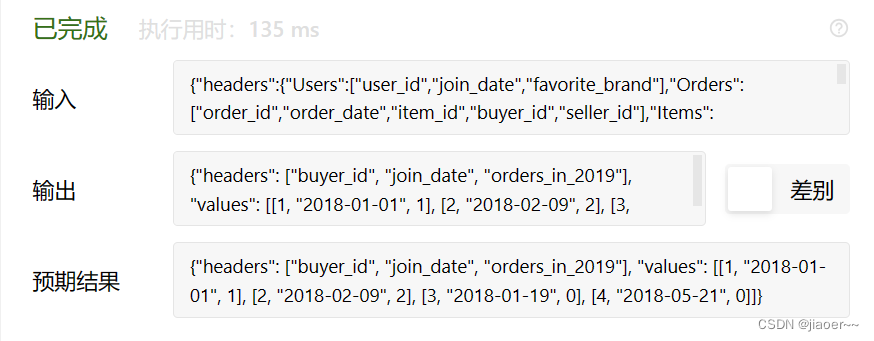
本篇文章给大家谈谈python学到什么程度算入门,以及python从入门到精通好吗,希望对各位有所帮助,不要忘了收藏本站喔。

学习 Python 之 进阶学习
-
- 一切皆对象
-
- 1. 变量和函数皆对象
- 2. 模块和类皆对象
- 3. 对象的基本操作
-
- (1). 可以赋值给变量
- (2). 可以添加到集合中
- (3). 可以作为函数参数
- (4). 可以作为函数返回值返回
- 4. object, type, class之间的关系
-
- (1). object类
- (2).type类和type对象
- 闭包
-
- 1. 查看闭包
-
- (1). 查看闭包
- (2). 查看环境变量
- 2. 分析闭包
- 3. 闭包的用处
- Lambda 表达式
-
- 1. 匿名函数
- 2. 三元表达式
- 3. map类
- 4. map与lambda表达式结合使用
- 5. reduce函数
-
- ```reduce()```函数运算原理
- 6. filter函数
- 装饰器
-
- 1. 引例
- 2. 装饰器
- 3. 装饰器使用
- 4. 对带有参数的函数定义装饰器
- 5. 带有参数的装饰器的理解
- 6. 装饰器完整定义
- 7. 使用python装饰器保存内置变量的值
- 8. 数据类装饰器 dataclass
- 用字典映射代替switch case
- 列表推导式
-
- (1). 简单使用
- (2). 带有条件的列表推导式
- (3). 使用列表推导式创建元组
- (4). 字典列表推导式
-
- items()
- 字典推导字典
- 函数式编程
- 迭代器
-
- (1). 可迭代对象 和 迭代器
- (2). 自定义迭代器
- 生成器
- 海象运算符 :=
一切皆对象
1. 变量和函数皆对象
在python中, 所有的变量函数都是一个对象
print(type(1))
print(type(1.))
print(type(True))
print(type(None))
结果:
<class 'int'>
<class 'float'>
<class 'bool'>
<class 'NoneType'>
可以看出, 变量都是对象, 它们的类型都是class, 再看看函数
def f():
pass
print(type(f))
结果:
<class 'function'>
从上面的例子可以看出, 实际上函数就是一个对象, 那么函数可以当某个函数的参数和返回值了
2. 模块和类皆对象
就连模块和类都是对象
import sys
print(type(sys))
class A:
pass
print(type(A))
结果:
<class 'module'>
<class 'type'>
3. 对象的基本操作
(1). 可以赋值给变量
(2). 可以添加到集合中
(3). 可以作为函数参数
(4). 可以作为函数返回值返回
4. object, type, class之间的关系
(1). object类
object类是所有类都要继承的一个基础类(父类)
class People:
pass
print(People.__bases__)
结果:
(<class 'object'>,)
(2).type类和type对象
type()函数查看变量类型, 但是type也是一个类, 还是一个对象
a = 1
print(type(a))
print(type(int))
结果:
<class 'int'>
<class 'type'>
因此, type类 生成 int类, int类 生成 1, 1 赋值给 a, 所以 a是int类的对象
所以, type类生成其他类
print(type.__bases__)
print(type(type))
print(type(object))
print(object.__bases__)
结果:
(<class 'object'>,)
<class 'type'>
<class 'type'>
()
可以看出, object类的父类是空
type类继承object类, type类又生成object类
type类生成type类
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ug6hlh6Q-1654273663491)(学习图片/type与object的关系.png)]](https://img-blog.csdnimg.cn/a7bd77d4ffd04d00af4cc5e36be3e0e6.png#pic_center)
闭包
一个函数中的变量由其外部环境变量所决定的整体, 即函数 + 环境变量
闭包的意义: 保存了函数, 和函数定义时的变量
def func1():
a = 5
def ax2(x):
return a * x * 2
return ax2
a 是环境变量, ax2()是函数, 它们构成了一个闭包
1. 查看闭包
(1). 查看闭包
只有闭包才拥有内置属性__closure__
def func1():
a = 5
def ax2(x):
return a * x * 2
return ax2
f = func1()
print(f.__closure__)
(<cell at 0x0000025E9917AF50: int object at 0x0000025E99010170>,)
(2). 查看环境变量
def func1():
a = 5
def ax2(x):
return a * x * 2
return ax2
f = func1()
print(f.__closure__[0].cell_contents)
5
2. 分析闭包
函数里定义变量后不是闭包
def fun1():
a = 5
def fun2():
b = 10
return b
return fun2
f = fun1()
print(f.__closure__)
None
def fun1():
a = 5
def fun2():
return a
return fun2
f = fun1()
print(f.__closure__)
(<cell at 0x0000025E9917AF50: int object at 0x0000025E99010170>,)
3. 闭包的用处
问题: 实现函数, 每次返回结果, 要在加入上一次的结果
假设开始 x = 0, 函数名是 add()
第一次 add(5), x = 5
第二次 add(10), x = 15
第三次 add(40), x = 40
x的值是在上一次的结果上叠加
- 不用闭包
x = 0
def add(v):
global x
x += v
return x
print('第一次:' , add(1))
print('第二次:' , add(5))
print('第三次:' , add(6))
print('第四次:' , add(10))
结果
第一次: 1
第二次: 6
第三次: 12
第四次: 22
- 使用闭包
x = 0
def start(x):
def add(v):
nonlocal x
x += v
return x
return add
add = start(x)
print('第一次:' , add(1))
print('第二次:' , add(5))
print('第三次:' , add(6))
print('第四次:' , add(10))
使用nonlocal关键字
闭包的意义在于可以记录了上一次的值
Lambda 表达式
1. 匿名函数
没有函数名的函数
语法:
lambda parameter_list: expression
定义使用labmda关键字
expression只能是表达式
def add(x, y):
return x + y
f = lambda x, y: x + y
print(f(1, 2))
2. 三元表达式
条件为真返回结果 if 条件 else 条件为假返回结果
x = 1
y = 6
print(x if x > y else y)
如果 x > y 返回 x 的值, 否则返回 y 的值
3. map类
map类接收两个参数, 一个是函数, 另一个是序列
map的使用方法是, 对序列中的每一个元素都进行前面函数的操作, 并把结果存放新的序列中, 最后返回
x = [1, 2, 3]
def square(x):
return x * x
r = map(square, x)
print('结果: ', list(r))
print('x: ', x)
这个代码相当于使用for循环
x = [1, 2, 3]
def square(x):
return x * x
# r = map(square, x)
r = []
for v in x:
r.append(square(v))
print('结果: ', list(r))
print('x: ', x)
结果是一样的:
结果: [1, 4, 9]
x: [1, 2, 3]
4. map与lambda表达式结合使用
可以简化代码
x = [1, 2, 3]
r = map(lambda x: x + x, x)
print('结果: ', list(r))
print('x: ', x)
结果:
x = [1, 2, 3]
r = map(lambda x: x * x, x)
print('结果: ', list(r))
print('x: ', x)
使用多个序列, 需要注意, 后面传入的序列个数和lambda表达式参数个数一直
x = [1, 2, 3]
y = [10, 20, 30, 40]
# 传入x和y两个参数, lambda表示参数个数也是2
r = map(lambda x, y: x * y, x, y)
print('结果: ', list(r))
print('x: ', x)
结果:
结果: [10, 40, 90]
x: [1, 2, 3]
返回结果的长度是最小的序列长度
5. reduce函数
from functools import reduce
recude(函数, 序列, 初值)
from functools import reduce
def add(x, y):
return x + y
x = [1, 2, 3]
r = reduce(add, x)
print(r)
结果
6
reduce()函数运算原理
-
没有初值的情况
第一次执行, 调用add(1, 2), r = add(1, 2)
第二次执行, 调用add(r, 3), r = add(r, 3)
此时, 序列已经执行到最后一个元素了, 返回执行的结果
所以结果是: add(add(1, 2), 3)
-
有初值的情况
第一次执行, 调用add(初值, 2), r = add(初值, 2)第二次执行, 调用add(r, 2), r = add(r, 2)
第三次执行, 调用add(r, 3), r = add(r, 3)
此时, 序列已经执行到最后一个元素了, 返回执行的结果
所以结果是: add(add(add(初值, 1), 2), 3)
from functools import reduce
def add(x, y):
return x + y
x = ['1', '2', '3']
r = reduce(add, x, 'v')
print(r)
结果:
v123
6. filter函数
filter(函数, 序列)
例子: 保留x列表中值大于3的元素
x = [1, 2, 6, 5, 4, 3]
def fun(x):
return True if x > 3 else False
r = filter(fun, x)
print(list(r))
装饰器
1. 引例
现在有三个函数, 在每个函数中都要输出函数调用的时间
import time
def practice():
def func1():
print(time.time())
print('func1')
def func2():
print(time.time())
print('func2')
def func3():
print(time.time())
print('func3')
return func1, func2, func3
printTime = practice()
for i in printTime:
i()
结果:
1653194377.809377
func1
1653194377.809377
func2
1653194377.809377
func3
如果此时, 将打印时间改为打印函数名, 是不是需要对每一个函数进行修改?
修改是封闭的, 扩展是开放的, 修改不能解决根本
优化
import time
def practice():
def printTime(func):
print(time.time())
func()
def func1():
print('func1')
def func2():
print('func2')
def func3():
print('func3')
return func1, func2, func3, printTime
func1, func2, func3, printTime = practice()
printTime(func1)
printTime(func2)
printTime(func3)
结果:
1653194518.6538224
func1
1653194518.6538224
func2
1653194518.6538224
func3
为了更简便, 这就引入了装饰器
2. 装饰器
import time
# 定义装饰器
def decorator(func):
def wrapper():
print(time.time())
func()
return wrapper
def func1():
print('func1')
# 使用装饰器
func1 = decorator(func1)
func1()
看上去, 这种使用跟printTime()这种方法没什么区别
3. 装饰器使用
使用@简化调用
使用方法: @装饰器名字
import time
def decorator(func):
def wrapper():
print(time.time())
func()
return wrapper
@decorator
def func1():
print('func1')
func1()
结果
1653195433.3289523
func1
4. 对带有参数的函数定义装饰器
对于wrapper()函数使用可变参数
import time
def decorator(func):
def wrapper(*parameters):
print(time.time())
func(*parameters)
return wrapper
@decorator
def func1(x):
print('func1', x)
@decorator
def func2(x, y):
print('func1', x, y)
func1(1)
func2('aaa', 'bbb')
结果:
1653196573.0688334
func1 1
1653196573.0688334
func1 aaa bbb
这种情况也有问题, 不兼容 **args参数
import time
def decorator(func):
def wrapper(*parameters):
print(time.time())
func(*parameters)
return wrapper
@decorator
def func1(**x):
print('func1', x)
func1(a = 2, b = 3)
会报错
解决办法:
import time
def decorator(func):
def wrapper(*parameters, **kwargs):
print(time.time())
func(*parameters, **kwargs)
return wrapper
@decorator
def func1(**x):
print('func1', x)
func1(a = 2, b = 3)
5. 带有参数的装饰器的理解
*parameters用于获取函数默认的传参顺序所获得的值
**kwargs用于获取可变参数列表的值
def decorator(func):
def wrapper(*parameters, **kwargs):
print(parameters)
print(kwargs)
func(*parameters, **kwargs)
return wrapper
@decorator
def func1(p1, p2, **x):
print('func1', p1, p2, x)
func1(1, 2, a = 2, b = 3)
结果:
(1, 2)
{'a': 2, 'b': 3}
func1 1 2 {'a': 2, 'b': 3}
6. 装饰器完整定义
def 装饰器名字(func):
def wrapper(*parameters, **kwargs):
所要执行的逻辑
func(*parameters, **kwargs)
return wrapper
使用
@装饰器名称
7. 使用python装饰器保存内置变量的值
from functools import wraps
def 装饰器名字(func):
@wraps(func)
def wrapper(*parameters, **kwargs):
所要执行的逻辑
func(*parameters, **kwargs)
return wrapper
8. 数据类装饰器 dataclass
用来简化构造函数赋值
原来的样子
class Student:
def __init__(self, name, age):
self.name = name
self.age = age
使用修饰器
from dataclasses import dataclass
@dataclass
class Student:
name: str
age: int
# def __init__(self, name, age):
# self.name = name
# self.age = age
def showInfo(self):
print(self.name, self.age)
student = Student('小米', 18)
student.showInfo()
看一下dataclass函数
def dataclass(cls=None, /, *, init=True, repr=True, eq=True, order=False,
unsafe_hash=False, frozen=False, match_args=True,
kw_only=False, slots=False):
...
可以看出, 在@dataclass后面可以指定参数
init=True 表示默认产生构造函数
用字典映射代替switch case
C语言中的switch case语句
switch (表达式) {
case 整型数值1: 语句 1;
case 整型数值2: 语句 2;
......
case 整型数值n: 语句 n;
default: 语句 n+1;
}
python中使用字典
switcher = {
值1: 函数1
值2: 函数2
......
值n: 函数n
}
r = switcher.get(值, default函数)()
例子: 输入1 ~ 7之间的数字, 输出对应的星期
def isMonday():
return '星期一'
def isTuesday():
return '星期二'
def isWednesday():
return '星期三'
def isThursday():
return '星期四'
def isFriday():
return '星期五'
def isSaturday():
return '星期一'
def isSunday():
return '星期天'
def default():
return '输入错误'
switcher = {
1: isMonday,
2: isTuesday,
3: isWednesday,
4: isThursday,
5: isFriday,
6: isSaturday,
7: isSunday
}
v = input()
r = switcher.get(int(v), default)()
print(r)
列表推导式
列表推导式: 使用列表, 字典, 元组, 集合, 创建一个新的列表, 字典, 元组, 集合
(1). 简单使用
[ 表达式 i for in x ]
def add(x):
return x + x
x = [1, 2, 3]
b = [add(i) for i in x if i == 2]
print(b)
结果:
[2, 4, 6]
(2). 带有条件的列表推导式
[ 表达式 i for in x if 表达式 ]
当i满足条件e()时, 执行f(), 将结果放入新的列表中
def add(x):
return x + x
def condition(x):
return x == 2
x = [1, 2, 3]
b = [add(i) for i in x if condition(i)]
print(b)
结果:
[4]
(3). 使用列表推导式创建元组
def add(x):
return x + x
def condition(x):
return x >= 2
x = [1, 2, 3, 4, 5]
b = (add(i) for i in x if condition(i))
print(b)
结果:
<generator object <genexpr> at 0x00000134B19F18C0>
此时结果不是元组, 而是一个generator, 遍历一下generator
def add(x):
return x + x
def condition(x):
return x >= 2
x = [1, 2, 3, 4, 5]
b = (add(i) for i in x if condition(i))
for i in b:
print(i)
结果:
4
6
8
10
转换一下可以得到元组
def add(x):
return x + x
def condition(x):
return x >= 2
x = [1, 2, 3, 4, 5]
b = tuple((add(i) for i in x if condition(i)))
print(b)
结果:
(4, 6, 8, 10)
(4). 字典列表推导式
items()
students = {
'张三': 18,
'李四': 19,
'王五': 21
}
s = [key for key, value in students.items()]
print(s)
结果:
['张三', '李四', '王五']
需要注意的是, 字典遍历需要使用items()函数
字典推导字典
将students字典中的key变成value, value变成key
students = {
'张三': 18,
'李四': 19,
'王五': 21
}
s = {value: key for key, value in students.items()}
print(s)
结果:
{18: '张三', 19: '李四', 21: '王五'}
函数式编程
for i in range(start, end, step = 1):
pass
代替
[pass for i in range(start, end, step = 1)]
list(
map(lambda i: dosomething, [i for i in range(start, end, step = 1)])
)
迭代器
(1). 可迭代对象 和 迭代器
可迭代对象: 可以使用for-in循环遍历的对象
迭代器: 是一个类, 可以被for-in循环遍历
(2). 自定义迭代器
类实现两个函数, __iter__()和 __next__()
def __iter__(self):
pass
def __next__(self):
pass
例子:
class BookCollection:
def __init__(self):
self.data = ['1', '2', '3']
self.cur = 0
def __iter__(self):
return self
def __next__(self):
if self.cur >= len(self.data):
self.cur = 0
raise StopIteration()
r = self.data[self.cur]
self.cur += 1
return r
books = BookCollection()
[print(i) for i in books]
结果:
1
2
3
生成器
生成器是针对函数的, 保存一个算法
def generate(end):
n = 0
while n < end:
n += 1
yield n
print(generate(100))
使用列表推导式得到生成器
print(i for i in range(1, 9))
海象运算符 :=
可以使用在if中, 使得函数调用的值赋给一个变量, 同时进行条件判断操作, 省去了在外定义变量
a = "Python"
if l := len(a) > 5:
print(l)
结果:
6
使用前:
a = "Python"
l = len(a)
if l > 5:
print(l)