一、数据结构差别
-
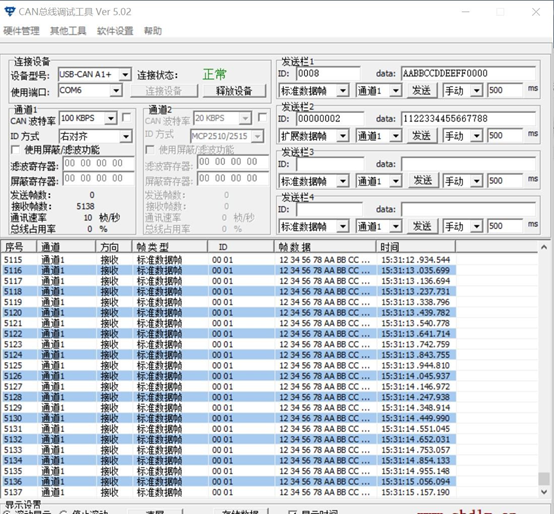
1.7:数组+链表
-
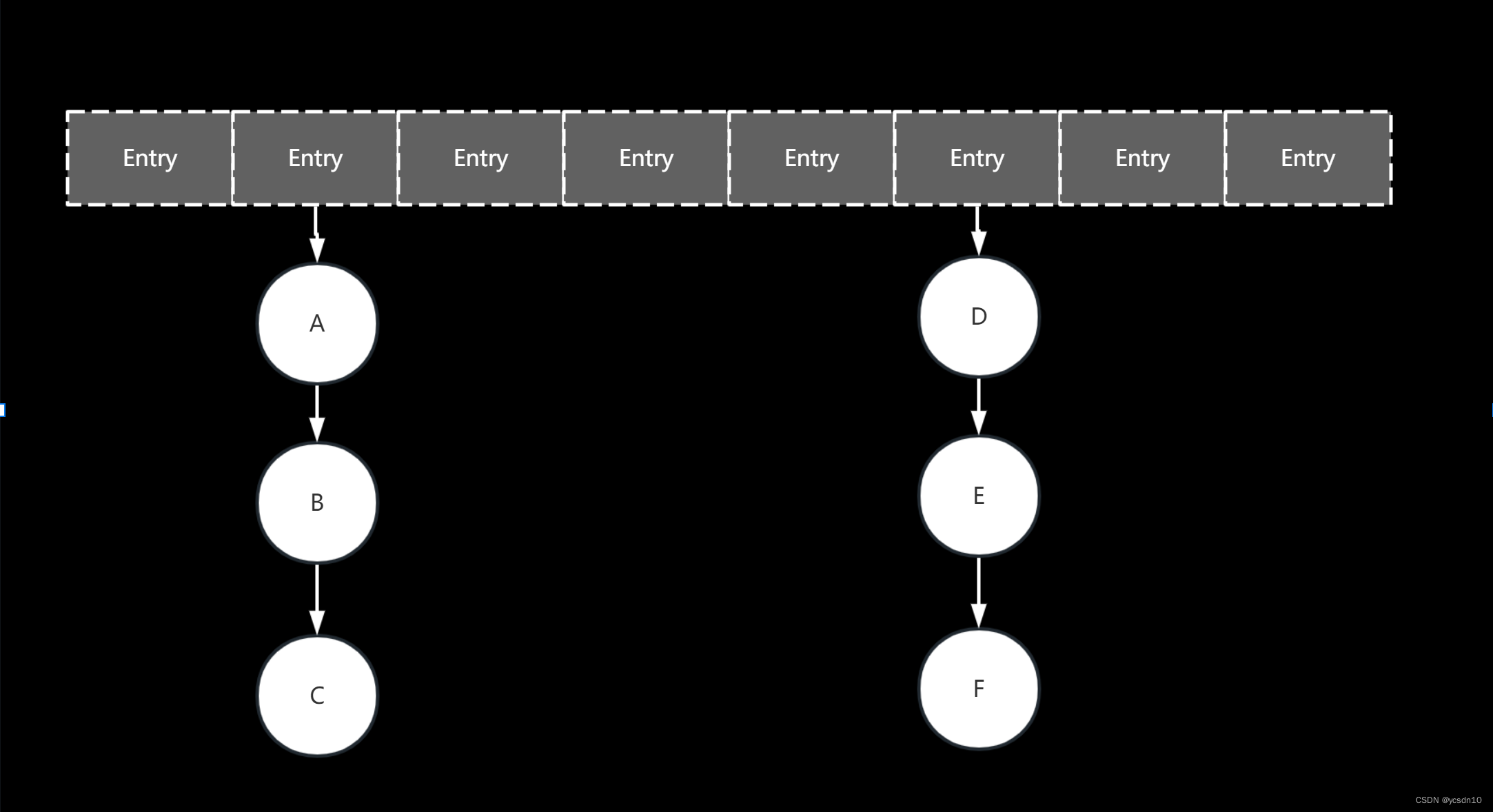
1.8:数组+链表+红黑树
- 当链表的长度大于8时,数组长度大于64,原来的链表数据结构变为红黑树
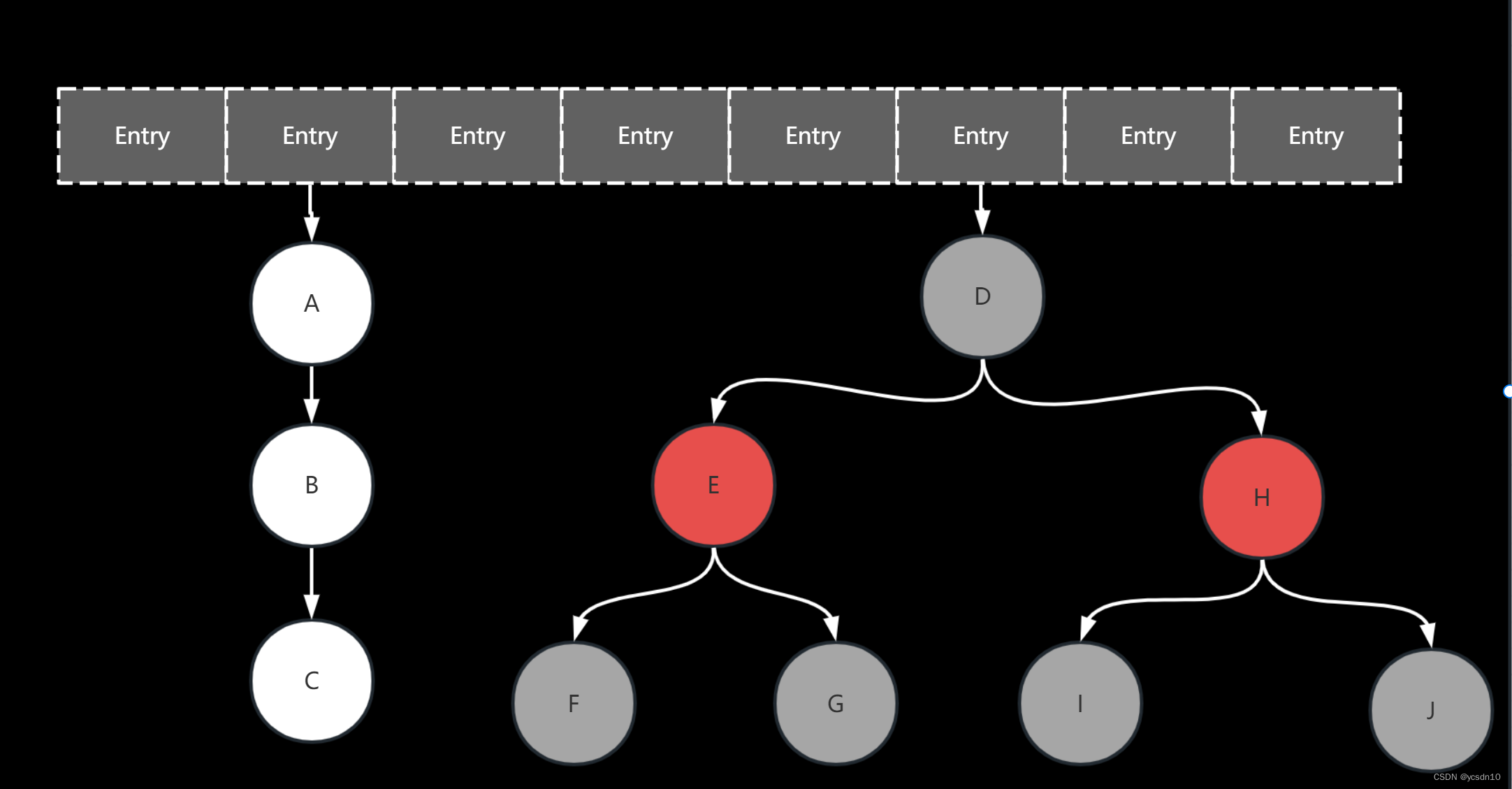
二、HashMap中的关键属性和方法区别
| 方法/变量/类 | JDK7 | JDK8 | 备注 |
| DEFAULT_INITIAL_CAPACITY | 16 | 16 | 默认初始的大小16 |
| MAXIMUM_CAPACITY | 2的30 | 2的30 | 最大的key的容量 |
| DEFAULT_LOAD_FACTOR | 0.75 | 0.75 | 默认的负载因子 |
| table | Entry[] | Node<K,V>[] | JDK7:表,根据需要调整大小。长度必须始终是二的幂。 JDK8:该表在首次使用时初始化,并根据需要调整大小。分配时,长度总是二的幂。(我们在某些操作中也允许长度为零,以允许目前不需要的自举机制。) |
| size | int | int | 此映射中包含的键值映射数。 |
| threshold | Int | int | 要调整大小的下一个大小值(容量*负载系数)。 |
| loadFactor | float | float | 哈希表的加载因子。 |
| modCount | int | int | 该HashMap在结构上被修改的次数结构修改是指改变HashMap中映射数量或以其他方式修改其内部结构(例如,rehash)的修改。该字段用于使HashMap的Collection视图上的迭代器快速失败。(请参见ConcurrentModificationException)。 |
| TREEIFY_THRESHOLD | 无 | 8 | 为bin使用树而不是列表的bin计数阈值。当向至少有这么多节点的bin添加元素时,bin会转换为树。该值必须大于2,并且应至少为8,将转化成树(链表转成树条件) |
| UNTREEIFY_THRESHOLD | 无 | 6 | 在调整大小操作期间用于取消检测(拆分)桶的长度计数阈值。应小于TREEIFY_THRESHOLD,并且最多为6,以便在移除时进行收缩检测。(树退化成链表的条件) |
| MIN_TREEIFY_CAPACITY | 无 | 64 | 可以将存储箱树化的最小表容量。(否则,如果一个bin中的节点太多,则会调整表的大小。)应至少为4*TREEIFY_THRESHOLD,以避免调整大小阈值和树化阈值之间的冲突。(链表转成树条件或者退化条件) |
| hash | static int | static final int | Jdk7:将补充散列函数应用于给定的hashCode防御质量较差的散列函数。这是至关重要的 因为HashMap使用两个长度哈希表的幂否则会遇到没有差异的hashCode冲突以较低的比特。注意:空键总是映射到哈希0,因此索引 JDK8:计算key.hashCode()并将哈希的高位扩展(XOR)到低位。因为该表使用两个掩码的幂,所以仅在当前掩码之上以位为单位变化的哈希集总是会发生冲突。(已知的例子包括在小表中保存连续整数的Float键集。)因此,我们应用了一种向下扩展高位影响的变换。比特扩展的速度、效用和质量之间存在折衷。因为许多常见的哈希集已经合理分布(因此不会从扩展中受益),而且因为我们使用树来处理箱中的大型冲突集,所以我们只需以最便宜的方式对一些移位的比特进行异或运算,以减少系统损失,并合并最高比特的影响,否则由于表边界的原因,这些比特将永远不会用于索引计算。 |
| Entry<K,V> | implements Map.Entry<K,V> | ||
| Node<K,V> | 无 | 新增 implements Map.Entry<K,V> | JDK8:基本hash bin节点,用于大多数条目。 |
| entrySet | Set<Map.Entry<K,V>> | 保留缓存的entrySet()。请注意,AbstractMap字段用于keySet()和values()。 | |
| putIfAbsent | 无 | 新增 | 如果传入key对应的value已经存在,就返回存在的value,不进行替换。如果不存在,就添加key和value,返回null |
| computeIfAbsent | 无 | 新增 | 方法计算一个新值,如果该键没有与哈希映射中的任何值相关联,则将其与指定的键相关联。 import java.util.HashMap; class Main { public static void main(String[] args) { // 创建 HashMap HashMap<String, Integer> digitals= new HashMap<>(); // 向HashMap插入条目 prices.put("A", 20); prices.put("B", 30); prices.put("C", 15); System.out.println("HashMap: " + digital); // 简单用法 int afterChangeDigital = prices.computeIfAbsent("B", key -> 280); System.out.println("B的数字: " + afterChangeDigital ); // 打印更新HashMap System.out.println("更新后的 HashMap: " + digitals); } } |
| UnsafeHolder | 无 | 新增 | 支持在反序列化期间重置最终字段 |
| HashIterator | 有 | 有 | JDK7:private abstract class H HashIterator<E> implements Iterator<E> HDK8:abstract class HashIterator |
| TreeNode | 无 | 新增 | 树节点 |
三、JDK1.8版本优点
1.对于1.7来讲,1.8版本的HashMap在数据量大的时候,HashCode相同的大于8,且数组的数量大于64的时候,链表会转化成红黑树,红黑树查询效率更高
2.JDK8版本新特性来讲,具有流及函数计算特点


![【PWN · 栈迁移】[BUUCTF]ciscn_2019_es_2](https://s3-us-west-2.amazonaws.com/secure.notion-static.com/4f7d2562-49df-4956-9ae7-8351c56d1820/Untitled.png)