摘要
目前的语义通信模型在处理图像数据方面仍有可改善的部分,包括有效的图像语义编解码、高效的语义模型训练和精准的图像语义评估。为此,提出了一种深度图像语义通信(DeepISC)模型。首先采用基于 vision transformer 的自编码器(ViTA)网络实现高质量的图像语义编解码;接着采用自编码器实现信道编解码,保证语义在信道上的传输;然后利用判别器网络(DSN)和 ViTA 的双网络架构协同训练,提高重建图像的语义精度;最后针对不同的下游视觉任务提出不同的图像语义评估指标。仿真结果表明,相较于其他方案,DeepISC 可以更有效地还原传输图像的语义特征,使重建图像在各个下游任务中都展现出与原图像相同或相近的语义结果。
大致模型框架:
- 基于 vision transformer构造的 ViTA 网络来实现图像语义编解码
- 利用 DSN 和 ViTA 的双网络架构来进行协同训练,提高重建图像的语义精度
- 设计了一种通用的多任务图像语义评估机制(基于图像分类、目标检测、特征提取、PSNR等)
0, 引言
文本语义通信:xie等人提出基于深度学习的语义通信系统用于文本传输。通过恢复句子的含义最大化系统容量和最小化语义错误,使用迁移学习加速模型训练。与此同时,提出精简分布式语义通信系统,实现低复杂度文本传输,使IoT设备与云/边缘的数据传输在语义级别。
图像语义通信:
- Huang提出基于生成对抗网络的图像语义编码方式
- Patwa提出了一种压缩视觉数据的方法
- Sun等提出一种基于像素语义的联合源通道编码方法
- Wang等引入了对抗性损失来优化基于深度学习的联合源通道编码;设计了一个语义先验注意力模块来自适应地增强语义特征
现有图像语义通信模型不足:
- 图像语义编解码器:基于卷积的图像语义编码器 难以兼顾图像的全局语义特征和局部语义特征
- 图像语义模型训练:基于单网络架构和传统损失函数的图像语义训练模型容易丢失细节,模型训练过程中陷入局部极值, 重建图像失真。
- 图像语义评估指标
本文工作:
1.设计了vision transformer的自编码器。
vision transformer————作为编码器和解码器
深度卷积神经网络(DNN)————组成全连接自编码器作为信道编码器和解码器
2. 设计了指导ViTA学习的判别器网络(DSN),与ViTA形成双网络架构协同训练,增强ViTA学习能力。DSN对 ViTA 生成的重建图像和原图像识别,根据识别结果计算对抗损失函数,指导ViTA 的更新
3. 提出了一种针对下游任务的多任务图像语义评估机制.原图像与重构图像在三方面表现(图像分类、目标检测、特征提取)
1. 系统模型
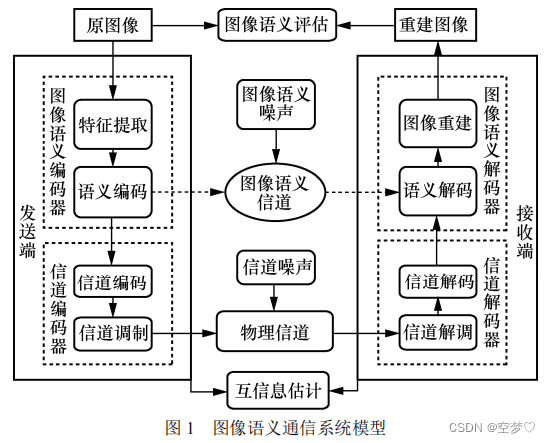
困难:
- 如何联合设计图像语义编码器和信道编码器
- 如何克服图像语义噪声,进行有效语义传输
1.1 图像语义编解码器
-
信源与信道编码
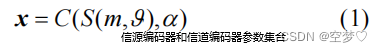
-
信源与信道解码
接收端的信号:y=hx+n
h:瑞利衰落信道的信道增益。 n:加性白高斯噪声(AWGN) -
图像语义模型的目标函数:均方误差(MSE)
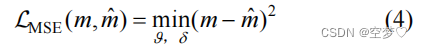
1.2 信道编码器和解码器
互信息一般用来衡量 2 个变量之间的相关性
互信息可以为训练接收机提供额外的信息
本文考虑最大化图像语义通信中信道输入和输出间的互信息
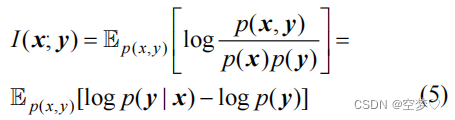
注:p(x)为发射信号 x 的边缘概率分布; p(y)为接收信号 y 的边缘概率分布;p(x, y ) 为 x 和 y 的联合概率分布;p(y|x) 为在给定 x 的条件下得到 y 的概率分布。
1.3 图像语义评估
基于某个特定的下游任务来对图像语义通信进行语义层面的评估。(例如图像分类、目标检测、语义分割、行为跟踪)
2.深度图像语义通信系统
2.1 DeepISC模型组成:
(1)面向图像的语义通信网络 ViTA
ViTA 的目标是实现高效的图像语义特征信息提取、传输以及图像语义特征重建
(2)指导ViTA的判别器网络DSN。
DSN对ViTA生成的重建图像和原图像进行识别,根据识别的结果计算相应的对抗损失函数,以此来指导 ViTA 的更新。DSN告诉语义差异,是ViTA朝着更好的方向学习。而且DSN与ViTA同步更新。
(3) 图像语义评估
图像分类任务——————根据分类结果计算分类偏差值(CLSD)
目标检测任务——————根据目标检测结果计算检测准确值(DTA)
特征提取任务——————根据特征向量之间的余弦距离计算特征相似值(FAS)
最后根据原始图像与重建图像的综合表现评估传输准确性
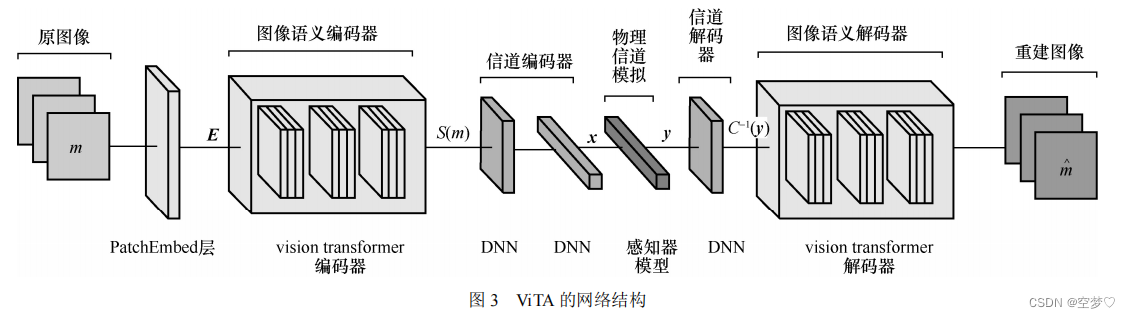
2.2面向图像语义的自编码器网络 ViTA
1. vision transformer
vision transformer 编码器的核心是多头注意力层
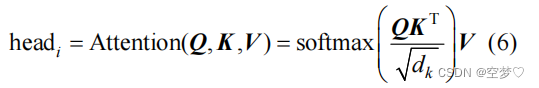
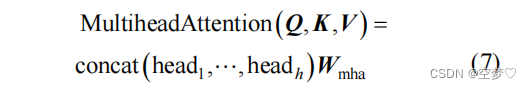
Q:为查询向量。
K:与 Q 相匹配的匹配向量
V:信息向量
Wmha :多头注意层的权重
- 信道编码层
由两层隐藏单元数不同的 DNN 组成:
第一层:激活函数采用 ReLU 函数
第二层:激活函数采用tanh 函数
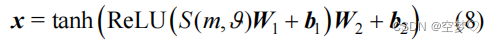
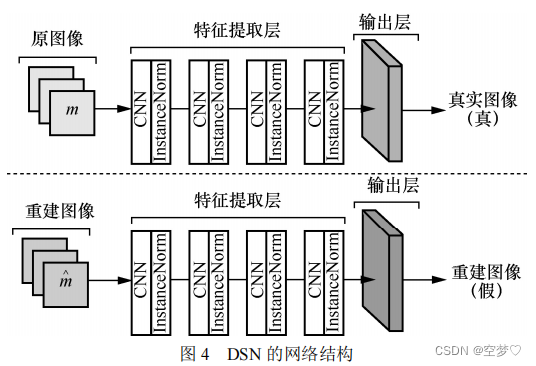
2.3 判别器网络DSN
单网络和传统的损失函数进行训练,存在陷入局部最优的风险
本文提出一种使用 DSN 和 ViTA 组成双网络架构进行协同训练
 4
4
4层CNN + 4层InstanceNorm层(做归一化)
对抗损失函数为:
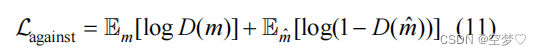
注:D(·)表示DSN模型的输出
模型的目标
-
DSN 的目标是能够分辨出原图像 m 和 ViTA 生成的重建图像ˆm ,就是将 m 识别为真,将 ˆm 识别为假。
-
ViTA 则是努力生成逼真的重建图像 ˆm 以混淆DSN 的判断
-
ViTA 和 DSN 协同训练的总目标可以表示为
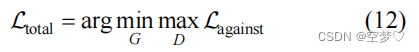
在对抗损失函数的基础上在引入L1损失,用来指导ViTA更新
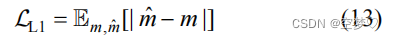
指导ViTA更新的损失函数为:(λ是调节 L1权重大小的系数)
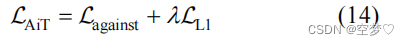
更新 DSN 的损失函数:
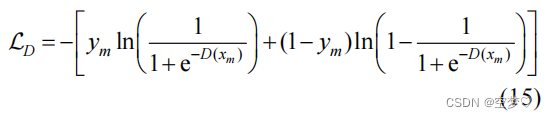
xm 代表输入的图像; ym 代表该图像的标签值
2.4 多任务图像语义评估机制
(1)分类偏差值
对原图像和重建图像分别进行识别,根据分类器的识别结果计算得出分类偏差值。
VCLSD越小说明原图像 m 和重建图像 ˆm 在分类任务上的语义越接近
(2)检测准确值
使用目标检测器分别对原图像和重建图像进行目标检测,根据检测结果计算得出两者的检测准确值
VDTA 越大说明原图像 m 和 重建图像 ˆm 在目标检测任务上的语义越接近
(3)特征相似值
首先使用一个特征提取器对原图像和重建图像分别进行特征提取,然后计算两者的特征距离(余弦距离)
VFAS 越大说明两者的特征相似度越高
3. 仿真分析
3.1 实验配置
- 数据集:Kaggle 的公开数据集 BIRDS-400
- 训练和测试环境:Ubuntu 20.04+CUDA 10.2
- 编程语言:Python
- 深度学习框架:PyTorch1.8.0
(1)图像分类任务:
分类器网络:ResNet50、VGG16 和 AlexNet
(2)目标检测任务:
YOLOv4作为公共检测器
(3)特征提取任务
使用ResNet50、VGG16 和 AlexNet 作为特征提取网络
(4)基于 PSNR 的语义通信评估
PSNR 对原图像和基于不同通信模型生成的重建图像进行评估,判断语义通信中图像的失真程度
变分自编码器(VAE)、卷积自编码器(CAE)、无DSN指导的ViTA作为基准模型
模型训练回合数:400、数据批次:32 、学习率:0.0001、采用Adam优化器
![[JVM] 5. 运行时数据区(2)-- 程序计数器(Program Counter Register)](https://img-blog.csdnimg.cn/img_convert/b78d59aa6414cac49c11b50f86666f8f.png#pic_center)