一、介绍
正则表达式通常被用来检索匹配某种模式(规律)的文本
日常文本检索,如果单纯检索某个数字,字母,或者单词匹配出来的结果较多,而面对目标文件内容较大的时,我们也不可能肉眼对检索出来的一行行里去找到自己想要的文本,所以这时候使用正则就能大大减少我们检索文本信息的所花费的时间。
常用的类型有:基础正则(BRE)和扩展正则(ERE)
二、语法
1、普通字符
判断一个长度为1的字符串是否是数字
使用代码就是
if (num==“0” or num==“1” or ...num==“9”) /*麻烦的要死*/
换成正则,就可以写成 [0123456789]
"[]"表示一个字符组,代表一位字符,只要匹配的字符串里有方括号里任何一位字符就算匹配成功
当然这样写还是有点长度,如果引用多次这个表达式,文本也会显得臃肿,
所以书写上还可进一步简化
[0-9] /*连续的就可以用-加上起始字符和终止字符*/
这样轻易就能看出其意思,书写起来也方便
同样字母就是[a-z]、[A-Z],比如我要匹配xyz中一个字符就是[xyz]
最常见的匹配输入是yes或者Yes ,那表达式就可以是 [Yy]es
2、字符转义
针对表示特殊意义的字符,去其本身字面字符
就单纯字面意思,学习编码语言也学过,不再赘述,通用办法就是使用“\"进行转义
例如刚我们说的[0-9]表示就是0到9之间的任何一个数字字符,那我们就是想要字面字符的意思,表示”0“,”-“,”9“中的一个字符,那就是[0\-9]
3、元字符
在正则中有特殊意义的字符
常见元字符如下:
\ 将下一个字符标记为特殊字符按或字面指,如n匹配字符,\n匹配换行符
^ 匹配输入的开始部分 ,如以a开头的字符串,^a......
$ 匹配输入的结束部分,如以z结尾的字符串,......z$
* 匹配零次或多次前面的字符,如zo*匹配z、zo、zoo
+ 匹配一次或多次前面的字符,如zo+匹配zo、zoo
?匹配零次或一次前面的字符,如z?oo 匹配oo、zoo
. 匹配单个字符,换行符除外
x|y 匹配x或y,如,z|zoo 匹配z、zoo,(z|w)oo 匹配zoo、woo
{n} n是一个非负整数,精确匹配c次前面的字符,用法与*,+,?类似
{n,} 至少匹配n次前面的字符
{n,m} 至少匹配n次且至少匹配m次前面的字符
[xyz] 匹配下x,y,z中任一个字符
[^xyz] 匹配任何一个不是x,y,z的字符,同理还有[a-z]、[^a-z]
\b 匹配某个单词边界,即某个单词和空格之间的位置,如\bsa匹配he said 里的sa
\B 匹配非单词边界,如ea*r\B匹配never early中的ear
\d 匹配数字字符,等价于[0-9]
\D 匹配非数字字符
\f 匹配换页字符
\n 匹配换行符
\r 匹配回车字符
\s 匹配任何空白字符,包含空个、制表符、换页字符等
\S 匹配任何非空白字符
\t 匹配跳进字符
\v 匹配垂直跳进字符
\w 匹配任何单词字符,包含下划线,类似于[a-zA-Z0-9_]
\W 匹配任何非单词字符,类似于[^a-zA-Z0-9_]
4、限定符
指定输入中必须存在字符、组或字符类的多少个实例才能找到匹配项,可以理解为次数,如上文讲述到的{2}匹配前面字符2次,常见限定符有:*、+、?、{n}、{n,}、{n,m}
5、定位符
定位符能够将正则表达式固定到行尾或行首,用来描述字符串或单词的边界,常见定位符有:^、$、\b、\B
这里讲两个关于边界的定位符例子:
"area bare arena mare" 使用正则”\bare\w*\b" 去匹配,会得到“area" ,"arena" ,”\bare\w*\b" 以“边界+以are开头的单词+边界”去匹配
“equity queen equip acquaint quiet” 使用正则“\Bqu\w+"去匹配,会得到”equity“,”quip“,”quaint “,以qu开头非边界的单词
6、分组构造
正则表达式的子表达式,用于捕获输入字符串的子字符串,使用(子表达式)表示,有点像数据基础运算里括号的意思,使用括号将多个元字符表达式组合成一个对象,并且可以针对这个对象使用限定符和定位符。
例
“He said that that was the correct answer." 使用表达式”(\w+)\s(\w+)\W"匹配=>"He said ","that that ","was the ","correct answer."
/*单词+空格+单词+非单词字符*/
7、匹配模式
匹配的时候使用的规则,常见有:不区分大小写模式,单行模式,多行模式。
单行模式(点号通配)改变元字符"."的匹配模式,“."默认匹配所有字符,但不包括换行符"\n",而单行模式下"."可以匹配任何字符。
多行模式改变的是"^"和"$"的匹配模式,默认模式下 "^"和"$"匹配的是整个字符串的起始位置和结束位置,而在多行模式,它们会匹配字符串内部某一行文本的起始位置和结束位置。
/*多行的字符串即内包含"r""\n"的字符串*/\
三、基础/扩展正则的常见元字符
基础正则表达式:"^","$",".","*","\","[abc]","[^abc]","[a-d]"
再加上一些特殊字符匹配特定类型的字符:
[[:alpha:]] 匹配任何字母字符,无论大小写
[[:alnum:]] 匹配任何字符和数字字符
[[:blank:]] 匹配空格或制表符
[[:digit:]] 匹配0-9之间的数字
[[:lower:]] 匹配任意小写的字母字符
[[:upper:]] 匹配任意大写的字母字符
[[:print:]] 匹配任意可打印的字符
[[:punct:]] 匹配任意标点符号
[[:space:]] 匹配任意空白字符
扩展正则表达式:x|y,+,?,(pattrn),{n,m}
四、正则表达式的使用
1、grep命令
语法:grep+正则表达式+文件名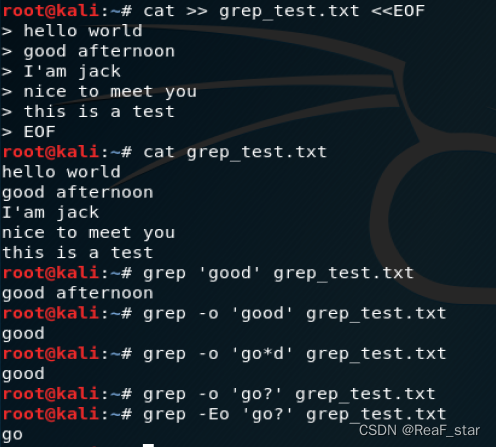
grep -o 仅展示捕获到的内容
grep -E 使用扩展正则表达式去捕获
2、sed命令
语法 sed -n '/正则表达式/p'
-n 参数使sed命令只显示匹配命中的一行
p :打印,亦即将某个选择的数据印出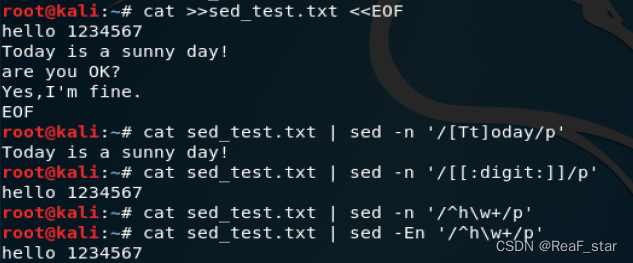
3、gawk命令
语法:gawk '/正则表达式/{print $0}'
正则范围:为扩展正则表达式
$0 代表整个文本
$N 代表文本行中的第N个数据字段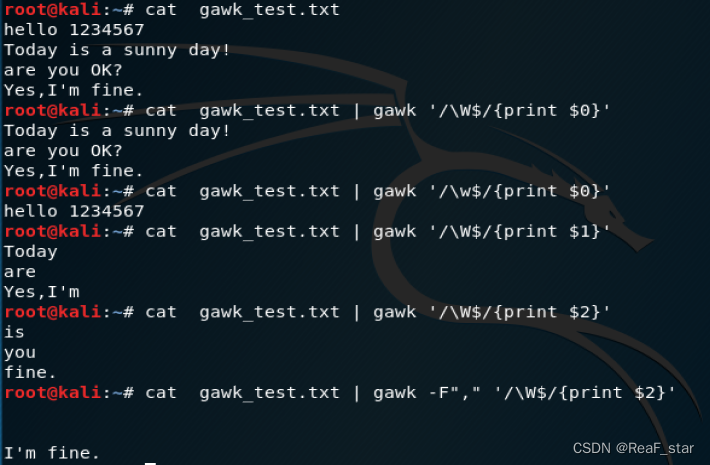
五、生活中常用的正则表达式
1、账号是否合法(5-16字节)
^[a-zA-Z]\w{4,16}$
2、身份证号码
^[1-9]\d{5}[1|2]\d{3}((0\d)|1[0-2])([0-2]\d|3[0-1])\d{3}[0-9Xx]$
3、手机号码
^1([358]\d|4[579]|66|7[0135678]|9[89])\d{8}$
4、IP地址
((25[0-5]|2[0-4]\d|((1\d{2})|([1-9]?\d)))\.){3}(25[0-5]|2[0-4]\d|((1\d{2})|([1-9]?\d)))
5、email地址
^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$
#该文章为日常学习所记录,若有不合理地方,欢迎指教,谢谢