前言
论文分享 来自2019ACL的多文档摘要生成方法论文,作者来自英国爱丁堡大学,引用数310
Hierarchical Transformers for Multi-Document Summarization 代码地址hiersumm
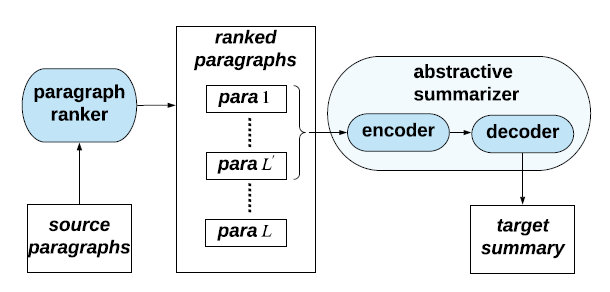
多文档摘要抽取的难点在于没有合适的数据集,同时过长的文档文本也导致现在硬件水平无法支撑模型的训练,Generating Wikipedia by summarizing long sequences.提出了WikiSum数据集,以维基百科的第一段内容作为摘要,以标题+引用的文章或根据标题在网页搜索的前10篇文章(除去wikipedia本文)作为相同主题的文章集(document cluster)输入,提出WikiSum的作者采用二步结构,先抽取式选择一部分重要的段落,然后将这些重要的段落拼接成一个段落后,采用生成式模型进行生成
作者指出,这种将所有重要段落拼接成一个段落的方式忽略了段落之间的层次信息,作者的创新点在于设计了学习文章间层次结构的transformer,并发现对输入文章进行排序能够增强模型效果
模型
首先作者构建了一个段落排序模型,采用基于LSTM的回归模型,以标题和段落作为输入,以段落与目标摘要的ROUGE-2分数作为输出进行拟合,得到一个可以根据标题和段落生成分数的预测模型,在测试时,段落会根据回归模型生成的分数进行排序,最后筛选出
L
′
L'
L′个段落作为最终摘要模型的输入,这里其实是摘要式方法的一种变种,可以有很多选择,整体模型的过程如下图所示,将排序后的
L
′
L'
L′个段落输入到encoder-decoder中最终输出生成式摘要
编码层: 编码层将字转化成向量,并加入位置信息,位置信息为三角函数编码
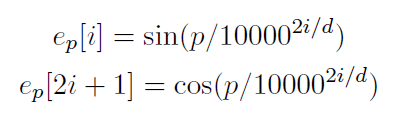
其中由于输入的位置包括字的位置信息和段落的位置信息,因此作者将两个三角函数位置信息通过拼接的方式,拼接到每一个字向量后,i为段落位置,j为字位置,拼接后得到位置编码
p
e
i
j
pe_{ij}
peij,
w
i
j
w_{ij}
wij为字向量,
x
i
j
0
x_{ij}^0
xij0代表第0层,第i个段落第j个字符的向量
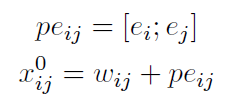
局部Transformer层: 和普通的Transformer一样,由多头注意力层和前向连接层构成
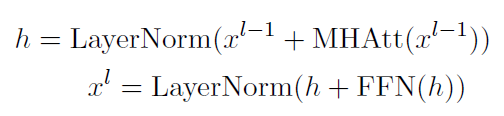
全局Transformer层: 全局Transformer层通过self-attention让每一个段落收集其他段落的信息,得到一个获取上下文信息的全局向量,其由多头池化(Multi head pooling),段落间注意力机制(inter paragraph attention mechanism)和前向连接层构成
多头池化: 是论文的创新点之一,其计算每一个字的分布,根据不同字的权重编码整个句子,是将序列字编码成单一向量的好方法,公式如下
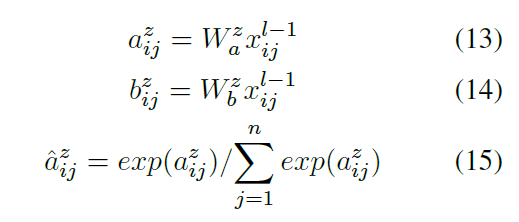
由局部Transformer编码的向量维度为
[
b
a
t
c
h
,
s
e
q
l
e
n
,
d
i
m
]
[batch, seqlen, dim]
[batch,seqlen,dim],通过两个全连接层分别映射到注意力值
a
a
a,维度为
[
b
a
t
c
h
,
n
h
e
a
d
,
s
e
q
l
e
n
,
1
]
[batch,n_{head},seqlen,1]
[batch,nhead,seqlen,1]和值
b
b
b,维度为
[
b
a
t
c
h
,
n
h
e
a
d
,
s
e
q
l
e
n
,
,
d
h
e
a
d
]
[batch,n_{head},seqlen,,d_{head}]
[batch,nhead,seqlen,,dhead],注意力分数通过对注意力值进行softmax得到
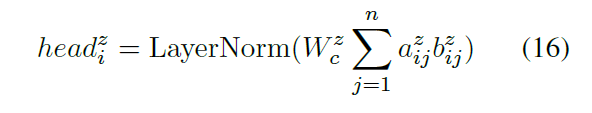
将注意力分数和字向量进行相乘后,在序列长度维度进行相加和归一化后,得到每一个段落不同head的表征,多头池化代码如下,输入为
[
b
a
t
c
h
,
s
e
q
l
e
n
,
d
i
m
]
[batch, seqlen, dim]
[batch,seqlen,dim],输出为
[
b
a
t
c
h
,
h
e
a
d
,
d
i
m
]
[batch,head,dim]
[batch,head,dim]
class MultiHeadedPooling(nn.Module):
def __init__(self, head_count, model_dim, dropout=0.1, use_final_linear=True):
assert model_dim % head_count == 0
self.dim_per_head = model_dim // head_count
self.model_dim = model_dim
super(MultiHeadedPooling, self).__init__()
self.head_count = head_count
self.linear_keys = nn.Linear(model_dim,
head_count)
self.linear_values = nn.Linear(model_dim,
head_count * self.dim_per_head)
self.softmax = nn.Softmax(dim=-1)
self.dropout = nn.Dropout(dropout)
if (use_final_linear):
self.final_linear = nn.Linear(model_dim, model_dim)
self.use_final_linear = use_final_linear
def forward(self, key, value, mask=None):
batch_size = key.size(0)
dim_per_head = self.dim_per_head
head_count = self.head_count
def shape(x, dim=dim_per_head):
""" projection """
return x.view(batch_size, -1, head_count, dim) \
.transpose(1, 2)
def unshape(x, dim=dim_per_head):
""" compute context """
return x.transpose(1, 2).contiguous() \
.view(batch_size, -1, head_count * dim)
scores = self.linear_keys(key)
value = self.linear_values(value)
scores = shape(scores, 1).squeeze(-1)
value = shape(value)
# key_len = key.size(2)
# query_len = query.size(2)
#
# scores = torch.matmul(query, key.transpose(2, 3))
if mask is not None:
mask = mask.unsqueeze(1).expand_as(scores)
scores = scores.masked_fill(mask, -1e18)
# 3) Apply attention dropout and compute context vectors.
attn = self.softmax(scores)
drop_attn = self.dropout(attn)
context = torch.sum((drop_attn.unsqueeze(-1) * value), -2)
if (self.use_final_linear):
context = unshape(context).squeeze(1)
output = self.final_linear(context)
return output
else:
return context
不输出head维度,直接输出单一的段落向量方法,输入为 [ b a t c h , s e q l e n , d i m ] [batch, seqlen, dim] [batch,seqlen,dim],输出为 [ b a t c h , d i m ] [batch,dim] [batch,dim]
class MultiHeadPoolingLayer( nn.Module ):
def __init__( self, embed_dim, num_heads ):
super().__init__()
self.num_heads = num_heads
self.dim_per_head = int( embed_dim/num_heads )
self.ln_attention_score = nn.Linear( embed_dim, num_heads )
self.ln_value = nn.Linear( embed_dim, num_heads * self.dim_per_head )
self.ln_out = nn.Linear( num_heads * self.dim_per_head , embed_dim )
def forward(self, input_embedding , mask=None):
a = self.ln_attention_score( input_embedding )
v = self.ln_value( input_embedding )
a = a.view( a.size(0), a.size(1), self.num_heads, 1 ).transpose(1,2)
v = v.view( v.size(0), v.size(1), self.num_heads, self.dim_per_head ).transpose(1,2)
a = a.transpose(2,3)
if mask is not None:
a = a.masked_fill( mask.unsqueeze(1).unsqueeze(1) , -1e9 )
a = F.softmax(a , dim = -1 )
new_v = a.matmul(v)
new_v = new_v.transpose( 1,2 ).contiguous()
new_v = new_v.view( new_v.size(0), new_v.size(1) ,-1 ).squeeze(1)
new_v = self.ln_out( new_v )
return new_v
段落间注意力: 段落间注意力是采用自注意力机制(scale dot product)对每一个段落的head表征进行学习,目的是让每一个段落学习到其他段落的关联信息,最终得到段落i,注意力头z的上下文表征
c
o
n
t
e
x
t
i
z
context_i^z
contextiz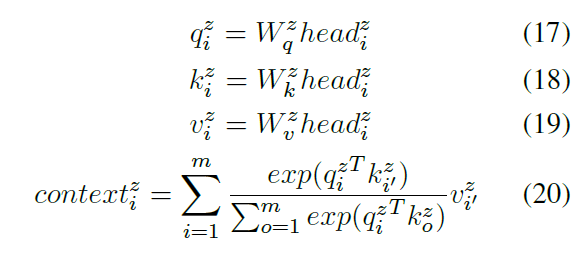
前向连接层: 前向连接层的输入为一个段落多个head的拼接, 最终输出和全局Transformer层输入一样维度的输出
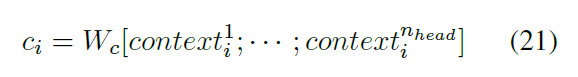
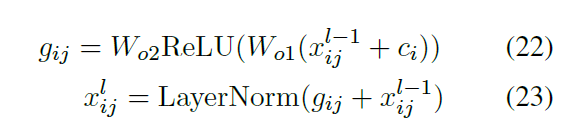
段落间注意力的注意力分数其实是段落间的关系系数,因此可以采用已学习好的图表征来代替,例如句法关系图(Lexical Relation Graph)和(近似对画图)Approximate Discourse Graph,有兴趣的读者可以看论文附录,替代方式如下
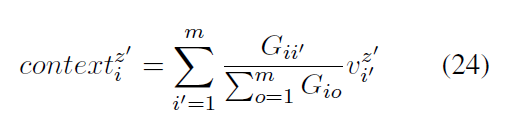
实验
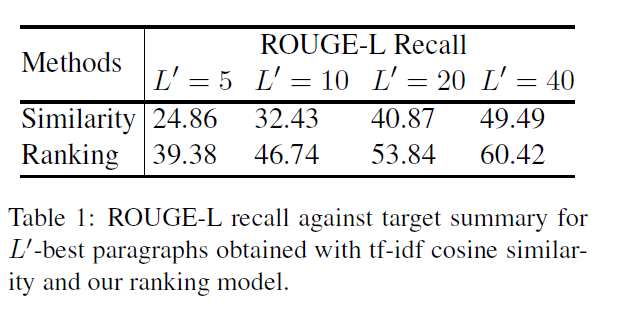
作者比较了不同数量段落的情况下,tf-idf cosine similarity和使用回归模型排序选择方式下,抽取段落和真实摘要之间的ROUGE-L 召回值,可以发现回归模型能够选择更好的段落
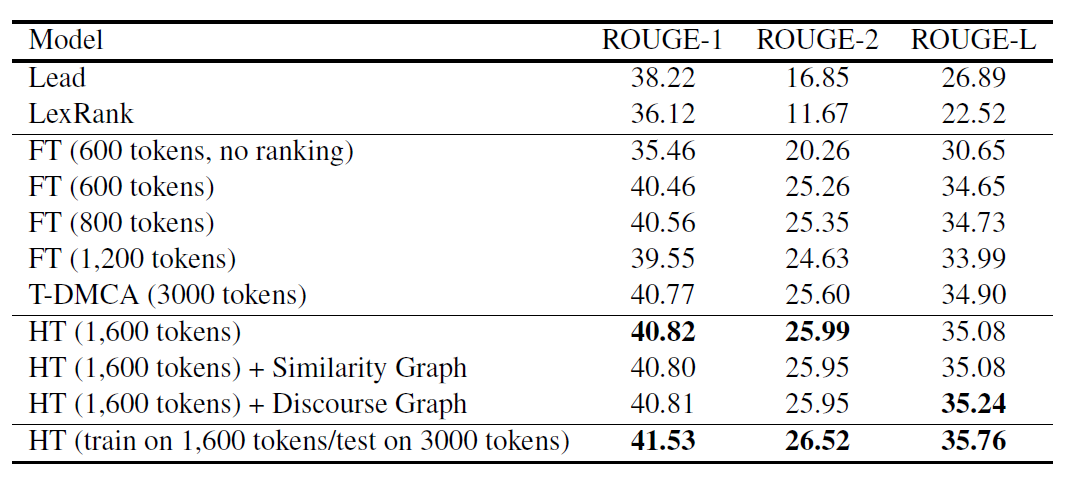
作者比较了层次Transformer模型与Flat Transformer和Transformer Decoder with Memory Compression attention之间的性能,HT相比T-DMCA在更少的字符数下能够有些微的提升,同时,在1600长度文本训练的模型,在3000字输入的情况下能够获得更好的结果,近1个点的ROUGE提升

作者还做了消融实验,表明位置编码,多头池化和全局Transformer都是有用的
结论
论文中采用多头池化的方式获得多头上下文表征,并将不同段落的多头上下文表征进行相互学习