目录
- 网络工作流程
- 数据加载
- 模型加载
- 模型预测过程
- RPN获取候选区域
- FastRCNN进行目标检测
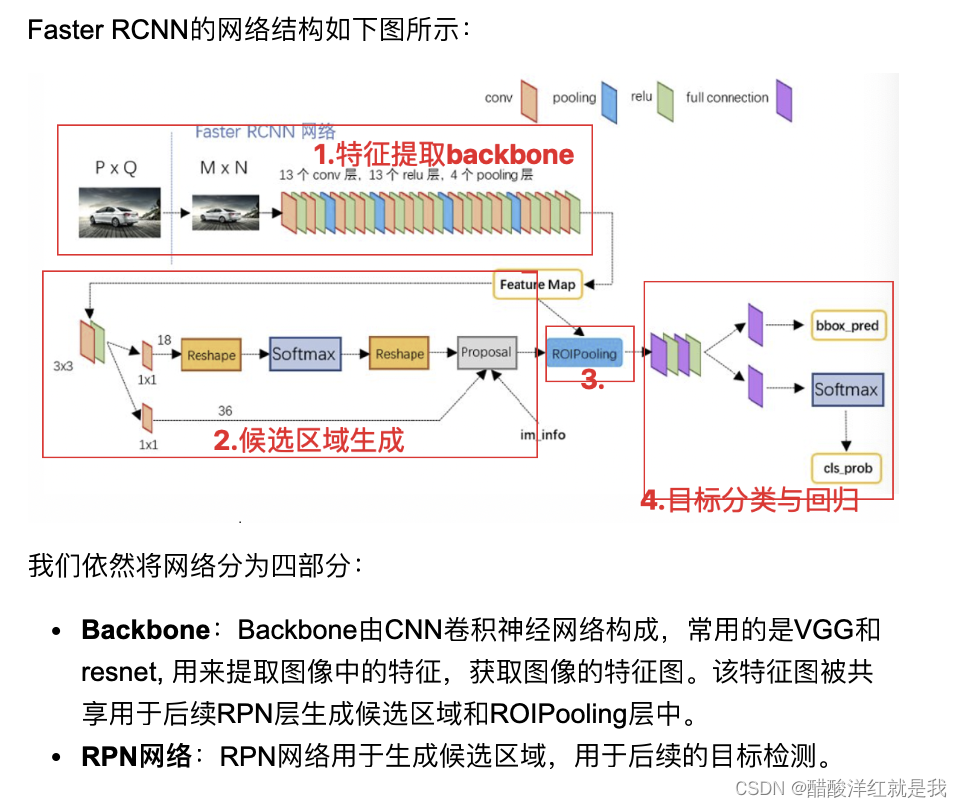
- 模型结构详解
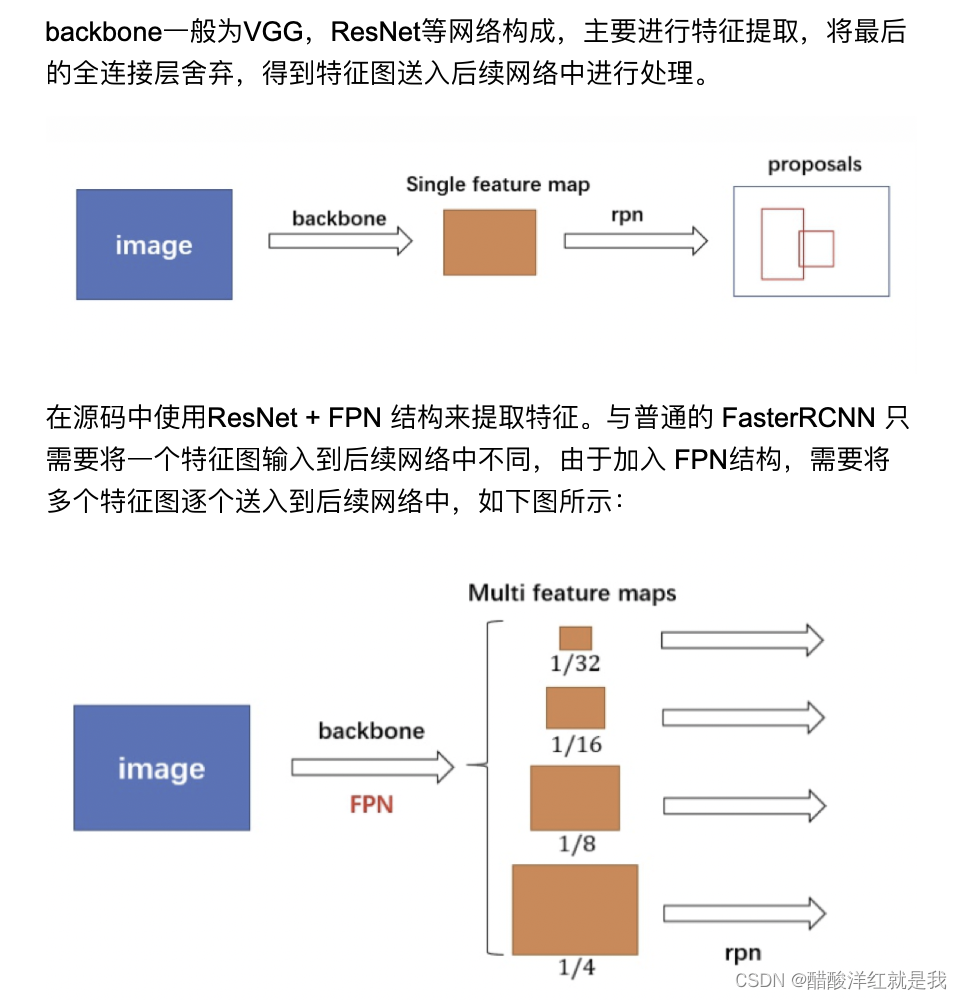
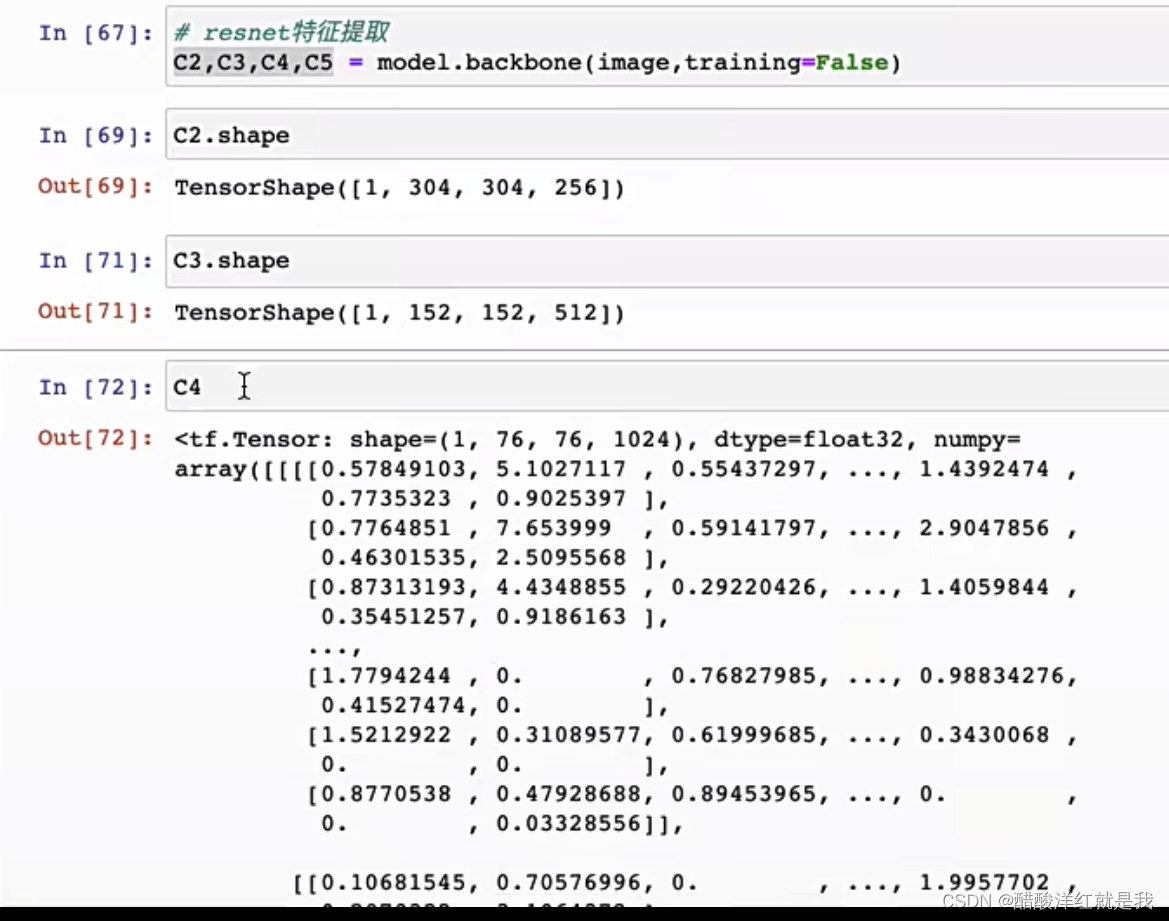
- backbone
- RPN网络
- anchors
- RPN分类
- RPN回归
- Proposal层
- ROIPooling
- 目标分类与回归
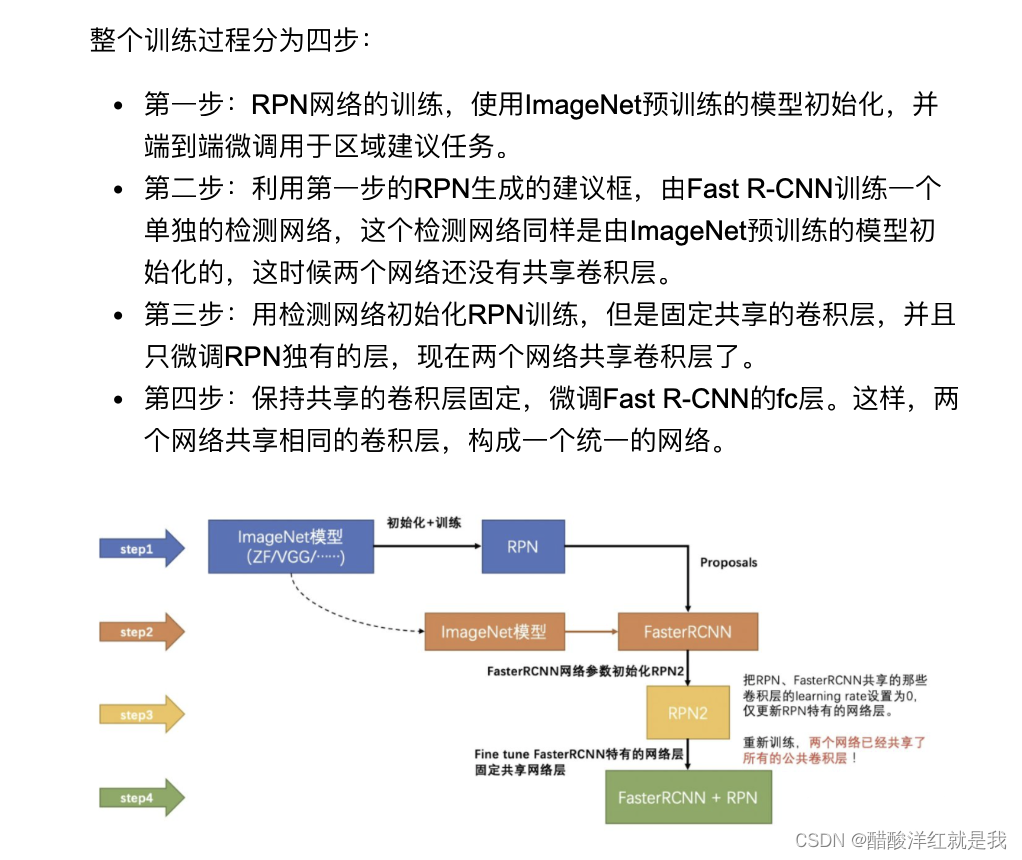
- FasterRCNN的训练
- RPN网络的训练
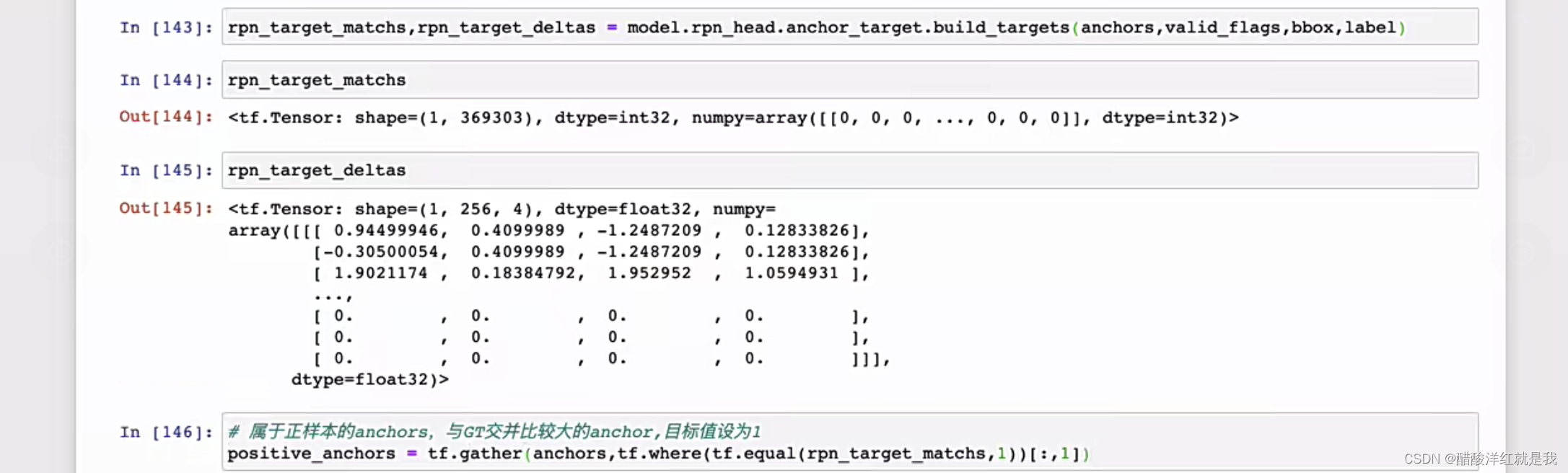
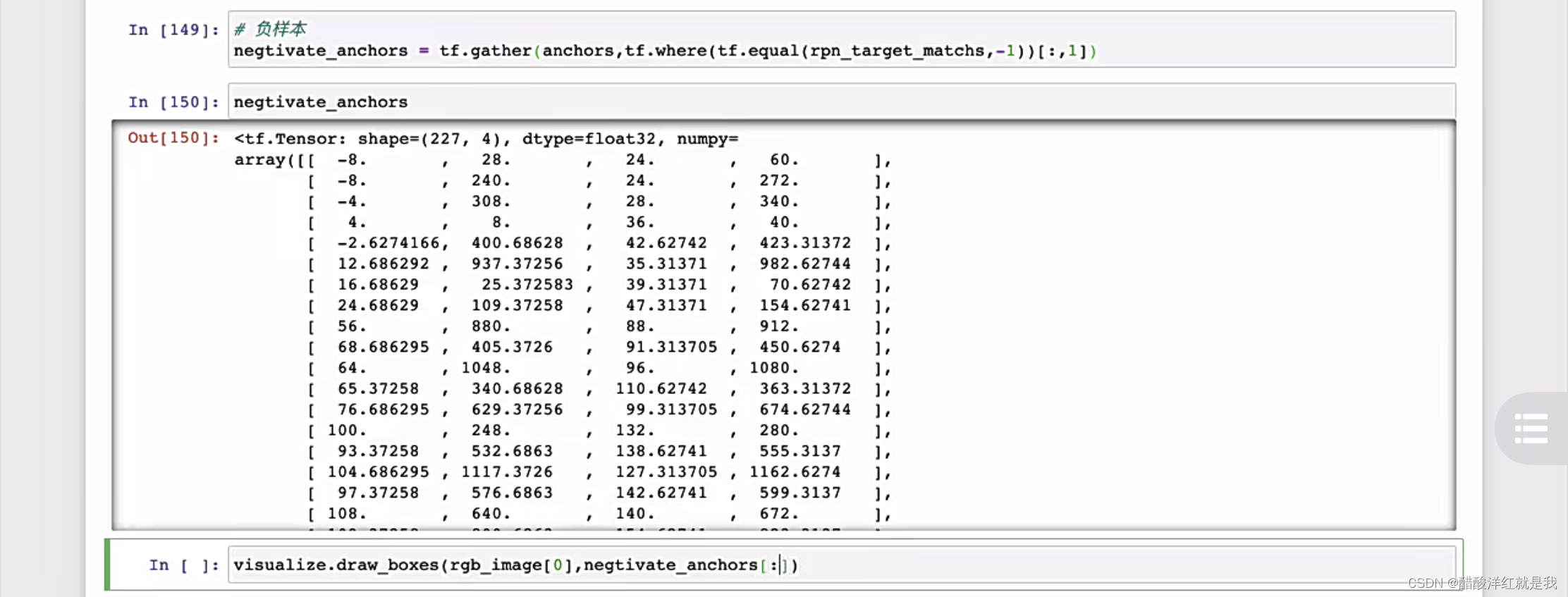
- 正负样本标记
- RPN网络的损失函数
- 训练过程
- 实现
- 正负样本设置
- 损失函数
- FastRCNN网络的训练
- 正负样本标记
- FastRCNN网络的训练
- 训练过程
- 实现
- 正负样本设置
- 损失函数
- 共享卷积训练
- 端到端训练
- 数据加载
- 模型实例化
- 模型训练
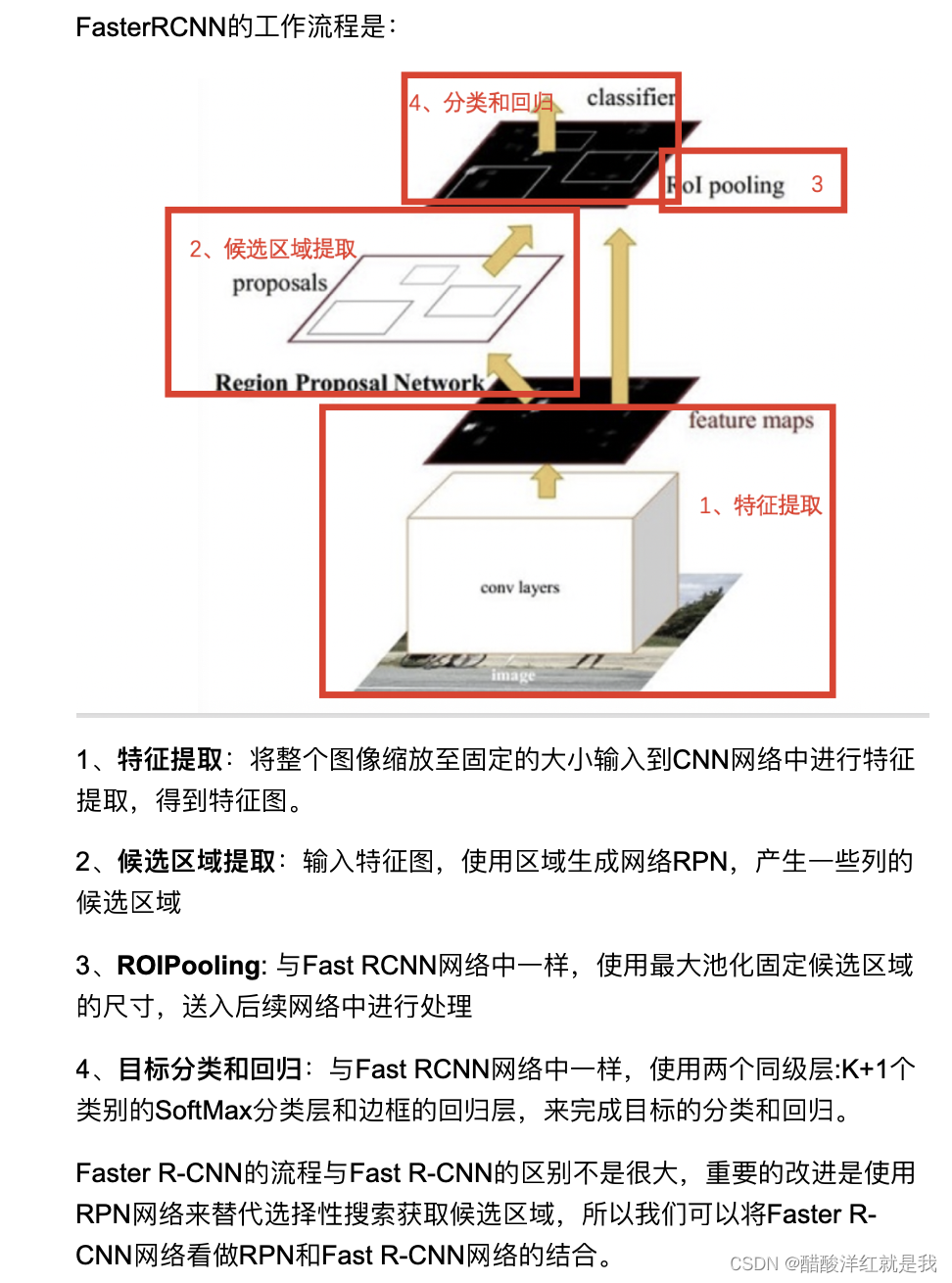
网络工作流程

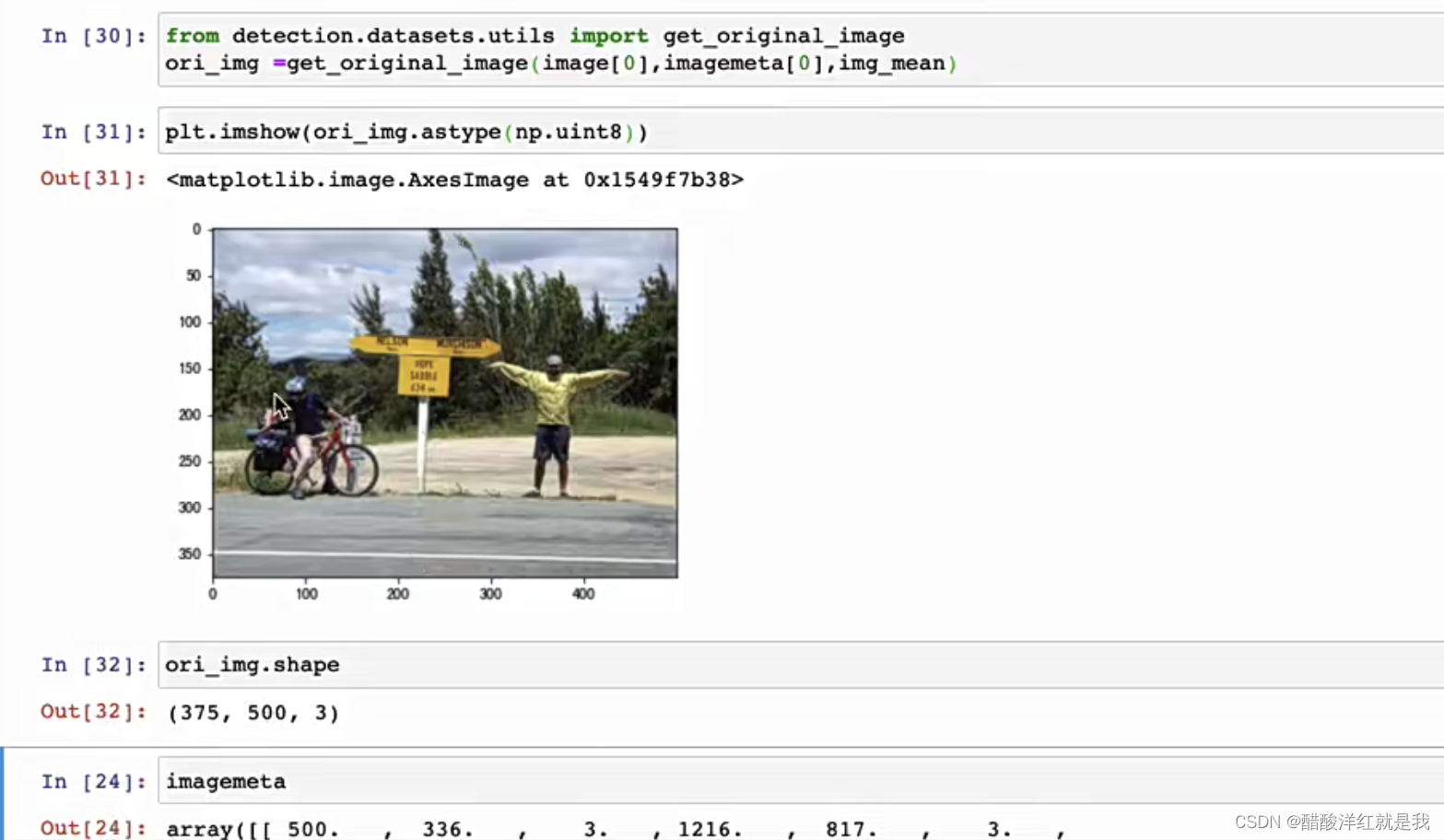
数据加载
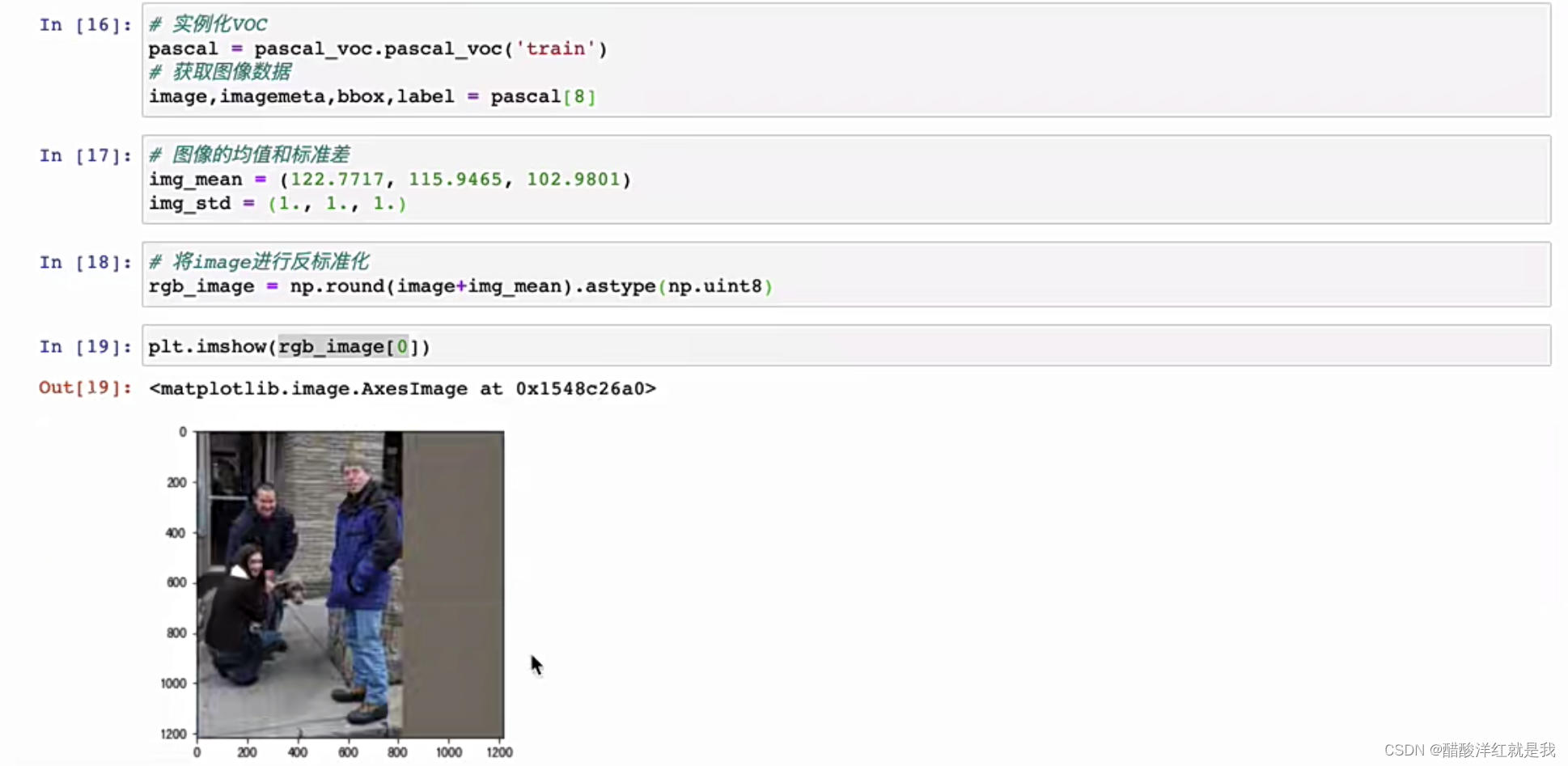
只要In[16]就可以送入网络了,剩下的只是方便展示观看
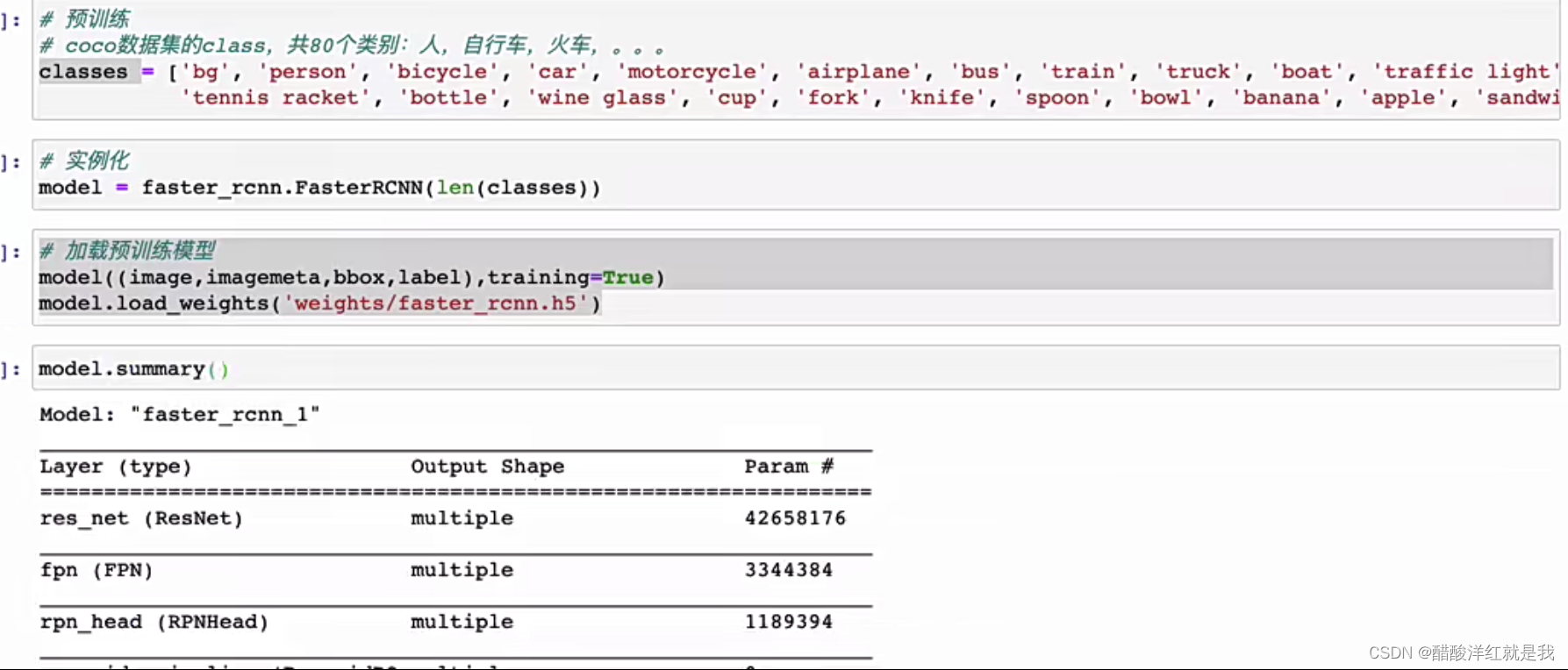
模型加载
模型预测过程
分为两部分:RPN生成候选区域和Fast RCNN进行目标的分类与回归
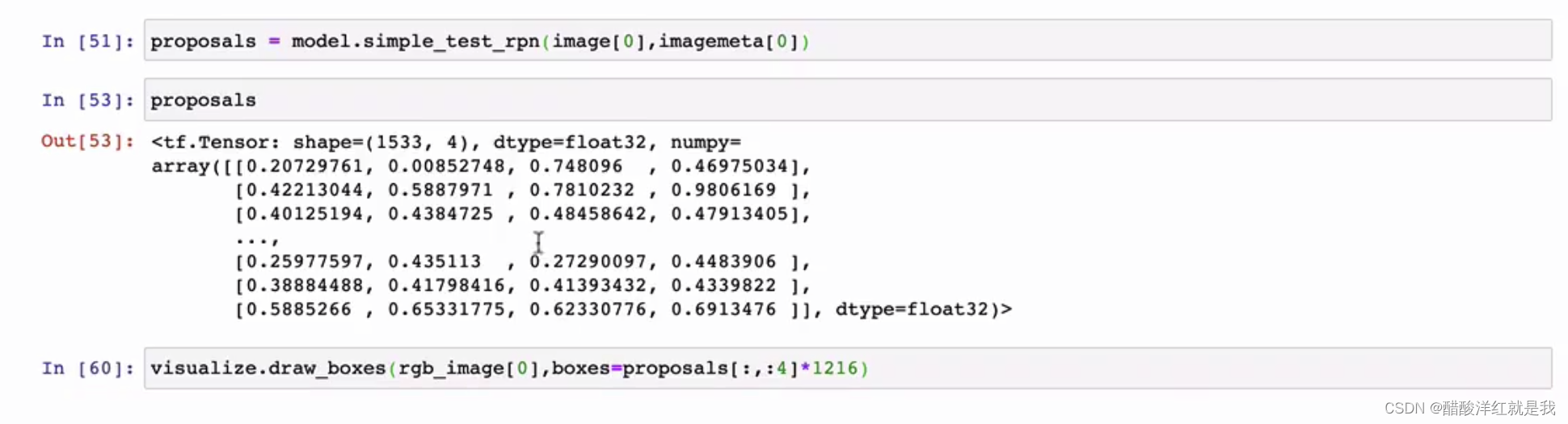
RPN获取候选区域

FastRCNN进行目标检测
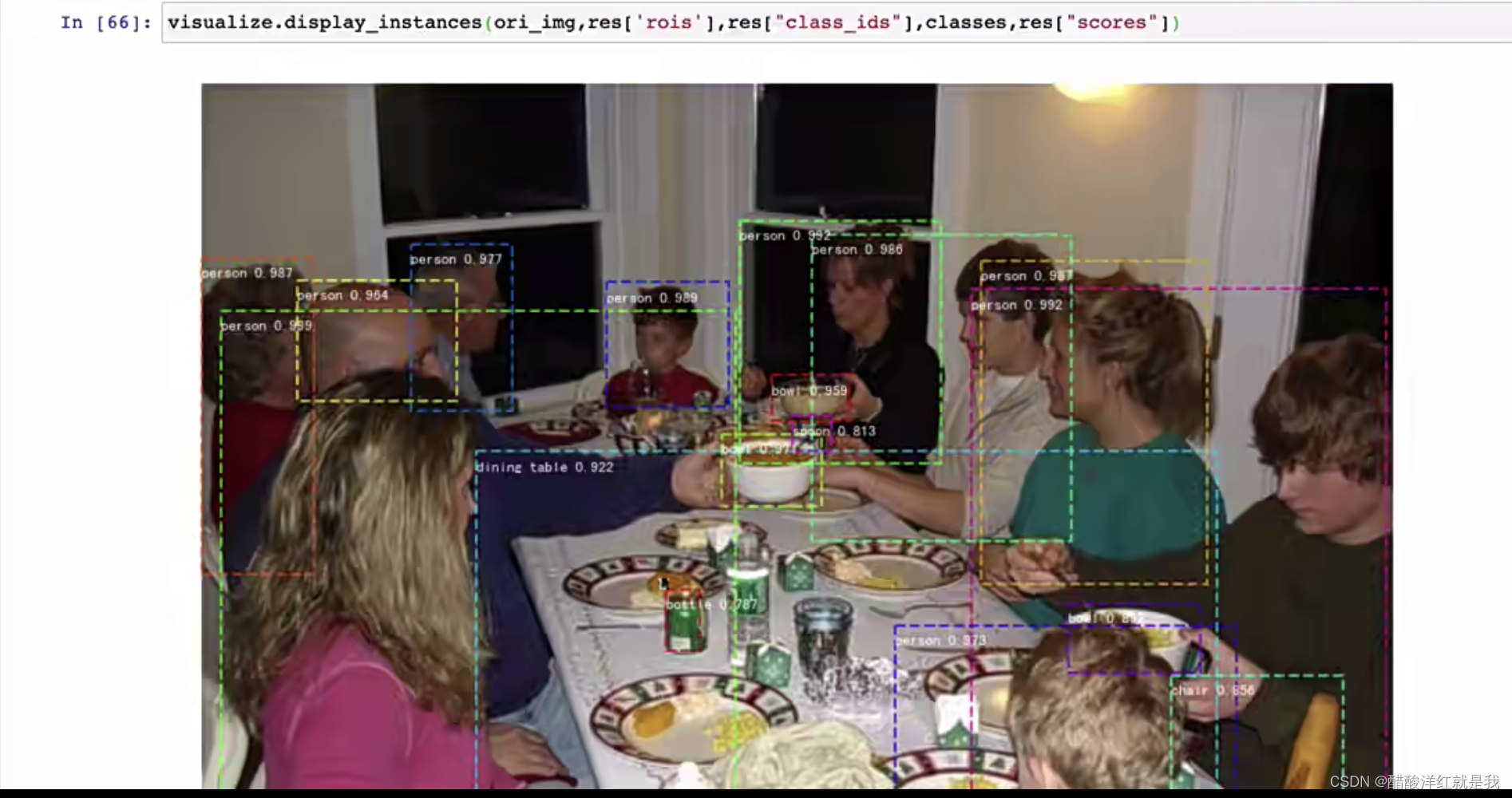
将获取的候选区域送入到Fast RCNN网络中进行检测
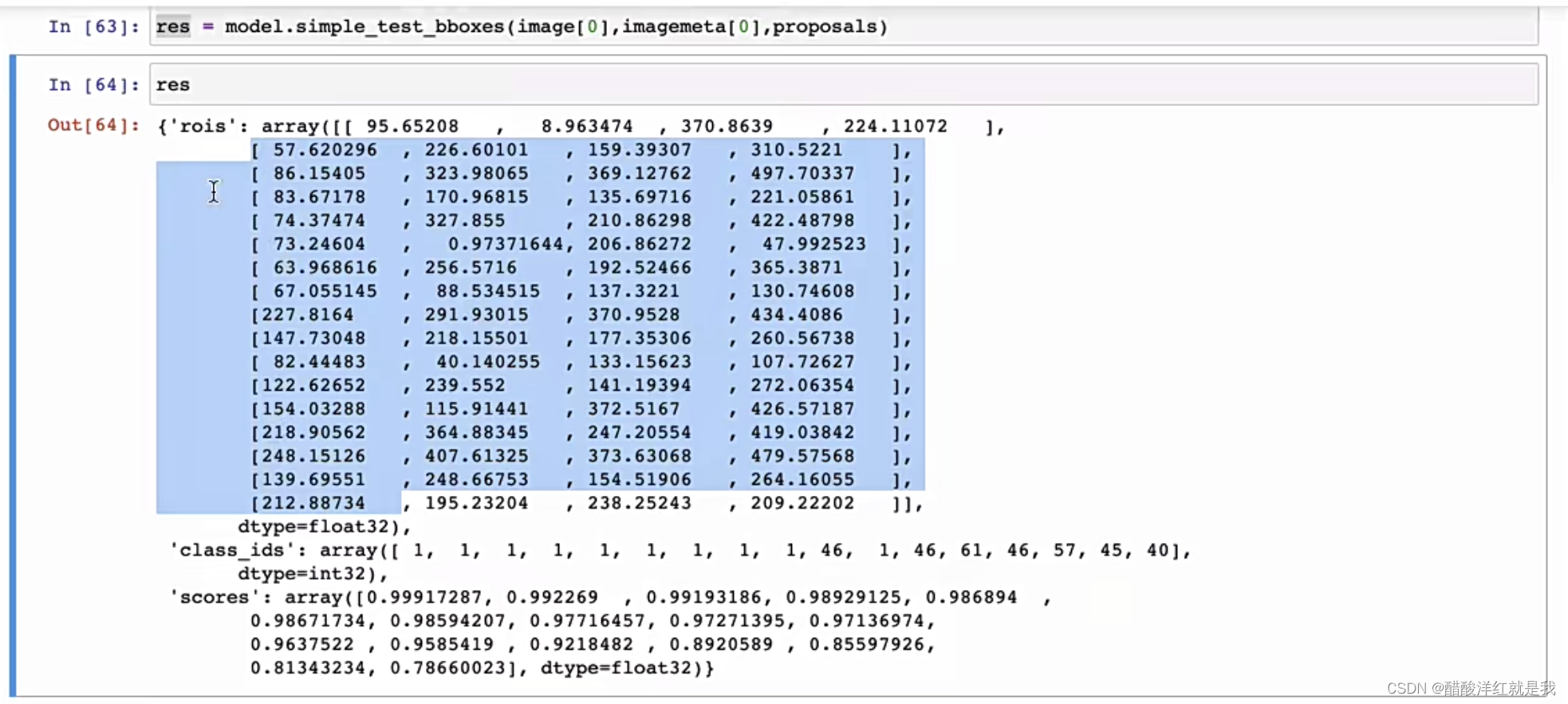
res是一个字典,其中rois是目标框,class_ids是所属的类别,scores是置信度
模型结构详解

backbone

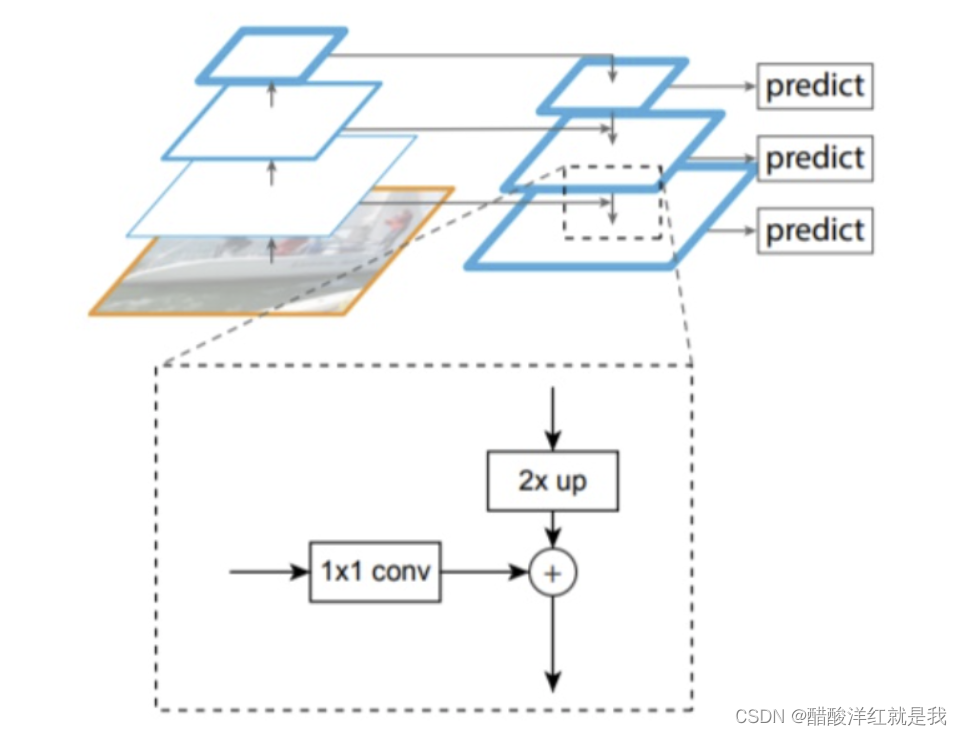
FPN就是特征融合,使用多个特征图而不是使用一个特征图
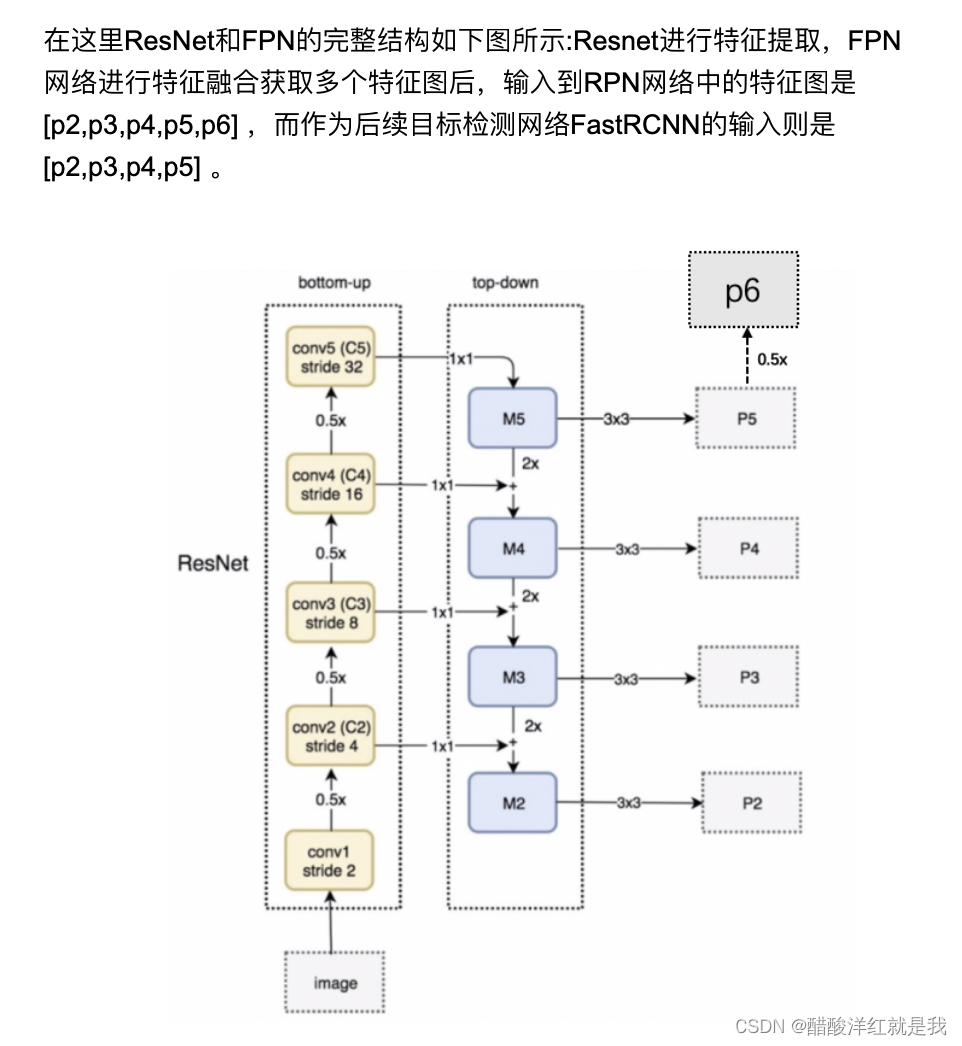
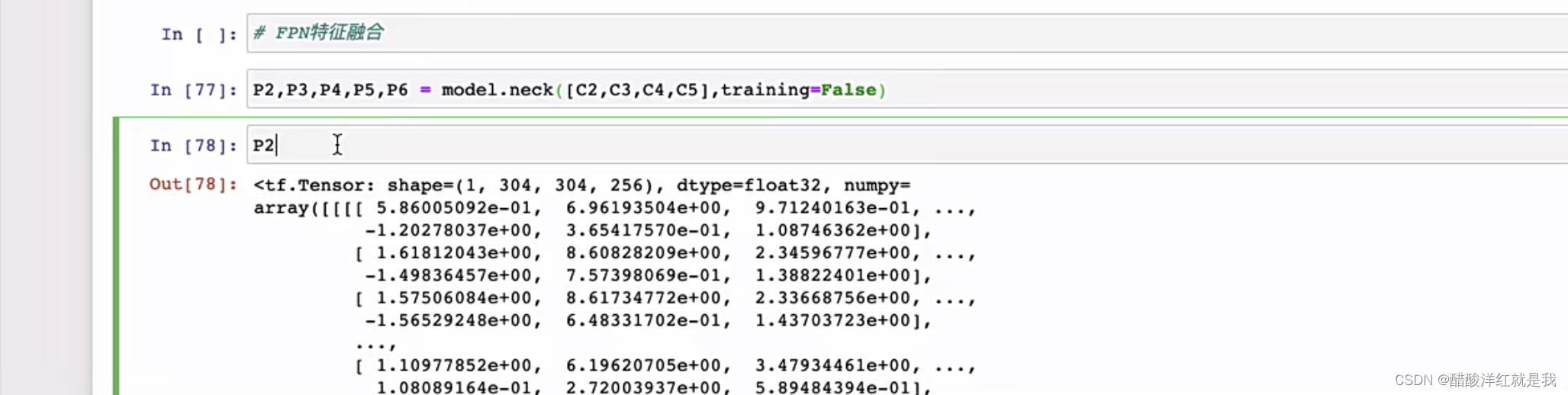
RPN网络
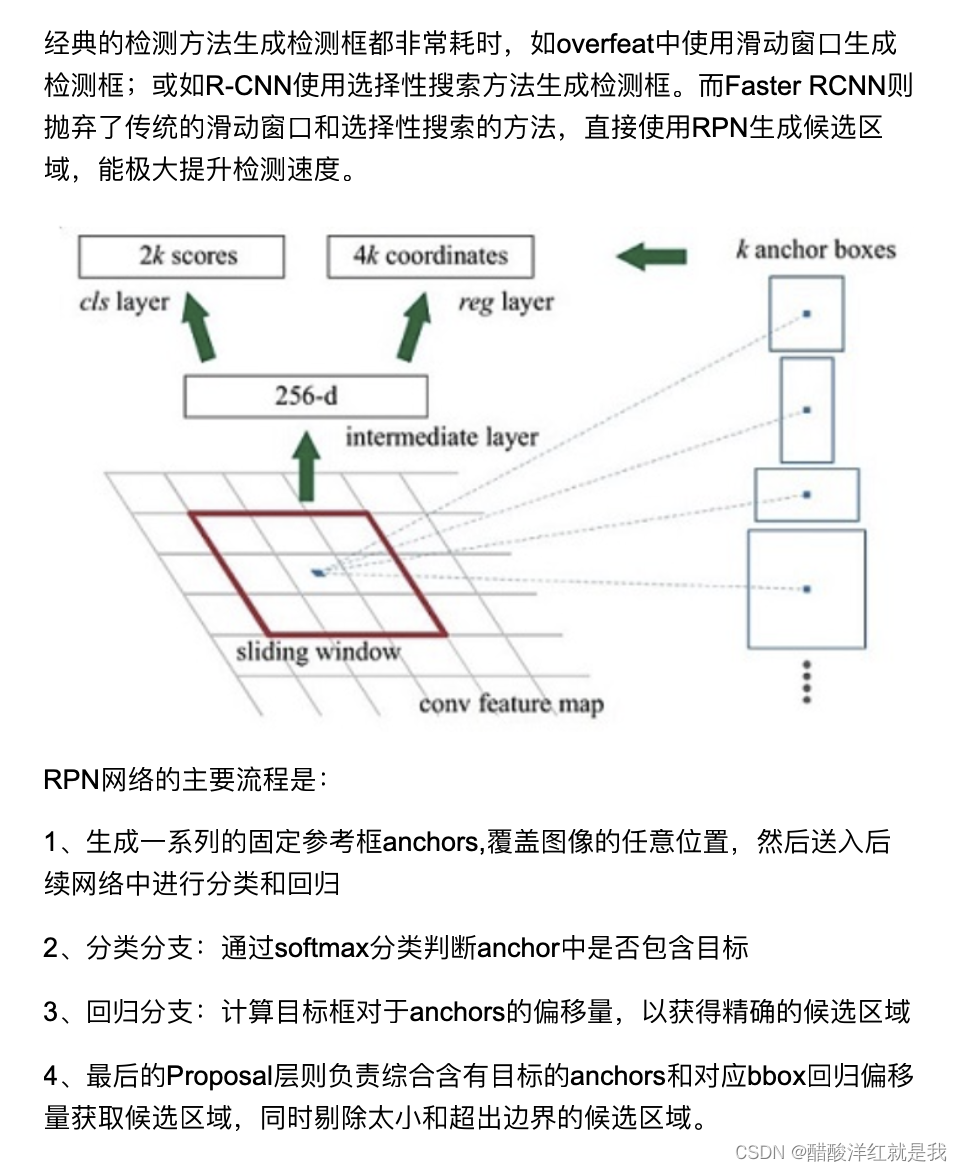
anchors
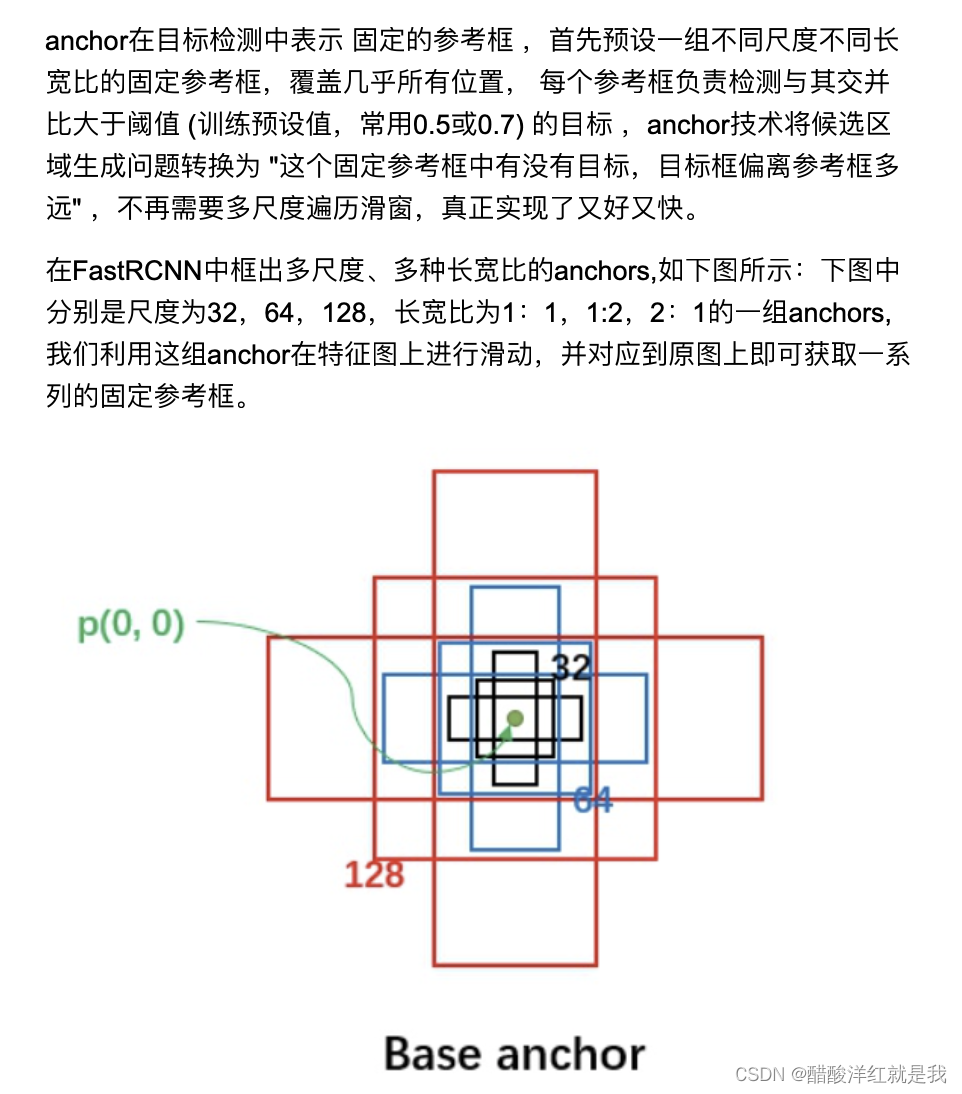
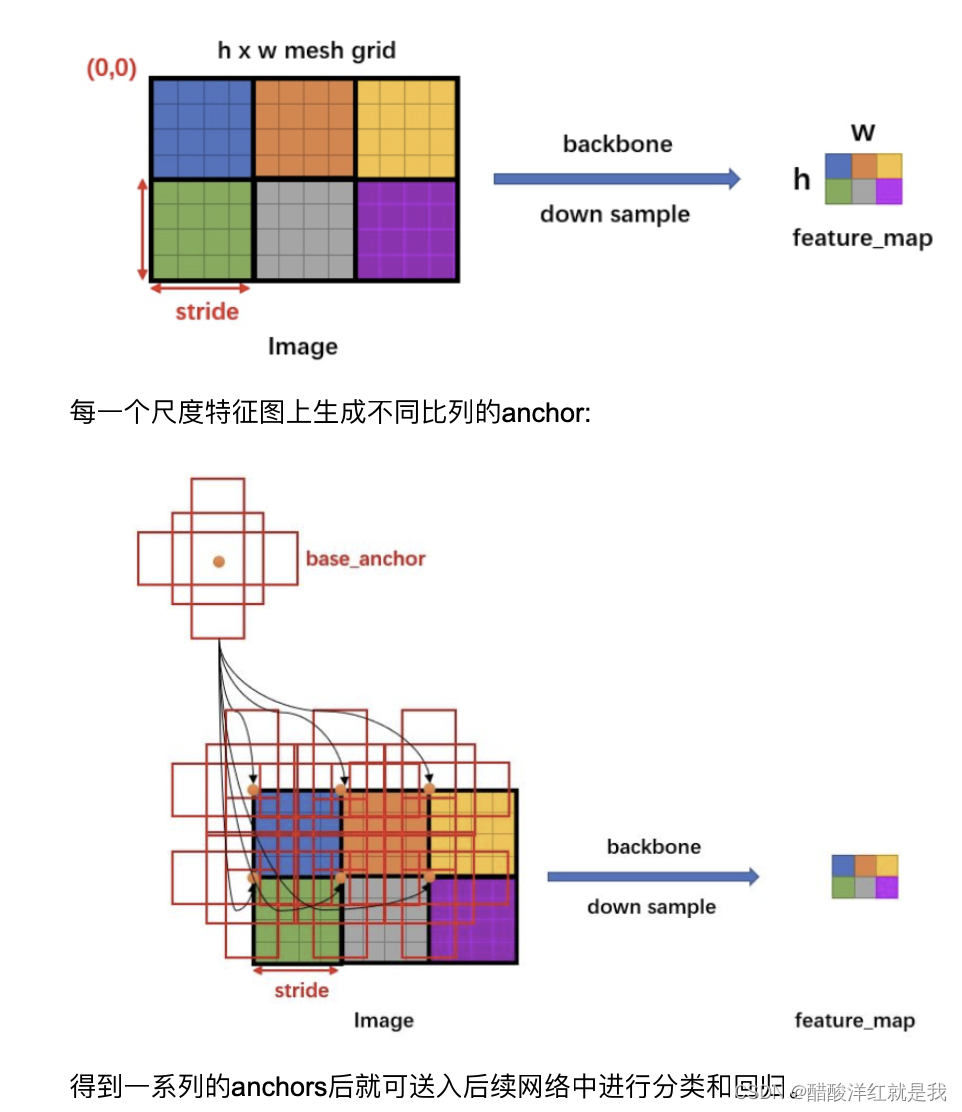
预设一组anchors(不同尺度,不同长宽比)
遍历特征图上的特征点,并映射回原图

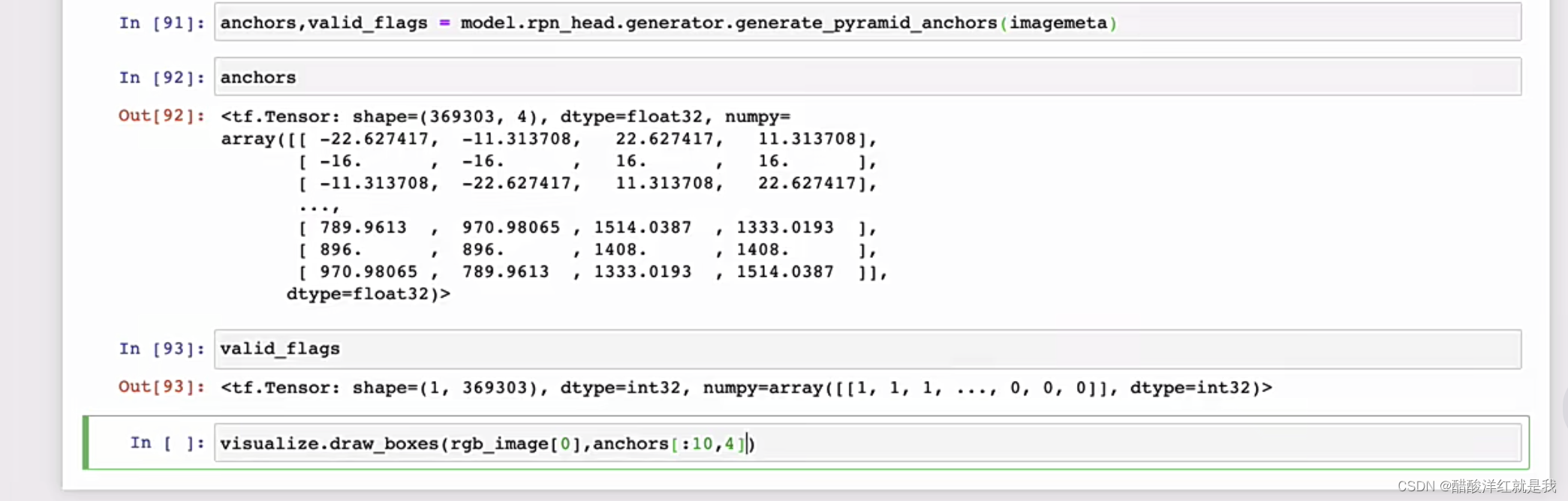

RPN分类

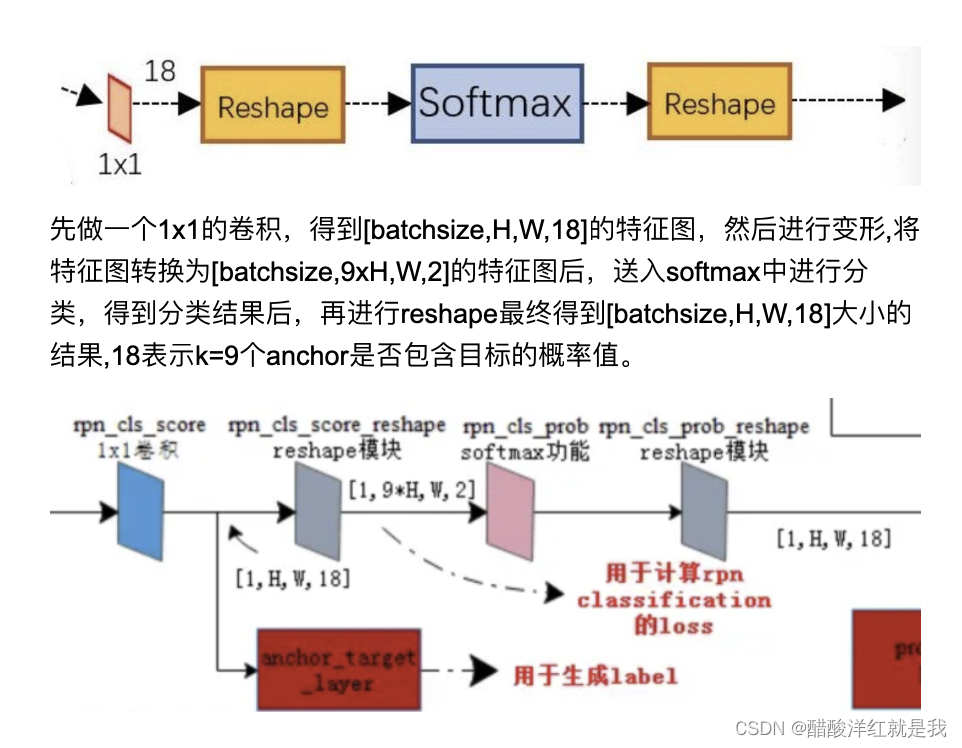
RPN回归

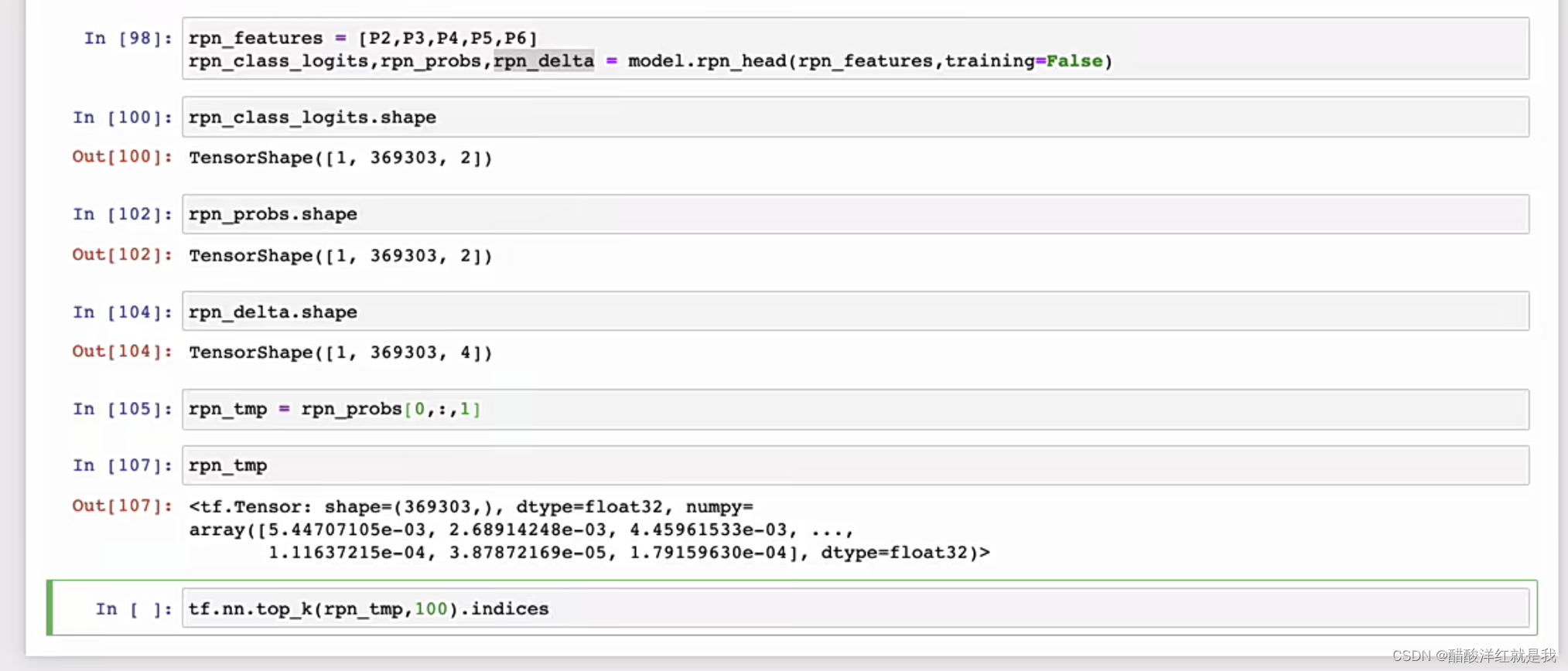
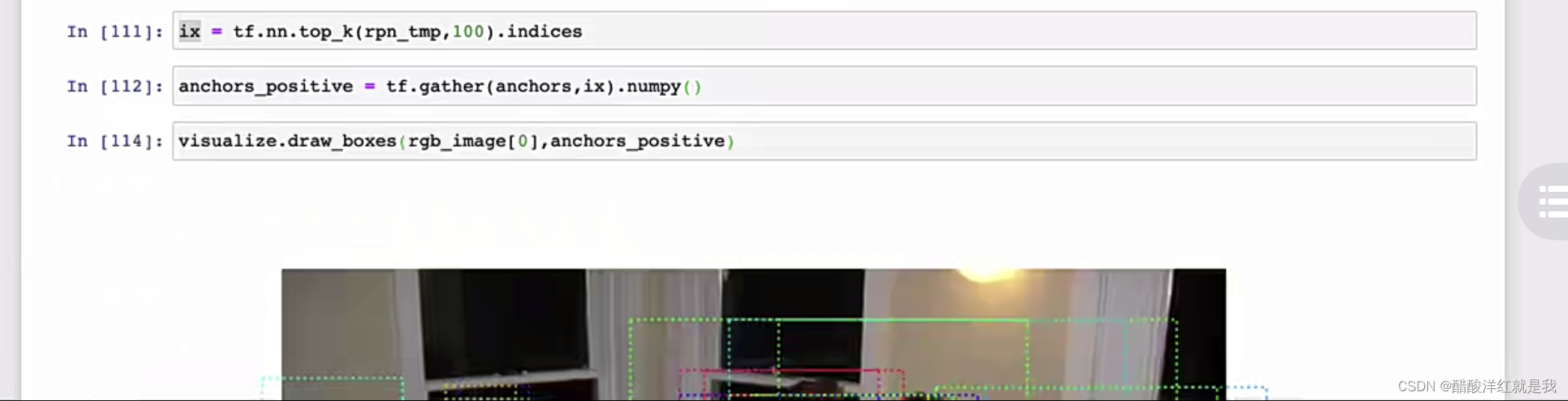
Proposal层
利用回归结果对anchor的坐标进行修正


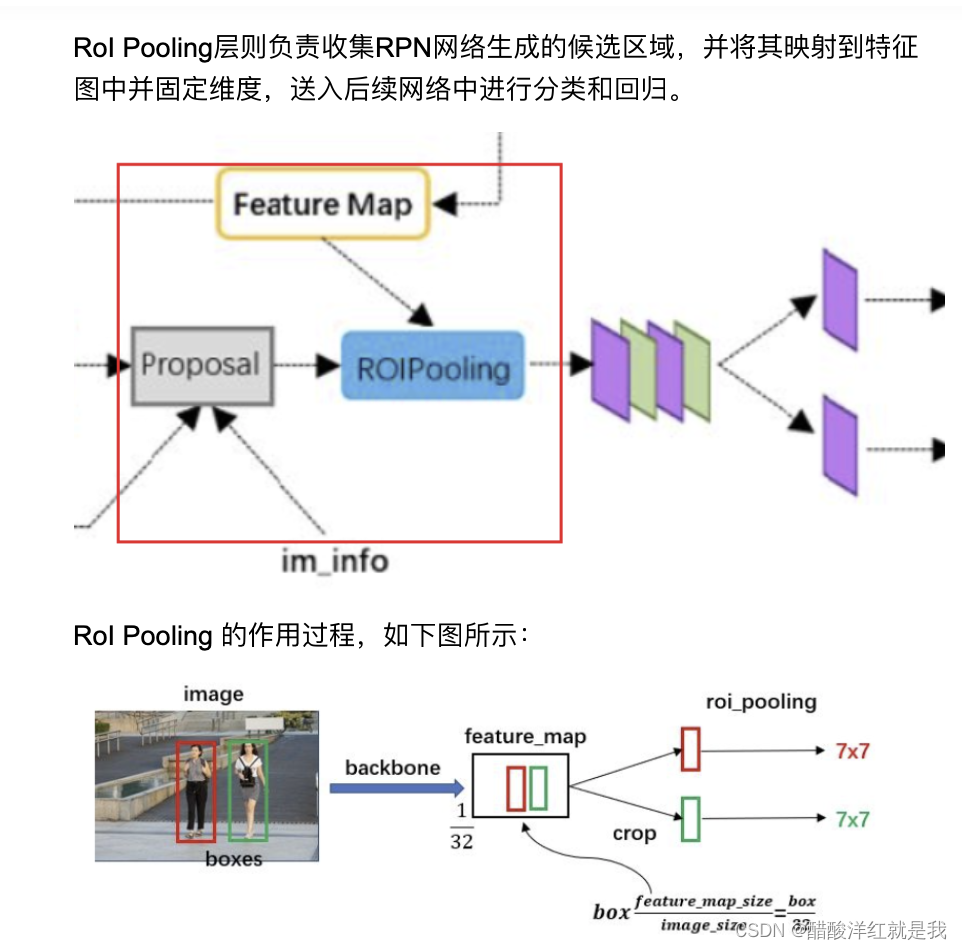
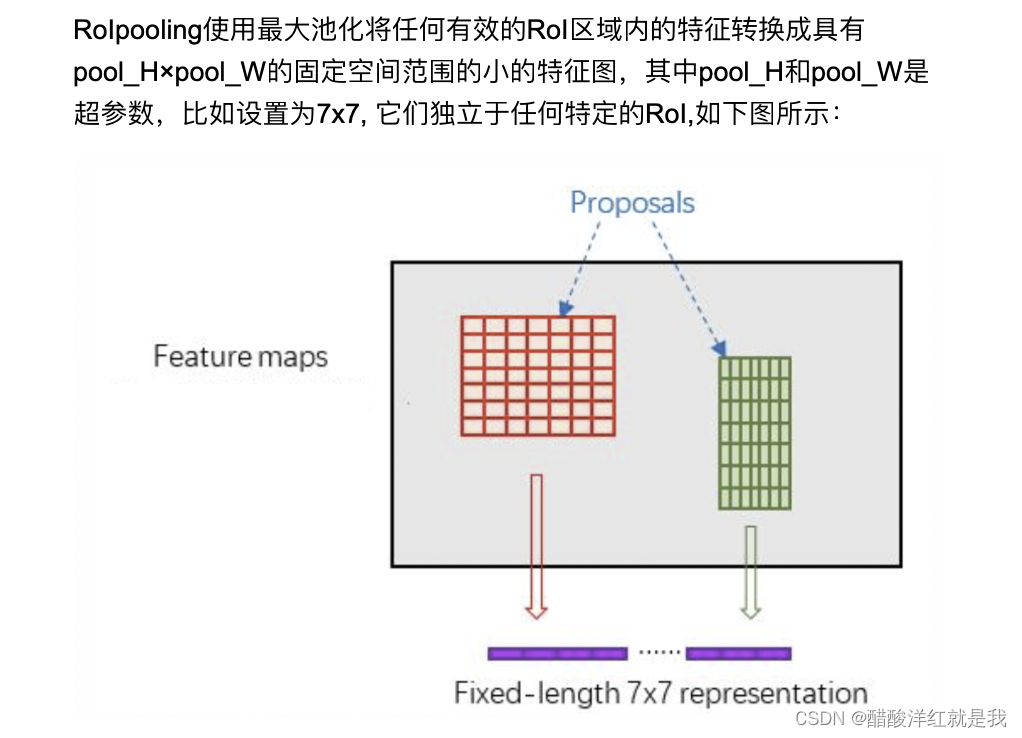
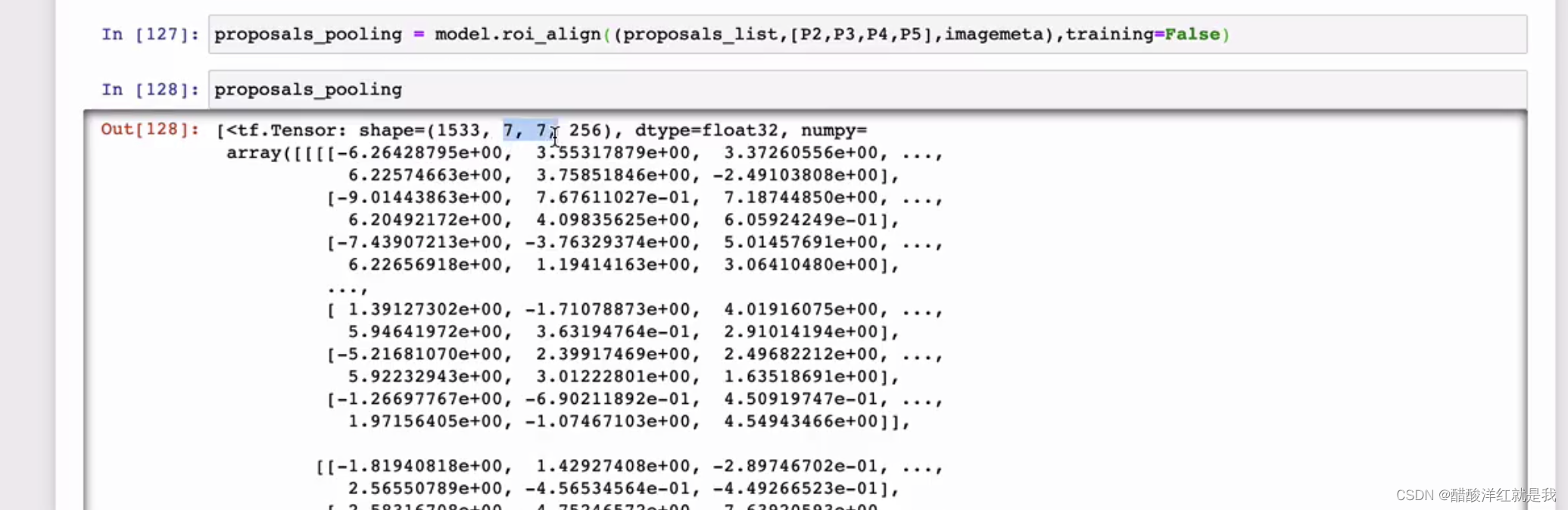
ROIPooling
确定proposal要映射到哪个特征图上,获取对应的候选框
将候选框进行H*W的网格划分
在每一个网络中取最大值得到ROIPooling的结果

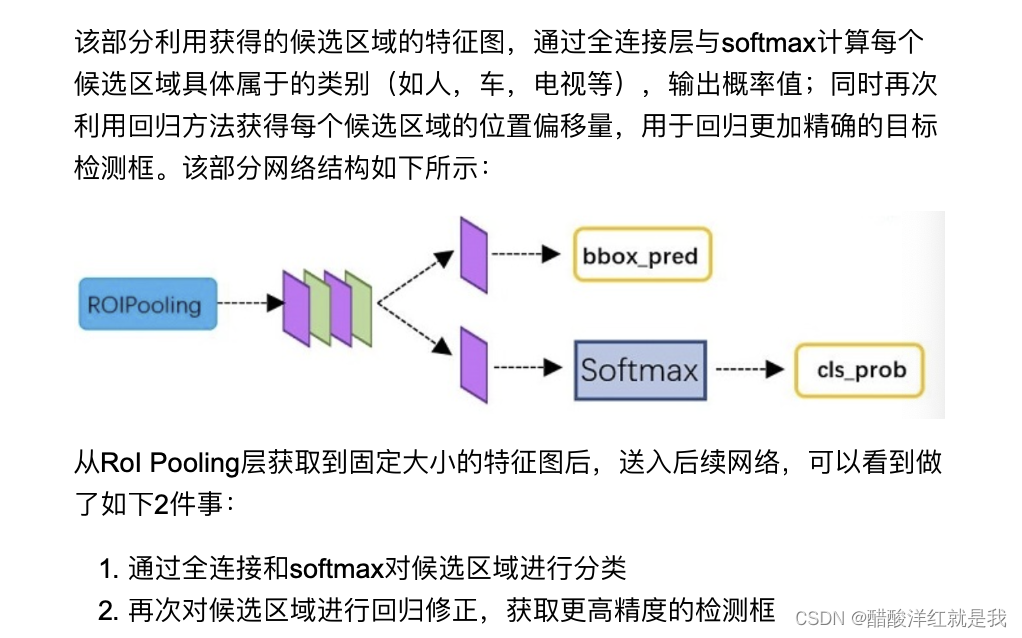
目标分类与回归
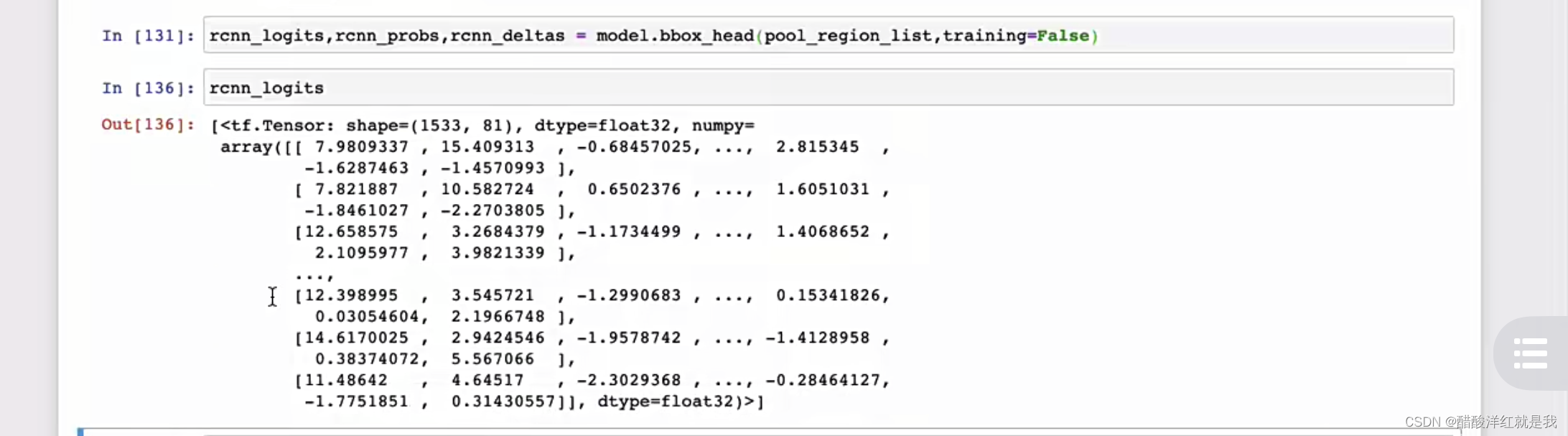
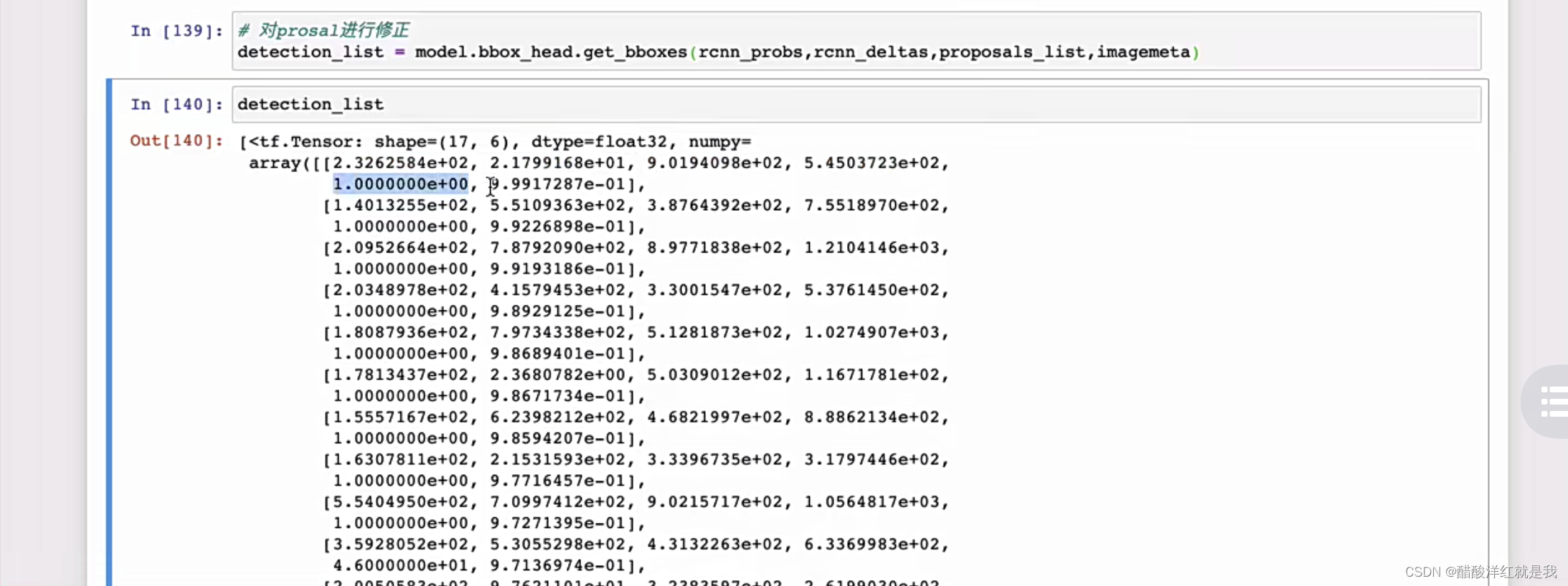
FasterRCNN的训练
RPN网络的训练

正负样本标记

RPN网络的损失函数
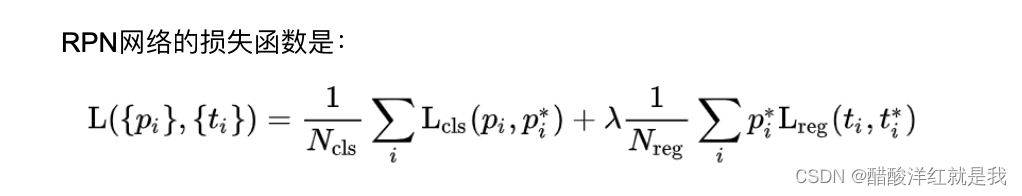
训练过程

实现
正负样本设置
损失函数

FastRCNN网络的训练

正负样本标记
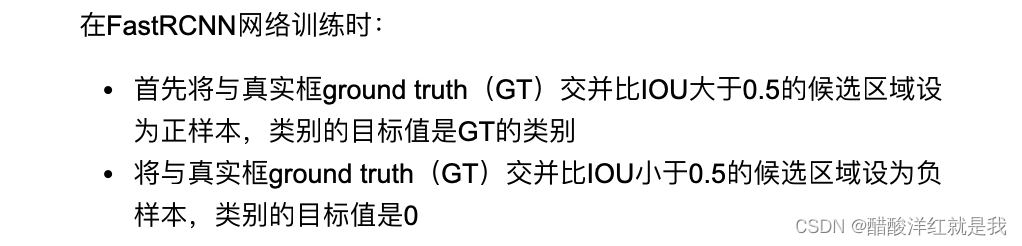
FastRCNN网络的训练

训练过程

实现
正负样本设置
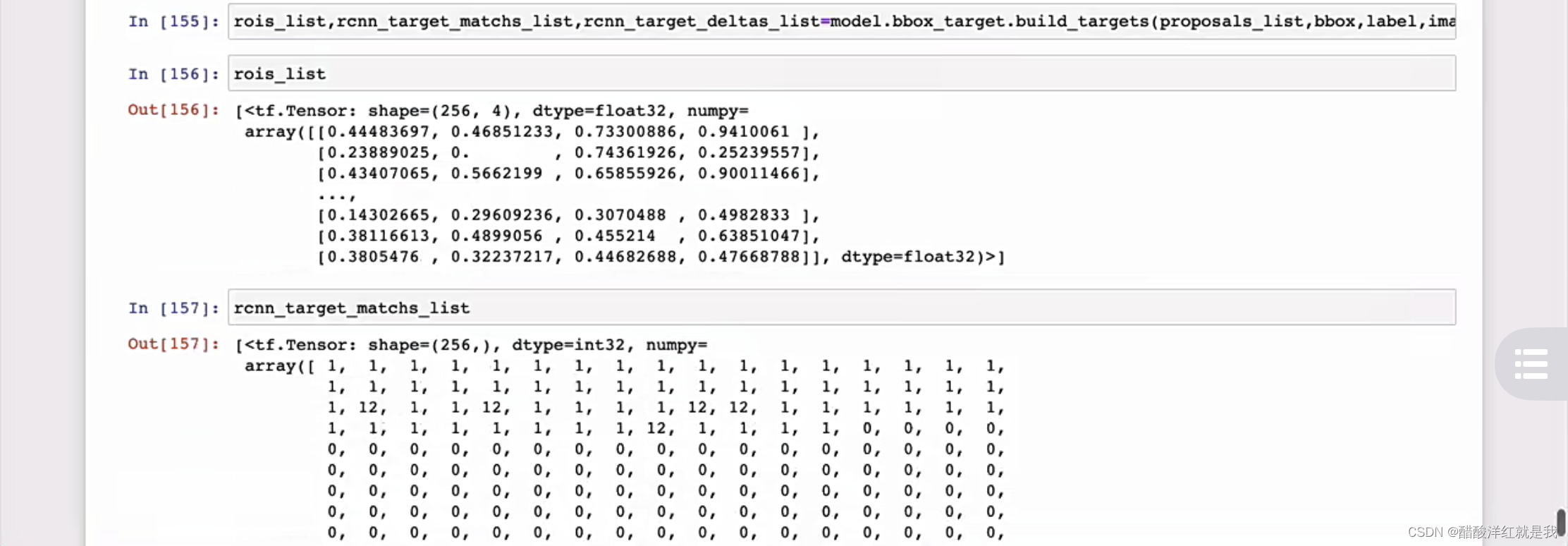
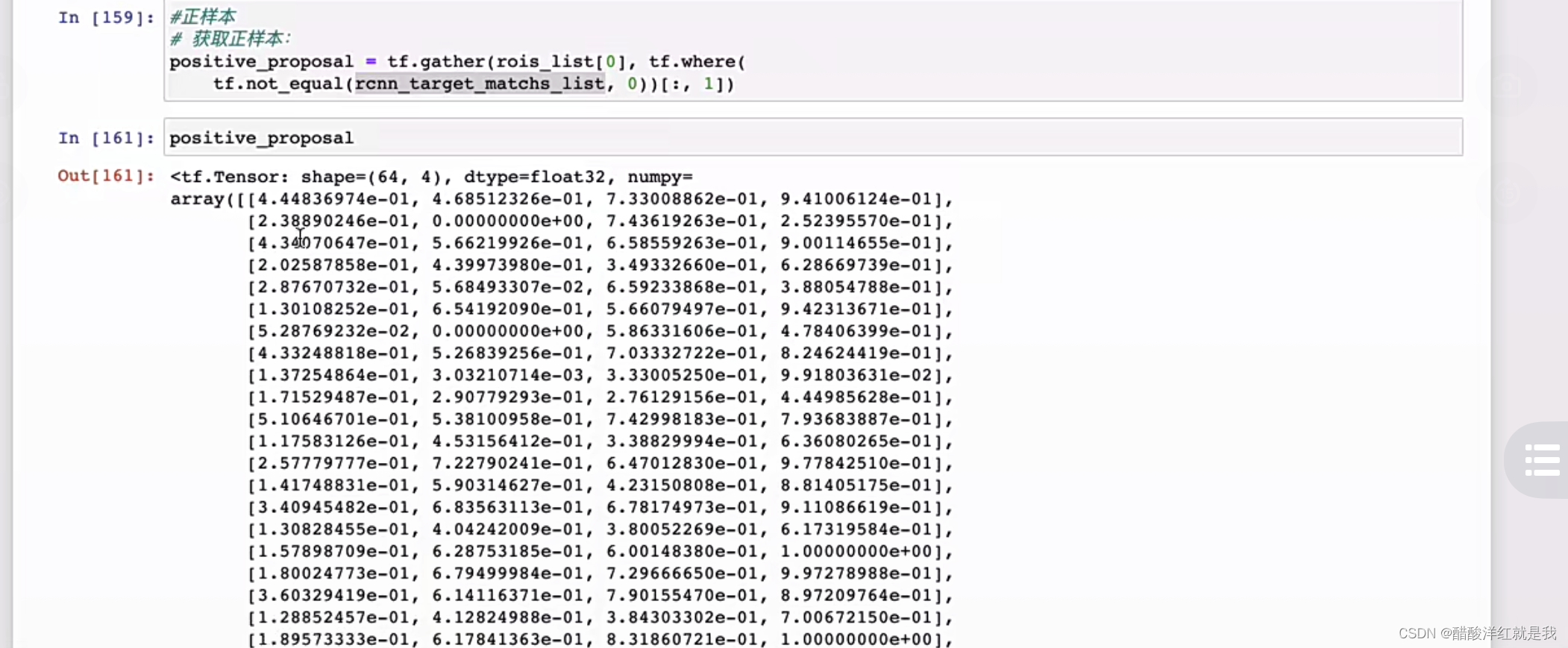
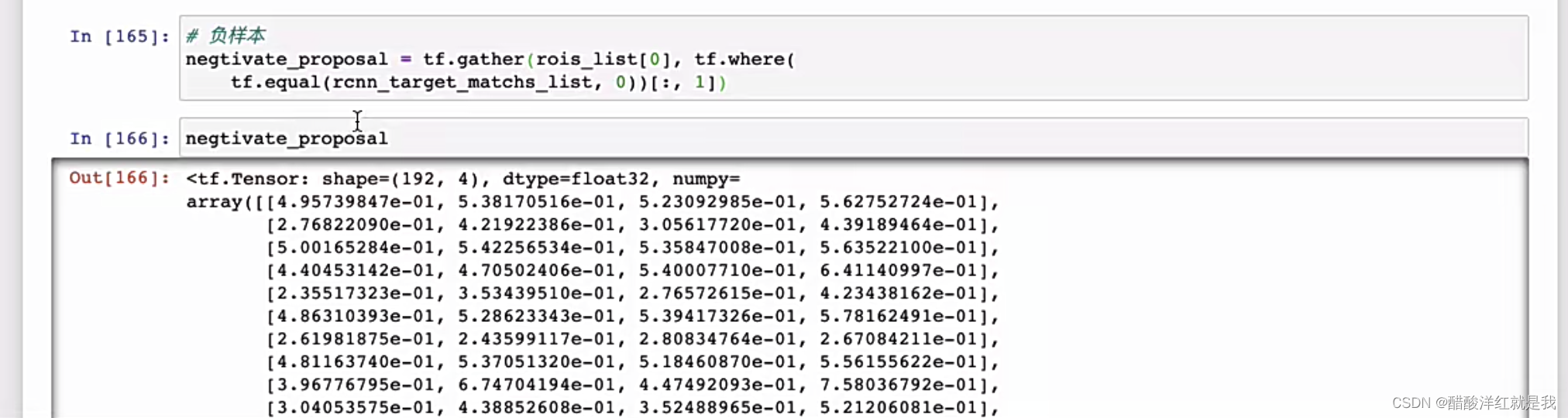
损失函数
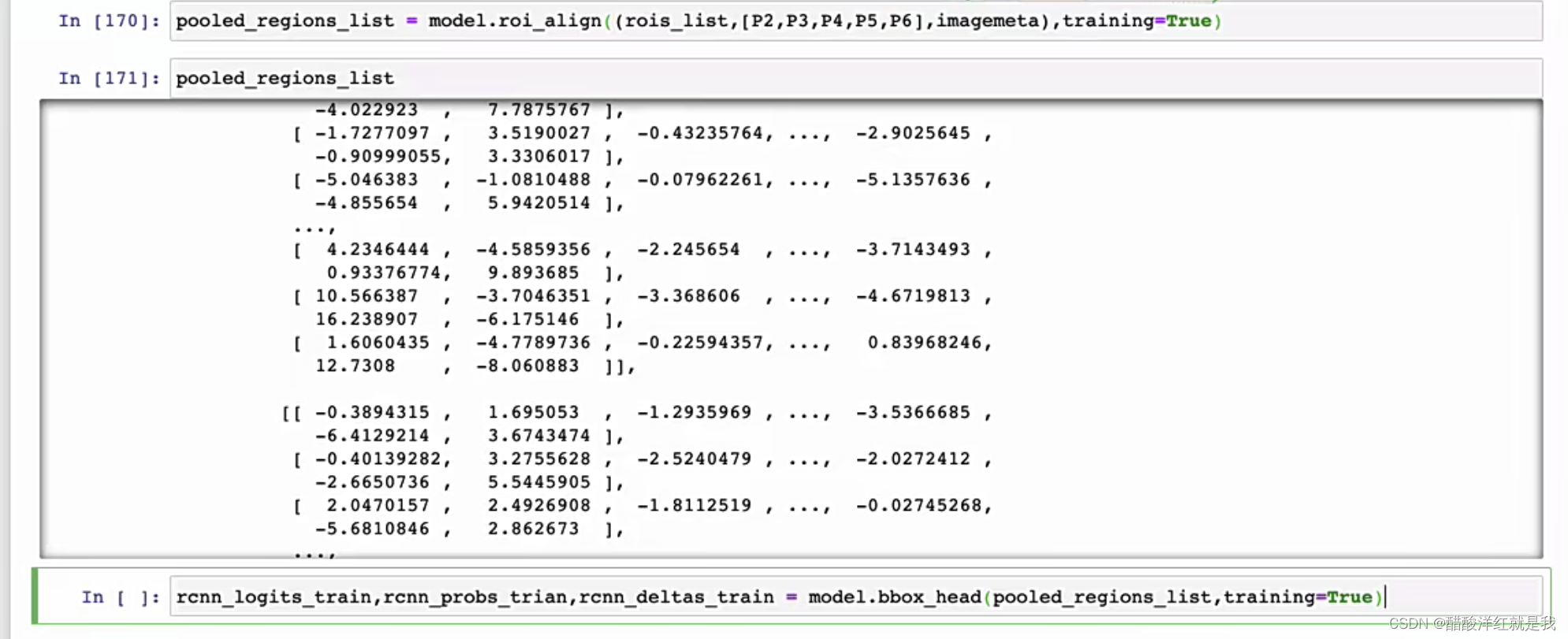

共享卷积训练

端到端训练

数据加载


模型实例化

模型训练
#导入工具吧
from detection.datasets import pascal_voc
from detection.model.detectors import faster_rcnn
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
#数据获取
train_dataset=pascal_voc.pascal_voc('train')
num_classes=len(train_dataset.classes)
#加载模型
model=faster_rcnn.FasterRCNN(num_classes=num_classes)
#优化器
optimizer=tf.keras.optimizers.SGD(1e-3,momentum=0.1,nesterov=True)
#损失函数变化列表
loss_his=[]
#使用tf.gradientTape进行训练
#epoch
for epoch in range(2):
#获取索引
indices=np.arange(train_dataset.num_gtlabels)
np.random.shufflele(indices)
#迭代次数
iter=np.round(train_dataset.num_gtlabels/train_dataset.batch_size).astype(np.uint8)
for idx in range(iter):
#获取batch数据索引
idx=indices[idx]
#获取batch_size
batch_image,batch_metas,batch_bboxes,batch_label=train_dataset[idx]
#梯度下降
with tf.GradientTape() as tape:
#计算损失函数
rpn_class_loss,rpn_bbox_loss,rcnn_class_loss,rcnn_bbox_loss=model((batch_image,batch_metas,batch_bboxes,batch_label),training=True)
#总损失
loss=rpn_class_loss+rpn_bbox_loss+rcnn_bbox_loss+rcnn_class_loss
#计算梯度
grads=tape.gradient(loss,model.trainable_variables)
#更新参数值
optimizer.apply_gradients(zip(grads,model.trainable_variables))
print('epoch:%d,batch:%d,loss:%f'%(epoch+1,idx,loss))
loss_his.append(loss)



![学习babylon.js --- [3] 开启https](https://img-blog.csdnimg.cn/de5381c579a1456f981f34e9b42c8a60.png)