📋📋📋本文目录如下:⛳️⛳️⛳️
目录
1 概述
2 Matlab代码实现
3 写在最后
1 概述
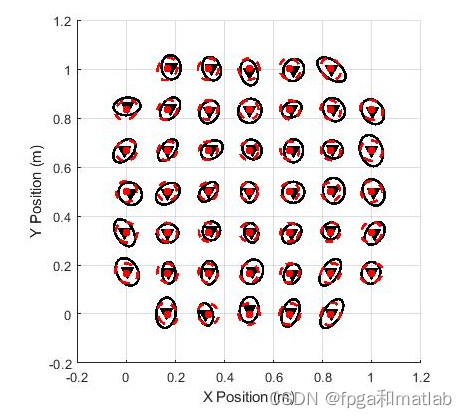
动态规划是一种机器学习方法,它利用环境、计算资源和马尔可夫特性等知识来创建在环境中最佳执行的策略。有了这项强大的技术,一个看似复杂的问题就可以用几行代码来分析和解决。在本文告中,介绍了使用基于Matlab的动态程序解决多队列网络问题的整个过程。基于所得结果,最后得出结论,具有策略迭代的动态规划是解决该类问题有效方法。
2 Matlab代码实现
部分代码:
clear all ,
clc
state2state = zeros ( 9 , 9 , 9 , 9 )
rewardfor1 = zeros ( 9 , 9 , 9 , 9 )
rewardfor2 = zeros ( 9 , 9 , 9 , 9 )
policy = zeros ( 9 , 9 )
values = zeros ( 9 , 9 )
none= .7 * .4
just1= .3 * .4
just2= .6 * .7
both= .6 * .3
for i = 1 : 9
for j = 1 : 9
state2state = applyProb(state2state, i , j );
end
end
stateDone = 1
for i = 1 : 9
for j = 1 : 9
rewardfor1 = applyReward(rewardfor1, i , j , 1 );
end
end
reward1Done = 1
for i = 1 : 9
for j = 1 : 9
rewardfor2 = applyReward(rewardfor2, i , j , 2 );
end
end
%randomize policy
for i = 1 : 9
for j = 1 : 9
policy( i , j ) = 1 ;
%policy(i,j) = binornd(1,.5) + 1;
end
end
reward2Done = 1
setupDone = 1
%policyIteration.m
run setup.m
iterating = 1
total = 0 ;
while iterating == 1
total=total + 1
%evaluation
evaluating = 1
while evaluating == 1
theta = 0.001 ;
delta = 0 ;
discount = .4 ;
for q2 = 1 : 9
for q1 = 1 : 9
v = values(q2,q1);
sumOfValues = 0 ;
for nextq2 = 1 : 9
for nextq1 = 1 : 9
myProb = tranP(q1 - 1 ,q2 - 1 ,policy(q2,q1),nextq1 - 1 ,nextq2 - 1 ,state2state);
myReward = tranR(q1 - 1 ,q2 - 1 ,policy(q2,q1),nextq1 - 1 ,nextq2 - 1 ,rewardfor1,rewardfor2);
myNextVal = values(nextq2,nextq1);
sumOfValues = sumOfValues + myProb * (myReward + discount * myNextVal);
end
end
values(q2,q1) = sumOfValues;
delta = max (delta, abs (v - values(q2,q1)))
end
end
if (delta < theta)
evaluating = 0 ;
end
end
%improvment
policyStable = 1
for q2 = 1 : 9
for q1 = 1 : 9
b = policy(q2,q1);
action1sumOfValues = 0 ;
action2sumOfValues = 0 ;
for nextq2 = 1 : 9
for nextq1 = 1 : 9
myProb = tranP(q1 - 1 ,q2 - 1 , 1 ,nextq1 - 1 ,nextq2 - 1 ,state2state);
myReward = tranR(q1 - 1 ,q2 - 1 , 1 ,nextq1 - 1 ,nextq2 - 1 ,rewardfor1,rewardfor2);
myNextVal = values(nextq2,nextq1);
action1sumOfValues = action1sumOfValues + myProb * (myReward + discount * myNextVal);
end
end
for nextq2 = 1 : 9
for nextq1 = 1 : 9
myProb = tranP(q1 - 1 ,q2 - 1 , 2 ,nextq1 - 1 ,nextq2 - 1 ,state2state);
myReward = tranR(q1 - 1 ,q2 - 1 , 2 ,nextq1 - 1 ,nextq2 - 1 ,rewardfor1,rewardfor2);
myNextVal = values(nextq2,nextq1);
action2sumOfValues = action2sumOfValues + myProb * (myReward + discount * myNextVal);
end
end
if (action1sumOfValues > action2sumOfValues)
policy(q2,q1) = 1 ;
elseif (action2sumOfValues >=action1sumOfValues)
policy(q2,q1) = 2 ;
end
if (b ~= policy(q2,q1))
policyStable = 0 ;
end
end
end
if (policyStable == 1 )
iterating = 0
end
end
clear all ,
clc
state2state = zeros ( 9 , 9 , 9 , 9 )
rewardfor1 = zeros ( 9 , 9 , 9 , 9 )
rewardfor2 = zeros ( 9 , 9 , 9 , 9 )
policy = zeros ( 9 , 9 )
values = zeros ( 9 , 9 )
none= .7 * .4
just1= .3 * .4
just2= .6 * .7
both= .6 * .3
for i = 1 : 9
for j = 1 : 9
state2state = applyProb(state2state, i , j );
end
end
stateDone = 1
for i = 1 : 9
for j = 1 : 9
rewardfor1 = applyReward(rewardfor1, i , j , 1 );
end
end
reward1Done = 1
for i = 1 : 9
for j = 1 : 9
rewardfor2 = applyReward(rewardfor2, i , j , 2 );
end
end
%randomize policy
for i = 1 : 9
for j = 1 : 9
policy( i , j ) = 1 ;
%policy(i,j) = binornd(1,.5) + 1;
end
end
reward2Done = 1
setupDone = 1
%policyIteration.m
run setup.m
iterating = 1
total = 0 ;
while iterating == 1
total=total + 1
%evaluation
evaluating = 1
while evaluating == 1
theta = 0.001 ;
delta = 0 ;
discount = .4 ;
for q2 = 1 : 9
for q1 = 1 : 9
v = values(q2,q1);
sumOfValues = 0 ;
for nextq2 = 1 : 9
for nextq1 = 1 : 9
myProb = tranP(q1 - 1 ,q2 - 1 ,policy(q2,q1),nextq1 - 1 ,nextq2 - 1 ,state2state);
myReward = tranR(q1 - 1 ,q2 - 1 ,policy(q2,q1),nextq1 - 1 ,nextq2 - 1 ,rewardfor1,rewardfor2);
myNextVal = values(nextq2,nextq1);
sumOfValues = sumOfValues + myProb * (myReward + discount * myNextVal);
end
end
values(q2,q1) = sumOfValues;
delta = max (delta, abs (v - values(q2,q1)))
end
end
if (delta < theta)
evaluating = 0 ;
end
end
%improvment
policyStable = 1
for q2 = 1 : 9
for q1 = 1 : 9
b = policy(q2,q1);
action1sumOfValues = 0 ;
action2sumOfValues = 0 ;
for nextq2 = 1 : 9
for nextq1 = 1 : 9
myProb = tranP(q1 - 1 ,q2 - 1 , 1 ,nextq1 - 1 ,nextq2 - 1 ,state2state);
myReward = tranR(q1 - 1 ,q2 - 1 , 1 ,nextq1 - 1 ,nextq2 - 1 ,rewardfor1,rewardfor2);
myNextVal = values(nextq2,nextq1);
action1sumOfValues = action1sumOfValues + myProb * (myReward + discount * myNextVal);
end
end
for nextq2 = 1 : 9
for nextq1 = 1 : 9
myProb = tranP(q1 - 1 ,q2 - 1 , 2 ,nextq1 - 1 ,nextq2 - 1 ,state2state);
myReward = tranR(q1 - 1 ,q2 - 1 , 2 ,nextq1 - 1 ,nextq2 - 1 ,rewardfor1,rewardfor2);
myNextVal = values(nextq2,nextq1);
action2sumOfValues = action2sumOfValues + myProb * (myReward + discount * myNextVal);
end
end
if (action1sumOfValues > action2sumOfValues)
policy(q2,q1) = 1 ;
elseif (action2sumOfValues >=action1sumOfValues)
policy(q2,q1) = 2 ;
end
if (b ~= policy(q2,q1))
policyStable = 0 ;
end
end
end
if (policyStable == 1 )
iterating = 0
end
endfunction [ matrix ] = applyProb ( matrix,row,col )
matrix(row,col,row,col) = .28
if (row < 9),
matrix(row + 1 ,col,row,col) = .42
else
end
if (col < 9),
matrix(row,col + 1 ,row,col) = .12
end
if (row < 9),
if (col < 9),
matrix(row + 1 ,col + 1 ,row,col) = .18
end
end
if (row == 9 & col == 9 )
matrix(row,col,row,col) = 1
end
if (row ~= 9 & col == 9 )
matrix(row + 1 , 9 ,row,col) = .42 + .18
matrix(row, 9 ,row,col) = .28 + .12
end
if (row == 9 & col ~= 9 )
matrix( 9 ,col + 1 ,row,col) = .12 + .18
matrix( 9 ,col,row,col) = .28 + .42
end
end
3 写在最后
部分理论引用网络文献,若有侵权请联系博主删除。








![[附源码]Node.js计算机毕业设计蛋糕店会员系统Express](https://img-blog.csdnimg.cn/53c9352ecab94b4b83ba9bb72270b06d.png)