Java阶段五Day18
文章目录
- Java阶段五Day18
- 缓存方案
- 面试题整理
- 项目功能
- 新增审核
- 业务流程图
- 账户
- 账户表格和ER图
- 账号服务功能
- 账号的创建
- 当前实现功能时序图(对应全景图)
- 抢单相关时序图
- 供应商和需求单
- 附录
- 布隆过滤器
缓存方案
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bFcLjafu-1691152268571)(E:/TeduWork/notes-2303/%25E8%25AF%25BE%25E5%25A0%2582%25E7%25AC%2594%25E8%25AE%25B0/Day18/assets/image-20230801090222363.png)]](https://img-blog.csdnimg.cn/552a6275b18e4b50a2120e966638a811.png)
面试题整理
目标:
- 整理相关问题的话术,碰到问题
思路: 概念 是什么 原因 为什么 解决方案 如何解决
-
缓存雪崩:
- 概念: 缓存在长期应用的系统中,存储了大量的高并发访问数据,一旦这些数据突然批量消失,访问吞吐的并发,到达数据库,导致数据库崩溃
- 原因:
- 大量数据超时时间固定,相同的
redis分片宕机(数据分布式)短时间造成雪崩,但是不会持续,也不会总是交给代码处理,因为高并发高吞吐的redis架构是cluster,保证集群高可用,数据的高可靠性
- 解决方案:
- 超时时间不要固定
- 第二种代码不提供解决方案,最多降级处理(不重要的数据降级)
-
缓存穿透:
- 概念: 缓存没有命中数据,同时数据库也没有命中数据,缓存穿透就出现了
- 原因:
- 故意造成,高并发请求,携带无效数据
- 错误,误差
- 解决方案:
- 错误误差: 通过日志,监控
- 故意: 引入过滤器(布隆过滤器),拦截根本不存在的数据.或者对于数据库查询为
null的(临时数据),也存储到缓存(redis可能会因为大量故意访问,出现大量null数据)
-
缓存击穿:
- 概念: 对于
cache-aside缓存方案中,命中返回缓存,没命中查询数据库.如果没命中的数据是热点数据(并发高,访问高)可能造成大量线程在缓存都没有命中数据,都到数据库查询数据 - 原因: 高并发访问热点数据,缓存方案
cache-aside造成的逻辑问题 - 解决方案: 分布式锁.
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-k66ymG52-1691152268572)(E:/TeduWork/notes-2303/%25E8%25AF%25BE%25E5%25A0%2582%25E7%25AC%2594%25E8%25AE%25B0/Day18/assets/image-20230801092300545.png)]](https://img-blog.csdnimg.cn/be3a2b8f2887419daa05ea6b0bd6559b.png)
穿透和击穿的区别:
- 穿透是缓存没有,数据库也没有,击穿缓存没有,但是数据库有
- 都是高并发造成的影响,穿透更多的情况是大量不同数据,击穿针对少量(相同)业务数据(热点)
- 概念: 对于
-
一致性
- 批量一致性
- 批量: 一次性处理大批数据
- 解决方案: 预热同步.同步刷新
- 增量一致性
- 增量: 一次处理1条,几条数据,相比于批量百万,千万级别数据量,非常小的数据量
- 批量一致性
-
增量一致性场景: redis存储200万数据,有一条数据存储了一个电脑的商品信息,后台对这个电脑数据做了变更,原价在数据库200元-500元.
redis和mysql同步改(写,先写谁,后写谁)- 先写
redis(200-500) 再写数据库(200-500)——问题数据库写失败 - 先写数据库(200-500)再写
redis(200-500)——处理事务问题
- 先写
redis先删,mysql写- 造成高并发下的数据不一致问题(因为
cache-aside缓存方案)
- 造成高并发下的数据不一致问题(因为
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7OzfJkj7-1691152268572)(E:/TeduWork/notes-2303/%25E8%25AF%25BE%25E5%25A0%2582%25E7%25AC%2594%25E8%25AE%25B0/Day18/assets/image-20230801093935104.png)]](https://img-blog.csdnimg.cn/24368912989d4774a6dc7ed8cc95e568.png)
- 采用双删(延迟双删)
延迟双删和双删的区别,就是第二次删除
redis的时候,是否要先等待1~3秒![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TsXtdYZM-1691152268573)(E:/TeduWork/notes-2303/%25E8%25AF%25BE%25E5%25A0%2582%25E7%25AC%2594%25E8%25AE%25B0/Day18/assets/image-20230801094155129.png)]](https://img-blog.csdnimg.cn/961d53f2045d4fb696676bcdbd612237.png)
项目功能
新增审核
业务流程图
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Tb7EQoQE-1691152268573)(E:/TeduWork/notes-2303/%25E8%25AF%25BE%25E5%25A0%2582%25E7%25AC%2594%25E8%25AE%25B0/Day18/assets/image-20230801101639854.png)]](https://img-blog.csdnimg.cn/3414fadec7af438fa3e63ed9eaa9a3a7.png)
账户
账户表格和ER图
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pQQq0jPD-1691152268574)(E:/TeduWork/notes-2303/%25E8%25AF%25BE%25E5%25A0%2582%25E7%25AC%2594%25E8%25AE%25B0/Day18/assets/image-20230801112055557.png)]](https://img-blog.csdnimg.cn/3f383673c0264a70b464cea4b3e566f6.png)
账号服务功能
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4O2cmEUc-1691152268574)(E:/TeduWork/notes-2303/%25E8%25AF%25BE%25E5%25A0%2582%25E7%25AC%2594%25E8%25AE%25B0/Day18/assets/image-20230801112722398.png)]](https://img-blog.csdnimg.cn/4fce86d2736d4887935608b52e25d28e.png)
账号的创建
- 什么时候调用账号创建? 审核通过创建
- 调用方式:
dubbo accountprovider角色 在account-server有对外暴露的接口adapter层 实现这个接口,并且server启动时,支持dubbo运行
账号dubbo远程调用,检查调整的内容
第一步: 确定角色 谁是provider(admin server) account-server 谁是consumer worker-admin
第二步: dubbo配置
- 依赖(当前在源代码基础上实现的配置,依赖一般不需要检查)
applicationContextdubbo:reference dubbo:service代替原来自动配的注解@DubboReference,@DubboService- 其他标签都对应的
yaml文件配置
provider提供实现(accountRpcService有没有添加@Service)consumer注入使用(@Autowired)
当前实现功能时序图(对应全景图)
https://sparrowzoo.feishu.cn/docx/My4mdlLuMovmQixHko4c6qXbnYc?from=from_copylink
抢单相关时序图
供应商和需求单
https://sparrowzoo.feishu.cn/docx/My4mdlLuMovmQixHko4c6qXbnYc?from=from_copylink
需求单是供应商通过远程调用提供的接口推送过来的
现在没有这个流程,在数据库直接准备可以抢的需求单
数据request_order表格 修改grab_status 抢单状态0 还没人抢 1 已经被抢了,version 0 1 表示版本(防止抢单多线程并发,导致抢单 多个师傅抢到一个订单)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-n4nN7rMv-1691152268575)(E:/TeduWork/notes-2303/%25E8%25AF%25BE%25E5%25A0%2582%25E7%25AC%2594%25E8%25AE%25B0/Day18/assets/image-20230801163439780.png)]](https://img-blog.csdnimg.cn/a0c4e855fdfd489280fbb2955e828b6e.png)
附录
布隆过滤器
布隆工作流程(filter)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HzgSLQh4-1691152268576)(E:/TeduWork/notes-2303/%25E8%25AF%25BE%25E5%25A0%2582%25E7%25AC%2594%25E8%25AE%25B0/Day18/assets/image-20230801090931138.png)]](https://img-blog.csdnimg.cn/7dd6b9baa51f4cc4835faed2088f7965.png)
布隆过滤器缺点
- 批量新增到布隆,也可以增量新增,不能删除(重新清空预热)
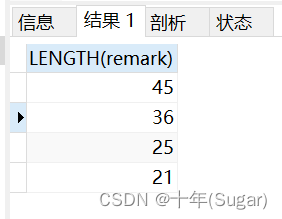
- 判断存在的概率,有可能误判的。比如100万条,判断100万条存在。200条实际是不存在的,即:误差
0.02%
![[每周一更]-(第57期):用Docker、Docker-compose部署一个完整的前后端go+vue分离项目](https://img-blog.csdnimg.cn/90f5bca6c1e94333b3ba2547fa98c70b.png#pic_center)