(y)与
f
(
x
)
+
[
∇
f
(
x
)
]
T
(
y
−
x
)
f(x) + [\nabla f(x)]^T (y - x)
f(x)+[∇f(x)]T(y−x)之间的差距过大的话,那么必然是
f
(
y
)
f(y)
f(y)处的斜率与
f
(
x
)
f(x)
f(x)处的斜率差距过大产生的结果。因此这个差距上界
L
2
∣
∣
y
−
x
∣
∣
2
\begin{aligned}\frac{\mathcal L}{2}||y - x||^2\end{aligned}
2L∣∣y−x∣∣2本质上依然是约束
∇
f
(
⋅
)
\nabla f(\cdot)
∇f(⋅)变化率的大小。
这种情况出现梯度爆炸的可能性更高。
二次上界与最优步长之间的关系
假定二次上界引理是已知的,我们观察:二次上界引理对精确步长的求解起到什么作用。
∀
x
,
y
∈
R
n
⇒
f
(
y
)
≤
f
(
x
)
+
[
∇
f
(
x
)
]
T
⋅
(
y
−
x
)
+
L
2
∣
∣
y
−
x
∣
∣
2
\forall x,y \in \mathbb R^n \Rightarrow f(y) \leq f(x) + [\nabla f(x)]^T \cdot (y-x) + \frac{\mathcal L}{2}||y - x||^2
∀x,y∈Rn⇒f(y)≤f(x)+[∇f(x)]T⋅(y−x)+2L∣∣y−x∣∣2
既然二次上界引理对于
∀
x
,
y
∈
R
n
\forall x,y \in \mathbb R^n
∀x,y∈Rn均成立,我们可以将
x
,
y
x,y
x,y视作:某次迭代步骤
k
k
k的
x
k
,
x
k
+
1
x_k,x_{k+1}
xk,xk+1:
后续依然使用
x
,
y
x,y
x,y进行表示。
{
x
⇒
x
k
y
⇒
x
k
+
1
y
=
x
+
α
k
⋅
P
k
\begin{cases} x \Rightarrow x_k \\ y \Rightarrow x_{k+1} \\ y = x + \alpha_k \cdot \mathcal P_k \end{cases}
⎩
⎨
⎧x⇒xky⇒xk+1y=x+αk⋅Pk
由于
x
⇒
x
k
x \Rightarrow x_k
x⇒xk是上一次迭代步骤产生的位置,是已知项。这意味着:上述不等式右侧相当于关于变量
y
⇒
x
k
+
1
y \Rightarrow x_{k+1}
y⇒xk+1的一个二次函数。记作
ϕ
(
y
)
\phi(y)
ϕ(y):
{
ϕ
(
y
)
≜
f
(
x
)
+
[
∇
f
(
x
)
]
T
⋅
(
y
−
x
)
+
L
2
∣
∣
y
−
x
∣
∣
2
f
(
y
)
≤
ϕ
(
y
)
\begin{cases} \phi(y) \triangleq f(x) + [\nabla f(x)]^T \cdot (y - x) + \frac{\mathcal L}{2}||y - x||^2 \\ \quad \\ f(y) \leq \phi(y) \end{cases}
⎩
⎨
⎧ϕ(y)≜f(x)+[∇f(x)]T⋅(y−x)+2L∣∣y−x∣∣2f(y)≤ϕ(y)
由于关于
y
y
y的二次项
L
2
>
0
\begin{aligned}\frac{\mathcal L}{2} > 0\end{aligned}
2L>0,说明函数
ϕ
(
y
)
\phi(y)
ϕ(y)存在最小值。对该值进行求解:
函数图像开口向上~
y
m
i
n
=
arg
min
y
∈
R
n
ϕ
(
y
)
y_{min} = \mathop{\arg\min}\limits_{y \in \mathbb R^n} \phi(y)
ymin=y∈Rnargminϕ(y)
- 首先对
ϕ
(
y
)
\phi(y)
ϕ(y)关于
y
y
y求解梯度:
与x x x相关的项均视作常数。
∇ ϕ ( y ) = 0 + ∇ f ( x ) ⋅ 1 + L 2 ⋅ 2 ⋅ ( y − x ) = ∇ f ( x ) + L ⋅ ( y − x ) \begin{aligned} \nabla \phi(y) & = 0 + \nabla f(x) \cdot 1 + \frac{\mathcal L}{2} \cdot 2 \cdot (y-x) \\ & = \nabla f(x) + \mathcal L \cdot (y-x) \end{aligned} ∇ϕ(y)=0+∇f(x)⋅1+2L⋅2⋅(y−x)=∇f(x)+L⋅(y−x) - 令
∇
ϕ
(
y
)
≜
0
\nabla \phi(y) \triangleq 0
∇ϕ(y)≜0,有:
y m i n = − ∇ f ( x ) L + x y_{min} = -\frac{\nabla f(x)}{\mathcal L} + x ymin=−L∇f(x)+x
对应 ϕ ( y ) \phi(y) ϕ(y)的最小值 min ϕ ( y ) \min \phi(y) minϕ(y)有:
min ϕ ( y ) = ϕ ( y m i n ) = f ( x ) + [ ∇ f ( x ) ] T ⋅ ( − ∇ f ( x ) L ) + L 2 ⋅ [ − ∇ f ( x ) ] T [ − ∇ f ( x ) ] L 2 = f ( x ) − ∣ ∣ ∇ f ( x ) ∣ ∣ 2 2 L \begin{aligned} \min \phi(y) & = \phi(y_{min}) \\ & = f(x) + [\nabla f(x)]^T \cdot \left(-\frac{\nabla f(x)}{\mathcal L}\right) + \frac{\mathcal L}{2} \cdot \frac{[- \nabla f(x)]^T [- \nabla f(x)]}{\mathcal L^2}\\ & = f(x) - \frac{||\nabla f(x)||^2}{2\mathcal L} \end{aligned} minϕ(y)=ϕ(ymin)=f(x)+[∇f(x)]T⋅(−L∇f(x))+2L⋅L2[−∇f(x)]T[−∇f(x)]=f(x)−2L∣∣∇f(x)∣∣2
将 y = x + α k ⋅ P k y = x + \alpha_k \cdot \mathcal P_k y=x+αk⋅Pk代入,观察:
-
P
k
\mathcal P_k
Pk
是描述更新方向的向量,对应的是负梯度方向 − ∇ f ( x ) -\nabla f(x) −∇f(x); 同理,α k \alpha_k αk对应1 L \begin{aligned}\frac{1}{\mathcal L}\end{aligned} L1。
{ y = x + α k ⋅ P k y m i n = x + 1 L ⋅ [ − ∇ f ( x ) ] ⇒ { α k = 1 L P k = − ∇ f ( x ) \begin{cases} \begin{aligned} y & = x + \alpha_k \cdot \mathcal P_k \\ y_{min} & = x + \frac{1}{\mathcal L} \cdot [-\nabla f(x)] \end{aligned} \end{cases} \Rightarrow \begin{cases} \begin{aligned}\alpha_k & = \frac{1}{\mathcal L} \\ \mathcal P_k & = - \nabla f(x) \end{aligned} \end{cases} ⎩ ⎨ ⎧yymin=x+αk⋅Pk=x+L1⋅[−∇f(x)]⇒⎩ ⎨ ⎧αkPk=L1=−∇f(x)
但需要注意的是: f ( y ) ≤ ϕ ( y ) f(y) \leq \phi(y) f(y)≤ϕ(y),而 y m i n y_{min} ymin仅仅是 ϕ ( y ) \phi(y) ϕ(y)中的最小值。也就是说: y m i n y_{min} ymin是 f ( y ) f(y) f(y)取值上界中的最小值。在这种条件下,我们认为 α k = 1 L \begin{aligned}\alpha_k = \frac{1}{\mathcal L}\end{aligned} αk=L1就是可控制的最优步长。
二次上界引理证明过程
条件:函数
f
(
⋅
)
f(\cdot)
f(⋅)可微,并且
∇
f
(
⋅
)
\nabla f(\cdot)
∇f(⋅)满足利普希兹连续;
结论:
f
(
⋅
)
f(\cdot)
f(⋅)存在二次上界:
∀
x
,
y
∈
R
n
⇒
f
(
y
)
≤
f
(
x
)
+
[
∇
f
(
x
)
]
T
⋅
(
y
−
x
)
+
L
2
∣
∣
y
−
x
∣
∣
2
\forall x,y \in \mathbb R^n \Rightarrow f(y) \leq f(x) + [\nabla f(x)]^T \cdot (y - x) + \frac{\mathcal L}{2}||y - x||^2
∀x,y∈Rn⇒f(y)≤f(x)+[∇f(x)]T⋅(y−x)+2L∣∣y−x∣∣2
证明:
由于上述的
x
,
y
∈
R
n
x,y \in \mathbb R^n
x,y∈Rn是定义域内任意取值,因而无法直接从条件中获取到
f
(
x
)
,
f
(
y
)
f(x),f(y)
f(x),f(y)之间的大小关系。这里不妨设:
y
>
x
y > x
y>x,并引入辅助函数
G
(
θ
)
\mathcal G(\theta)
G(θ):
在
x
,
y
∈
R
n
(
y
>
x
)
x,y \in \mathbb R^n \text{ } (y > x)
x,y∈Rn (y>x)确定的情况下,构建一个关于
θ
\theta
θ的函数,从而通过调节
θ
\theta
θ来获取
[
f
(
x
)
,
f
(
y
)
]
[f(x),f(y)]
[f(x),f(y)]之间的函数结果。
G
(
θ
)
=
f
[
θ
⋅
y
+
(
1
−
θ
)
⋅
x
]
=
f
[
x
+
θ
(
y
−
x
)
]
θ
∈
[
0
,
1
]
\begin{aligned} \mathcal G(\theta) & = f [\theta \cdot y + (1 - \theta) \cdot x] \\ & = f [x + \theta(y - x)] \quad \theta \in [0,1] \end{aligned}
G(θ)=f[θ⋅y+(1−θ)⋅x]=f[x+θ(y−x)]θ∈[0,1]
从而有:
G
(
0
)
=
f
(
x
)
;
G
(
1
)
=
f
(
y
)
\mathcal G(0) = f(x);\mathcal G(1) = f(y)
G(0)=f(x);G(1)=f(y)。将其与结论中的对应项进行替换:
仅需证明‘替换’后的式子成立即可。
G
(
1
)
≤
G
(
0
)
+
[
∇
f
(
x
)
]
T
⋅
(
y
−
x
)
+
L
2
∣
∣
y
−
x
∣
∣
2
⇒
G
(
1
)
−
G
(
0
)
−
[
∇
f
(
x
)
]
T
⋅
(
y
−
x
)
≤
L
2
∣
∣
y
−
x
∣
∣
2
\begin{aligned} & \quad \quad \mathcal G(1) \leq \mathcal G(0) + [\nabla f(x)]^T \cdot (y - x) + \frac{\mathcal L}{2} ||y - x||^2 \\ & \Rightarrow \mathcal G(1) - \mathcal G(0) - [\nabla f(x)]^T \cdot (y - x) \leq \frac{\mathcal L}{2} ||y - x||^2 \end{aligned}
G(1)≤G(0)+[∇f(x)]T⋅(y−x)+2L∣∣y−x∣∣2⇒G(1)−G(0)−[∇f(x)]T⋅(y−x)≤2L∣∣y−x∣∣2
观察不等式左侧:
使用牛顿-莱布尼兹公式,可以将
G
(
1
)
−
G
(
0
)
\mathcal G(1) - \mathcal G(0)
G(1)−G(0)表示成如下形式:
G
(
1
)
−
G
(
0
)
=
G
(
θ
)
∣
0
1
=
∫
0
1
G
′
(
θ
)
d
θ
\mathcal G(1) - \mathcal G(0) = \mathcal G(\theta) |_{0}^1 = \int_{0}^1 \mathcal G'(\theta) d\theta
G(1)−G(0)=G(θ)∣01=∫01G′(θ)dθ
关于项
[
∇
f
(
x
)
]
T
⋅
(
y
−
x
)
[\nabla f(x)]^T \cdot (y - x)
[∇f(x)]T⋅(y−x),同样可以使用定积分的形式进行表示。其中
[
∇
f
(
x
)
]
T
⋅
(
y
−
x
)
[\nabla f(x)]^T \cdot (y - x)
[∇f(x)]T⋅(y−x)中不含
θ
\theta
θ,被视作常数。
[
∇
f
(
x
)
]
T
⋅
(
y
−
x
)
=
[
∇
f
(
x
)
]
T
⋅
(
y
−
x
)
⋅
1
=
[
∇
f
(
x
)
]
T
⋅
(
y
−
x
)
⋅
θ
∣
0
1
=
[
∇
f
(
x
)
]
T
⋅
(
y
−
x
)
⋅
∫
0
1
1
d
θ
=
∫
0
1
[
∇
f
(
x
)
]
T
⋅
(
y
−
x
)
d
θ
\begin{aligned} [\nabla f(x)]^T \cdot(y - x) & = [\nabla f(x)]^T \cdot (y - x) \cdot 1 \\ & = [\nabla f(x)]^T \cdot (y - x) \cdot \theta |_0^1 \\ & = [\nabla f(x)]^T \cdot (y - x) \cdot \int_0^1 1 d\theta \\ & = \int_{0}^1 [\nabla f(x)]^T \cdot (y - x) d\theta \end{aligned}
[∇f(x)]T⋅(y−x)=[∇f(x)]T⋅(y−x)⋅1=[∇f(x)]T⋅(y−x)⋅θ∣01=[∇f(x)]T⋅(y−x)⋅∫011dθ=∫01[∇f(x)]T⋅(y−x)dθ
至此,不等式左侧可表示为:
I
l
e
f
t
=
∫
0
1
G
′
(
θ
)
d
θ
−
∫
0
1
[
∇
f
(
x
)
]
T
⋅
(
y
−
x
)
d
θ
=
∫
0
1
{
[
∇
f
(
x
+
θ
⋅
(
y
−
x
)
)
]
T
⋅
(
y
−
x
)
−
[
∇
f
(
x
)
]
T
⋅
(
y
−
x
)
}
d
θ
\begin{aligned} \mathcal I_{left} & = \int_{0}^1 \mathcal G'(\theta) d\theta - \int_{0}^1 [\nabla f(x)]^T \cdot (y - x) d\theta \\ & = \int_0^1 \left \{[\nabla f(x + \theta \cdot (y - x))]^T\cdot (y - x) - [\nabla f(x)]^T \cdot (y - x) \right\} d\theta \end{aligned}
Ileft=∫01G′(θ)dθ−∫01[∇f(x)]T⋅(y−x)dθ=∫01{[∇f(x+θ⋅(y−x))]T⋅(y−x)−[∇f(x)]T⋅(y−x)}dθ
提出公共部分:
y
−
x
y - x
y−x,将剩余部分进行合并:
I
l
e
f
t
=
∫
0
1
{
∇
f
[
x
+
θ
⋅
(
y
−
x
)
]
−
∇
f
(
x
)
}
T
⋅
(
y
−
x
)
d
θ
\mathcal I_{left} = \int_{0}^1 \left\{\nabla f[x + \theta \cdot (y - x)] - \nabla f(x)\right\}^T \cdot (y - x) d\theta
Ileft=∫01{∇f[x+θ⋅(y−x)]−∇f(x)}T⋅(y−x)dθ
观察积分号内的项,其本质上是向量
∇
f
[
x
+
θ
⋅
(
y
−
x
)
]
−
∇
f
(
x
)
\nabla f[x + \theta \cdot (y - x)] - \nabla f(x)
∇f[x+θ⋅(y−x)]−∇f(x)与向量
y
−
x
y - x
y−x的内积结果。因而有:
不等式满足的原因:
cos
θ
∈
[
−
1
,
1
]
\cos \theta \in [-1,1]
cosθ∈[−1,1]
{
∇
f
[
x
+
θ
⋅
(
y
−
x
)
]
−
∇
f
(
x
)
}
T
⋅
(
y
−
x
)
=
∣
∣
∇
f
[
x
+
θ
⋅
(
y
−
x
)
]
−
∇
f
(
x
)
∣
∣
⋅
∣
∣
y
−
x
∣
∣
⋅
cos
θ
≤
∣
∣
∇
f
[
x
+
θ
⋅
(
y
−
x
)
]
−
∇
f
(
x
)
∣
∣
⋅
∣
∣
y
−
x
∣
∣
\begin{aligned} \left\{\nabla f[x + \theta \cdot (y - x)] - \nabla f(x)\right\}^T \cdot (y - x) & = ||\nabla f[x + \theta \cdot (y - x)] - \nabla f(x)|| \cdot ||y - x|| \cdot \cos \theta \\ & \leq ||\nabla f[x + \theta \cdot (y - x)] - \nabla f(x)|| \cdot ||y - x|| \end{aligned}
{∇f[x+θ⋅(y−x)]−∇f(x)}T⋅(y−x)=∣∣∇f[x+θ⋅(y−x)]−∇f(x)∣∣⋅∣∣y−x∣∣⋅cosθ≤∣∣∇f[x+θ⋅(y−x)]−∇f(x)∣∣⋅∣∣y−x∣∣
将该不等式带回
I
l
e
f
t
\mathcal I_{left}
Ileft,有:
I
l
e
f
t
≤
∫
0
1
∣
∣
∇
f
[
x
+
θ
⋅
(
y
−
x
)
]
−
∇
f
(
x
)
∣
∣
⋅
∣
∣
y
−
x
∣
∣
d
θ
\mathcal I_{left} \leq \int_0^1 ||\nabla f[x + \theta \cdot (y - x)] - \nabla f(x)|| \cdot ||y - x|| d\theta
Ileft≤∫01∣∣∇f[x+θ⋅(y−x)]−∇f(x)∣∣⋅∣∣y−x∣∣dθ
由于
f
(
⋅
)
f(\cdot)
f(⋅)满足利普希兹连续,因而有:
其中
θ
∈
[
0
,
1
]
\theta \in [0,1]
θ∈[0,1],因而可以将其从范数符号中提出来。
∣
∣
∇
f
[
x
+
θ
⋅
(
y
−
x
)
]
−
∇
f
(
x
)
∣
∣
≤
L
⋅
∣
∣
x
+
θ
⋅
(
y
−
x
)
−
x
∣
∣
=
L
⋅
θ
⋅
∣
∣
y
−
x
∣
∣
||\nabla f[x + \theta \cdot (y - x)] - \nabla f(x)|| \leq \mathcal L \cdot ||x + \theta \cdot (y -x) - x|| = \mathcal L \cdot \theta \cdot ||y - x||
∣∣∇f[x+θ⋅(y−x)]−∇f(x)∣∣≤L⋅∣∣x+θ⋅(y−x)−x∣∣=L⋅θ⋅∣∣y−x∣∣
整理有:
I
l
e
f
t
≤
∫
0
1
L
⋅
θ
⋅
∣
∣
y
−
x
∣
∣
2
d
θ
\mathcal I_{left} \leq \int_0^1 \mathcal L \cdot \theta \cdot ||y - x||^2 d\theta
Ileft≤∫01L⋅θ⋅∣∣y−x∣∣2dθ
又因为
L
,
∣
∣
y
−
x
∣
∣
2
\mathcal L,||y - x||^2
L,∣∣y−x∣∣2与
θ
\theta
θ无关,因而从积分号中提出:
I
l
e
f
t
≤
L
⋅
∣
∣
y
−
x
∣
∣
2
⋅
∫
0
1
θ
d
θ
=
L
⋅
∣
∣
y
−
x
∣
∣
2
⋅
1
2
θ
2
∣
0
1
=
L
2
⋅
∣
∣
y
−
x
∣
∣
2
=
I
r
i
g
h
t
\begin{aligned} \mathcal I_{left} & \leq \mathcal L \cdot ||y - x||^2 \cdot \int_0^1 \theta d\theta \\ & = \mathcal L \cdot ||y - x||^2 \cdot \frac{1}{2} \theta^2|_0^1 \\ & = \frac{\mathcal L}{2} \cdot ||y - x||^2 \\ & = \mathcal I_{right} \end{aligned}
Ileft≤L⋅∣∣y−x∣∣2⋅∫01θdθ=L⋅∣∣y−x∣∣2⋅21θ2∣01=2L⋅∣∣y−x∣∣2=Iright
证毕。
相关参考:
【优化算法】梯度下降法-二次上界