目录
- 概念
- 相关问题查看阿里云文档
- ClickHouse相关
- Clickhouse分布式表应用修改点
概念
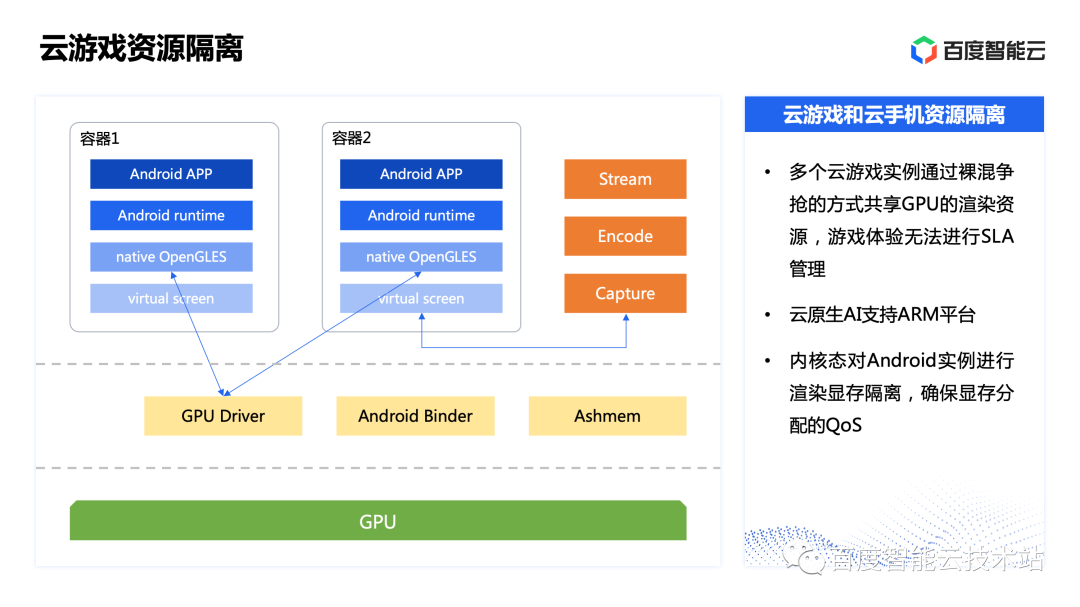
1.阿里云架构

2.节点
节点是逻辑概念,其架构也说明了集群默认包含1个或多个节点,或者说是分片(shard)
节点下包含一个或者多个服务器,具体包含几个,与购买的配置有关。
例如:单副本版:指的是节点中只有一个服务器,每个节点只有1个副本,该副本服务不可用时,会导致整个集群不可用,需要等待此副本完全恢复服务状态,集群才能继续提供稳定服务。
双副本版:每个节点包含两个副本,某个副本服务不可用的时候,同一分片的另一个副本还可以继续服务。
集群下包含节点(分片),节点下包含1个或者多个副本,或者说包含一个或多个服务器。
3.多分片多副本:需要购买双副本版,选择多个节点
4. 单分片多副本:需要购买双副本版,选择一个节点
5. 多分片1副本:需要购买单副本版,选择多个节点
相关问题查看阿里云文档
https://help.aliyun.com/document_detail/162815.html?spm=a2c4g.167447.0.0.bc531a2eSXY4yo
ClickHouse相关
Clickhouse分布式表应用修改点
分布式表创建
需要先建本地表
CREATE TABLE city_local on cluster default_cluster
(
`id` Int64,
`city_code` Int32,
`city_name` String,
`total_cnt` Int64,
`event_time` DateTime
)
Engine=ReplicatedMergeTree('/clickhouse/tables/{shard}/app/city_local', '{replica}')
PARTITION BY toYYYYMMDD(event_time)
ORDER BY id;
创建分布式表
CREATE TABLE city_all on cluster default_cluster
AS app.city_local
ENGINE = Distributed(default_cluster, app, city_local, rand());
rand()分片键可以用采用区分度较高的列的哈希值, 如sipHash64(id).
intHash64(toInt64(city_name))
表的操作
清空分布式表的数据,不会清空数据,只能通过清空本地表的方式来清空分布式表的数据
truncate table t_table_local on cluster default_cluster;
不会生效
truncate table t_table_distribute on cluster default_cluster;
drop分布式表
drop table t_table_distribure on cluster default_cluster;
修改本地表表名
修改本地表表名会更改本地系统的文件名称,但是不会更改zookeeper的路径名称,这块需要注意下。
新增分布式表的时候,只会在本地建一个空的目录,但是在zookeeper上面不会新增目录
所以可以通过rename本地表成本地表名加上local,然后建分布式表的时候直接用原先的本地表名就可以了。
SQL
RENAME TABLE test_name_local TO test_name_new on cluster default_cluster
修改表字段
修改本地表字段字段,分布式表会跟着改变吗?分布式表字段不会跟着改变,还需要修改分布式表的字段才可以
alter table t_table_local on cluster default_cluster drop column column_code
修改分布式表字段,本地表会跟着改变吗?修改分布式表的字段,本地表也不会跟着改变,还需要修改本地表的字段
alter table t_table_distribute on cluster default_cluster drop column category_code
插入操作
插入分布式表数据会自动同步到不同的分片中
insert into city_all (id, city_code, city_name, total_cnt, event_time)
values (1, 4000, 'guangzhou', 420000, '2022-02-21 00:00:00');
也可以通过插入不同的机器的分片来插入数据,但是需要知道不同分片的地址是啥。
insert into city_local (id, city_code, city_name, total_cnt, event_time)
values (1, 4000, 'guangzhou', 420000, '2022-02-21 00:00:00');
删除和更新
分布式表是不支持删除和更新的,如果需要删除更新数据,是通过删除和更新本地表来进行操作的。
删除数据
ALTER TABLE app.city_local ON CLUSTER default_cluster DELETE WHERE id in (1,2);
删除分区
ALTER TABLE app.city_local ON CLUSTER default_cluster drop partition(20220222);
更新数据
ALTER TABLE app.city_local ON CLUSTER default_cluster
update city_name ='beijing' where event_time >'2022-02-21 00:00:00';
查询操作
查询操作需要注意子查询和join操作就好,需要多加个global字段
SQLselect id,city_code from city_all where repo = 100
and id global in (select id from city_all where repo = 100)
select a.id from app.city_all a global inner join app.city_all b on a.id = b.id
改造点
删除或者更新数据的地方
如果是本地表只需要加on cluster default_cluster,如果是一个分片的集群也可以不加
如果是分布式表因为分布式表不支持删除,只能删除本地表所以需要在表的后缀加上 _local 并加上on cluster default_cluster
TableClusterUtil.getLocal(租户) 加表的后缀,只在更新表或者删除表的时候在表的后缀上调用这个方法。
查询的地方注意子查询和join查询
如果是本地表不加global,分布式表注意join和in前加上global可以使用
插入的地方不需要改变