文章目录
- DenseNet结构
- Dense Layer & Dense Block
- Dense Layer的宽度
- Transition Layers
- 对比实验
- 网络结构
- 训练参数
- 对比结果
- CIFAR-10,CIFAR-100,SVHN
- ImageNet数据集
- 进一步分析
从ResNet开始,有很多研究都是琢磨怎么通过提高深度网络中层与层之间的信息传递(包括正向和反向传播)来解决梯度消失的问题。
ResNet是通过增加一个Short Connection的恒等映射来传递数据,并将这个数据与卷积层输出的残差相加来作为下一层的输入。
Stochasic Depth方法就是通过在反向传播中(训练过程)随机的丢掉一些层来提供训练时的梯度。
DenseNet提出了一个新的思路:把每一层的输出,特别是浅层网络的输出做一个连接到后面所有的层,这样来保证有效的利用前面层的有效信息(因为前面层毕竟没有那么多的信息丢失)。而且不是同通过相加,而是通过featrue map的叠加方式进行。这种方式叫做featrue reuse。
论文名称:Densely Connected Convolutional Networks
代码在:https://github.com/liuzhuang13/DenseNet
DenseNet结构
Dense Layer & Dense Block
DenseNet的设计当然不是简单的把每一个卷积层的输出直接拼接叠加到后面的所有卷积层上。
因为如果是这样的话,那么连接数有点过多了,按照上面的说法,每一层的输出都要输出到后面的每一层的话,连接数就有
L
(
L
−
1
)
2
\frac{L(L-1)}{2}
2L(L−1)
这么多层,如果是101层的ResNet的话,相当于这里的连接数就有5000个,参数是一个非常大的数字。而且最后一层的Featrue map也是一个非常夸张的数字,对显存的占用也不太符合实际。
-
在DenseNet中,把一个BN-ReLU-Conv(3 * 3)的一个基本单位做为一个层,叫做Dense Layer。
在论文中的描述是:
ResNet中一个layer对上一层的输出的处理函数描述为:
x l = H ( x l − 1 ) + x l − 1 x_l = H(x_{l-1}) + x_{l-1} xl=H(xl−1)+xl−1H ( x ) H(x) H(x)函数就是ResNet中的残差结构。在DenseNet中没有这个结构,是直接把所有的前面层的输出都作为输入来处理,而且没有了恒等映射的部分:
x l = H ( [ x 0 , x 1 . . . x l − 1 ] ) x_l = H([x_0, x_1 ... x_{l-1}]) xl=H([x0,x1...xl−1])- 上面的公式表明是把所有的前面层的输入做了一个叠加,增加的是featrue map的通道数。
- H函数代表的操作就是BN+ReLU+Conv(3 * 3)
-
和ResNet类似的,也可以把上面的结构换成Bottleneck结构,就是加了1 * 1卷积核的。但是这里的形式是:BN-ReLU-Conv(1×1)-BN-ReLU-Conv(3×3),没有最后的一个1 * 1了,没有做通道数的恢复。
-
然后在Dense Layer的基础上,设置了一个叫做Dense Block的结构,这个结构包含了 k k k个layer。在这个block里,每个层的输出就会连接到后面所有的层去。
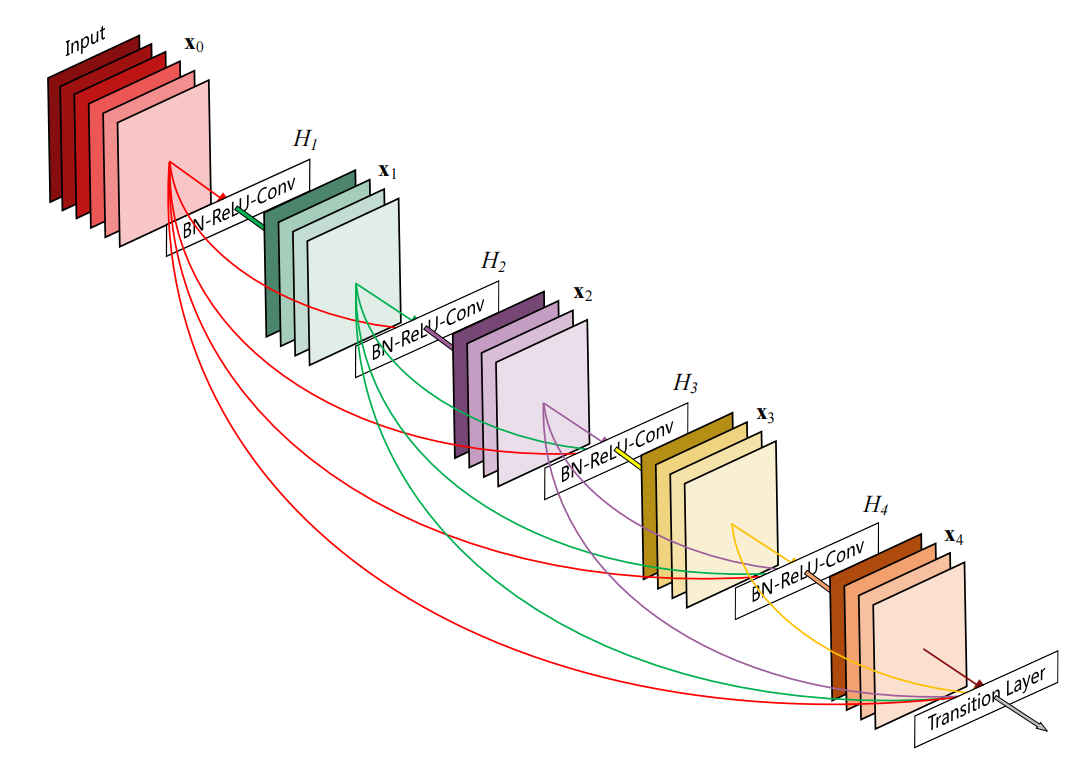
- 也就是说,这种跨层的连接一般都限制在block中。
- block中的卷积层需要保证output的w, h, channels相同,这样才能直接进行叠加(python里的append操作)
Dense Layer的宽度
与ResNet相比,DenseNet的一个关键区别是DenseNet是一个非常“窄”的网络。像ResNet可以看到不管是5 * 5,还是3 * 3的卷积层,卷积层的宽度,也就是卷积层的通道数都是比较大,比如32,64或则会128,还有更宽的网络。
我之前也写过,我理解是为了能提取更多特征。
而在DenseNet里,这个宽度可以是 k = 12 k=12 k=12,这个 k k k在论文里被称为growth rate(作为网络的超参数)。可以看出DenseNet的宽度比其他网络要窄的多,而且整个网络都是这个宽度。
其实也很好理解,DenseNet是把所有层的featrue map都整合到一起了,就不需要弄一个这么宽的卷积去提取卷积特征了。
论文中的原文是: One explanation for this is that each layer has access to all the preceding feature-maps in its block and, therefore, to the network’s “collective knowledge”. One can view the feature-maps as the global state of the network. Each layer adds k feature-maps of its own to this state. The growth rate regulates how much new information each layer contributes to the global state. The global state, once written, can be accessed from everywhere within the network and, unlike in traditional network architectures, there is no need to replicate it from layer to layer.
大意呢就是每个layer都可以提供k个featrue map到整个网络中(global state of network,而且没增加一层就增加k个特征,所以这个也被称作为growth rate的原因吧)。这个k也就是每个层对整个网络的贡献。
Transition Layers
上面提到了DenseNet中的基本结构DenseBlock,那么block与block之间就是通过一个叫做Transition Layer来进行拼接。
- 每个Block的输出可以有不同的尺寸,所以这个层由降维的1 * 1卷积核与下采样的pooling层组成。
- 论文上提出的是:consist of a batch normalization layer and an 1×1 convolutional layer followed by a 2×2 average pooling layer。也就是BN + 1 * 1卷积 + 2 * 2的平均池化层组成。

- 论文中还提到了可以在Transition Layer做一个通道数的降维操作——Compression,就是通过上一条提到的1 * 1卷积核的作用。只是说这个降维的操作是通过一个参数 θ \theta θ来控制的,这个 θ \theta θ的取值范围是: 0 < θ ≤ 1 0 < \theta \leq 1 0<θ≤1。
- 使用 θ < 1 \theta < 1 θ<1的网络结构计作DenseNet-C。在论文中是令 θ = 0.5 \theta = 0.5 θ=0.5。
- 再加上Bottleneck的话,就是后面提到的DenseNet-BC。
对比实验
对比实验主要基于CIFAR-10,CIFAR-100,SVHN,ImageNet四个数据集。
网络结构
-
CIFAR-10,CIFAR-100,SVHN这三个数据集用的是一种结构,采用三个Dense Block,每个Block都是使用相同数量的Dense Layer,论文里没有提到具体的数量,但是从代码里可以看出是三个16层的Dense Block。
-
通过三个Block中间的Transition layer(每个都带了2 * 2的平均池化层),所以三个层中的featrue map就是32 * 32, 16 * 16, 8 * 8。
-
基于普通DenseNet(没有Bottleneck和Compression)的使用了三种结构:{L = 40, k = 12}, {L = 100, k = 12} and {L = 100, k = 24},L为上面提到的Dense Layer,下同。
-
基于上文提到的DenseNet-BC的组建使用了三种结构:{L = 100, k = 12}, {L= 250, k= 24} and {L= 190, k= 40}
-
输入为224 * 224的图像。
-
-
ImageNet的数据集的结构和上面的不同,列在下表中:
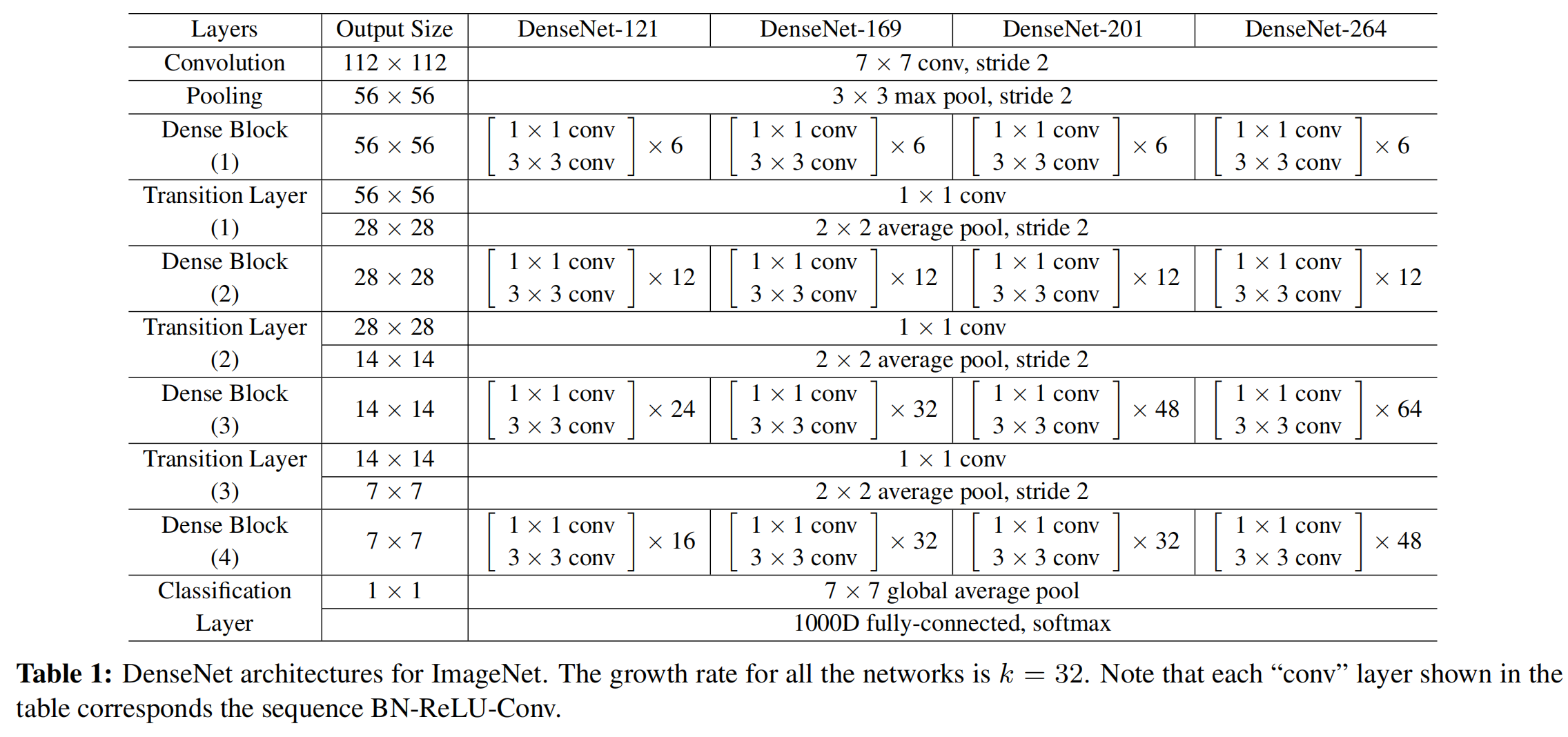
- 比起前面三种简单一点的数据集,增加了一个Block。层数和宽度(growth rate)都有所增加。
训练参数
-
CIFAR-10,CIFAR-100,SVHN数据集的 batch_size = 64; epoch = 300
- 前一半的学习率为0.1 50%-75%为0.01,最后的25%为0.001
- 在除了第一个卷积层后面都增加了一个dropout层。
-
ImageNet数据集的 batch_size = 256; epoch = 90
- 前30个epoch是0.1,满30次就为前面的十分之一
-
做了内存优化,参考论文Memory-efficient implementation of densenets,回头有时间再写写这个。
对比结果
CIFAR-10,CIFAR-100,SVHN
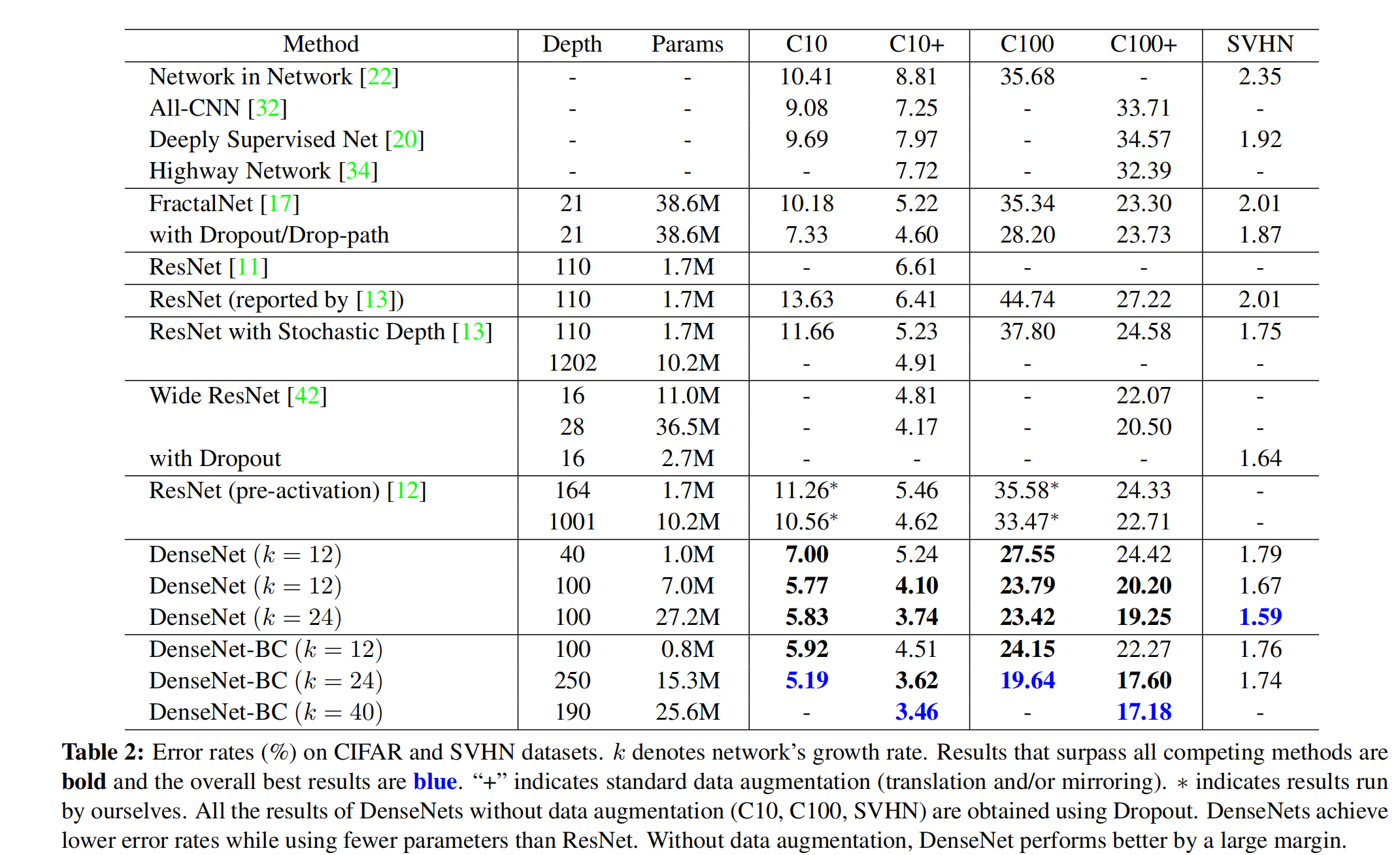
这三个数据集的测试错误率对比结果 如下:
-
带“+”号的数据集表示做了增强处理(增加数据多样性,使用translation and/or mirroring等预处理操作)
-
最下面的一行表示使用DenseNet-BC结构,L=190,k=40可以达到当时的最好的结果。
-
在SVHN数据集上,250层比100层没有太大的提高,和之前的类似,因为SVHN数据集比较简单,没必要用这么深的网络。
-
在CIFAR的两个数据集增强数据集(带+号)上,没有引入Bottleneck和Compression的网络是随着L和k的增加,准确率逐步提高。
- k越大,网络的表达能力越强,就是提取了更多的特征
- k增大,L增大,没有陷入过拟合。
-
使用DenseNet-BC结构可以有效的节省参数量
- DenseNet-BC with L = 100 and k = 12可以达到比ResNet(1001层)更好的准确率,但是参数要少得多,只有十分之一。并且还可以有效的解决梯度消失的问题,在训练过程中的loss一直维持的还可以。
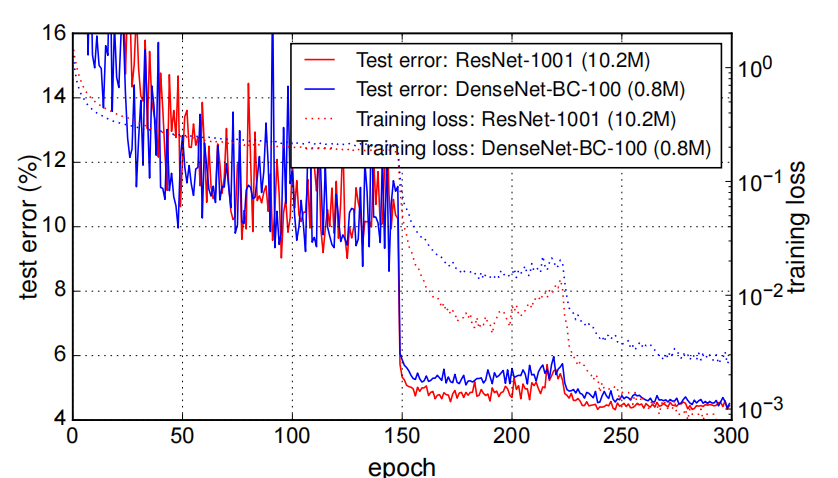
- DenseNet-BC比普通的DenseNet更好的避免过拟合。
ImageNet数据集
使用single-crop(选择其中的Center Crop)和10-crop(一般是取(左上,左下,右上,右下,正中)各5个Crop,以及它们的水平镜像,共10个Crops)的方式获取测试图像。
比对结果如下:
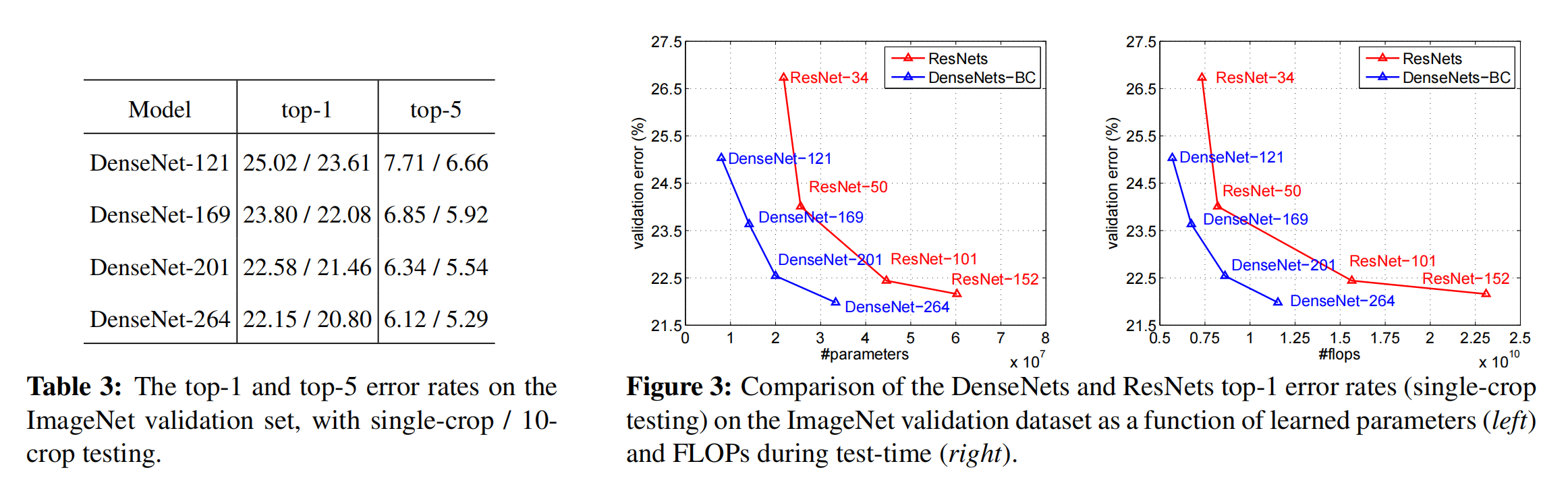
- 相当于DenseNet出了4组选手,121-169-201-264。ResNet也出了4组选手,34-50-101-152。
- 右边的那两幅图,左边的是错误率与参数量的关系,一副是错误率与运算量(FLOPs)的关系,再配合左边的表格,基本可以得到:
- 相同的错误率下,Dense Net的参数量更小,运算量更小
- 参数量相同的情况下,Dense Net的准确率更高。
进一步分析
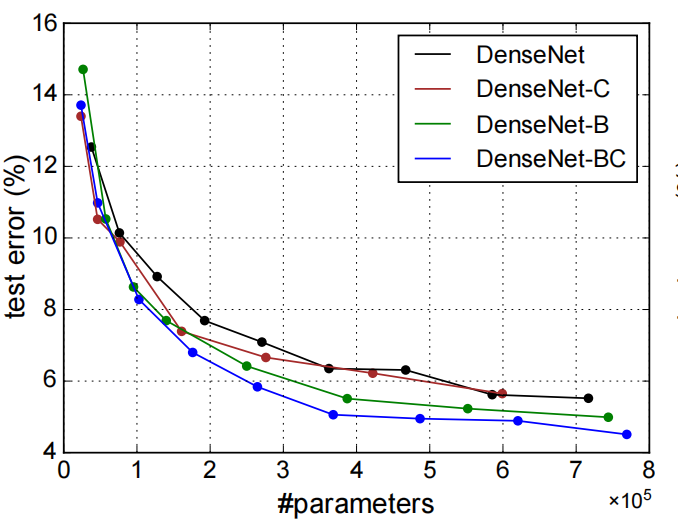
- 比对了DenseNet,DenseNet-B(加bottleneck),DenseNet-C(加Compression),DenseNet-BC(两者都加)的情况,得到说是DenseNet-BC效果最好,使用同样的参数量,得到的准确率最高。
-
对DenseNet效果好的一个解释,论文中提出了是说做到了Deep Supervision,深层次的监督。 原味为:a single classifier on top of the network provides direct supervision to all layers through at most two or three transition layers. However, the loss function and gradient of DenseNets are substantially less complicated, as the same loss function is shared between all layers.
我理解大意就是说,在整个网络输出层得到的loss值(这个是最直接和准确的损失和梯度)可以通过Dense connection直接传播到各个层(中间只需要经过2-3个transition layer,因为每个block是通过transition layer连接的),所以是所有层基本上都可以准确的得到和计算损失值来更新权重。
-
另一个针对ResNet的优化是stochastic depth,在训练的时候随机的丢掉一些residual block。论文描述是说:lts in a similar connectivity pattern as DenseNet: there is a small probability for any two layers, between the same pooling layers, to be directly connected if all intermediate layers are randomly dropped. Although the methods are ultimately quite different, the DenseNet interpretation of stochastic depth may provide insights into the success of this regularizer.
大致意思就是说从统计学上来看,每两个block之间可能会直接相连(中间的blcok被drop掉),所以损失和梯度也可以在训练的时候直接传递到各个层,所以逻辑上是和DenseNet达到同样的效果,所谓的殊途同归。
-
论文中还做了一个热点图,热点图中的每个点表示了某个层 l l l对之前所有的层 s s s之间的依赖程度(average absolute filter weights),也就是前面某个层的权重在后面的计算中起到多大的作用。三个block分开统计
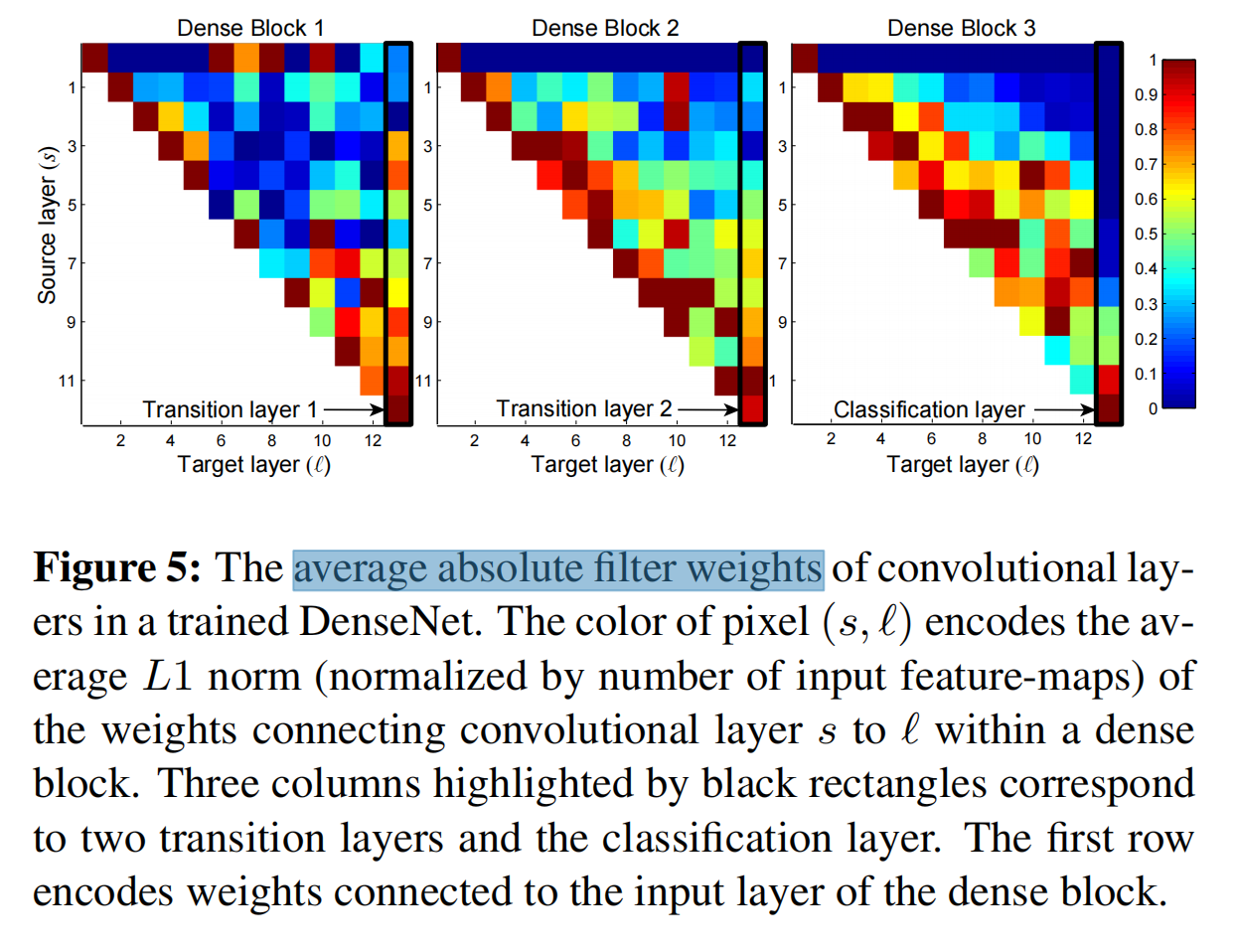
- 所有的层都起了作用。
- transition layer没有阻碍信息的传播。
- 从第二个block开始,前面的层对后面就没有太多的帮助了。论文的解释是transition layer输出了太多的冗余特征,没什么太多用,所以Compression是有效的:能有效的减少这些没用的东西。The layers within the second and third dense block consistently assign the least weight to the outputs of the transition layer (the top row of the triangles), indicating that the transition layer outputs many redundant features (with low weight on average). This is in keeping with the strong results of DenseNet-BC where exactly these outputs are compressed.