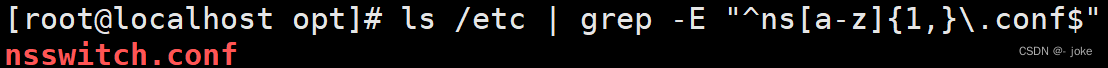文本处理有三剑客:grep sed awk
通配符:只能匹配文件名与目录名,不能匹配文件的内容
*匹配任意一个或者多个字符
?匹配任意一个字符(就是匹配单个字符)
[ ] 匹配范围内的任意单个字符
正则表达式:有一类特殊字符以及文本字符所编写的一种模式,用来处理文本当中的内容,其中的一些字符不表示字符的字面含义,表示控制或者通配的功能
基本正则表达式
字符匹配,元字符
. 匹配任意的单个字符,可以是一个汉字
\表示转义符,\.就是一个点
()括号表示分组的意思
\(\),就是括号
[ ] 匹配指定范围内的任意单个字符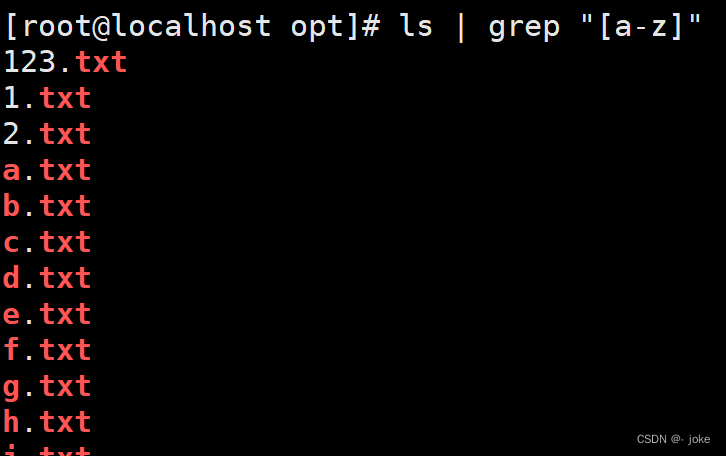


[^]取反,指定范围之外的

[[:space:]]包含空格,tab键,换行的空格,回车的空格
[[:blank:]] 空白字符(空格和tab制表符)
通配符不能完全匹配大小写, 正则可以
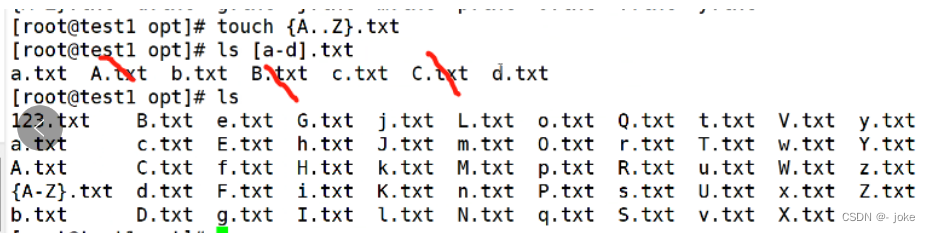
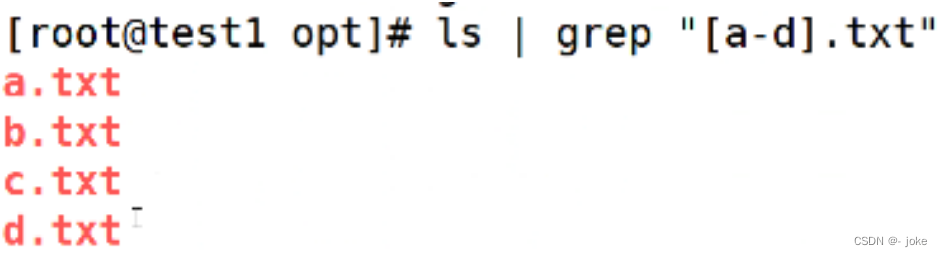
![]()
表示匹配不是a.txt .是或者 z.txt的文件(除了不匹配a或者z,其他都匹配)
正则表达式中表示次数的表达式
*匹配前面的字符任意次,0次也行,无数次也行,有多少匹配多少,没有也行
 .*匹配任意长度的字符,至少要有一次,不包括0次
.*匹配任意长度的字符,至少要有一次,不包括0次

\?匹配前面的字符0次或者一次,可有可无
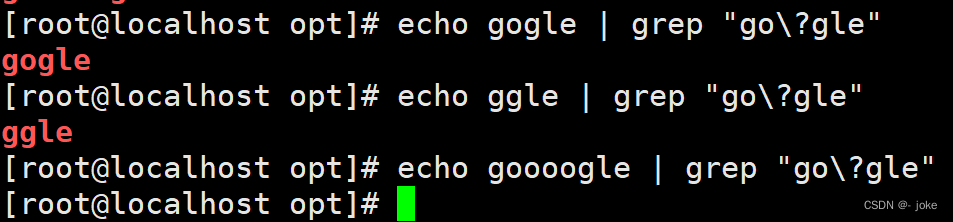
\+ 匹配前面的字符至少1次,最多可以无数次

\{n\}匹配前面的字符等于n次,必须连续出现才能匹配

\{m,n\}匹配前面的字符,最少m次,最多n次

\{,n\}匹配前面的字符,最多n次(只要出现几次,出现都算,除非没有,只要前面的字符有,都算)
\{n,\}匹配前面的字符至少n次

位置锚定:
^ 以什么为开头,在模式的左侧 ^root

$ 以什么为结尾,在模式的右侧 r$

^root$ 用于匹配整行,而且整行中只有以后个root
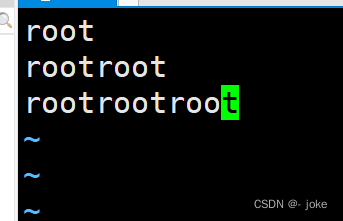

^$ / ^[[:space:]]$ 匹配空行
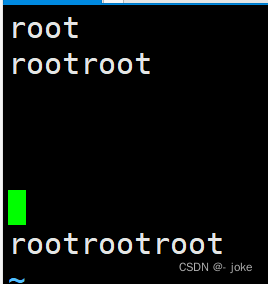

词首锚定 \< 或者 \b

词尾锚定 \> 或者 \b
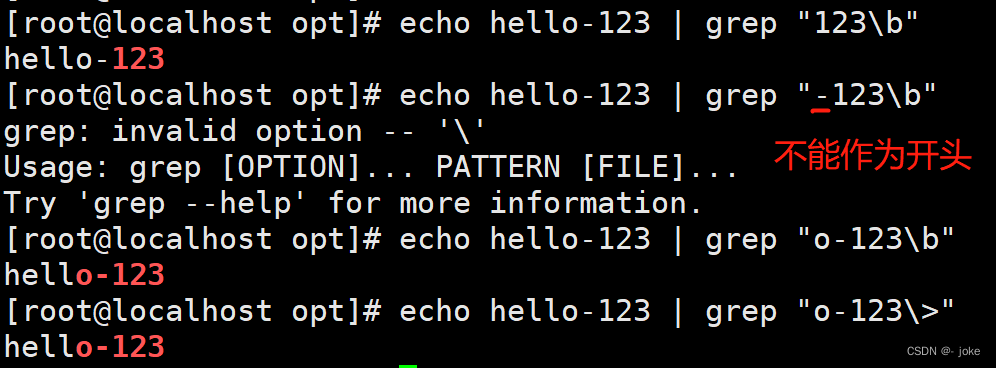
匹配整个单词

分组()
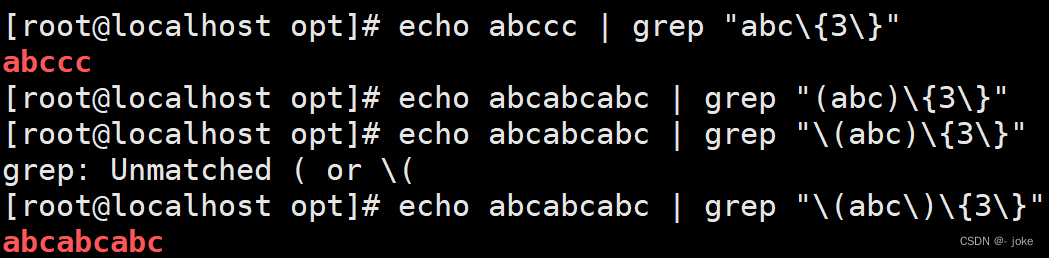


\| 表示逻辑或


扩展正则就是不写\
但是有要求 grep -E 或者egrep
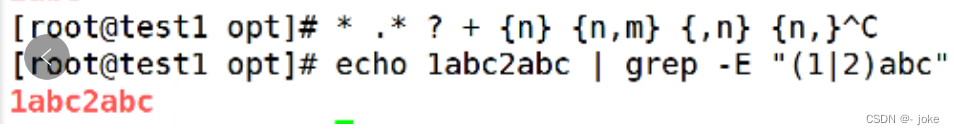
练习一条命令显示出文件内容

练习
显示/etc/passwd中以sh结尾的行

查找/etc/inittab中含有“以s开头,并以d结尾的单词”模式的行

查找ifconfig命令结果中的1-255之间的整数

显示/var/log/secure文件中包含“Failed”或“FAILED”的行

在/etc/passwd中取出默认shell为bash的行
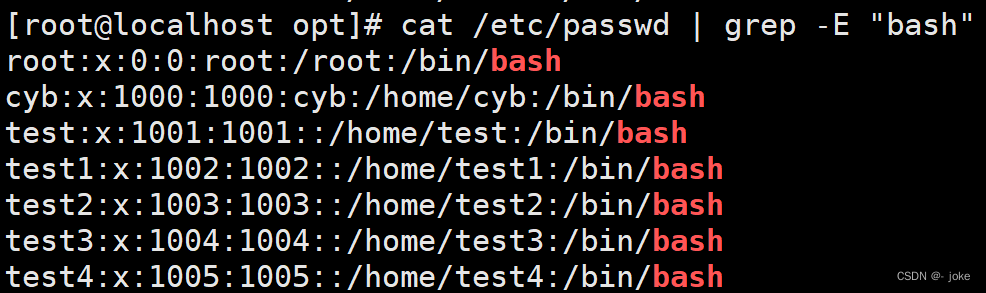
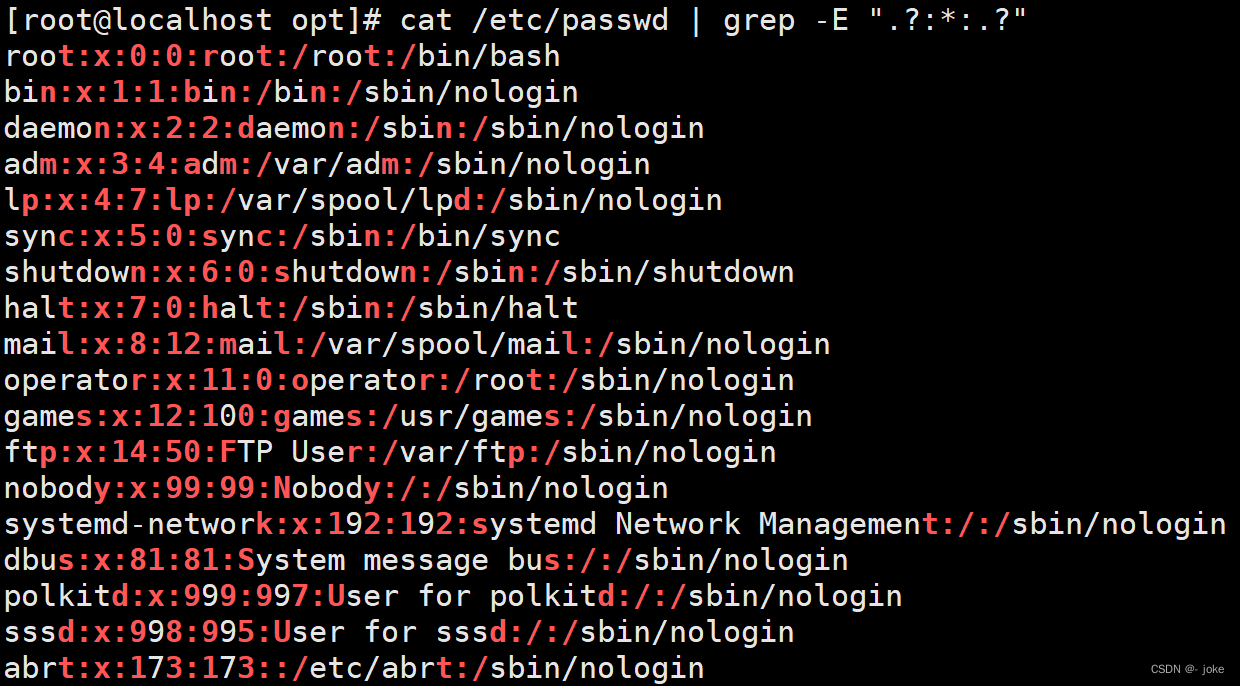
高亮显示passwd文件中冒号,及其两侧的字符

以长格式列出/etc/目录下以ns开头、.conf结尾的文件信息