原始文件:

目标文件:
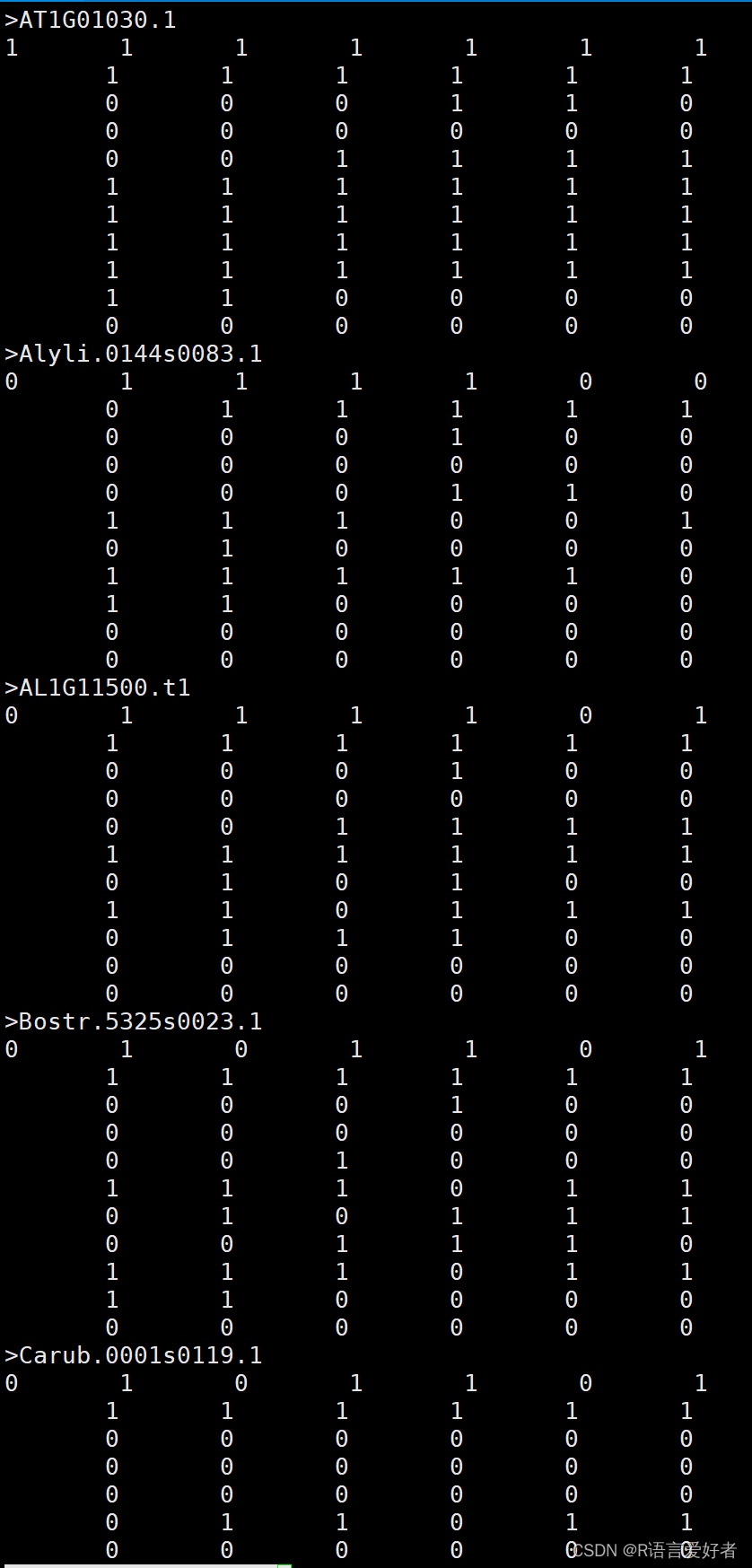
linux版本
#name:lin_convert_fasta_to_01.py
#! /usr/bin/env python
#usage: python hash-always.py -l 1.list -f 2.txt > out.txt
import argparse
parser = argparse.ArgumentParser(description="Advanced screening always by hash")
parser.add_argument("-f1","--file1",help="the original file,tabulated,make sure do not contain blank line")
args = parser.parse_args()
n = 0
newlist = []#创建一个列表
# b=open("out1.sequence.txt","w")
with open(args.file1,"r") as fn1:
for i in fn1:
eachline = i.strip()
n = n + 1
if eachline.startswith(">"):#把以">"开头的,打印出来,意思是把fasta序列的表头打印出来
print(eachline)
# b.write(eachline+"\n")
else:
if n ==2:
# print(eachline)
for i in eachline:
i = i.strip("\n").split()
i = "".join(i)
if i == "A":
newlist.append("1")
elif i == "T":
newlist.append("1")
elif i == "C":
newlist.append("1")
elif i == "G":
newlist.append("1")
elif i == "X":
newlist.append("1")
else:
newlist.append("0")
# print("".join(newlist))
# newlist = ["1" for i in eachline]
print("\t".join(newlist))
# b.write("".join(newlist)+"\n")
dz = eachline
else:
newlist = []
for i,j in zip(eachline,dz):
if i==j and i!="-":
newlist.append("1")
else:
newlist.append("0")
print("\t".join(newlist))