awk把每行内容称之为记录,而使用特殊字符分割之后的字符串称为 字段。
字段的引用
echo 'a : 1 : good ::::' >> awktest.txt
echo 'b : 2 : well ::::' >> awktest.txt
echo 'c : 3 : food ::::' >> awktest.txt
echo 'd : 4 : hood ::::' >> awktest.txt
echo 'e : 5 : bell ::::' >> awktest.txt
echo 'o : 6 : toll ::::' >> awktest.txt
echo '1 : a : good : h :::' >> awktest.txt
echo '2 : b : well : say :::' >> awktest.txt
echo '3 : c : food : gold :::' >> awktest.txt
把下边的内容:
a : 1 : good ::::
b : 2 : well ::::
c : 3 : food ::::
d : 4 : hood ::::
e : 5 : bell ::::
o : 6 : toll ::::
1 : a : good : h :::
2 : b : well : say :::
3 : c : food : gold :::
写入到awktest.txt里边。
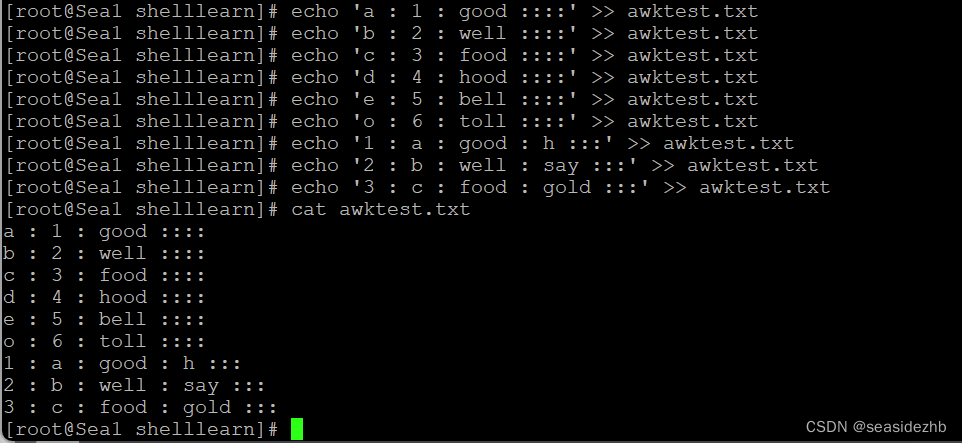
awk默认以空格为字段分隔符(列分割符)来进行字段分离。字段分离就是指把记录拆分字段。awk '{ print $6}' awktest.txt会把每行第六个字段输出到屏幕上。
还可以
awk 'pattern { action }
pattern { action }
pattern { action }' file
操作输出。
awk '/^a/{ print $6}
/^3/{print $7}' awktest.txt
可以先输出以a开头的记录中第六个字段,然后输出以3开头的记录中第七个字段,这里使用了正则表达式。

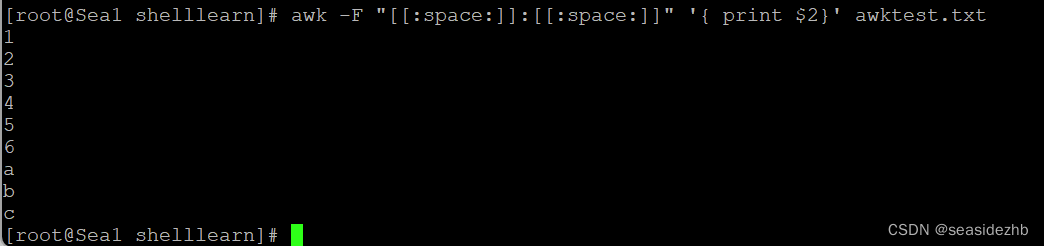
可以使用-F选项来修改字段分隔符。[[:space:]]是一个空格,awk -F "[[:space:]]:[[:space:]]" '{ print $2}' awktest.txt就能以空格+:+空格作为字段分割符,然后输出每个记录中第二个字段。
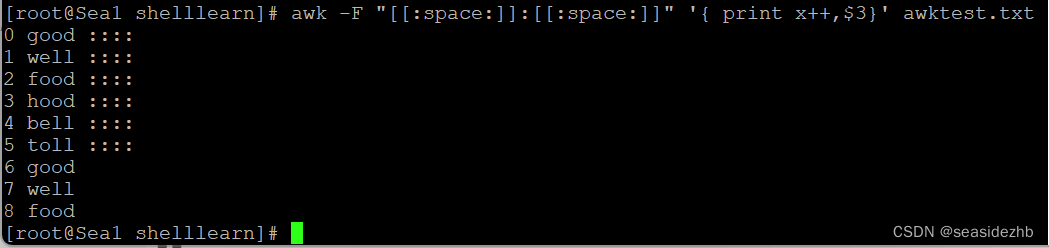
还可以使用变量来记录行号,awk -F "[[:space:]]:[[:space:]]" '{ print x++,$3}' awktest.txt就能以空格+:+空格作为字段分割符,然后输出每个记录中第三个字段,把行号减1写在前边。
此文章为8月Day 8学习笔记,内容来源于极客时间《Linux 实战技能 100 讲》。