文章目录
- 性能测试
- JMeter
- 测试计划
- 模拟并发
- 结果分析
- 分布式
- 性能监控
- grafana
- Flux
- Prometheus
- 小结
性能测试
- 为什么做性能测试?主要是解决这些问题

- 什么是性能测试
- 模拟多个用户的操作,看对服务器性能的影响
- 指标
- TPS:transaction per second
- RT:响应时间
- 常见工具

JMeter
- 这个工具最常用
- 安装
- 下载,建议使用 5.2.1 版本,到archive找
- 解压,加入到环境变量或者直接切换到解压目录
- 还需要 Java 环境
- 启动(Windows)
- 图像界面:双击运行 jmeter.bat
- 命令行界面:
jmeter -n,Linux/Mac也是同样
测试计划
- 先在 Windows 使用图形界面创建及调试测试计划,再到 Linux 执行压测
- 因为直接在 Linux 创建计划那个界面有点问题
- 步骤,先在 Windows下操作
- 打开界面,Test Plan 里添加线程组
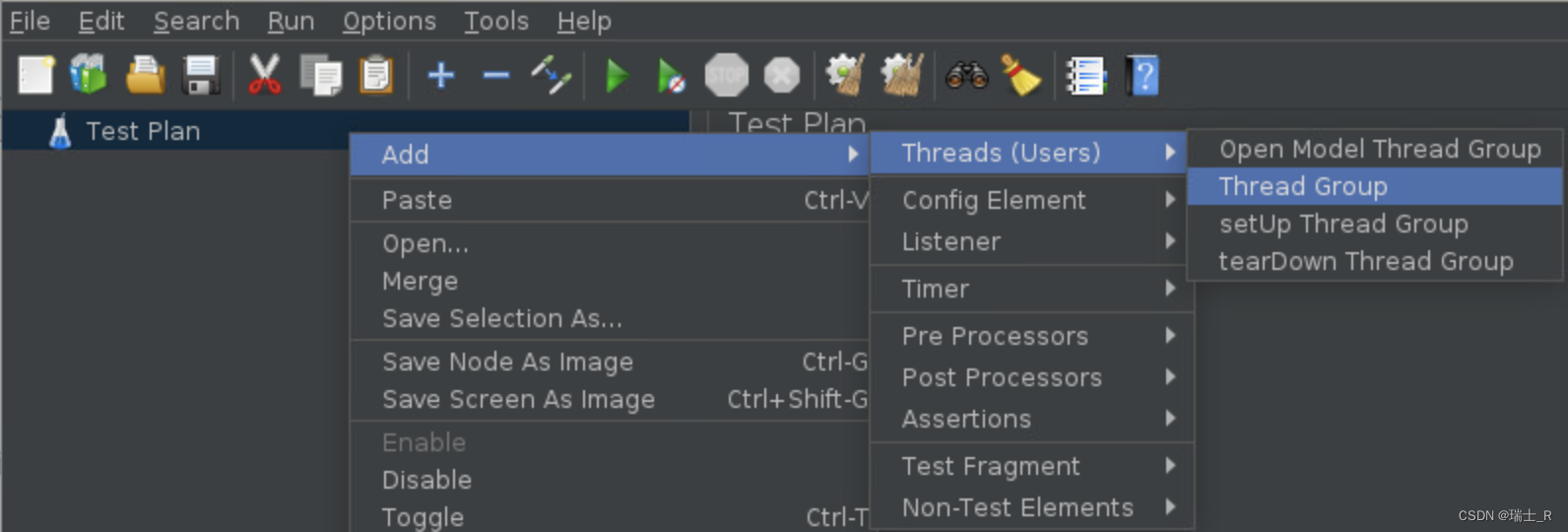
- 线程组中添加录制控制器

- Test Plan 里添加 Script Recorder,也就是和 Thread Group 并驾齐驱,一个过滤一个保存信息
- 设置网络代理
- 可以直接设置机器的网络> 代理,但这样会影响全局
- 使用浏览器插件:SwitchOmega,在Firefox的 extensions 中也能搜到
- Chrome 中可能有网络问题,可以在这里安装教程搜索安装

- new profile,设置完成需要。Apply Changes
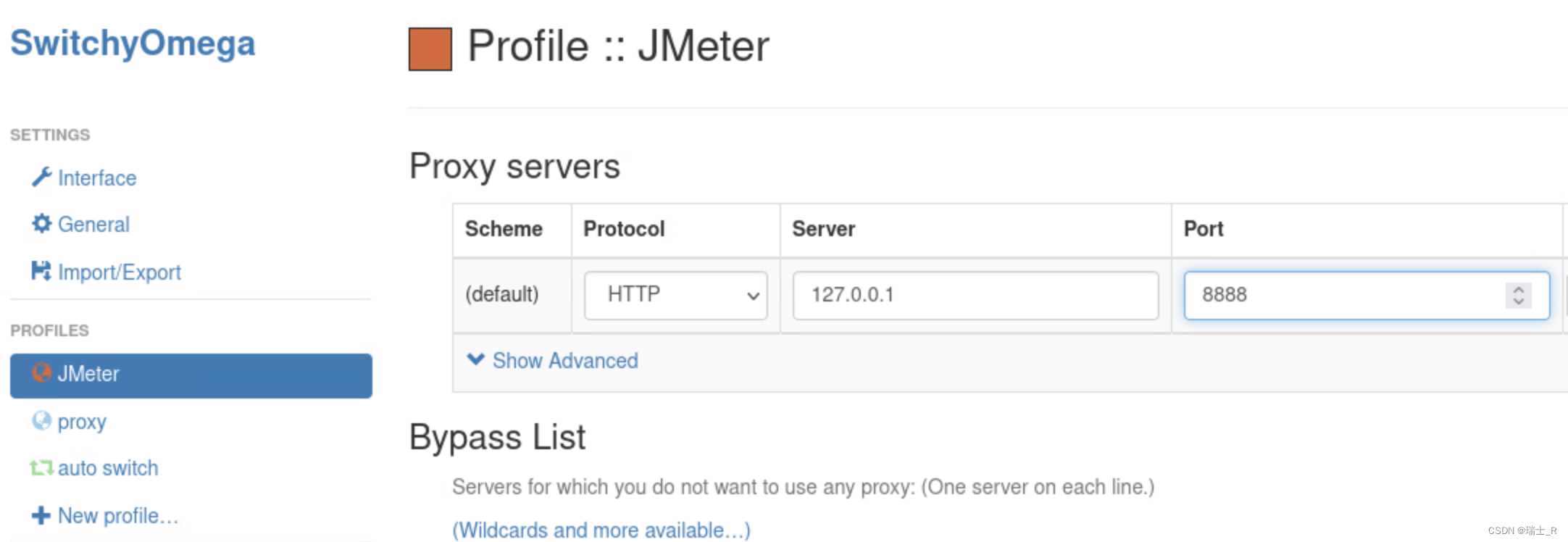
- 为什么设置代理呢?简单来说就是让访问链路经过我们设置的 JMeter 代理,才能抓包分析;具体原理自查
- 当然,设置浏览器代理意味着我们只能测 web 页面,一般非 web(URL) 提供的服务(比如直接运行本地脚本),只能转化为请求 URL 才能在这测(通过 web 服务请求本地脚本,再返回需要的数据,再解析 web 数据)
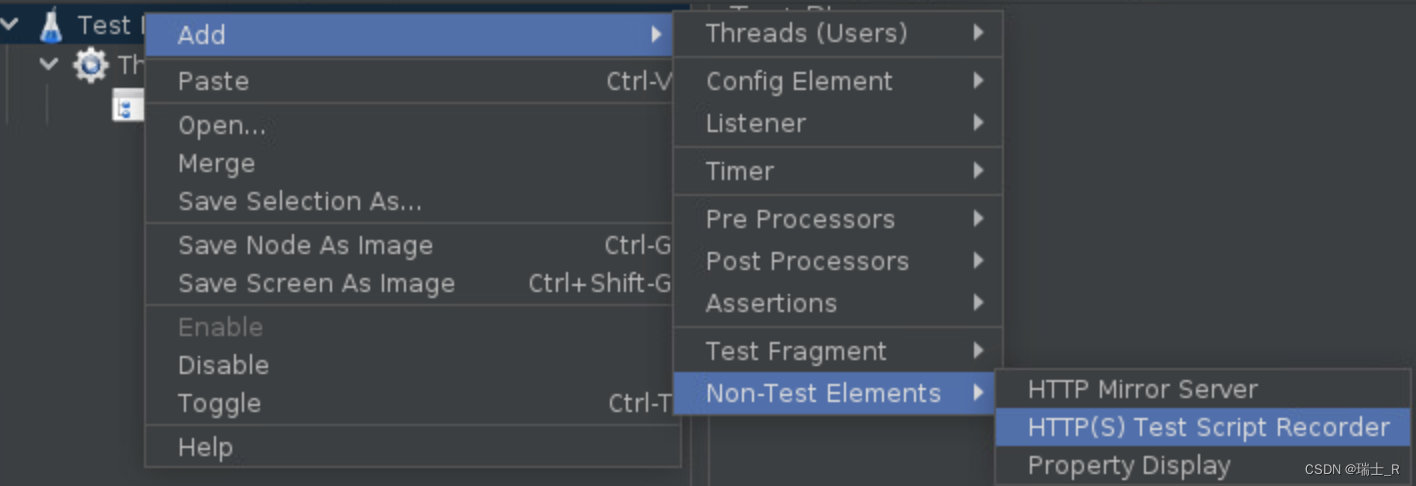
- 配置Script Recorder,点击 start
- 配置:其实就是这两个地方改一下,匹配要访问的网站,保存录制的位置
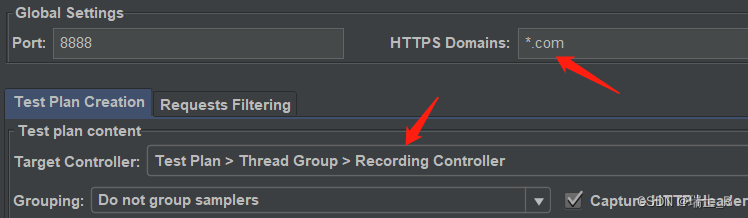
- start 提示安装证书
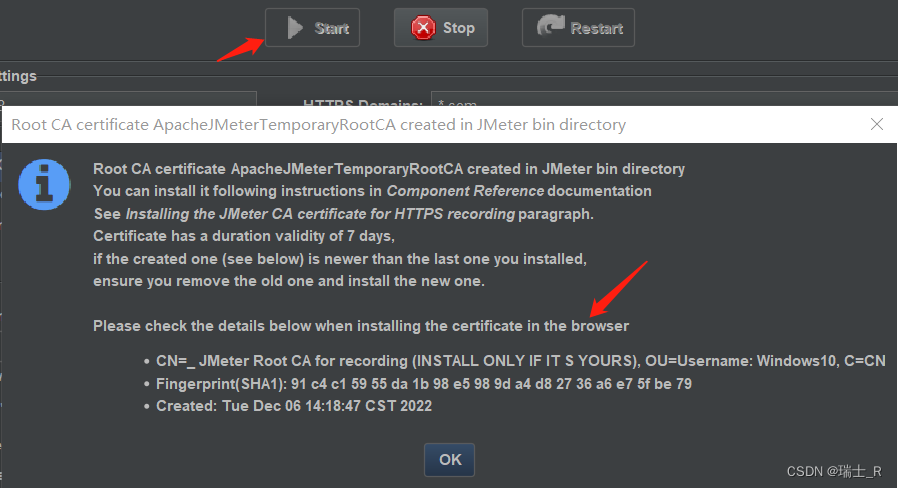
- 配置:其实就是这两个地方改一下,匹配要访问的网站,保存录制的位置
- 可以发现在 bin 目录下面出现了证书 ApacheJMeterTemporaryRootCA.crt,双击导入
- 注意:这里要选择 受信任 区域
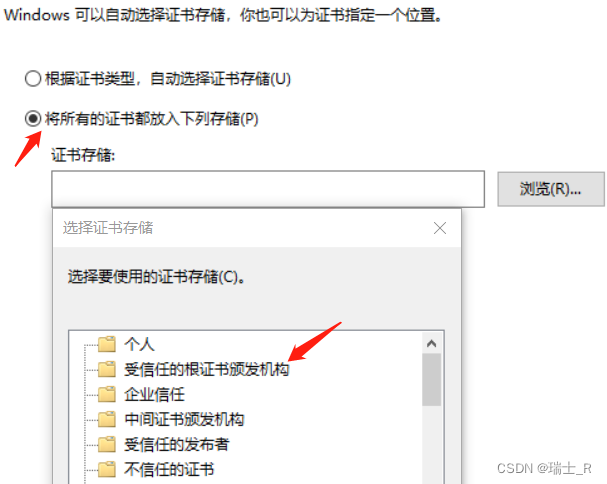
- 也可以在 浏览器> 隐私与安全 导入
- 注意:这里要选择 受信任 区域
- 此时可以看到抓的包的详细信息
- Record 录制,其实就是把所有的访问请求包抓取复制一下
- 而后就可以过滤包,获取我们需要的(要测试的)访问路径,进行后序测试
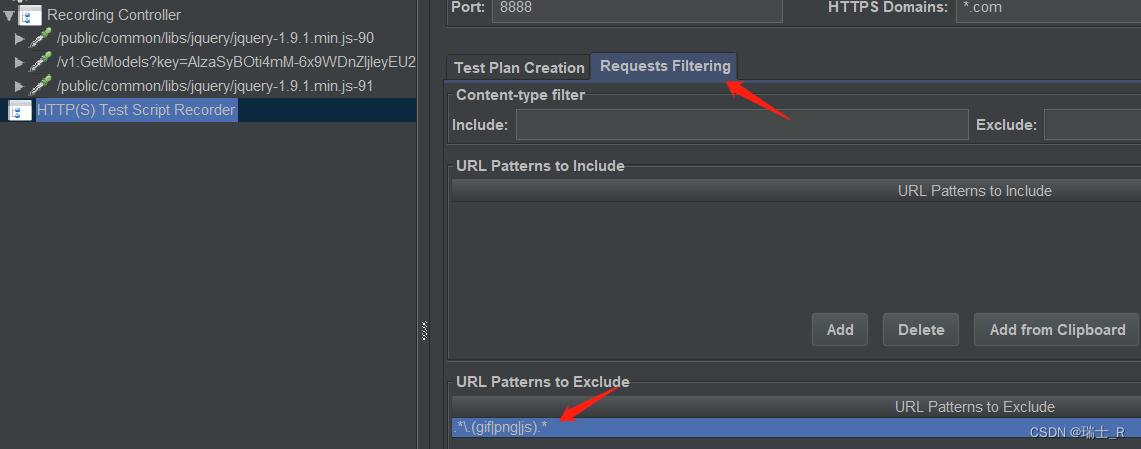
- 过滤请求路径(URL)
- 很多抓到的包我们并不需要,在 exclude 添加规则;可以看到左侧少了很多包
- 我们要测试的网站可能会访问其他网站,可以通过 include 限制只抓取我们的;例如我们只想访问 baidu.com
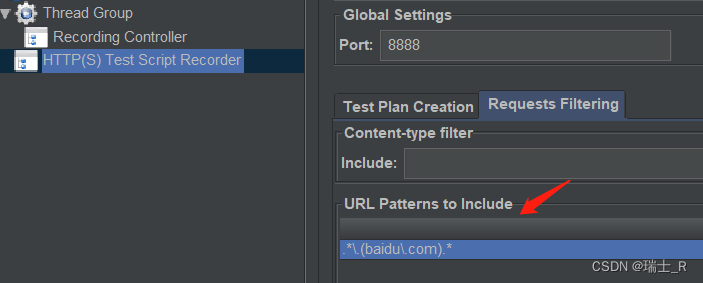
- 此时访问 bing.com,左侧空空如也~
- 很多抓到的包我们并不需要,在 exclude 添加规则;可以看到左侧少了很多包
- 得到了我们需要的URL,就可以禁用掉 Script Recorder
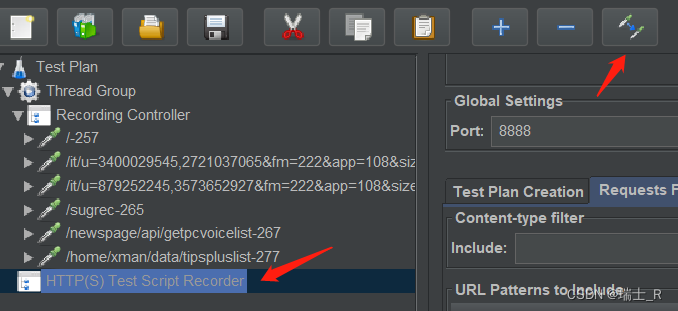
- 在 Thread Group > Listener 添加 View Results Tree,再次发送请求时,就可以在这看到结果
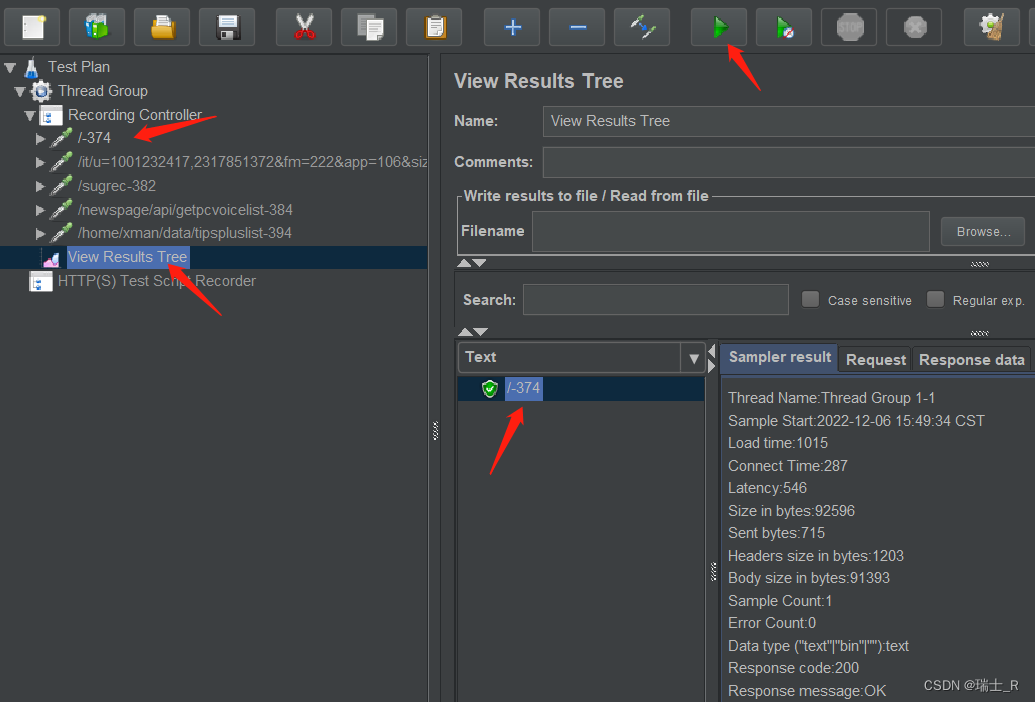
- 上面这是把其他的 toggle 了,不然点击 start 会全部请求并得到所有响应
- 打开界面,Test Plan 里添加线程组
- 以上便是使用 JMeter 录制的基操,目的是得到要测试的URL(录下来)
模拟并发
- JMeter 通过线程组(Thread Group)模拟多用户,所以 Test Plan 必须创建线程组
- 模拟多用户主要是压力测试,性能的衡量不止抗压能力,但却是最重要的指标
- 代表 1 秒钟模拟 500 个请求,执行一次
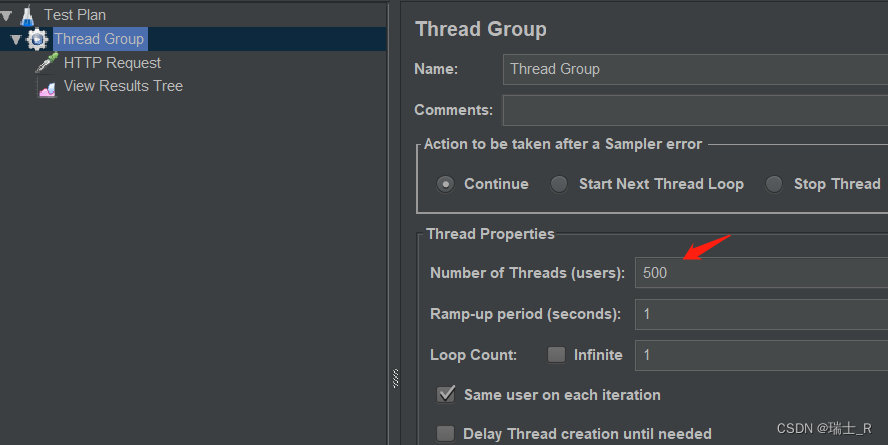
- 我们在下面创建 Request,
- server 我们在本地通过 python 模拟:
python -m http.server 80 - 所以,填本地内网 IP,端口 80
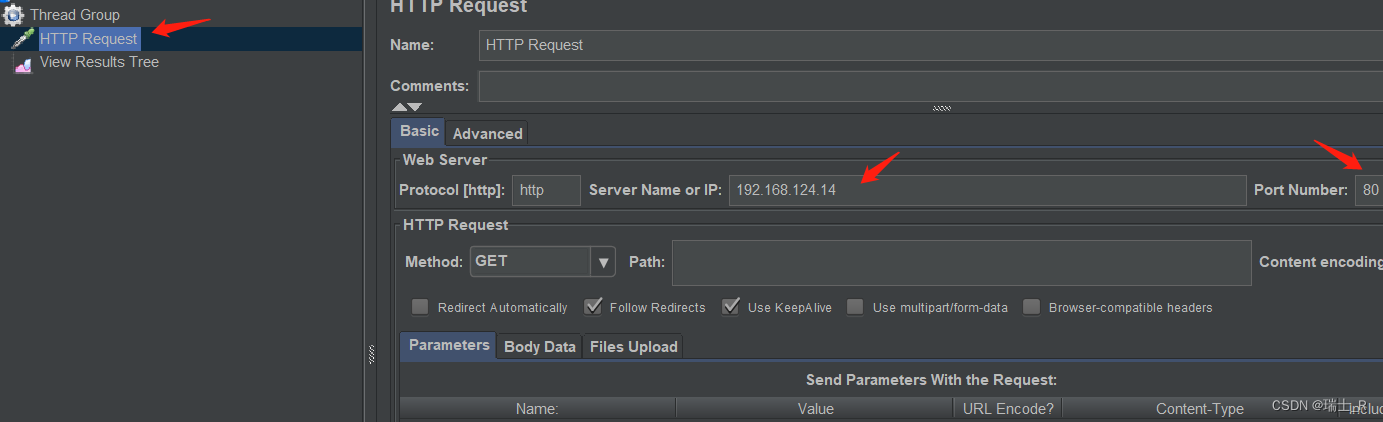
- start,命令行可以看到输出
- server 我们在本地通过 python 模拟:
- 线程(用户)数量由 JMeter 客户端的硬件性能决定,太大就会直接报错
- 硬件性能是一方面,也可以通过配置文件限制 VM 的内存使用范围(毕竟是个软件)
- 运行:
jconsole
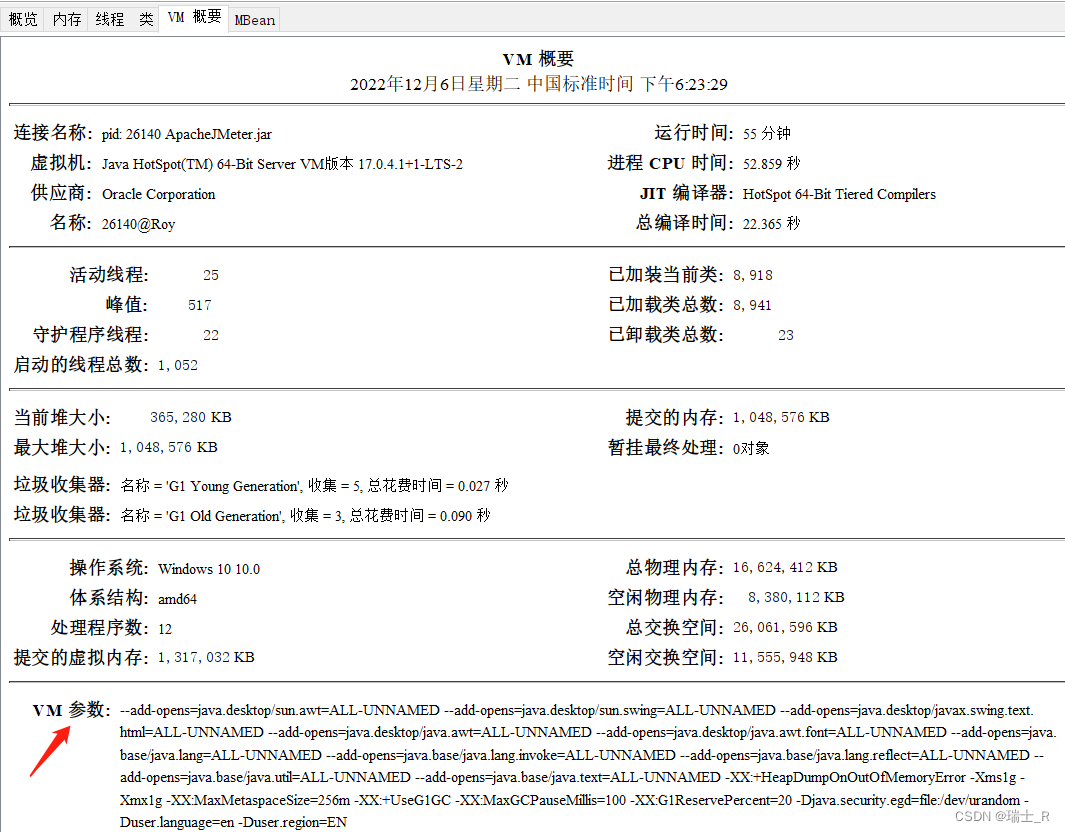
- 在哪配置呢?Linux 是 jmeter.sh 里
JVM_ARGS参数,Windows 是 jmeter.bat 里:

- 可以将 1g 改大一点
- 当然,还可以类似 pytest,设置 setup/teardown request
- View Results Tree 并不是必须的,因为请求了外部网站,不加看不到结果
- View Results Tree 并不是必须的,因为请求了外部网站,不加看不到结果
- 一般在待测服务器执行压测脚本还是远端发起请求(经过域名解析这些)?
结果分析
- 上面已经通过 View Results Tree 看到了请求的结果
- 界面上还有个 Browse,能把其他服务器上的压测结果拿过来看
- 有多种格式,支持 json,正则过滤等等
- 还有两种方式
- Aggregate Report 聚合报告
- Aggregate Report
- 各指标含义

- 本地启动服务,5个并发,平均响应时间14,还可以

- 但我们一般不使用图形界面,本身就会占用资源
- 在图形界面创建计划并保存,命令行运行:
jmeter -n -t aggregate.jmx -l test_http.jtl- 不使用图形界面
- 一般会保存成
.jtl报告 .jmx文件是 xml 格式,可以直接打开修改配置- 报告就保存到当前目录了,还是应该配置 jmeter 的环境变量
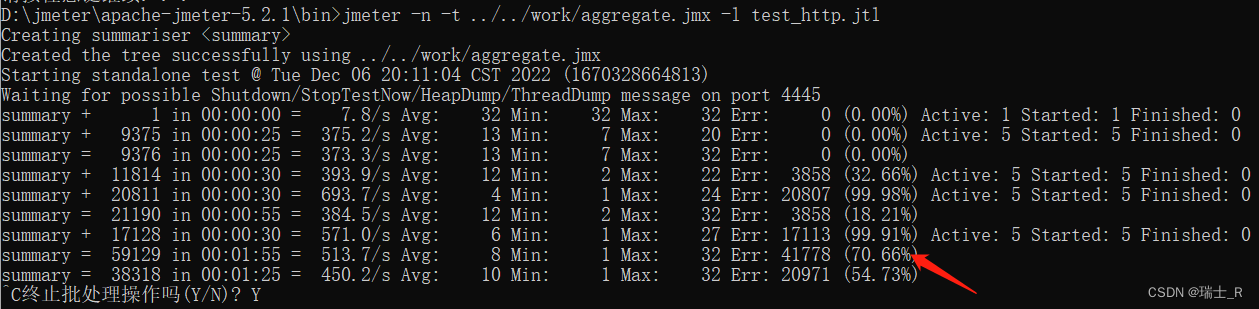
- 因为是通过 python 在本地开的服务,后面已经开始出错了;TPS 一直在 700 以下
- docker 创建 nginx 容器做服务器,测一下
- 创建容器
docker run --name nginx-load-test -p 88:80 -d nginx:1.17.9,我们映射到本地的 88 端口,和 python server 区别 - Windows上使用 docker 麻烦一些,Linux又不支持GUI界面,你可以买一台苹果~
- 更改 jmx(改访问的端口),再次启动测试,主要看 TPS,CPU 占用率(
docker stats nginx-load-test),平均响应时间 - docker 中的 ip 和本机内网 ip 一样吗?推荐文章
- 创建容器
- 各指标含义
分布式
- 为了突破单机的性能瓶颈,我们一般用分布式集群进行压测,确保有足够压力
- 负载机(slaver)部署步骤
- 解压安装 jmeter 包
- 修改:bin/jmeter.properties
- 查找并设置
server.rmi.ssl.disable=true不使用 SSL
- 查找并设置
- 修改:bin/system.properties
- 添加:
java.rmi.server.hostname=192.168.100.99本机内网 ip
- 添加:
- 启动:Windows中就是双击
jmeter-server.bat

- 同样的,其他 slave 机器也这样设置,我这里另一台 Linux 机器的 ip 为
192.168.109.131 - 启动:bin/jmeter-server
- 控制机(controller)部署
- 不使用 SSL
- 修改 bin/jmeter.properties
# Remote Hosts - comma delimited remote_hosts=192.168.109.131:1099,192.168.109.132 - 启动:jmeter / jmeter.sh (GUI 方式)
- 主从关系
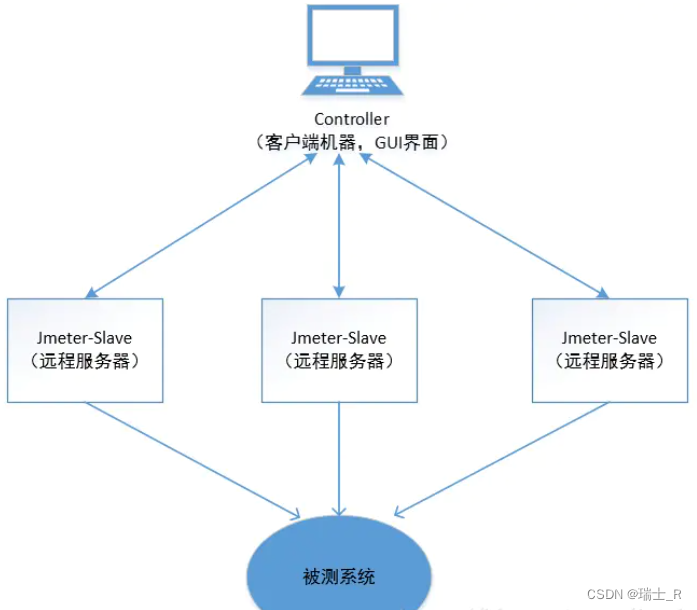
- 一般不会把 controller 配置成 slave,本身负载就比较大,单独分开比较好
- 在 controller 远程启动 slave 干活
-
创建线程组,配置要请求的地址
-
Remote Start,使用集群机器向被测机器发起请求,如果是 Start All 每个 slave 都会执行一遍计划(request/record controller)
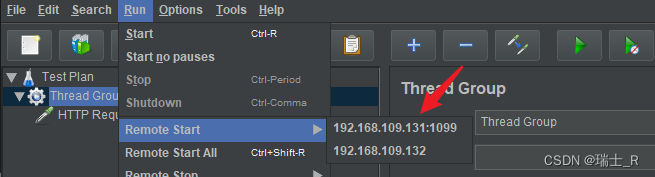
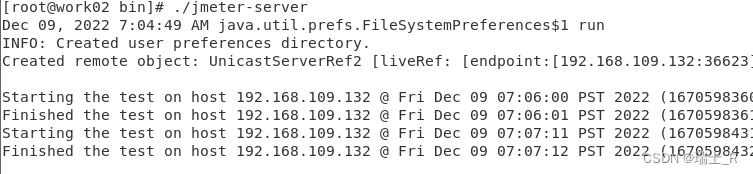
-
1099 是 slave 的默认端口,可以不用指定,也可以在 jmeter.properties 指定
server_port=1099 -
也许会主从连接失败,一般是因为忘了关闭 slave 的防火墙
systemctl stop firewalld.service
-
- 当然,也可以在 controller 使用命令行启动
- 执行:
jmeter -n -t fenbushi.jmx -l fenbushi.jtl -R 192.168.109.131:1099,192.168.109.132
- 执行:
性能监控
- 数据展示平台实时展示压测数据
- 这里用到两个工具:influxdb 和 grafana
- 比较方便的使用方法是在 docker 里启动,但对Windows不太友好,使用 Mac 作为主机的同学可以直接用 docker
- 这里推荐一种 Windows 上安装的方法
- 下载地址:grafana-9.3.1 influxdb-2.5.1
- grafana 是图形展示,能够和 influxdb 无缝对接
- influxdb
-
influxdb 是数据源,可以理解成是一种时间序列数据库,解压后在 cmd 运行
influxd,从浏览器来到图形界面

-
有三种操作数据库的方式

UI 就是图形界面啦,在浏览器操作
CLI (command line interface) 单独提供的命令行工具,must be downloaded and installed separately.
HTTP API 也就是通过 Client Libraries (开发语言操作) UI界面有教程,或者是直接使用 cURL 之类的工具调用API -
先看下
HTTP API,选一种你熟悉的语言,跟着教程走一遍,官方文档- cmd 能看到一些 log,最好是直接在 pycharm 执行代码,方便调试
- 建议看详细教程,先不要到 Cloud 上搞,容易受网络影响
- cmd 能看到一些 log,最好是直接在 pycharm 执行代码,方便调试
-
核心概念是 bucket,所以的数据都存在这里,类似 SQL 数据表;完整代码:
import influxdb_client, os, time from influxdb_client import InfluxDBClient, Point, WritePrecision from influxdb_client.client.write_api import SYNCHRONOUS # InfluxDB Cloud uses Tokens to authenticate API access. # We've created an all-access token for you for this set up process. # token = os.environ.get("INFLUXDB_TOKEN") token = "xxx-xxx" # 用你自己的token print(token) org = "Roy" # url = "https://us-west-2-1.aws.cloud2.influxdata.com/" url = "http://localhost:8086" # initialize the token, organization info, and server url # that are needed to set up the initial connection to InfluxDB. # The client connection is then established with the InfluxDBClient initialization. client = influxdb_client.InfluxDBClient(url=url, token=token, org=org) bucket = "first_bucket" # 得到API,执行写操作 write_api = client.write_api(write_options=SYNCHRONOUS) p = influxdb_client.Point("my_measurement").tag("location", "Prague").field("temperature", 25.3) write_api.write(bucket=bucket, org=org, record=p) # 先执行上面的部分,写入数据到 bucket if __name__ == '__main__': # 查询 query_api = client.query_api() # 类似SQL语句,这里叫做 flux,语法类似 # The query client sends the Flux query to InfluxDB # and returns a Flux object with a table structure. query = 'from(bucket:"first_bucket")\ |> range(start: -10m)\ |> filter(fn:(r) => r._measurement == "my_measurement")\ |> filter(fn:(r) => r.location == "Prague")\ |> filter(fn:(r) => r._field == "temperature")' result = query_api.query(org=org, query=query) results = [] for table in result: for record in table.records: results.append((record.get_field(), record.get_value())) print(results) # [(temperature, 25.3)]
-
- grafana
- 官方文档
- 启动:安装后的 bin 文件夹里
grafana-server.exe访问http://localhost:3000
grafana
- 配置数据源(Data Source)
- grafana 配置使用 influxdb 数据源,详细文档
- 如果都是用 docker,有容器的配置方法,这里直接使用刚创建的 bucket
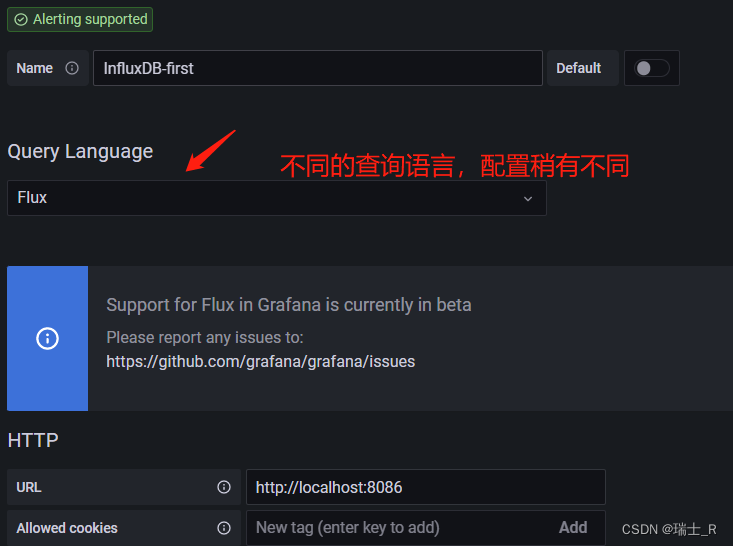
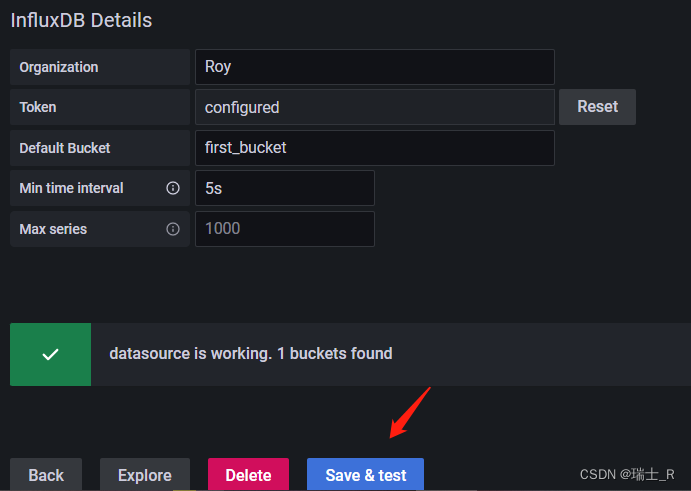
- 详细介绍都在文档里,这里也有;上面使用的是 Configure Flux 方式
- 这里推荐学习
Flux,因为 influxdb 用的是 OSS v2.5 版本,不再使用 databases 的概念了,即使用 SQL-like 方式,也是转化为 bucket - Flux 基础语法
- 使用 Flux 向 influxdb 写数据
- 使用 Flux 查询 influxdb 中的数据
- Flux 是一门数据库语言,可以依赖平台(数据源)直接运行其脚本,比如在 influxdb 上
- 也可以直接通过 API 执行 Flux 语句,上面给出了 python 的例子
- influxdb 提供了直接对接第三方数据的接口,比如 jmeter 的数据直接写入到 influxdb (在 jmeter 中使用后端监听器 backend listener)
- grafana 配置使用 influxdb 数据源,详细文档
- 配置仪表盘(Dashboard)
- 这里重点看数据怎么展示,官方文档,说的很详细
- You can create the perfect dashboard for your need. Each panel can interact with data from any configured Grafana data source.
- Dashboard snapshots are static. 就是说如果更新了查询语句,需要 update snapshot
- Dashboard 的界面介绍
- 创建仪表盘,文档说的很详细,但是对于 jmeter,grafana 有对应的模板,我们选择这个
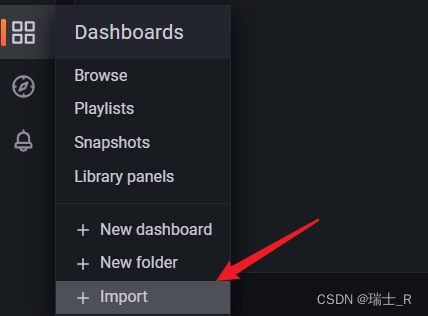
- 直接把地址粘贴过来 Load
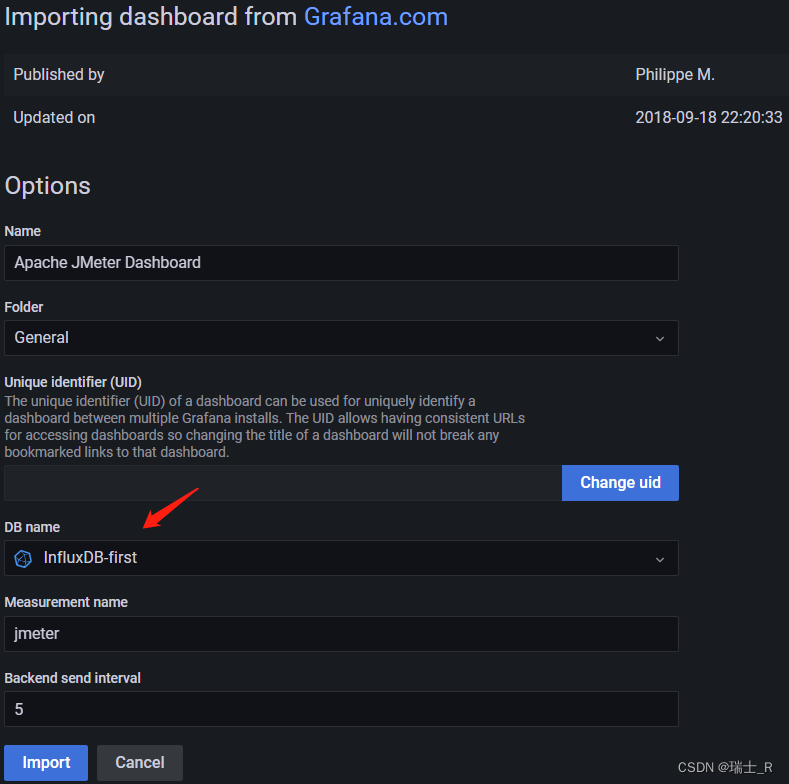
- 这个 Measurement name 等价于 MySQL 中 table,指代数据表,这里默认 jmeter
- import 之后
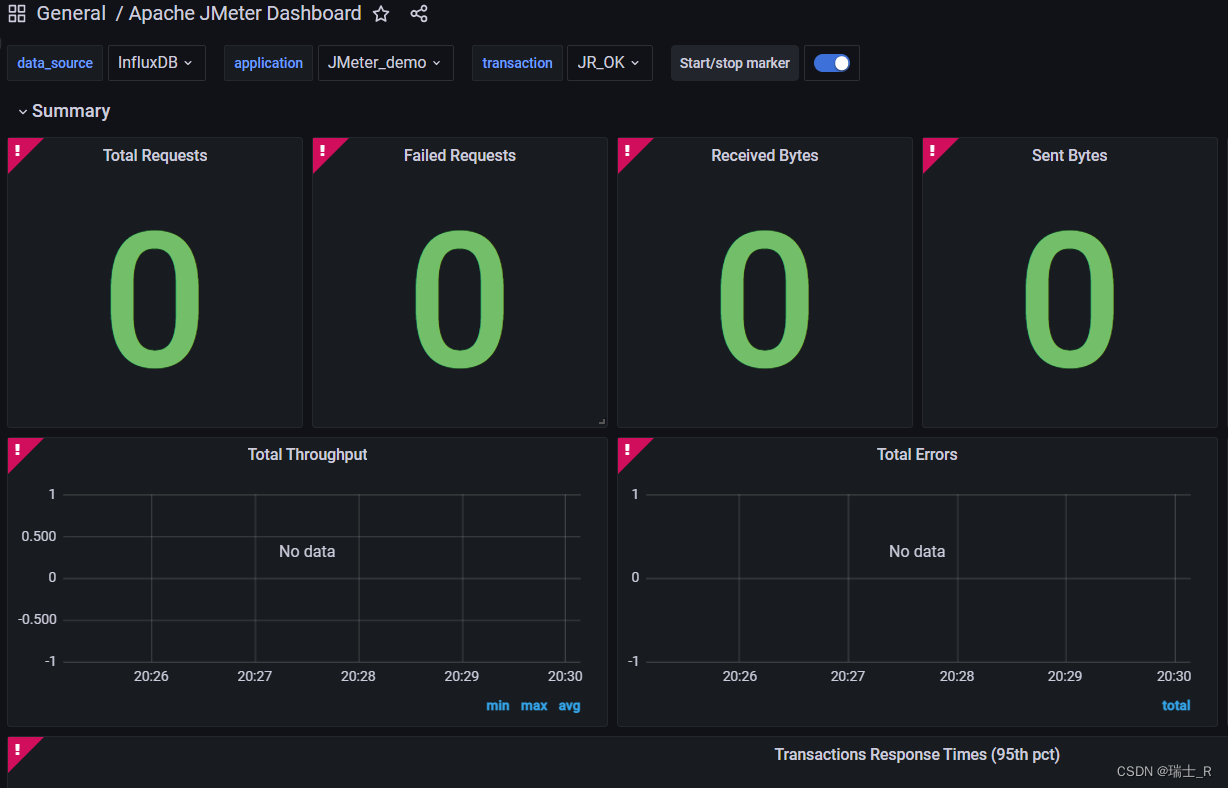
- 测试
- 上面在尽力说清楚如何把保存测试数据及展示数据的两个工具串联起来
- 接下来启动 jmeter,直接配置后端监听器为 influxdb,数据给到 influxdb 并在 grafana 展示一把
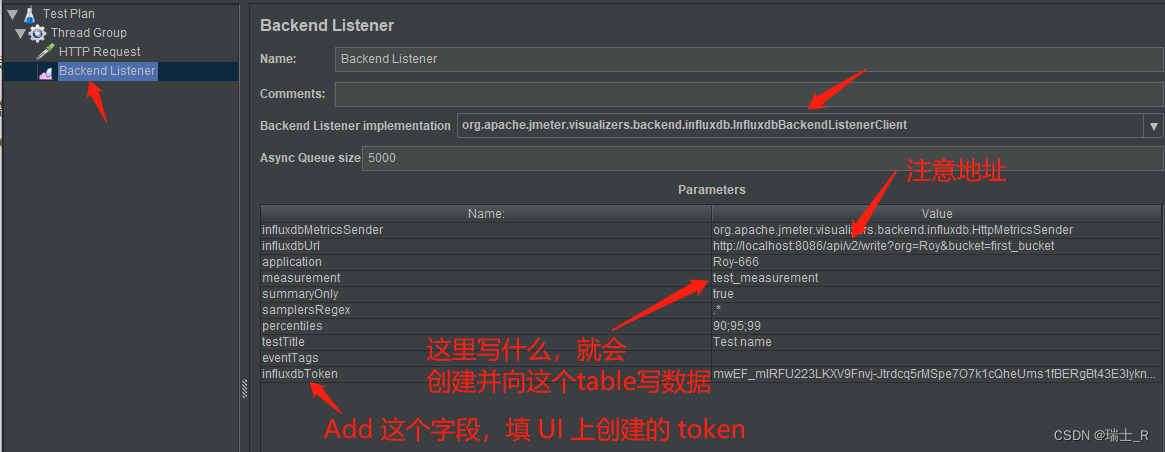
- 数据是给到了,但是没在 grafana 显示,添加 bucket 没有问题,为什么不显示呢?
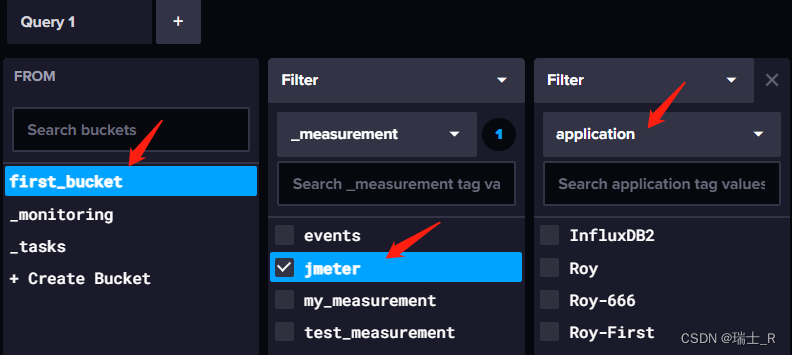
- grafana 和 influxdb 是通的,influxdb 和 jmeter 是通的,那问题只能出在显示这里了,看到 Dashboard 的那堆感叹号了吗?换一个 Dashboard 就完美了

- 我们可以在右上角的 settings 编辑这个模板,能看到它的查询语句
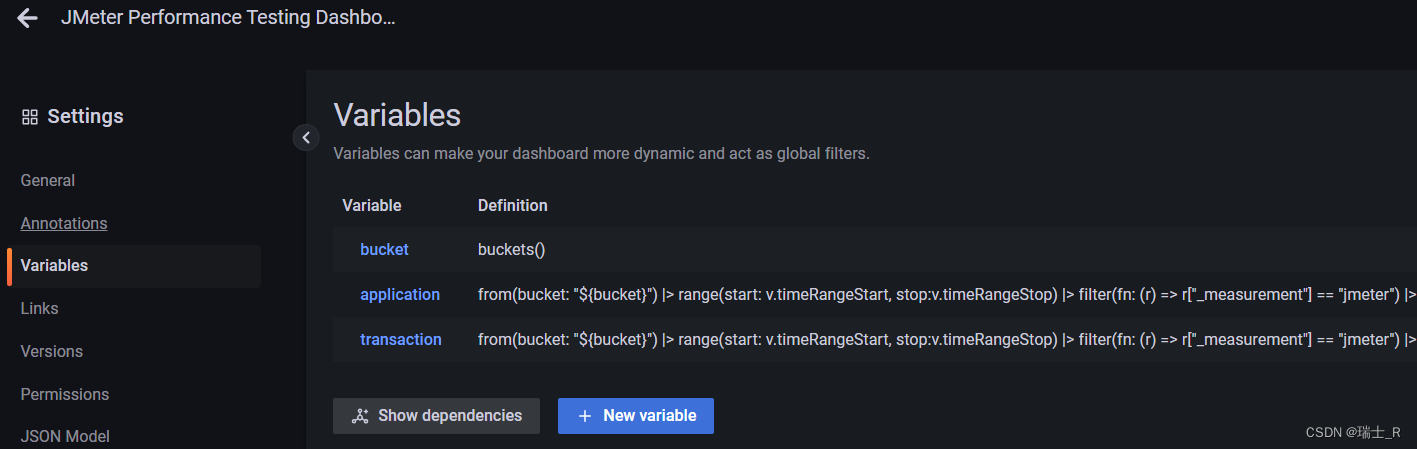
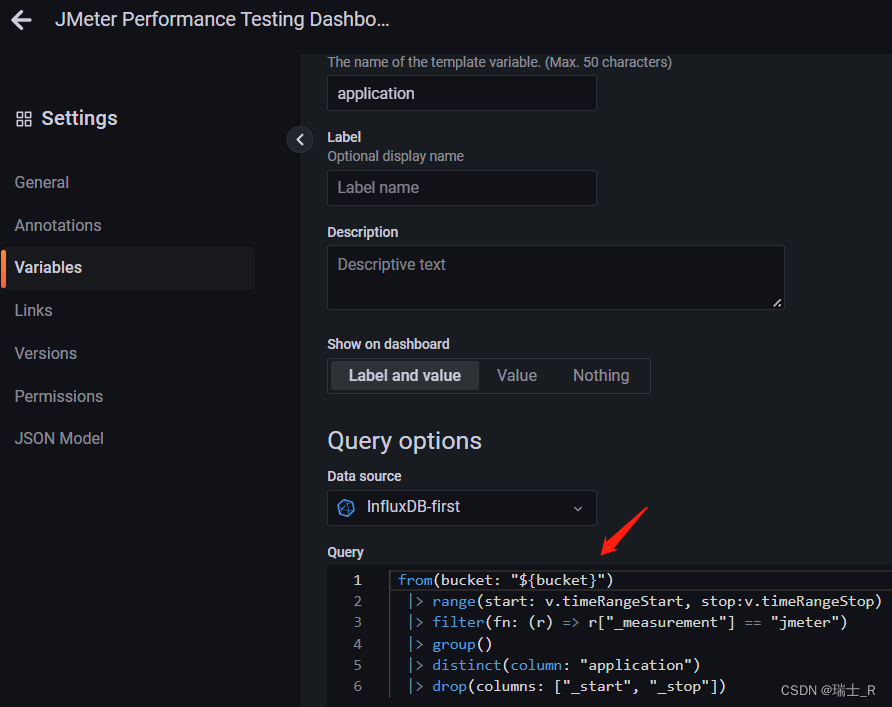
- Q&A:这里过滤查询 jmeter 表(measurement)
- 但从上面的截图可以看到,jmeter 下面有4个application,但我这里只有两个
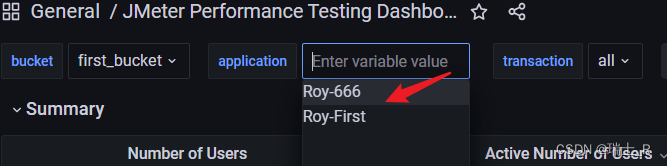
- 分析:之前使用 Telegraf 向 bucket 写数据,虽然是同一个数据库(bucket),但这个插件是运行在 docker 中的,这种情况下向 jmeter 表中写了前两个
application
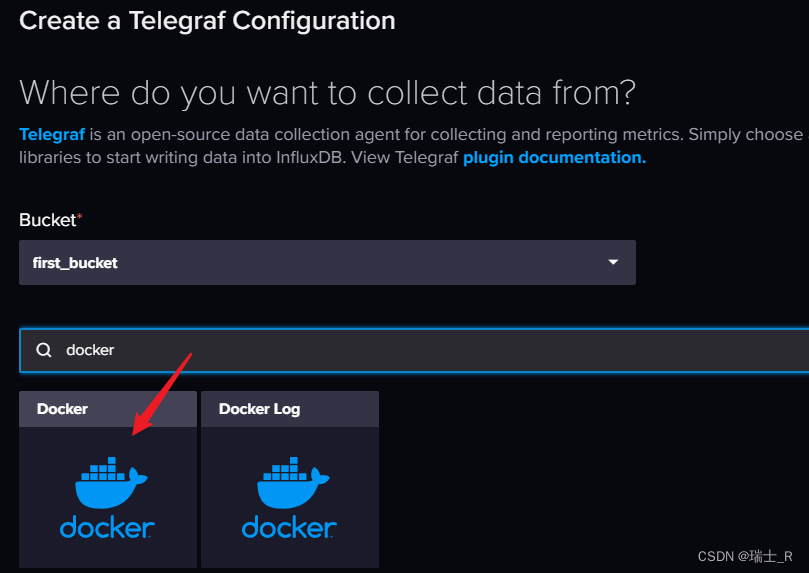
- 也就是同一个库的同一个表,但有两个 application 在 docker 中,不允许访问了
- 想换个专门的 Dashboard 展示这部分,创建 telegraf 的时候也会给一个 token,使用这个token 配置Data Soource,但识别不出来这个 bucket
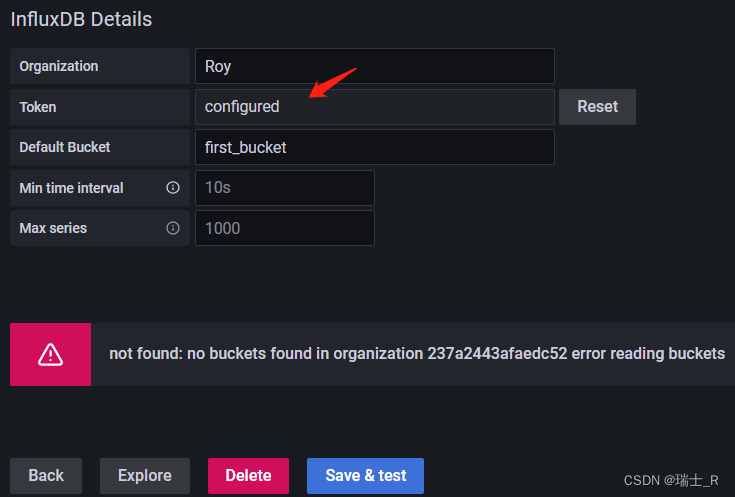
- 原因是 telegraf 给的这个 token 权限不足,但好像无法修改,是官方设定的,可能对于 data collector 是必要的
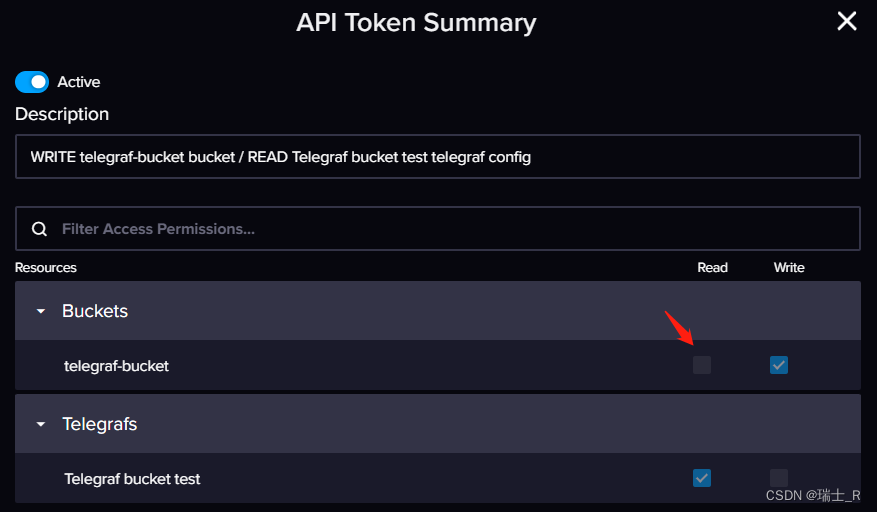
- 一方面是 docker 隔离,必须分开获取,一方面又 token 权限不足,导致无法展示~
- 但从上面的截图可以看到,jmeter 下面有4个application,但我这里只有两个
Flux
- 上面接触了几个概念
- bucket:相当于数据库 database
- measurem:相当于数据表 table
- 但还有一些,包括 Flux syntax 的含义都不熟悉,有点本末倒置
- 后续的 CURD 都是通过 Flux
- 在这里会结合文档一探究竟
- 实战部分可以学以致用
Prometheus
- 上面使用 influxdb 存储我们通过 jmeter 测试服务器得到的数据
- 这里介绍一个工具,能实时获取到服务器各种性能数据,再用 grafana 展示
- 压测展示的是性能数据,比如平均响应时间等
- Prometheus 是监控硬件状态,CPU,内存,磁盘,温度等信息
- 安装
- 下载地址,我这里还是 Windows
- 建议使用 docker,注意要和前面的 grafana 使用同一个 docker network
- 还要下载
node_exporter,这个是真正监控主机的,在 Linux 上直接解压运行 - 但是没有 Windows 的 node_exporter,好在社区提供了 windows_exporter
- Prometheus 和 node_exporter 的关系:exporter 会后台运行,监控主机的状态,P 会去抓取 e 收集到的信息
- 启动
- 直接运行 exporter,访问
http://localhost:9182/,可以在 Metrics 看到信息(在哪运行就是监听哪个机器) - 修改 P 的配置文件
prometheus.yml,写上运行 exporter 的 IP:portscrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config. - job_name: "prometheus" # metrics_path defaults to '/metrics' # scheme defaults to 'http'. scrape_interval: 5s metrics_path: "/metrics" static_configs: - targets: ["localhost:9182"] - 运行 prometheus.exe,访问
http://localhost:9090/,在 Targets 能看到
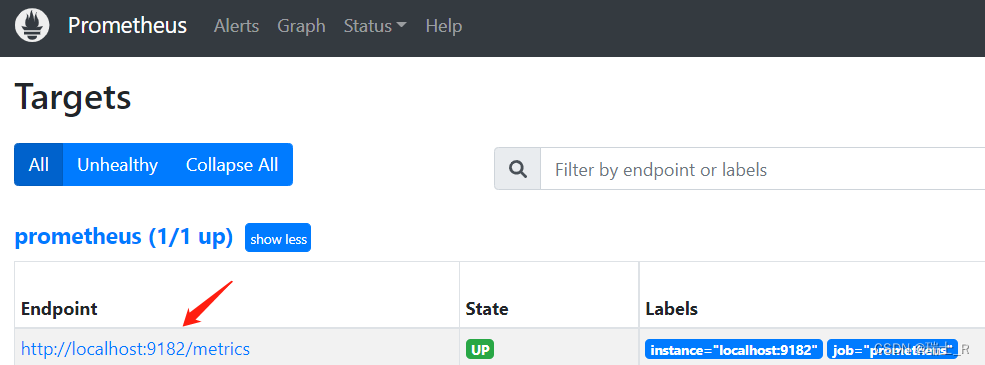
- 直接运行 exporter,访问
- 展示
- 在 grafana 添加数据源
- 配置 Dashboard,可以搜索使用,配置数据源时也有推荐(就用推荐的,比较新)
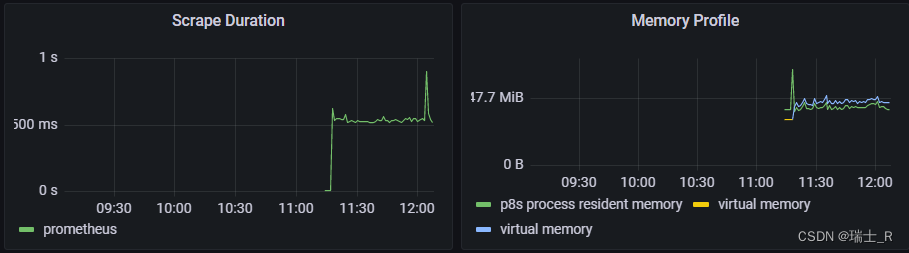
- 可以在命令行启动 python 的服务器并访问,被监控的 Linux 机器可以配置个 NGINX 服务器,然后通过 jmeter 疯狂访问,看看 Dashboard
- 在 grafana 添加数据源
小结
- 这篇内容比较多,但属于傻瓜式教程,我们围绕 jmeter,分别引入了数据收集,数据展示的多种工具
- 下一篇会记录《电商系统压测实战》的过程,结合具体业务需求,开展测试



![【无需注册账号】只需两步, Ai Studio上也可以玩[ChatGPT]了](https://img-blog.csdnimg.cn/img_convert/b92a0899d329d252c5d708cc0a1df9e1.png)



![[附源码]Python计算机毕业设计SSM基于的校园失物招领平台(程序+LW)](https://img-blog.csdnimg.cn/eecb39d791844f34881801cb954f4124.png)




![[附源码]Python计算机毕业设计SSM基于的校园卡管理系统(程序+LW)](https://img-blog.csdnimg.cn/5dfcdd1a965e49f4bbd674a5b0639a12.png)
![[附源码]Python计算机毕业设计SSM基于的小型房屋租赁平台(程序+LW)](https://img-blog.csdnimg.cn/bae51dfea4914354a450e01f16af2e0c.png)

