环境描述
环境是倒立摆(Inverted Pendulum),该环境下有一个处于随机位置的倒立摆。环境的状态包括倒立摆角度的正弦值,余弦值,角速度;动作为对倒立摆施加的力矩(action = Box(-2.0, 2.0, (1,), float32))。每一步都会根据当前倒立摆的状态的好坏给予智能体不同的奖励,该环境的奖励函数为,倒立摆向上保持直立不动时奖励为 0,倒立摆在其他位置时奖励为负数。环境本身没有终止状态,所以训练的时候需要设置终止条件(笔者在本文设置了260)。
一、构建智能体
构建智能体:
policy是和之前一样的。探索和利用, 就是利用的时候基于nn模型的预测
主要核心:
- QNet:
- 就是一个多层的NN
- update就是用MSELoss进行梯度下降
DQN:支持DQN和doubleDQN- update:
- 经验回放池R中的数据足够, 从R中采样N个数据
{ (si, ai, ri, si+1) }+i=1,...,N - 对于DQN: 对每个数据计算 y i = r i + γ Q w − ( s ′ , a r g m a x ( Q w − ( s ′ , a ′ ) ) y_i = r_i + \gamma Q_{w^-}(s',arg max(Q_{w^-}(s', a')) yi=ri+γQw−(s′,argmax(Qw−(s′,a′)) ,动作的选取依靠目标网络( Q w − Q_{w-} Qw−)
- 对于doubleDQN: 对每个数据计算
y
i
=
r
i
+
γ
Q
w
−
(
s
′
,
a
r
g
m
a
x
(
Q
w
(
s
′
,
a
′
)
)
y_i = r_i + \gamma Q_{w^-}(s',arg max(Q_{w}(s', a'))
yi=ri+γQw−(s′,argmax(Qw(s′,a′)) ,动作的选取依靠训练网络(
Q
w
Q_w
Qw)
-
f
m
a
x
f_{max}
fmax就是用
Q
N
e
t
(
s
i
+
1
)
QNet(s_{i+1})
QNet(si+1)计算出每个action对应的值,取最大值的index, 然后根据这个index去
T
a
g
e
t
Q
N
e
t
(
s
i
+
1
)
TagetQNet(s_{i+1})
TagetQNet(si+1)中取最大值
下面的代码可以看出差异
-
f
m
a
x
f_{max}
fmax就是用
Q
N
e
t
(
s
i
+
1
)
QNet(s_{i+1})
QNet(si+1)计算出每个action对应的值,取最大值的index, 然后根据这个index去
T
a
g
e
t
Q
N
e
t
(
s
i
+
1
)
TagetQNet(s_{i+1})
TagetQNet(si+1)中取最大值
- 经验回放池R中的数据足够, 从R中采样N个数据
- update:
# 下个状态的最大Q值
if self.dqn_type == 'DoubleDQN': # DQN与Double DQN的区别
max_action = self.q(next_states).max(1)[1].view(-1, 1)
max_next_q_values = n_actions_q.gather(1, max_action)
else: # DQN的情况
max_next_q_values = n_actions_q.max(1)[0].view(-1, 1)
q_targets = reward + self.gamma * max_next_q_values * (1 - done)
- 最小化目标函数
L
=
1
N
∑
(
y
i
−
Q
N
e
t
(
s
i
,
a
i
)
)
2
L=\frac{1}{N}\sum (yi - QNet(s_i, a_i))^2
L=N1∑(yi−QNet(si,ai))2
- 用
y
i
y_i
yi 和
q(states).gather(1, action)计算损失并更新参数
- 用
y
i
y_i
yi 和
代码实现
class QNet(nn.Module):
def __init__(self, state_dim: int, hidden_layers_dim: typ.List, action_dim: int):
super(QNet, self).__init__()
self.features = nn.ModuleList()
for idx, h in enumerate(hidden_layers_dim):
self.features.append(
nn.ModuleDict({
'linear': nn.Linear(state_dim if not idx else hidden_layers_dim[idx-1], h),
'linear_active': nn.ReLU(inplace=True)
})
)
self.header = nn.Linear(hidden_layers_dim[-1], action_dim)
def forward(self, x):
for layer in self.features:
x = layer['linear_active'](layer['linear'](x))
return self.header(x)
def model_compelet(self, learning_rate):
self.cost_func = nn.MSELoss()
self.opt = torch.optim.Adam(self.parameters(), lr=learning_rate)
def update(self, pred, target):
self.opt.zero_grad()
loss = self.cost_func(pred, target)
loss.backward()
self.opt.step()
class DQN:
def __init__(self,
state_dim: int,
hidden_layers_dim,
action_dim: int,
learning_rate: float,
gamma: float,
epsilon: float=0.05,
traget_update_freq: int=1,
device: typ.AnyStr='cpu',
dqn_type: typ.AnyStr='DQN'
):
self.action_dim = action_dim
# QNet & targetQNet
self.q = QNet(state_dim, hidden_layers_dim, action_dim)
self.target_q = copy.deepcopy(self.q)
self.q.to(device)
self.q.model_compelet(learning_rate)
self.target_q.to(device)
# iteration params
self.learning_rate = learning_rate
self.gamma = gamma
self.epsilon = epsilon
# target update freq
self.traget_update_freq = traget_update_freq
self.count = 0
self.device = device
# dqn类型
self.dqn_type = dqn_type
def policy(self, state):
if np.random.random() < self.epsilon:
return np.random.randint(self.action_dim)
action = self.target_q(torch.FloatTensor(state))
return np.argmax(action.detach().numpy())
def update(self, samples: deque):
"""
Q<s, a, t> = R<s, a, t> + gamma * Q<s+1, a_max, t+1>
"""
self.count += 1
state, action, reward, next_state, done = zip(*samples)
states = torch.FloatTensor(state).to(self.device)
action = torch.tensor(action).view(-1, 1).to(self.device)
reward = torch.tensor(reward).view(-1, 1).to(self.device)
next_states = torch.FloatTensor(next_state)
done = torch.FloatTensor(done).view(-1, 1).to(self.device)
actions_q = self.q(states)
n_actions_q = self.target_q(next_states)
q_values = actions_q.gather(1, action)
# 下个状态的最大Q值
if self.dqn_type == 'DoubleDQN': # DQN与Double DQN的区别
max_action = self.q(next_states).max(1)[1].view(-1, 1)
max_next_q_values = n_actions_q.gather(1, max_action)
else: # DQN的情况
max_next_q_values = n_actions_q.max(1)[0].view(-1, 1)
q_targets = reward + self.gamma * max_next_q_values * (1 - done)
# MSELoss update
self.q.update(q_values.float(), q_targets.float())
if self.count % self.traget_update_freq == 0:
self.target_q.load_state_dict(
self.q.state_dict()
)
二、智能体训练
2.1 注意点
在训练的时候:
- 所有的参数都在
Config中进行配置,便于调参
class Config:
num_episode = 300
state_dim = None
hidden_layers_dim = [10, 10]
action_dim = 20
learning_rate = 2e-3
gamma = 0.95
epsilon = 0.01
traget_update_freq = 3
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
buffer_size = 2048
minimal_size = 1024
batch_size = 128
render = False
save_path = r'D:\TMP\model.ckpt'
dqn_type = 'DoubleDQN'
# 回合停止控制
max_episode_rewards = 260
max_episode_steps = 260
def __init__(self, env):
self.state_dim = env.observation_space.shape[0]
try:
self.action_dim = env.action_space.n
except Exception as e:
pass
print(f'device = {self.device} | env={str(env)}')
- 由于这次环境的action空间是连续的,我们需要有一个函数进行action的离散和连续的转换
def Pendulum_dis_to_con(discrete_action, env, action_dim): # 离散动作转回连续的函数
action_lowbound = env.action_space.low[0] # 连续动作的最小值
action_upbound = env.action_space.high[0] # 连续动作的最大值
action_range = action_upbound - action_lowbound
return action_lowbound + (discrete_action / (action_dim - 1)) * action_range
2.2 训练
需要注意的是笔者的gym版本是0.26.2
def train_dqn(env, cfg, action_contiguous=False):
buffer = replayBuffer(cfg.buffer_size)
dqn = DQN(
state_dim=cfg.state_dim,
hidden_layers_dim=cfg.hidden_layers_dim,
action_dim=cfg.action_dim,
learning_rate=cfg.learning_rate,
gamma=cfg.gamma,
epsilon=cfg.epsilon,
traget_update_freq=cfg.traget_update_freq,
device=cfg.device,
dqn_type=cfg.dqn_type
)
tq_bar = tqdm(range(cfg.num_episode))
rewards_list = []
now_reward = 0
bf_reward = -np.inf
for i in tq_bar:
tq_bar.set_description(f'Episode [ {i+1} / {cfg.num_episode} ]')
s, _ = env.reset()
done = False
episode_rewards = 0
steps = 0
while not done:
a = dqn.policy(s)
# [Any, float, bool, bool, dict]
if action_contiguous:
c_a = Pendulum_dis_to_con(a, env, cfg.action_dim)
n_s, r, done, _, _ = env.step([c_a])
else:
n_s, r, done, _, _ = env.step(a)
buffer.add(s, a, r, n_s, done)
s = n_s
episode_rewards += r
steps += 1
# buffer update
if len(buffer) > cfg.minimal_size:
samples = buffer.sample(cfg.batch_size)
dqn.update(samples)
if (episode_rewards >= cfg.max_episode_rewards) or (steps >= cfg.max_episode_steps):
break
rewards_list.append(episode_rewards)
now_reward = np.mean(rewards_list[-10:])
if bf_reward < now_reward:
torch.save(dqn.target_q.state_dict(), cfg.save_path)
bf_reward = max(bf_reward, now_reward)
tq_bar.set_postfix({'lastMeanRewards': f'{now_reward:.2f}', 'BEST': f'{bf_reward:.2f}'})
env.close()
return dqn
if __name__ == '__main__':
print('=='*35)
print('Training Pendulum-v1')
p_env = gym.make('Pendulum-v1')
p_cfg = Config(p_env)
p_dqn = train_dqn(p_env, p_cfg, True)
三、训练出的智能体观测
最后将训练的最好的网络拿出来进行观察
p_dqn.target_q.load_state_dict(torch.load(p_cfg.save_path))
play(gym.make('Pendulum-v1', render_mode="human"), p_dqn, p_cfg, episode_count=2, action_contiguous=True)
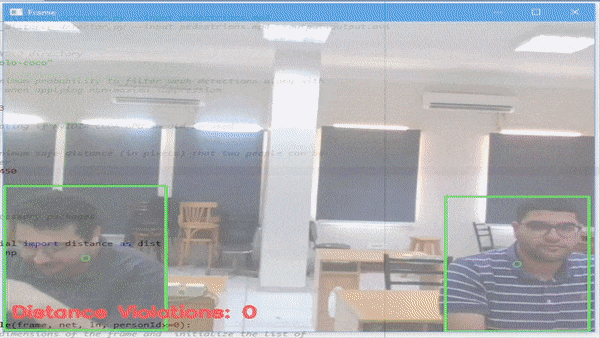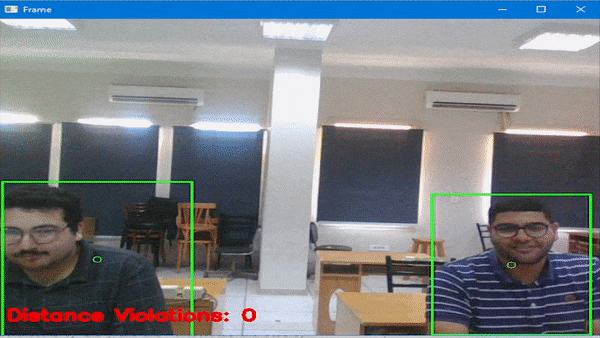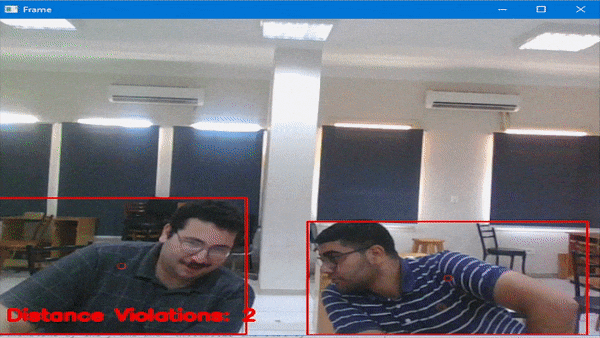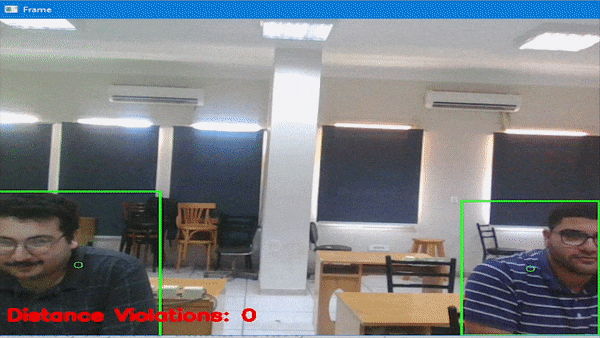
从下图中我们可以看出,本次的训练成功还是可以的。

完整脚本查看笔者github: Doubledqn_lr.py 记得点
Star哦
笔者后续会更深入的学习强化学习并对gym各个环境逐一进行训练







![[ Linux ] 一篇带你理解Linux下线程概念](https://img-blog.csdnimg.cn/img_convert/83909507702c18c57defc37117c5b017.png)