1.数据和环境准备
将通过意大利红酒的部分数据,调用scikit-learn包(sklearn)分别实现0-1标准化和z-score标准化,总结学习这两种标准化方法的特点。
本案例使用的环境为Anaconda + Jupyter notebook。
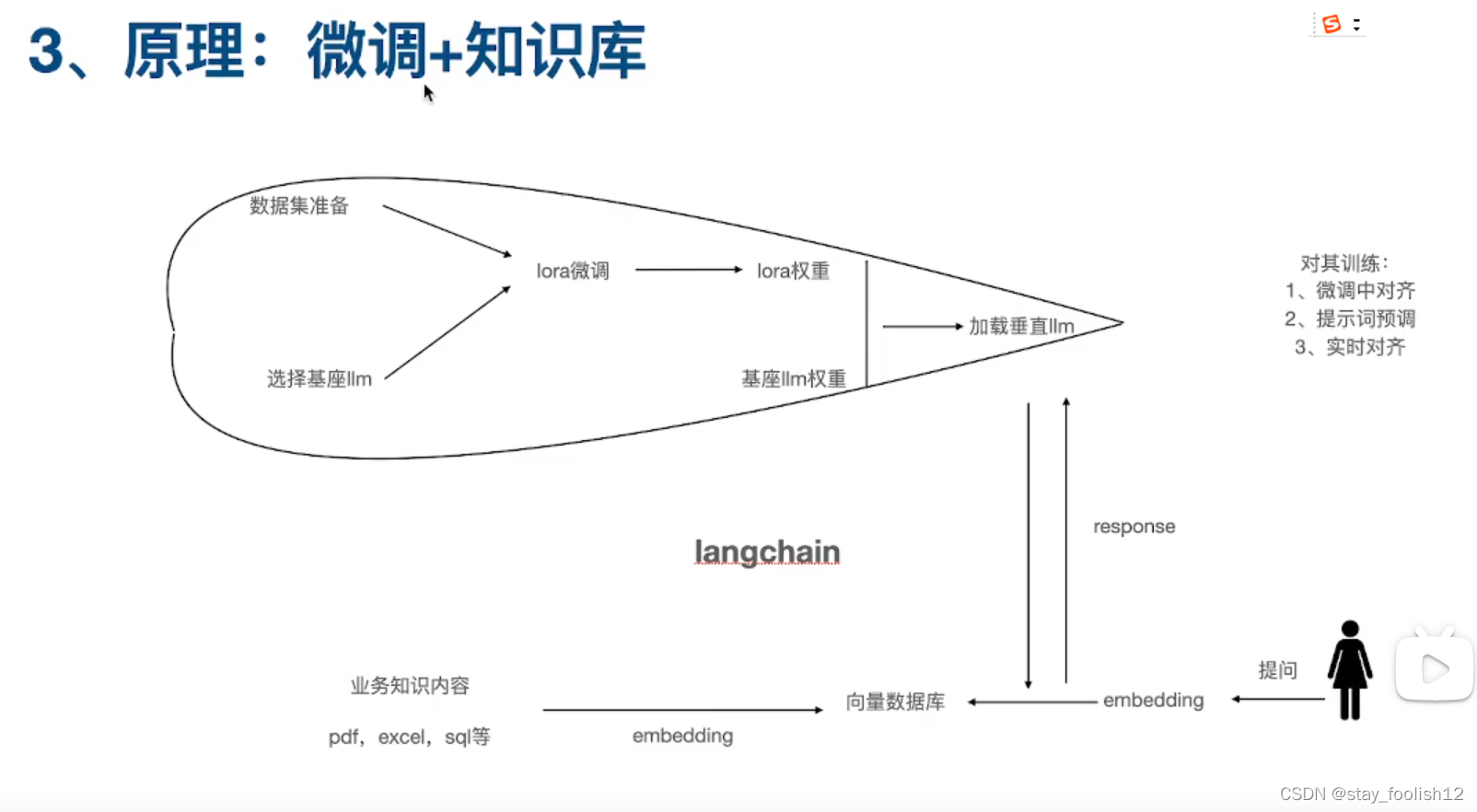
2.数据说明
我们使用的是UCI提供的红酒数据集,该数据集显示意大利红酒化学分析的结果,共178个样本,每个样本有13个特征变量,一个类别变量。
为简化实验,更清晰地展现实验结果,仅选取两个特征变量进行展示。
Alcohol:酒精含量
Malic acid:羟基丁二酸
Class:红酒分类情况
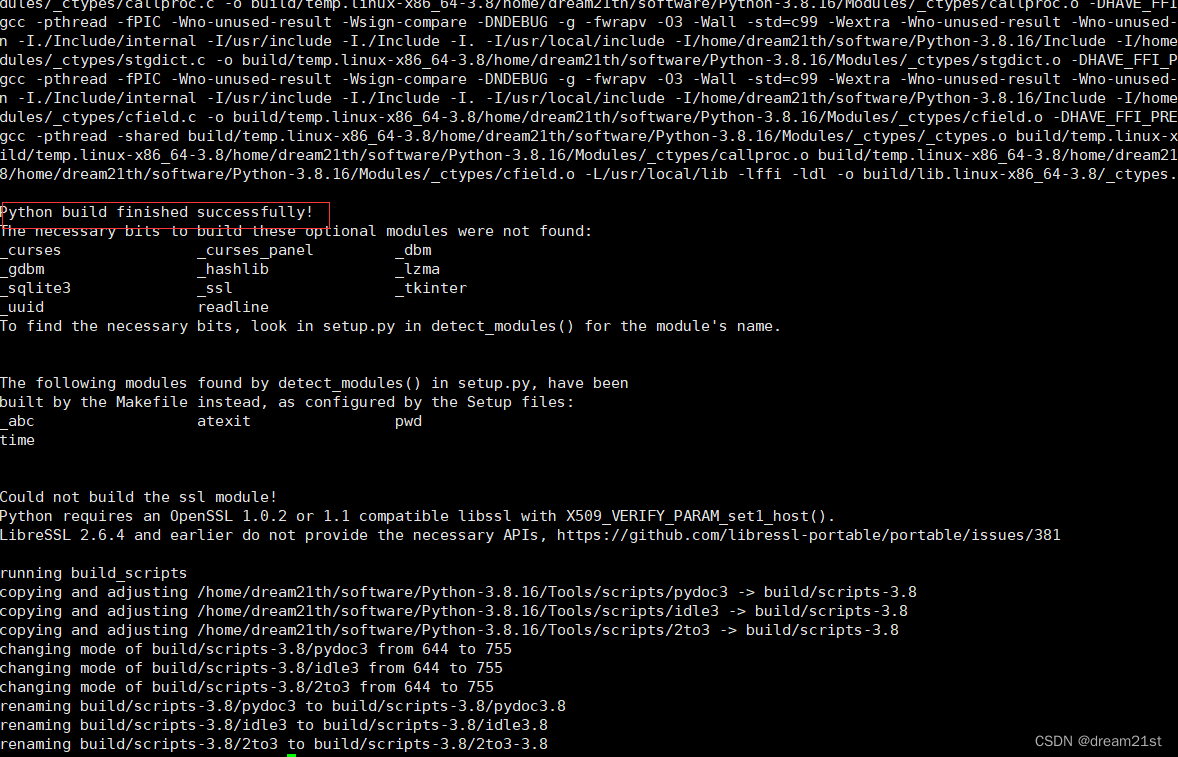
3.实验过程
导入需要的工具包

读取文件

 数据标准化
数据标准化
0-1标准化
![]()

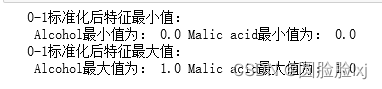
z-score标准化
![]()


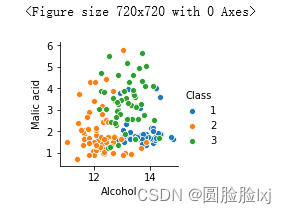
可视化
先进行数据备份

绘制散点图

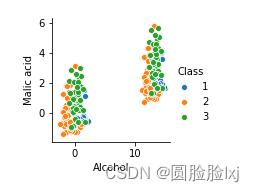
绘制原始数据的散点图








![[代码案例] pytorch快速上手写机器学习](https://img-blog.csdnimg.cn/e47c7e93587f4c5c9f64c3f3376492ac.png)
![int[]数组转Integer[]、List、Map「结合leetcode:第414题 第三大的数、第169题 多数元素 介绍」](https://img-blog.csdnimg.cn/20200507205513993.jpg?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L1RpYW5jNjY2,size_16,color_FFFFFF,t_70#pic_center)