



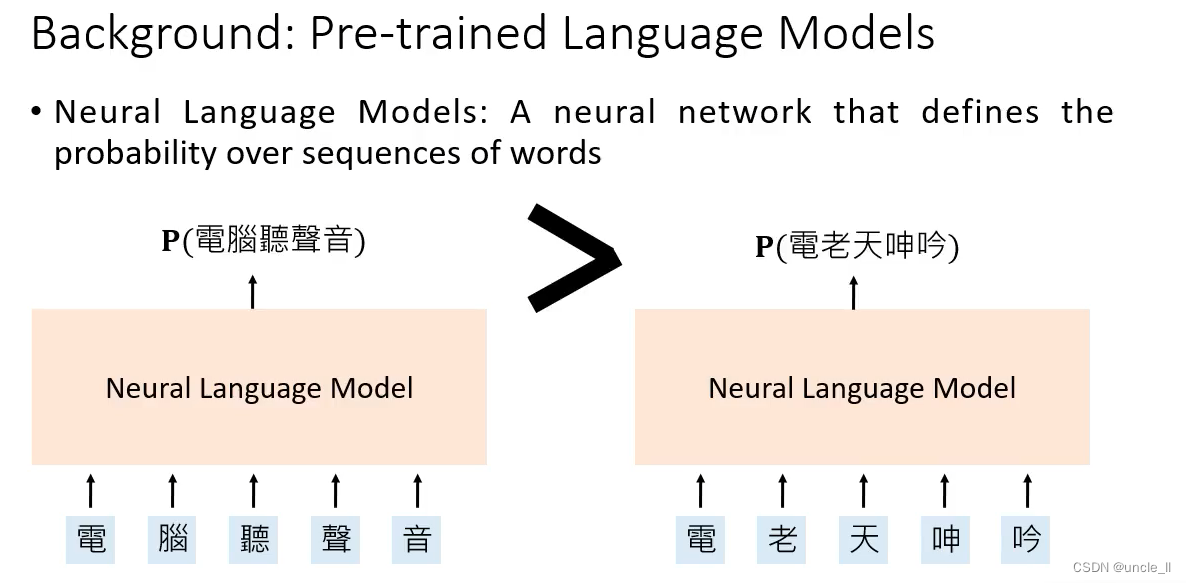
背景
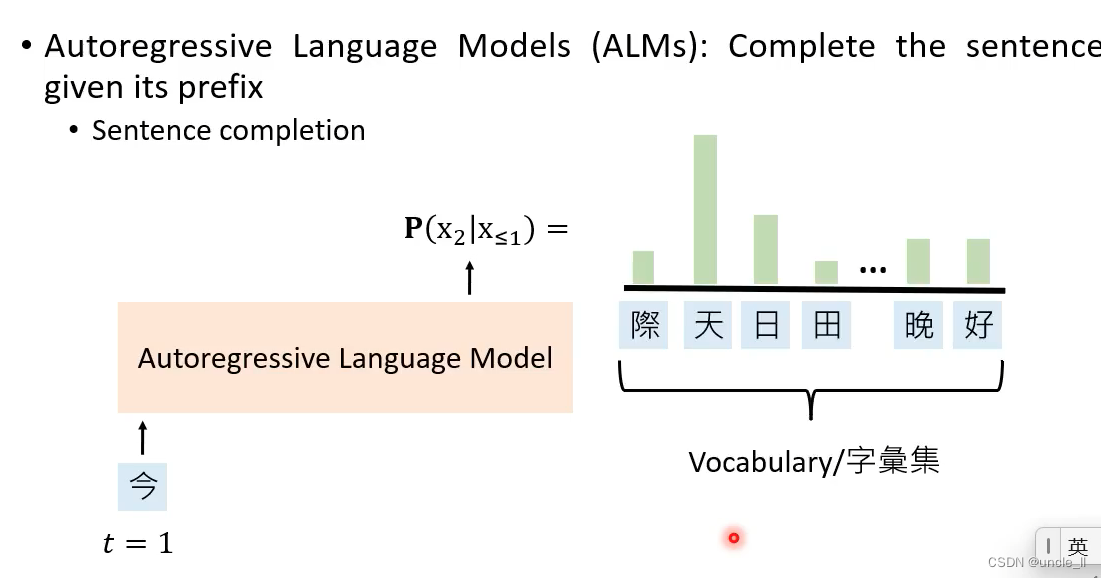
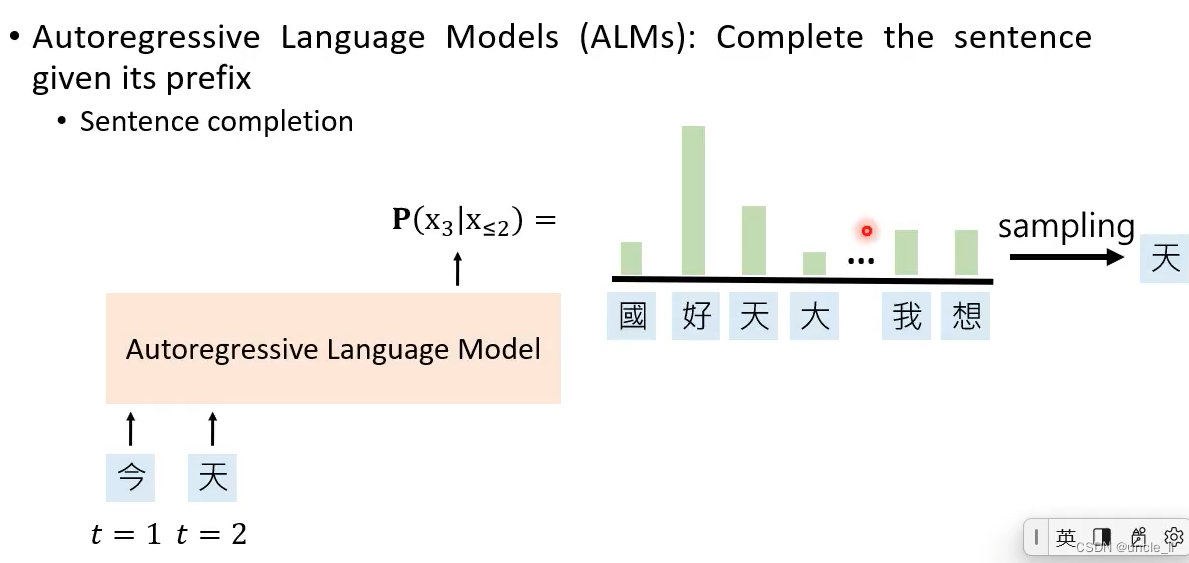
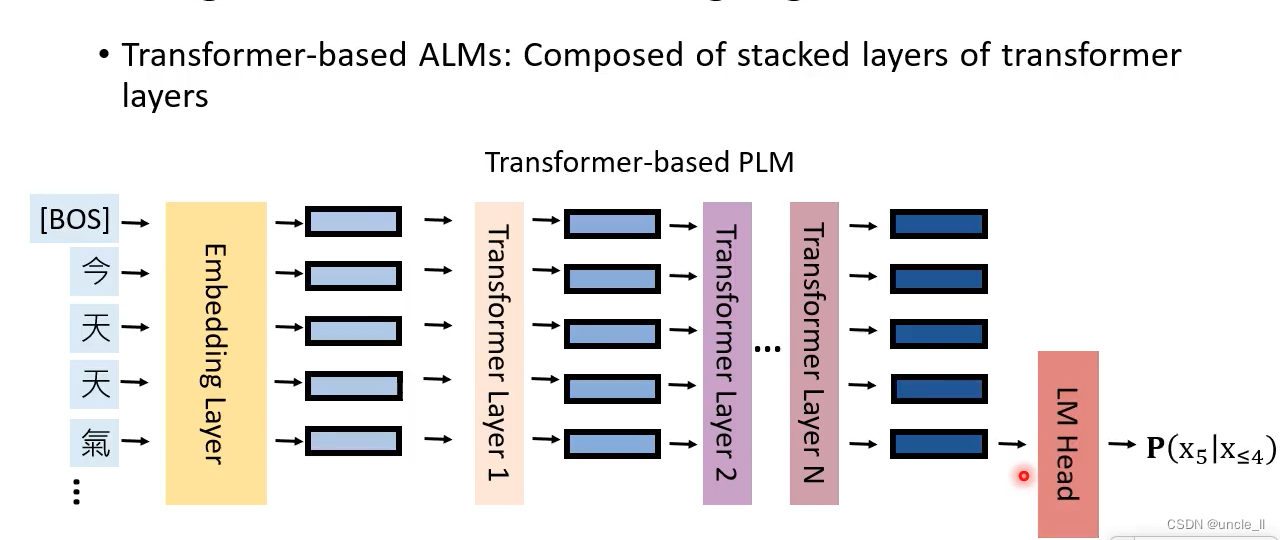
Autoregressive Langeuage Models
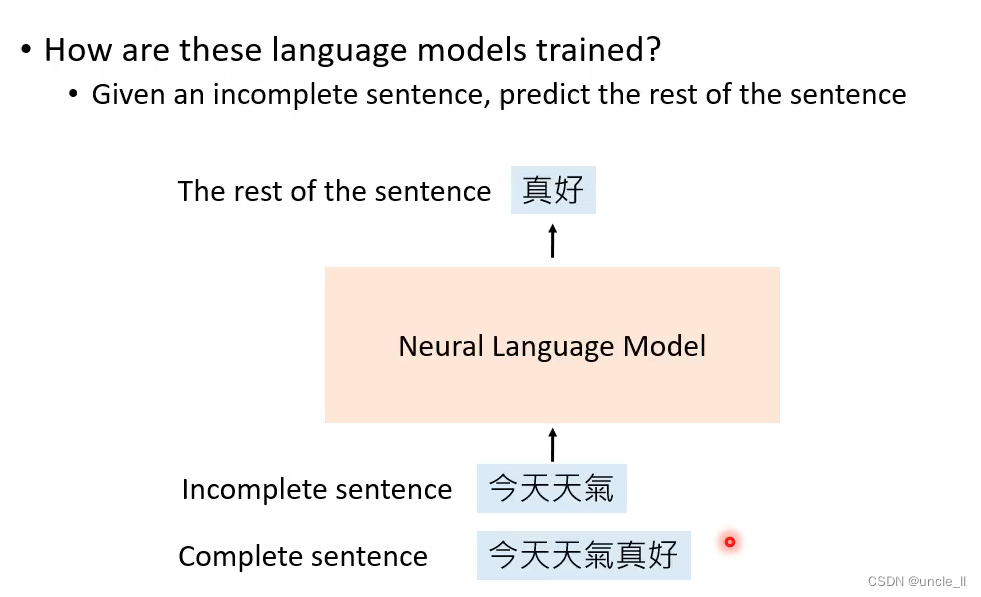
不完整的句子,预测剩下的空的词语
- sentence completion

Transformer-based ALMs
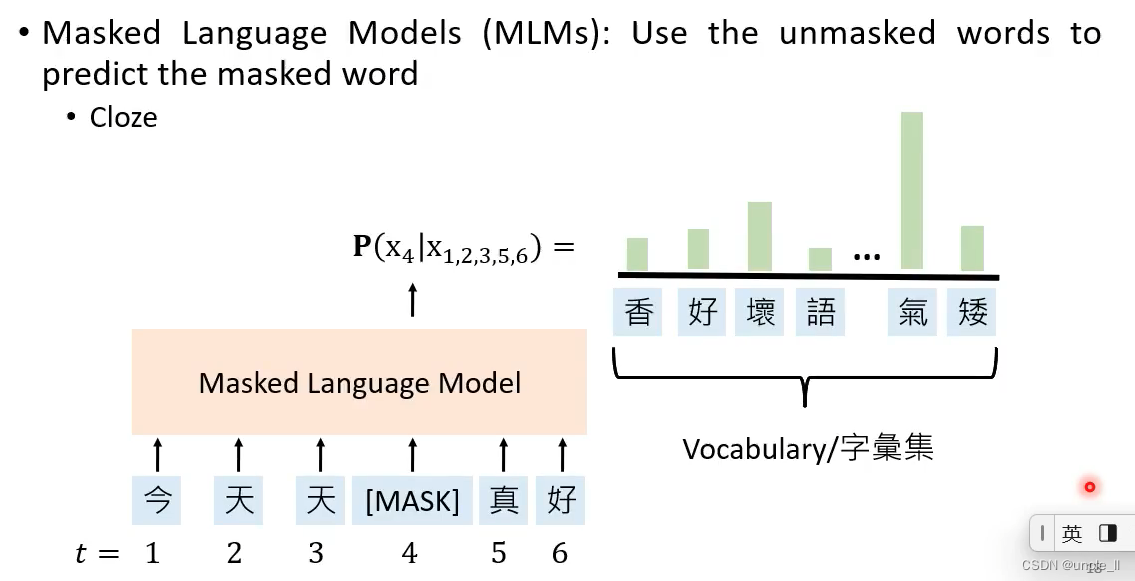
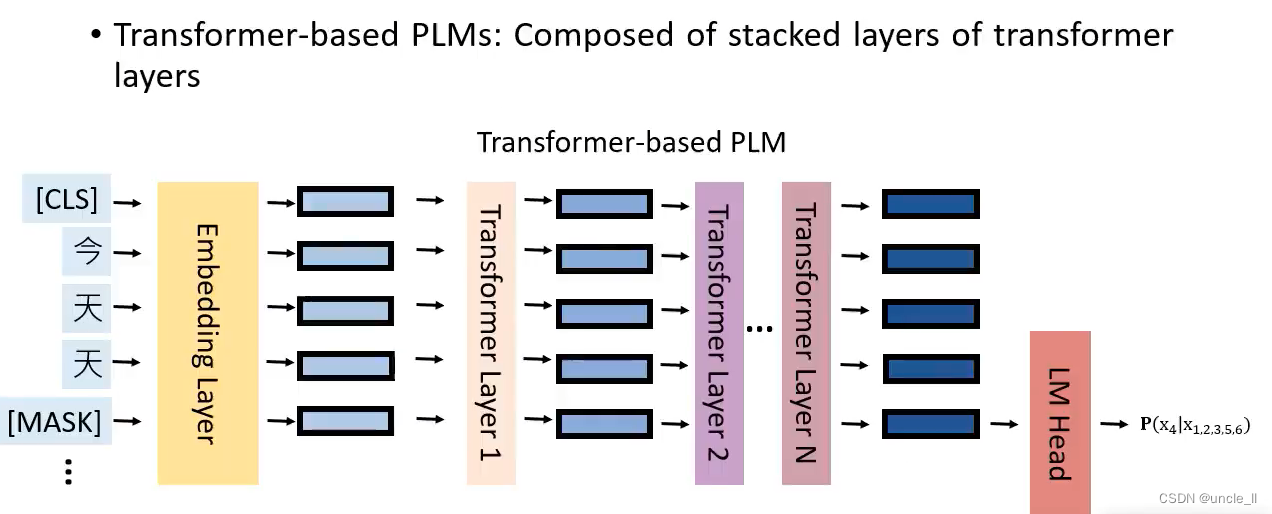
Masked language models-MLMs

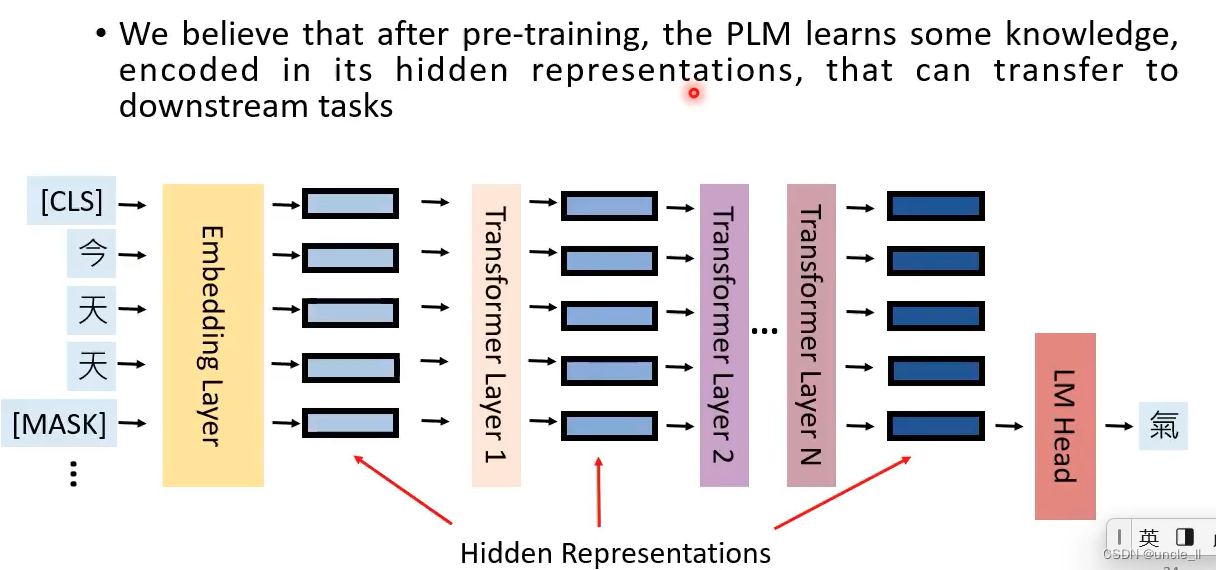
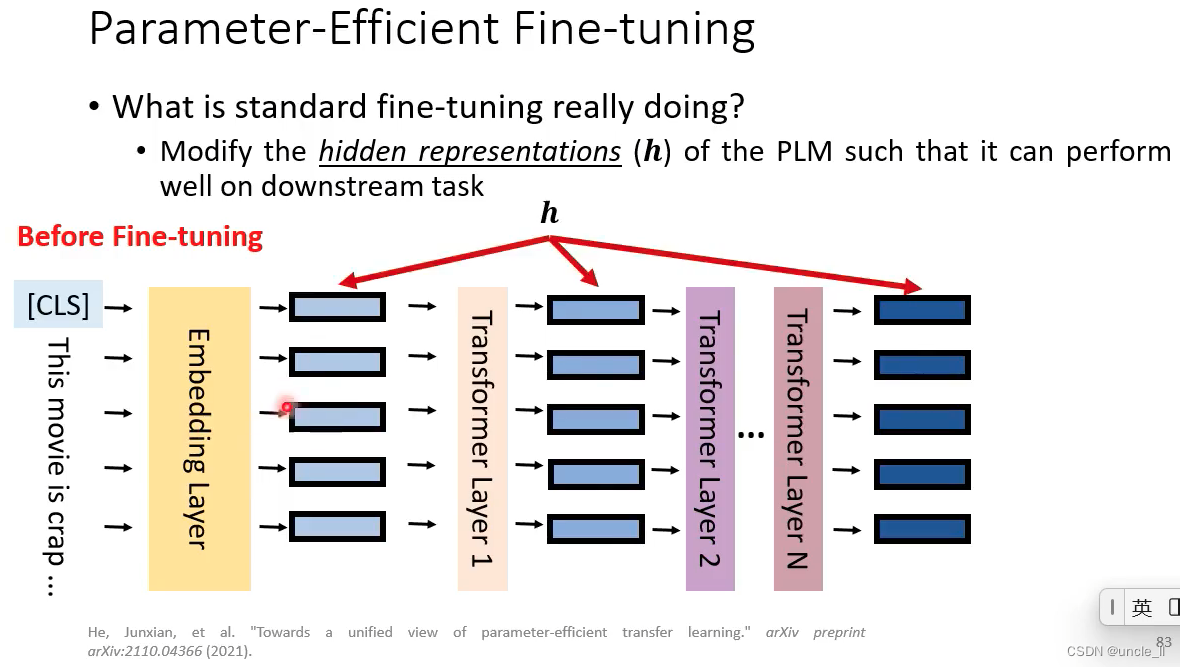
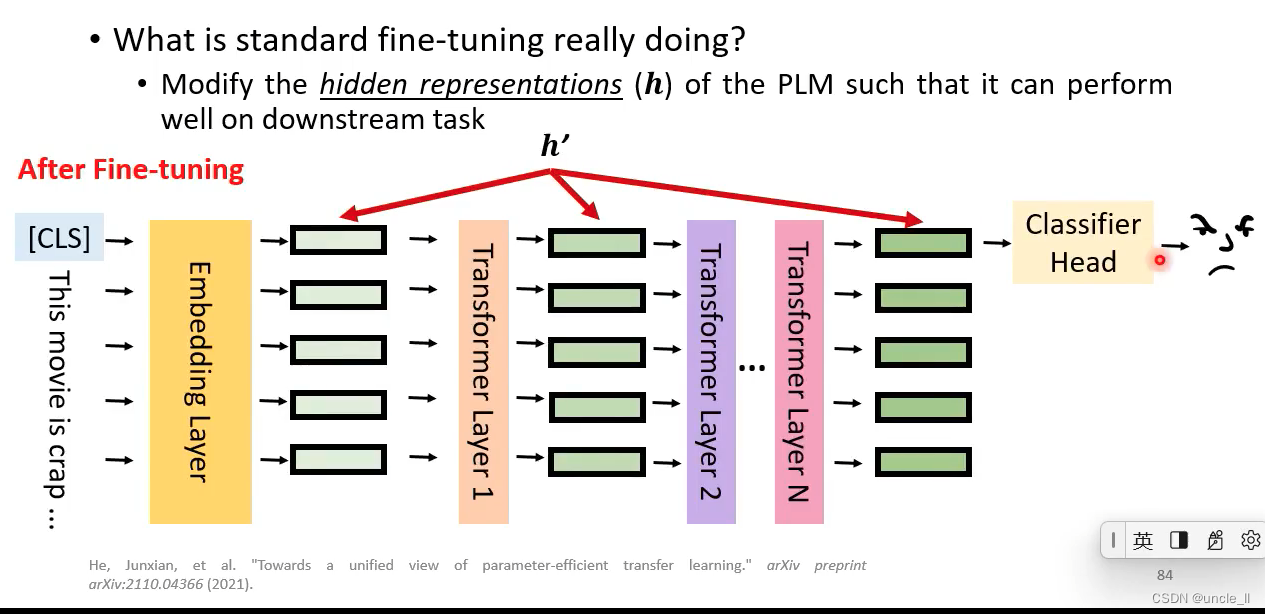
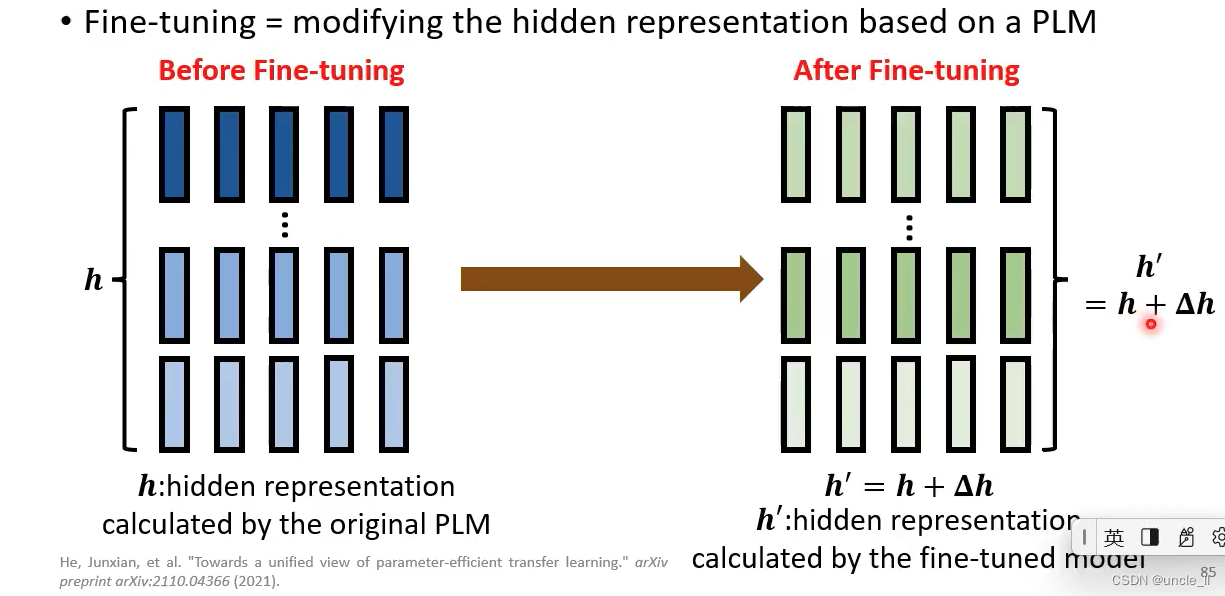
预训练模型能将输入文本转成hidden feature representation
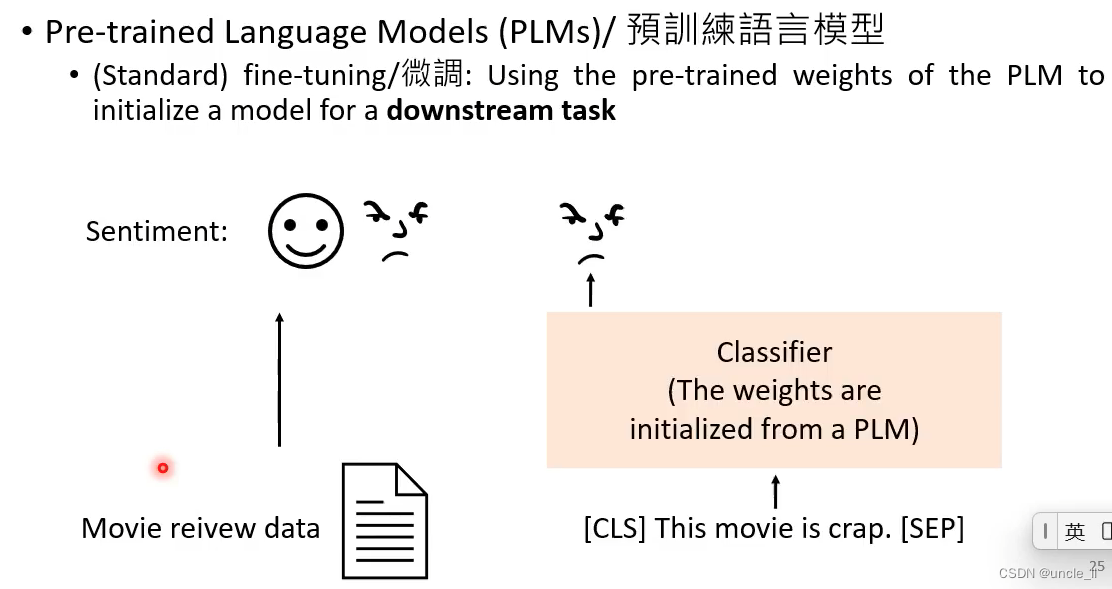
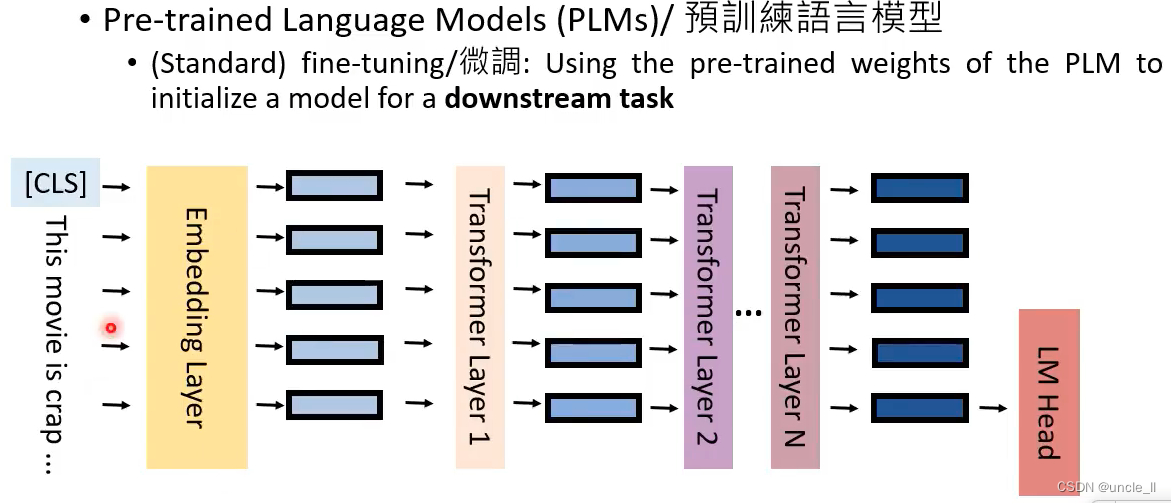
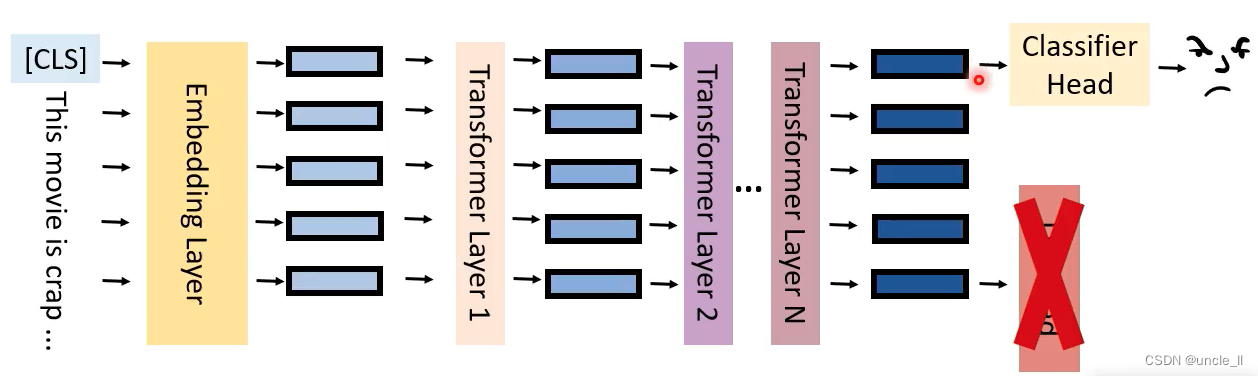
模型参数最开始是从预训练模型中拿到,然后给予具体任务再微调,中间模型参数可固定也可以微训练
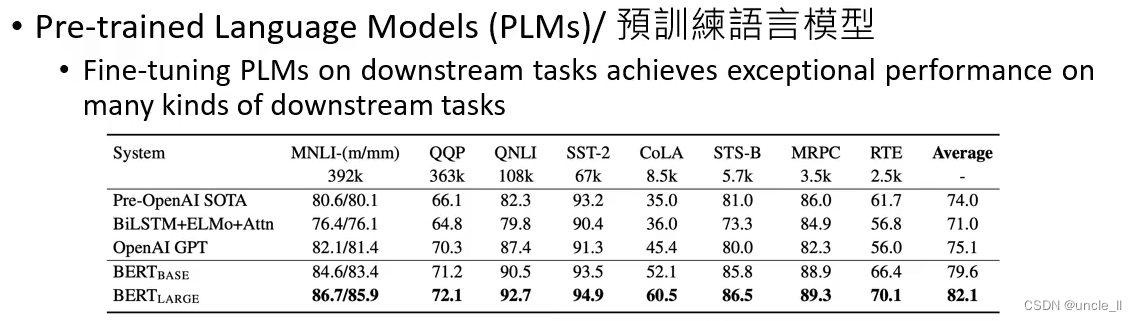
- 相关paper



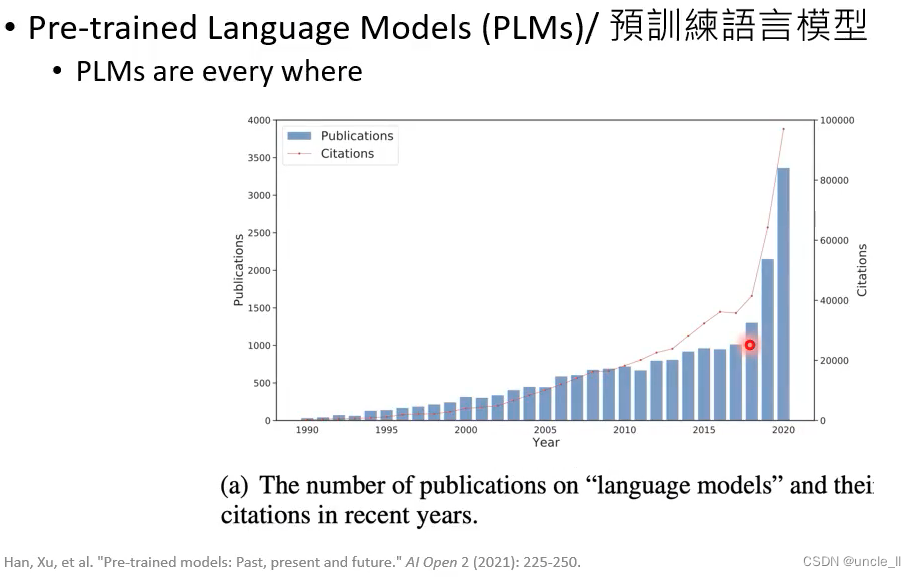
The Problems of PLMs
问题1:有label的数据少
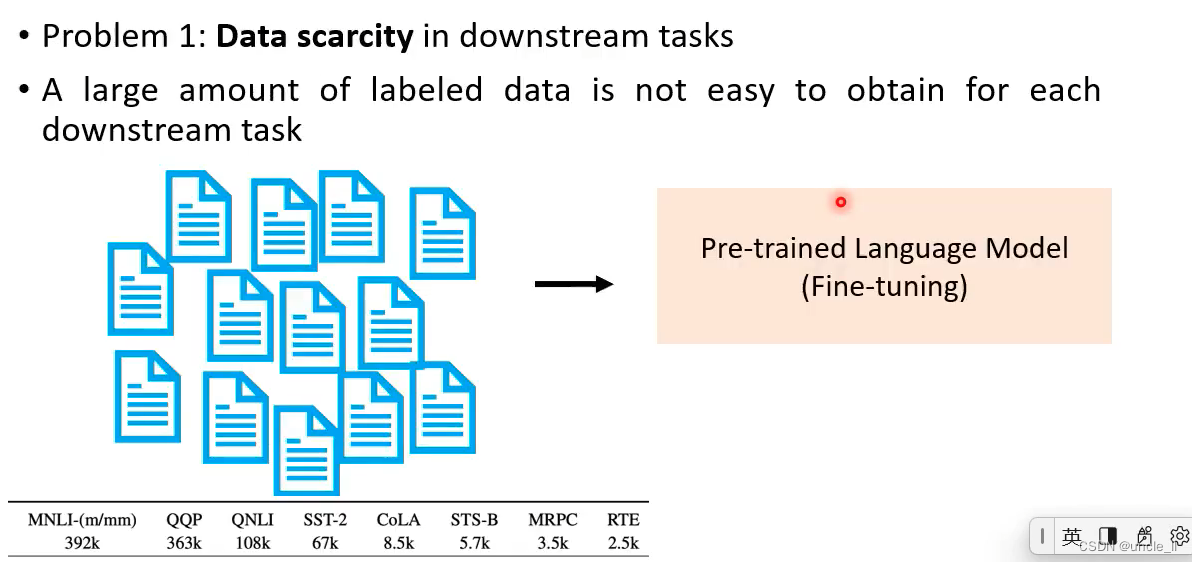
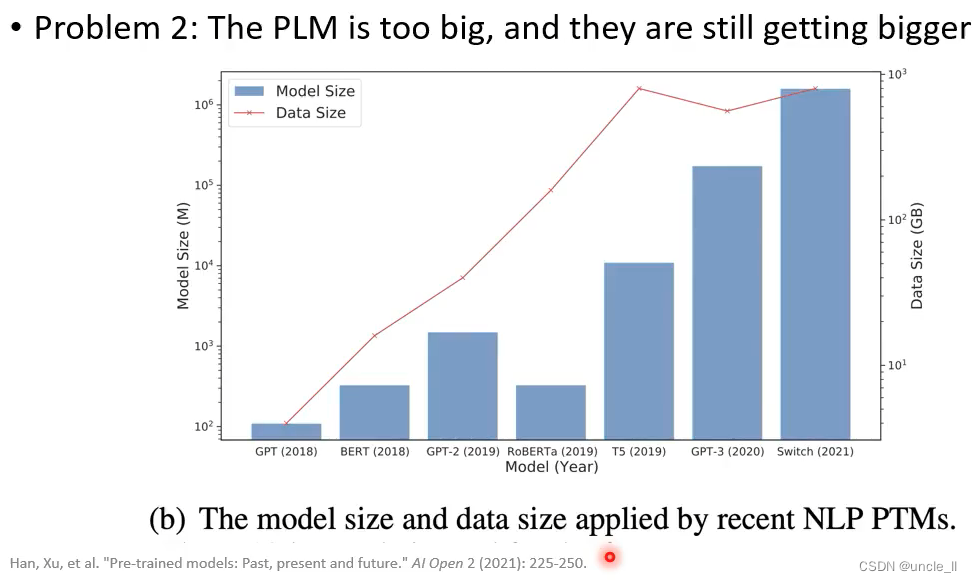
问题2:模型慢慢越来越大了,推理费时间
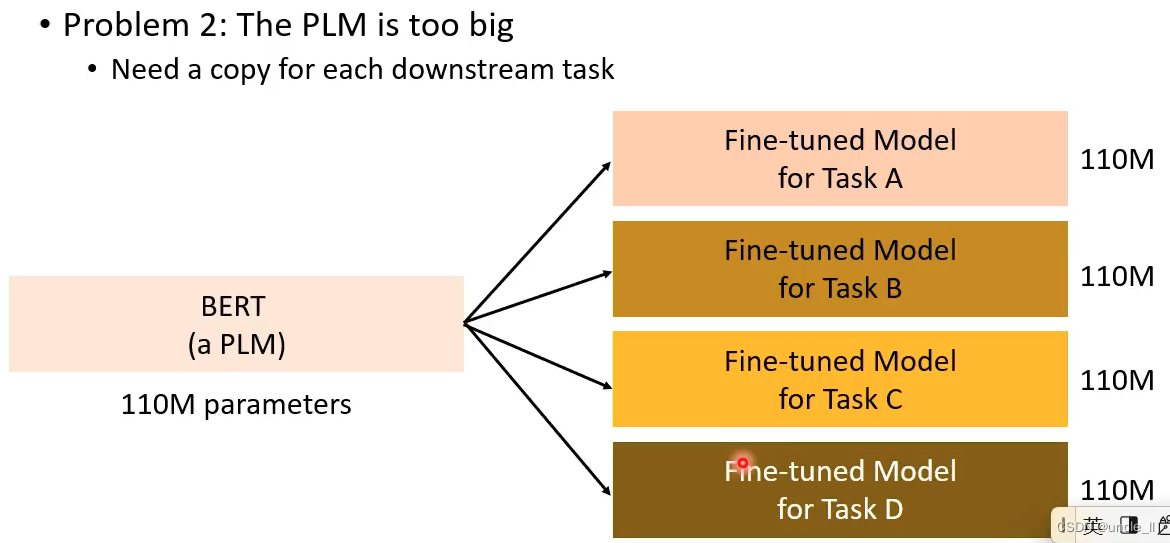
4个任务需要4倍显存大小
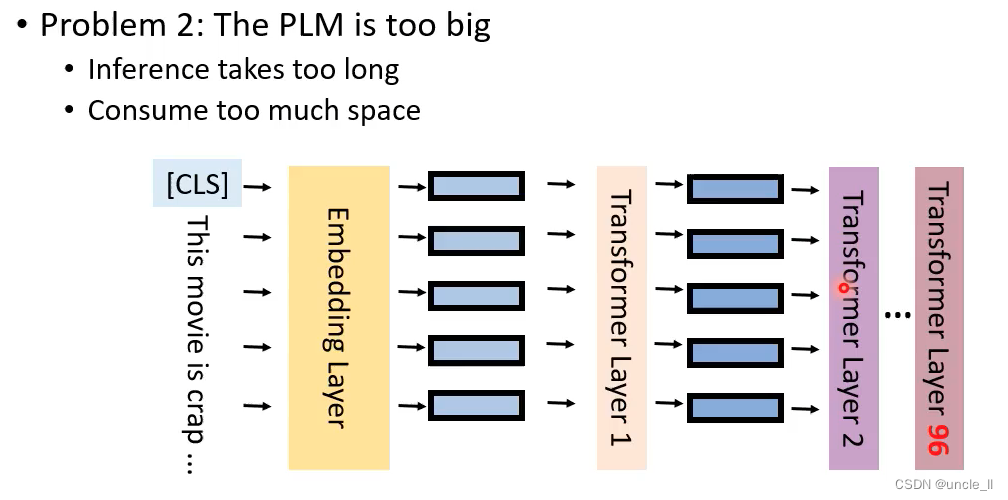
推理耗时长
解决办法
Labeled Data Scarcity——Data-efficient-tuning

当数据少的时候,可能模型无法学习到上述任务功能

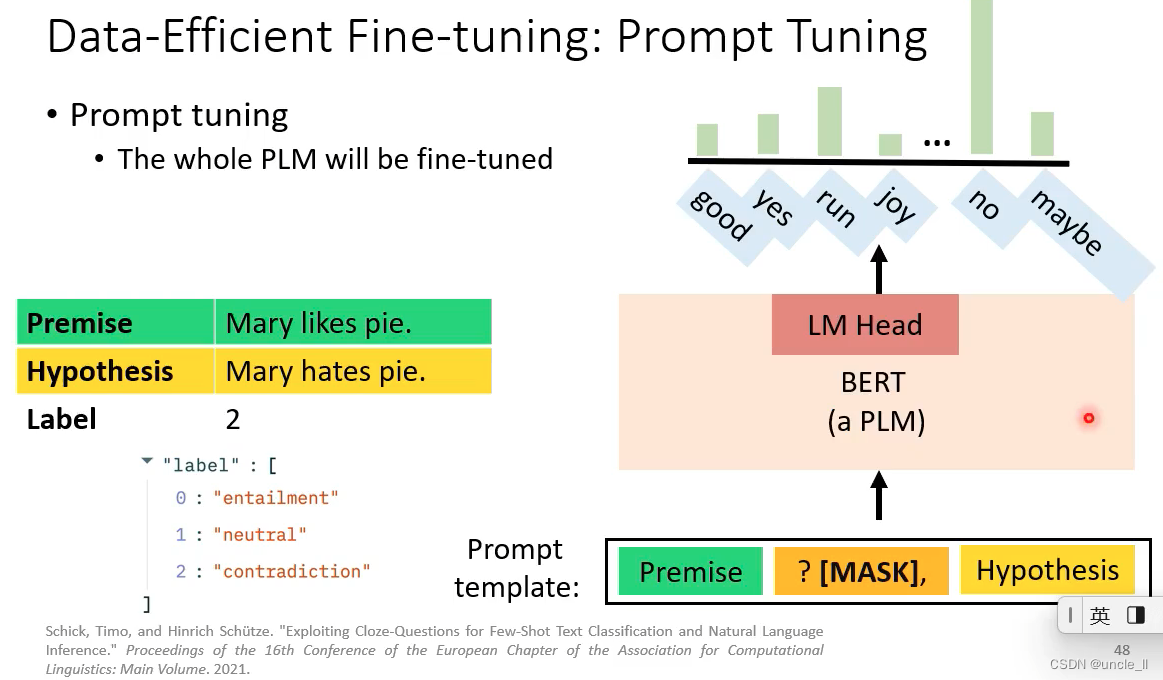
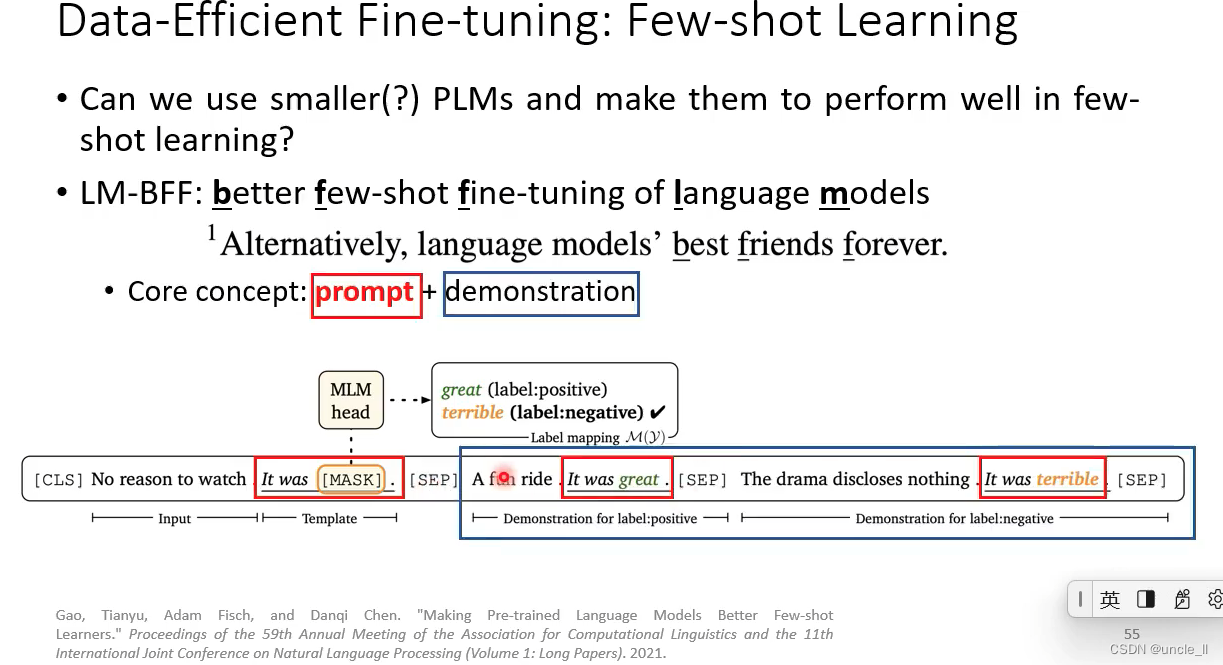
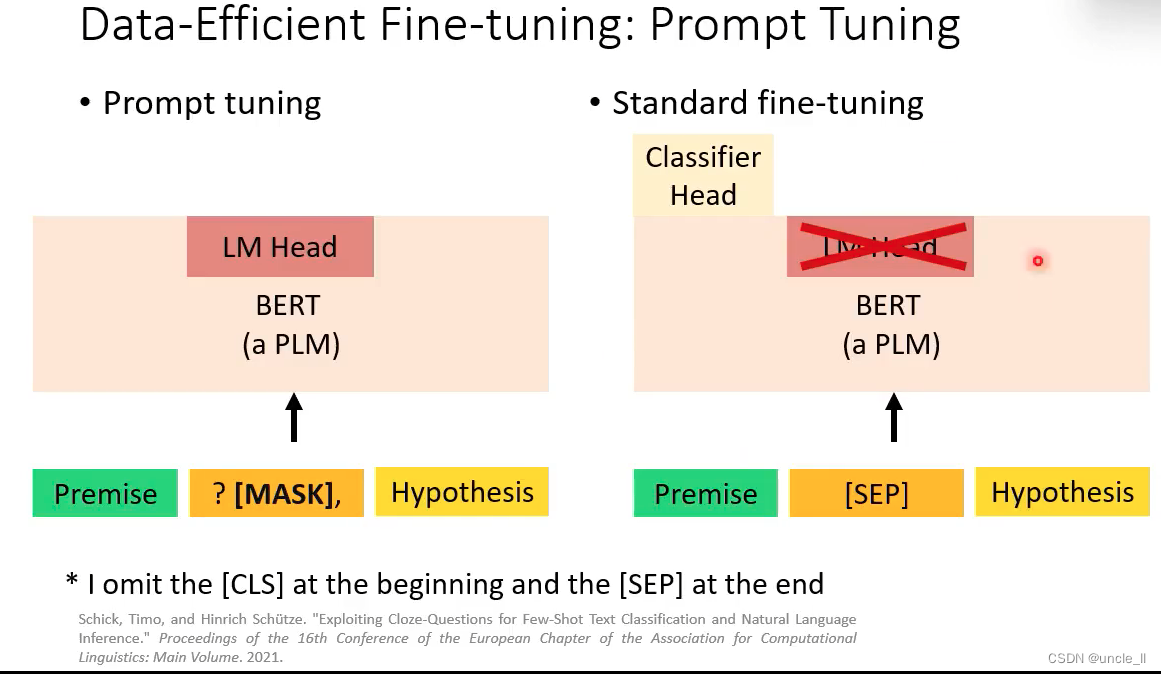
将数据转成自然语言的prompt,模型能更容易知道自己应该做什么
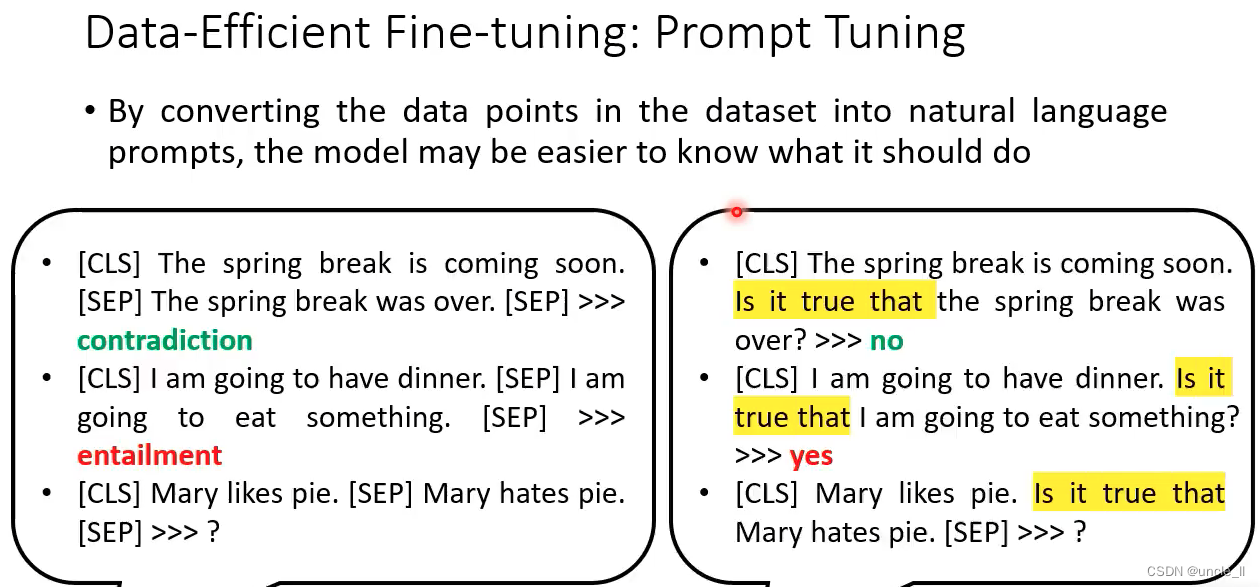

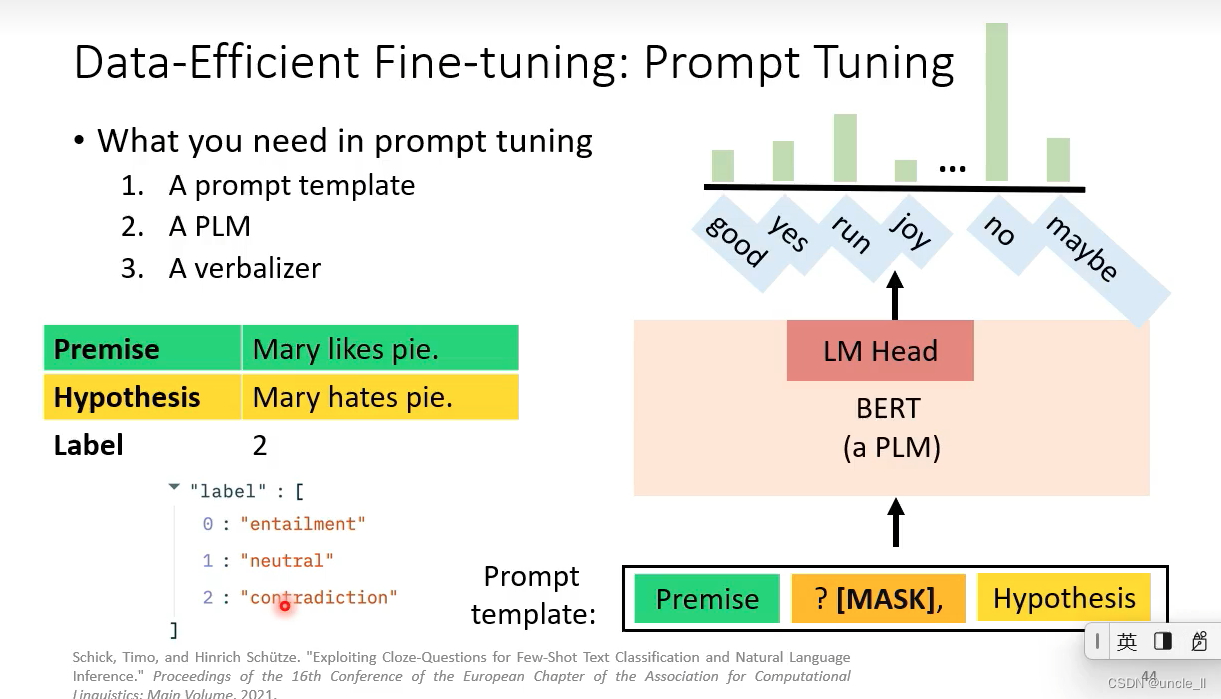
- 1 A prompt template: 告诉模型要做什么事,这里是填充中间的mask
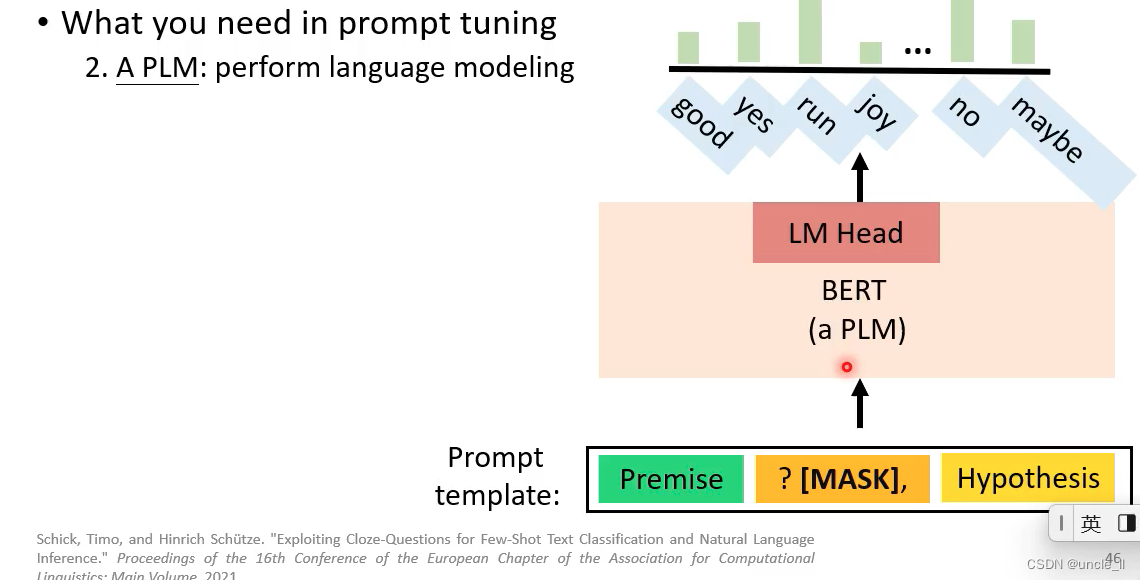
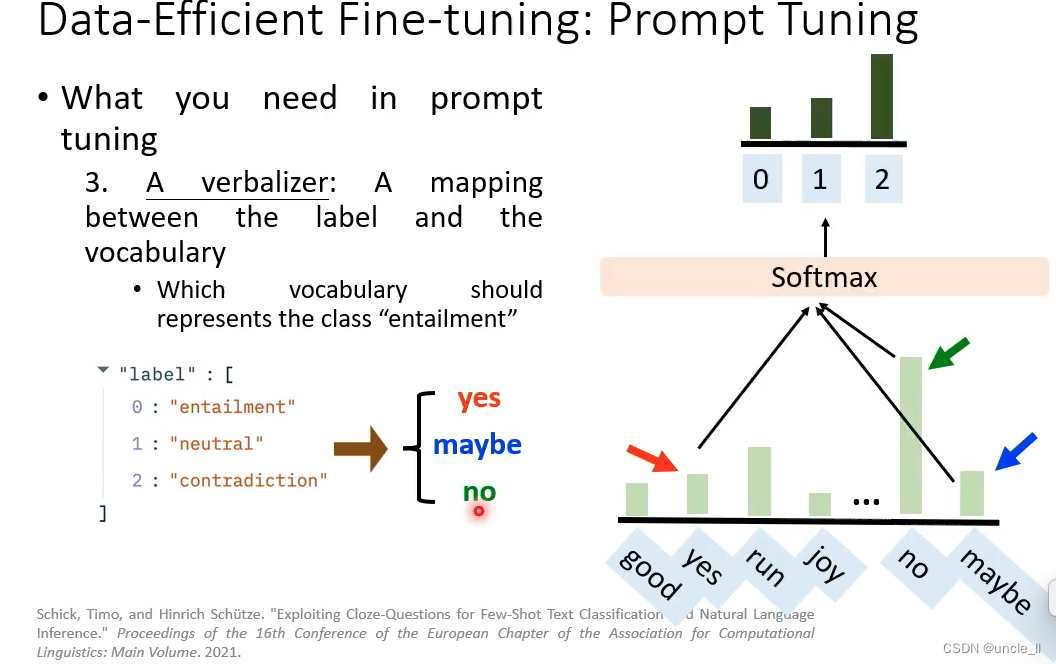
- 2-一个plm模型执行任务,输出概率最大的可能情况
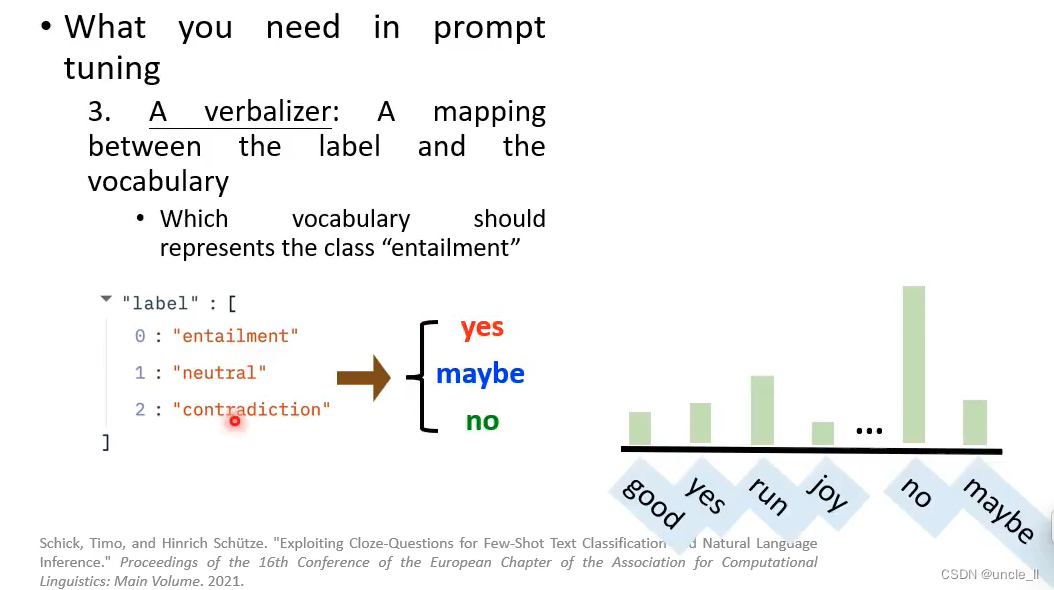
- verbalizer: 将标签和概率映射起来
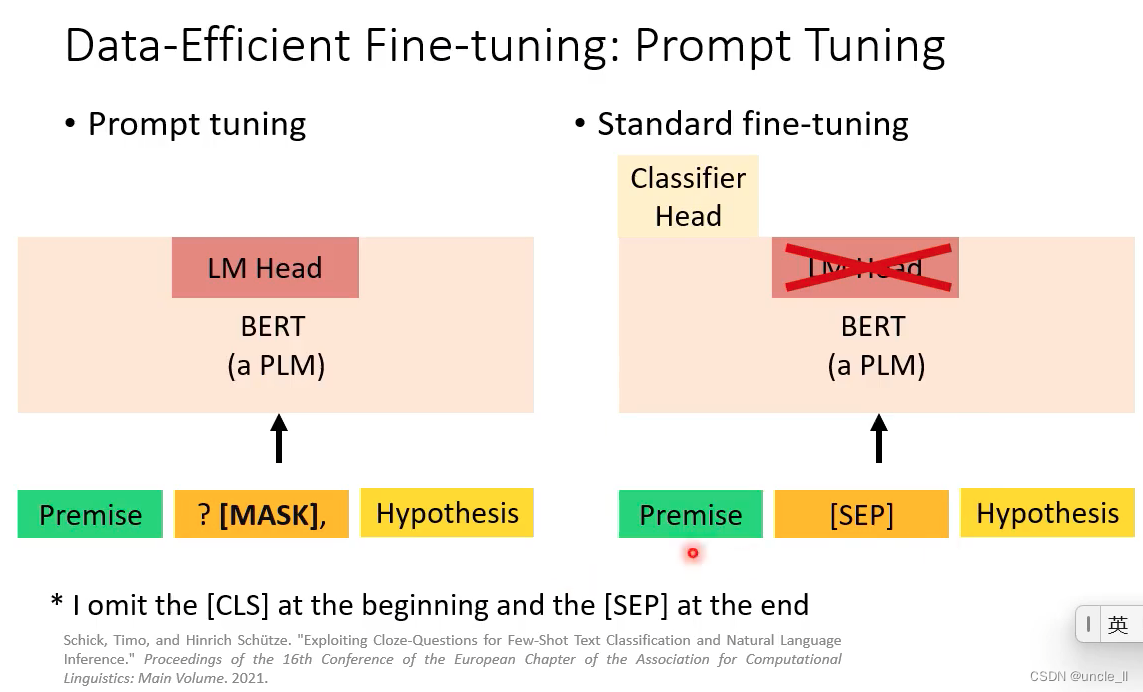
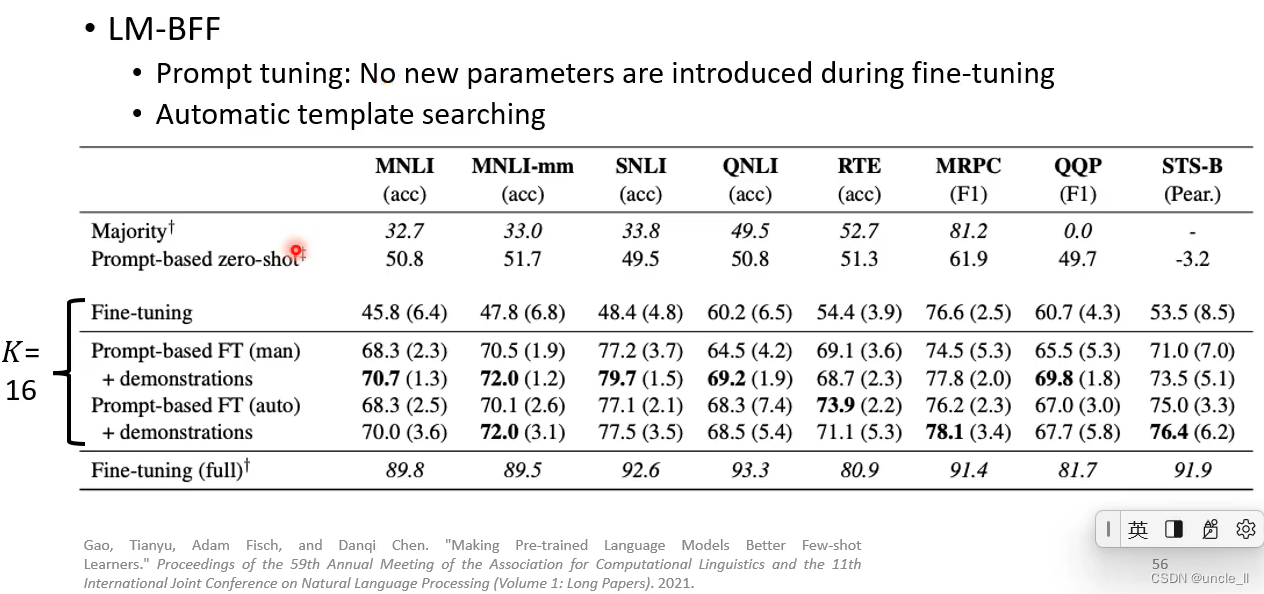
当标注数据比较少的话,标准微调是比较难训练好的;
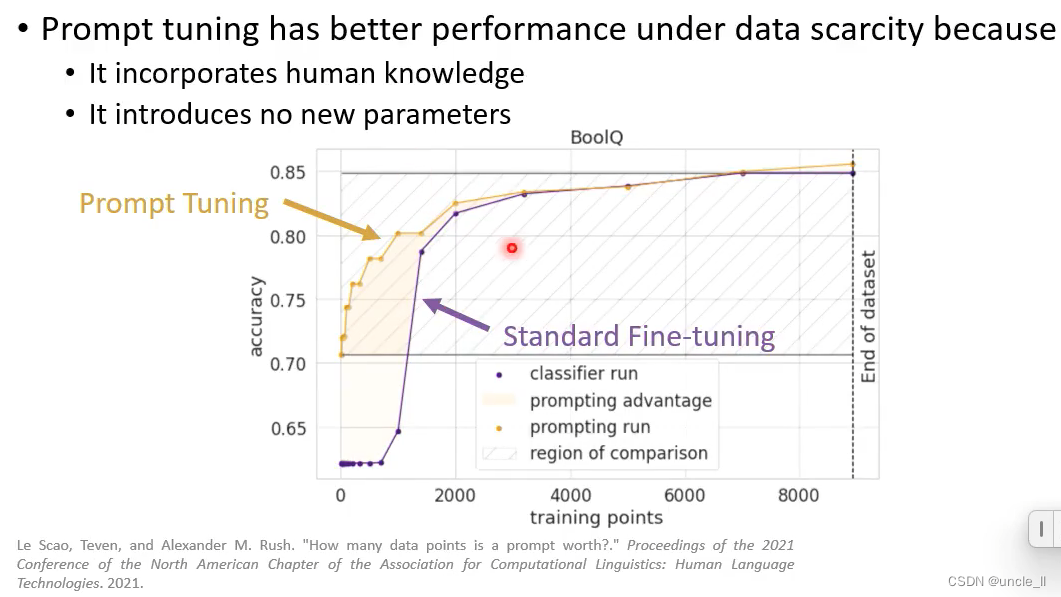

few-shot learning

semi-supervised learning
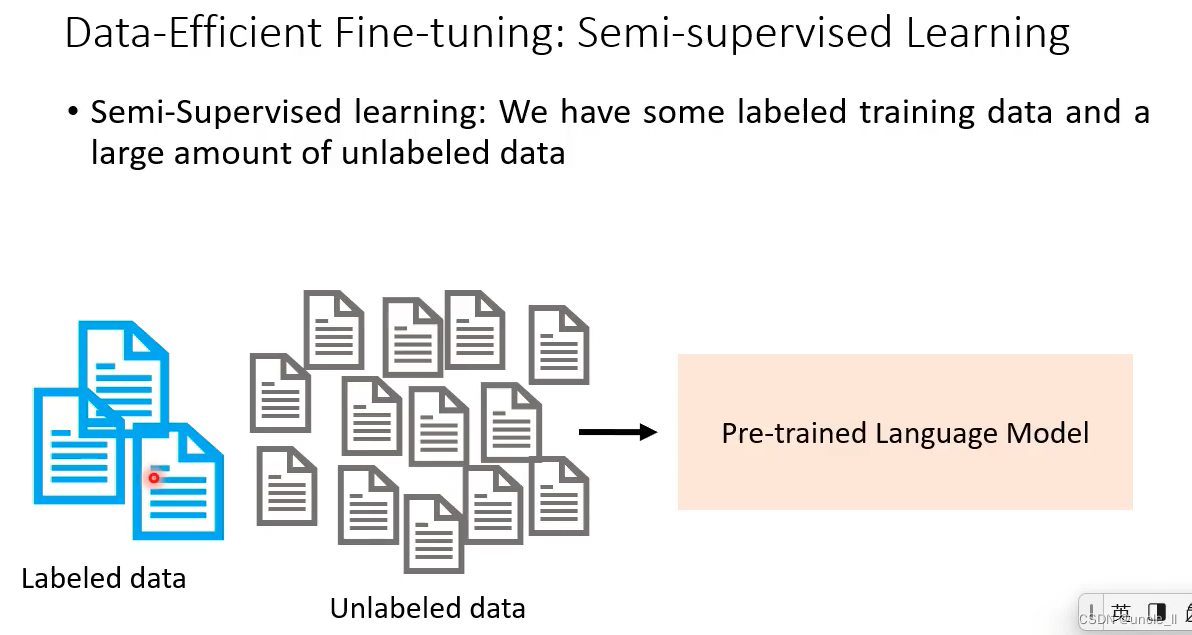

- PET
- 第一步:设计不同的prompt
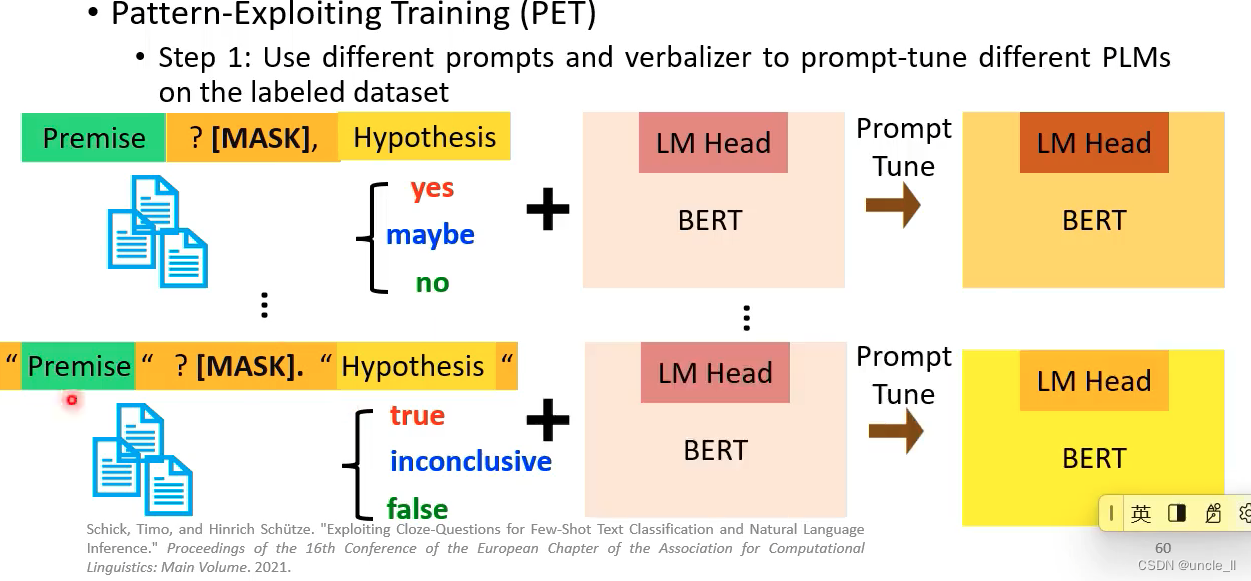
- 第二步:使用多个训练的模型去预测标签,将预测的结果加起来作为总的预测
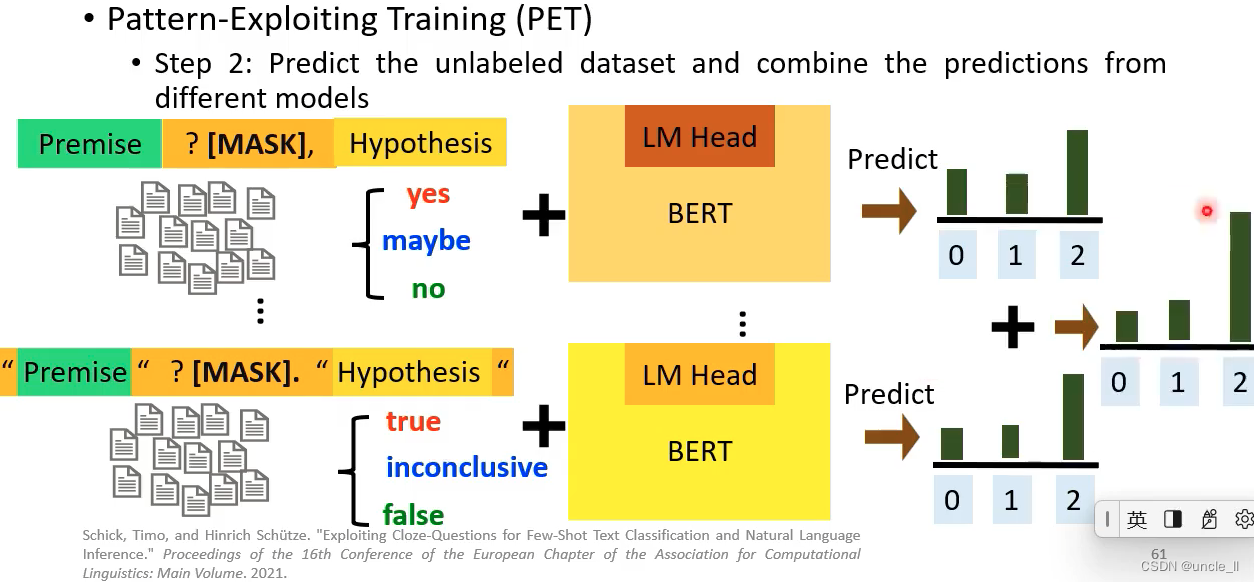
- 第三步:使用标准的训练方法,soft label
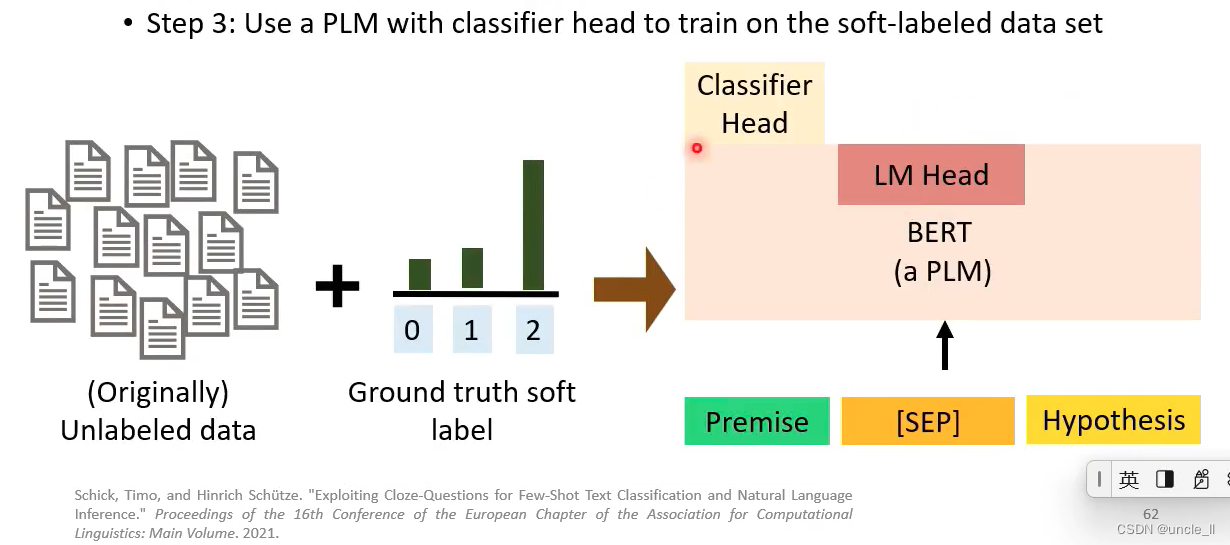
- 第一步:设计不同的prompt
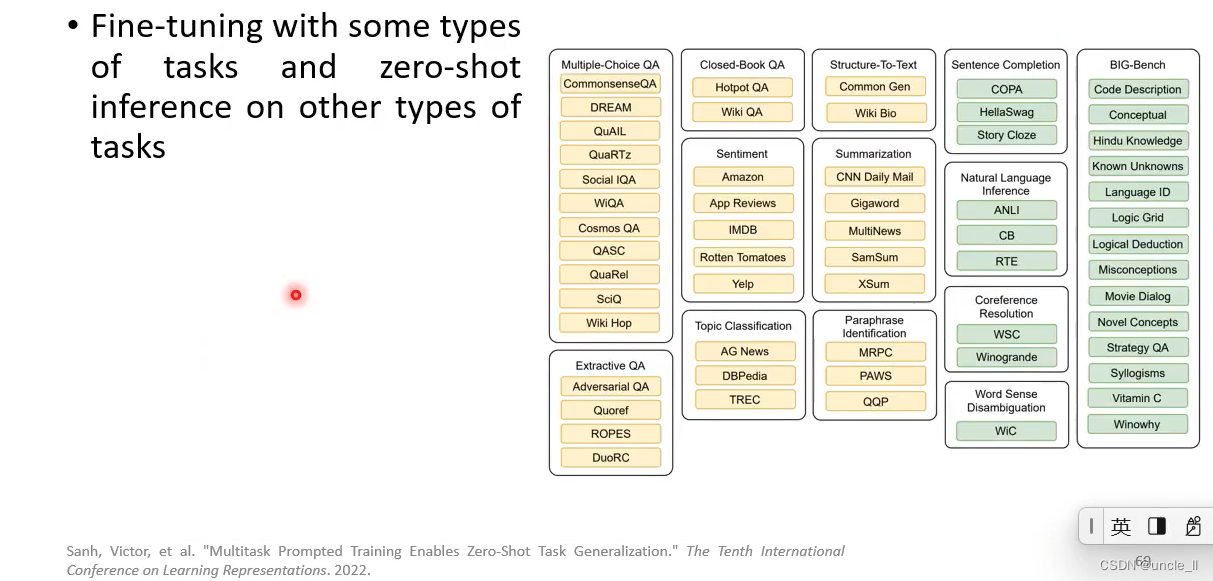
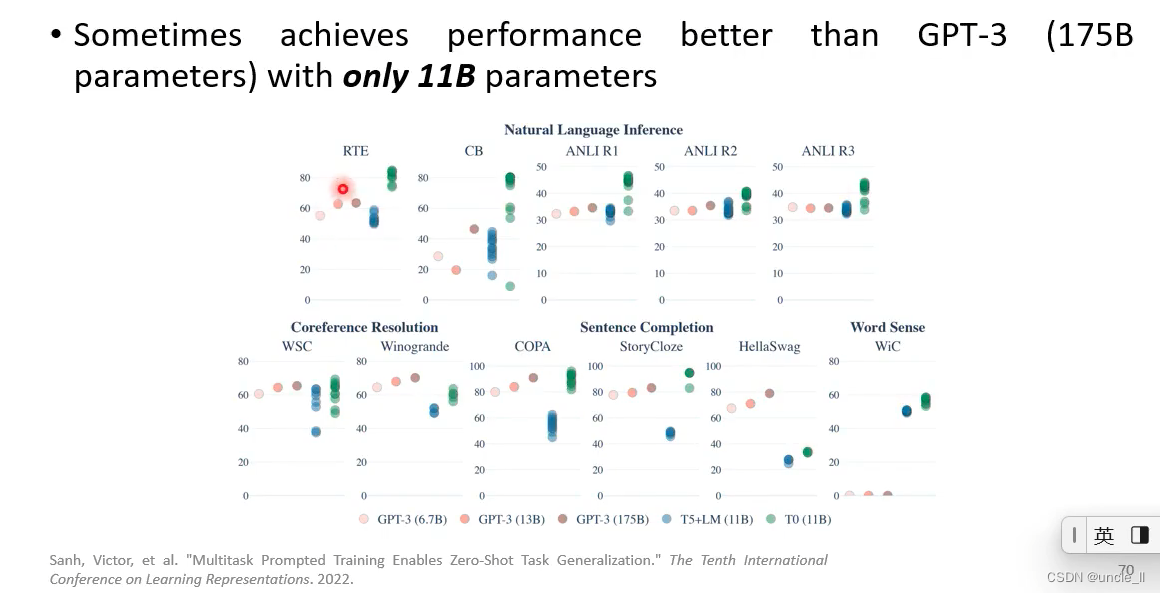
Zero-shot learning
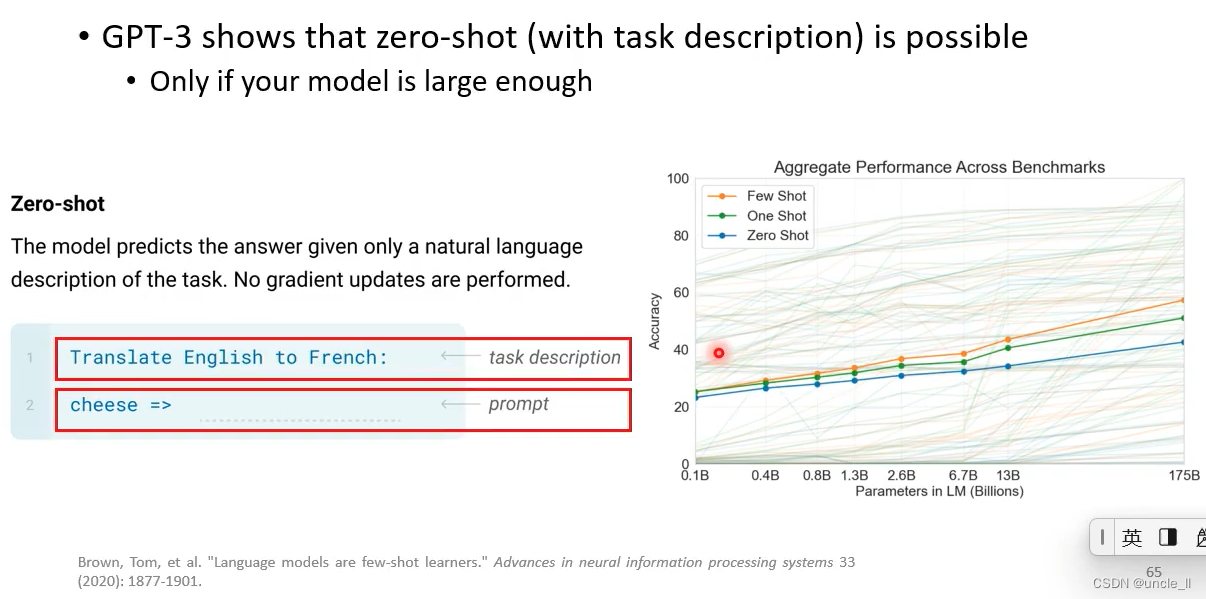
大模型够大,就可以实现zero-shot

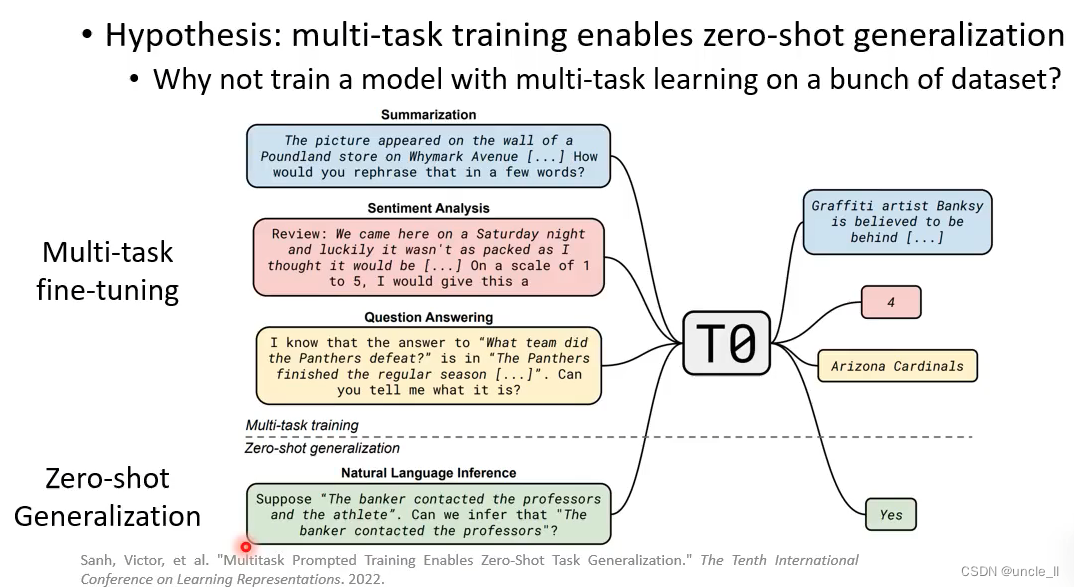
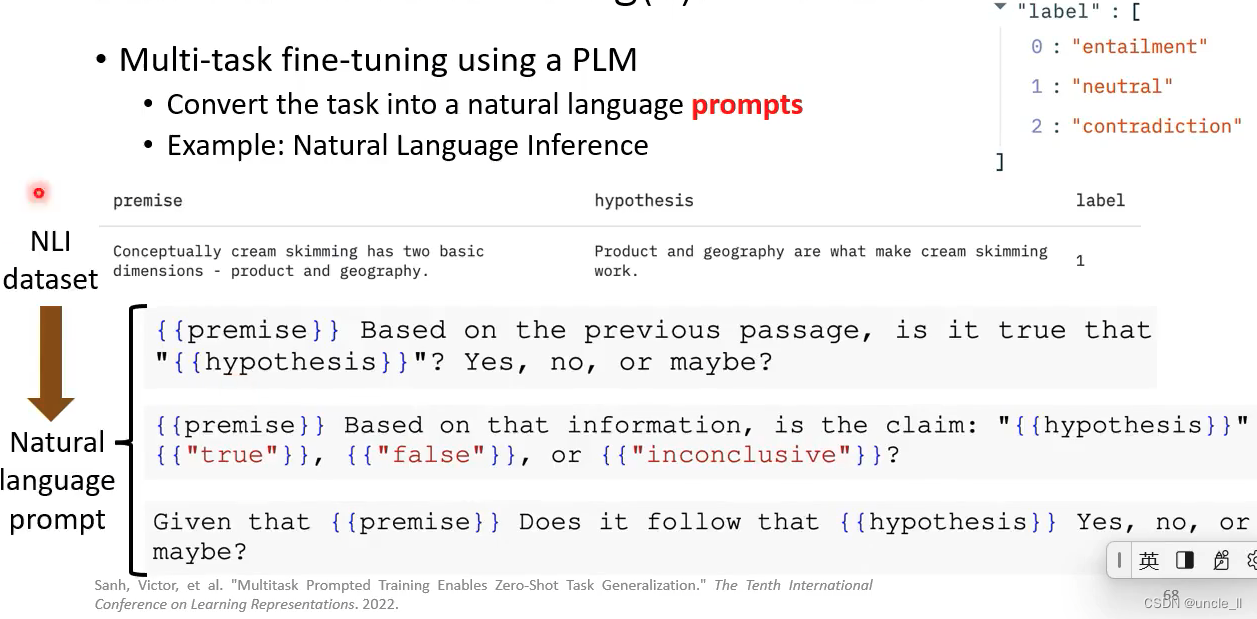
总结
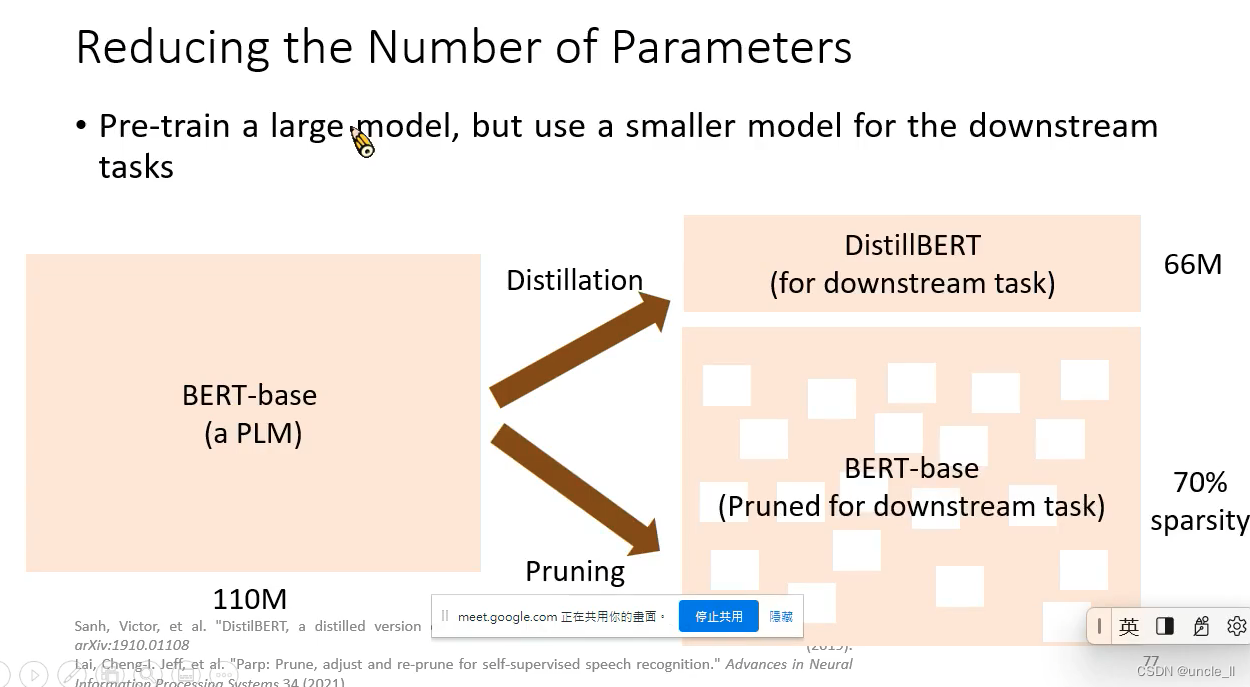
- 蒸馏
- 提纯到下游任务
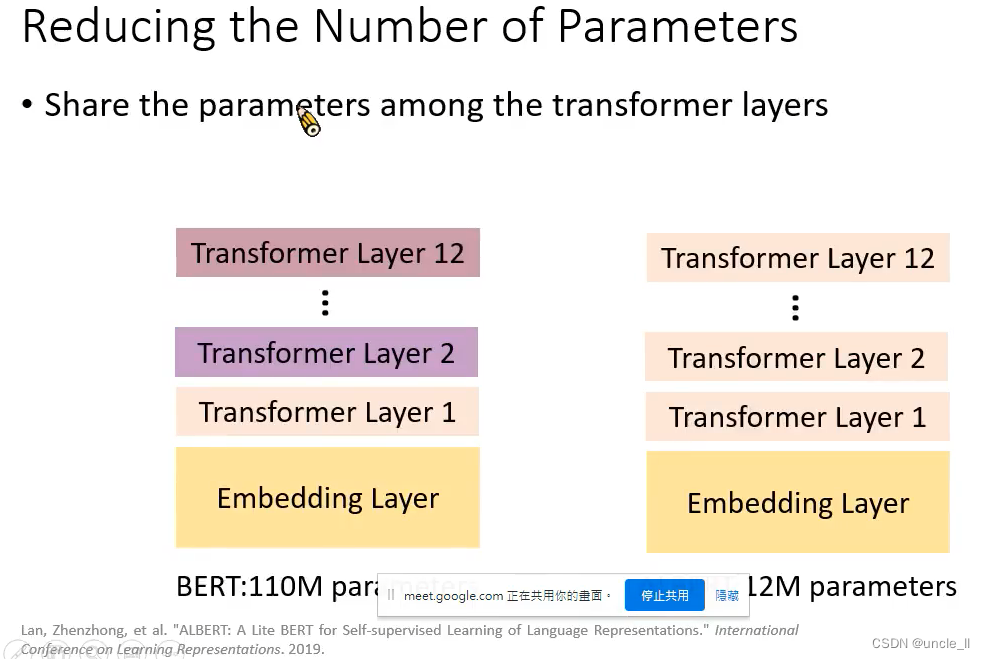
共享相关transfomer layers的参数
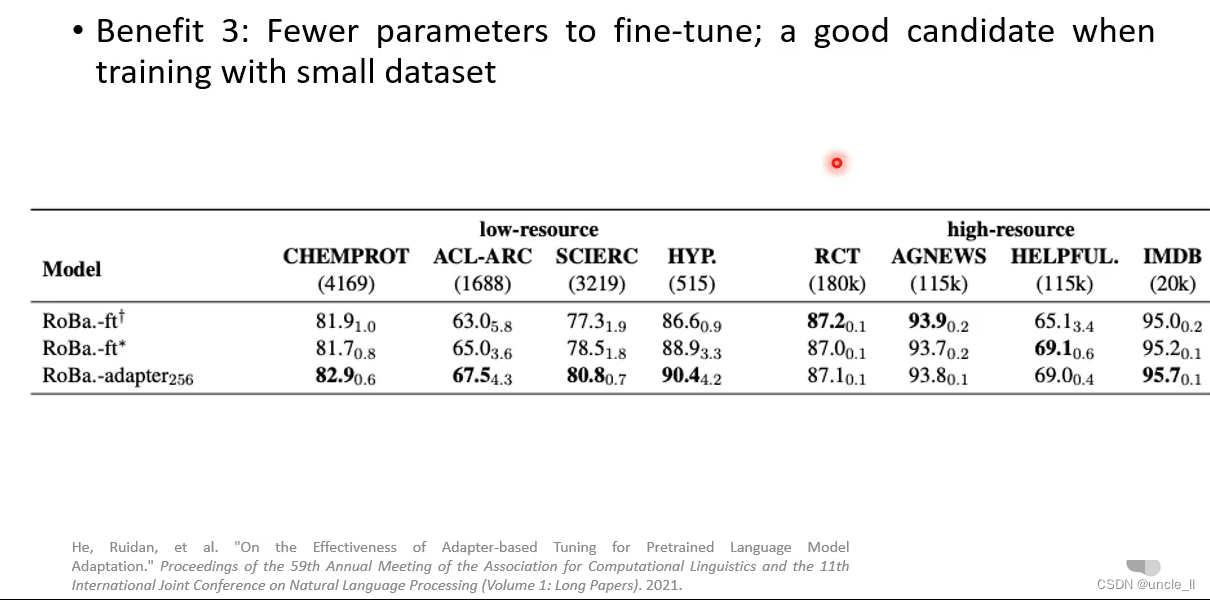
PLMs Are Gigantic——Reducing the Number of Parameters
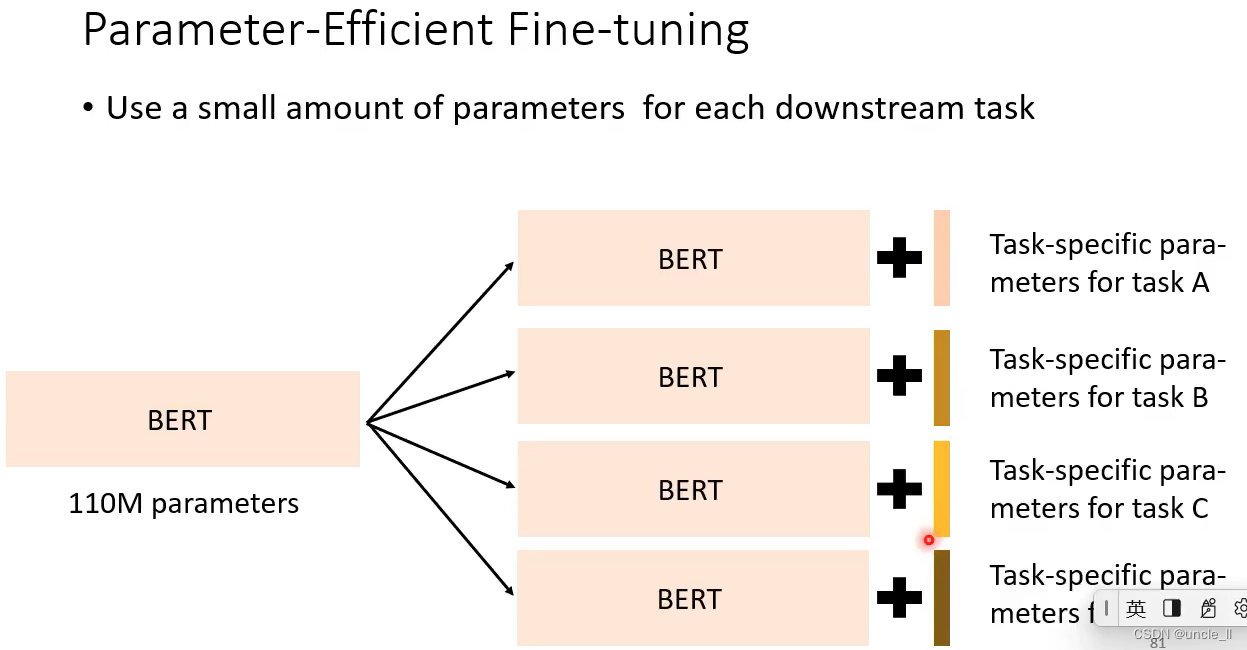
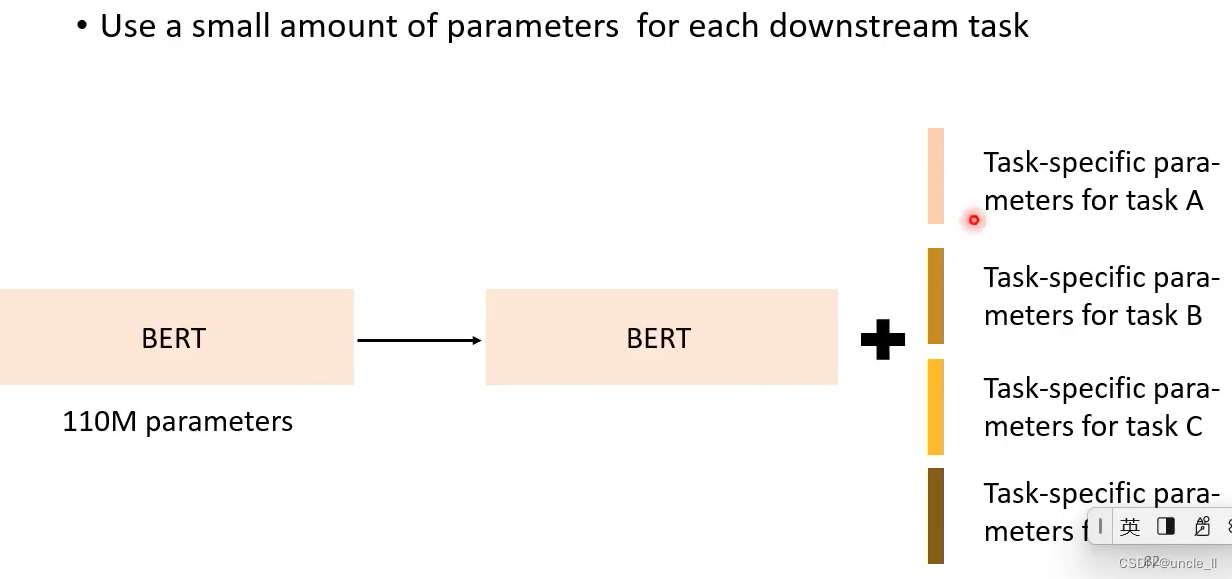
转变为共用一个bert模型
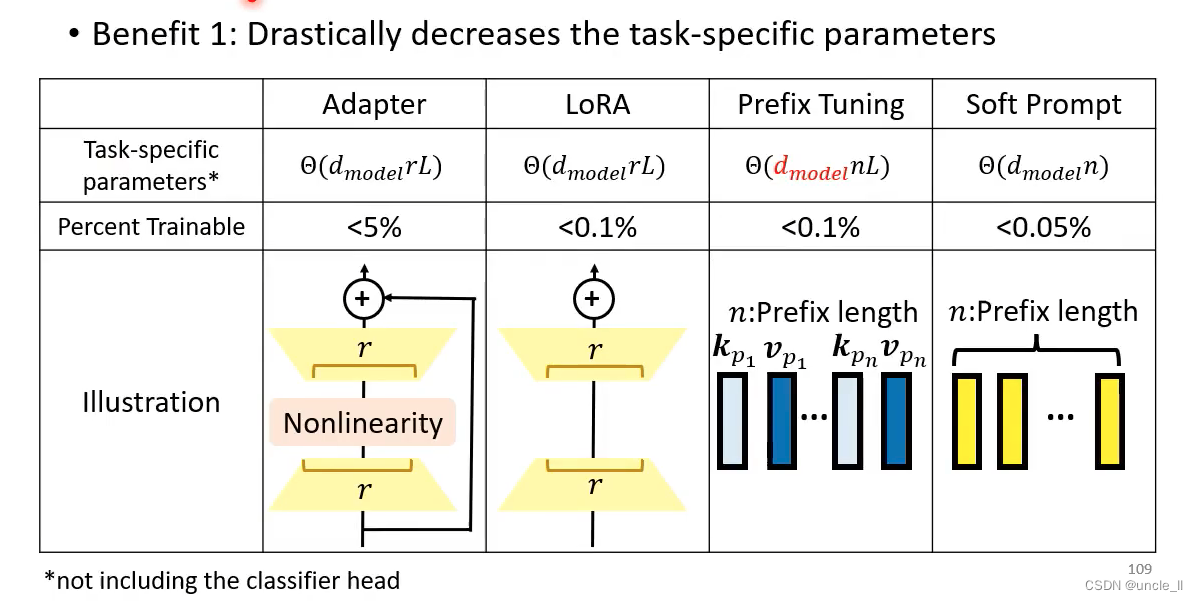
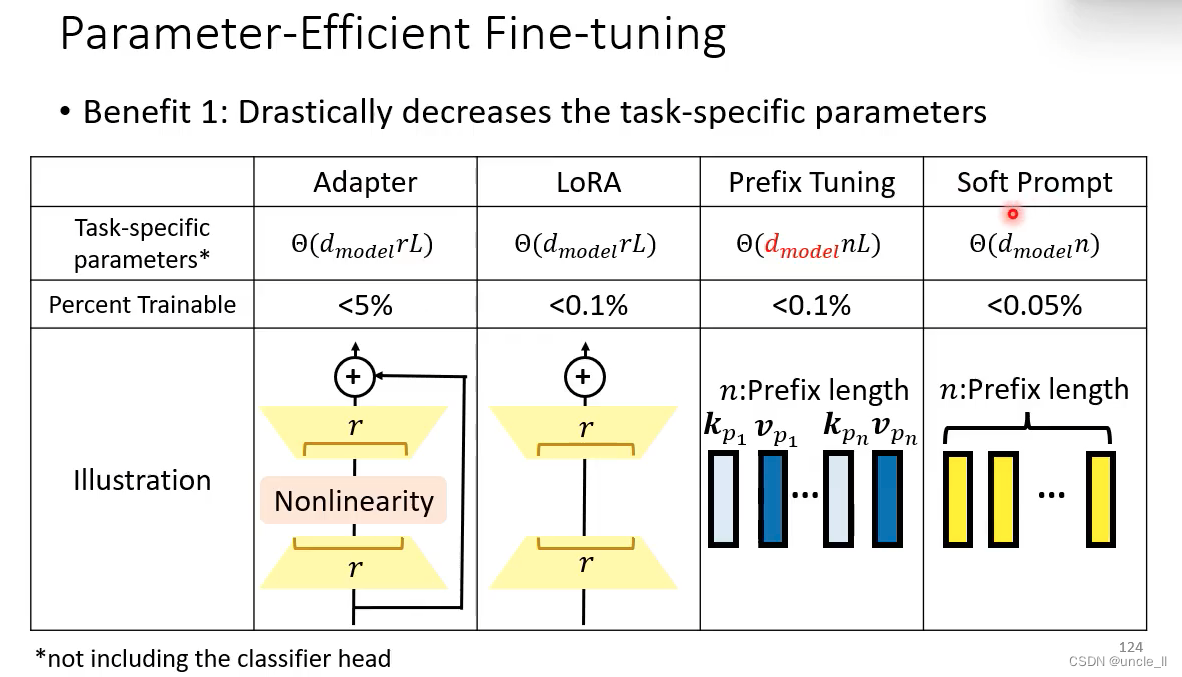
Adapter
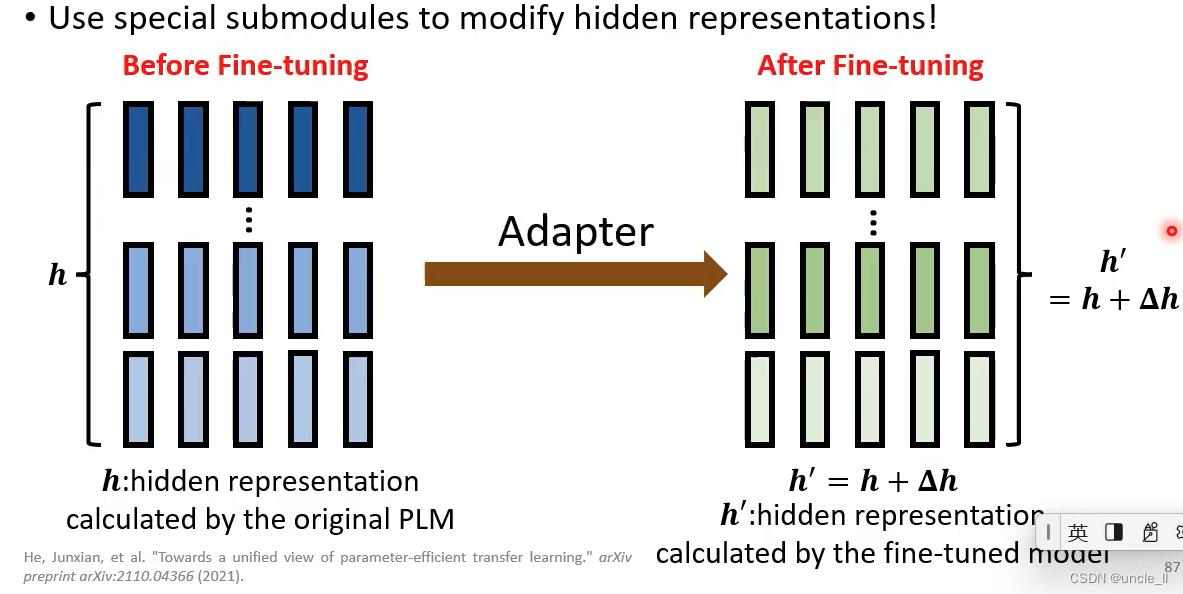
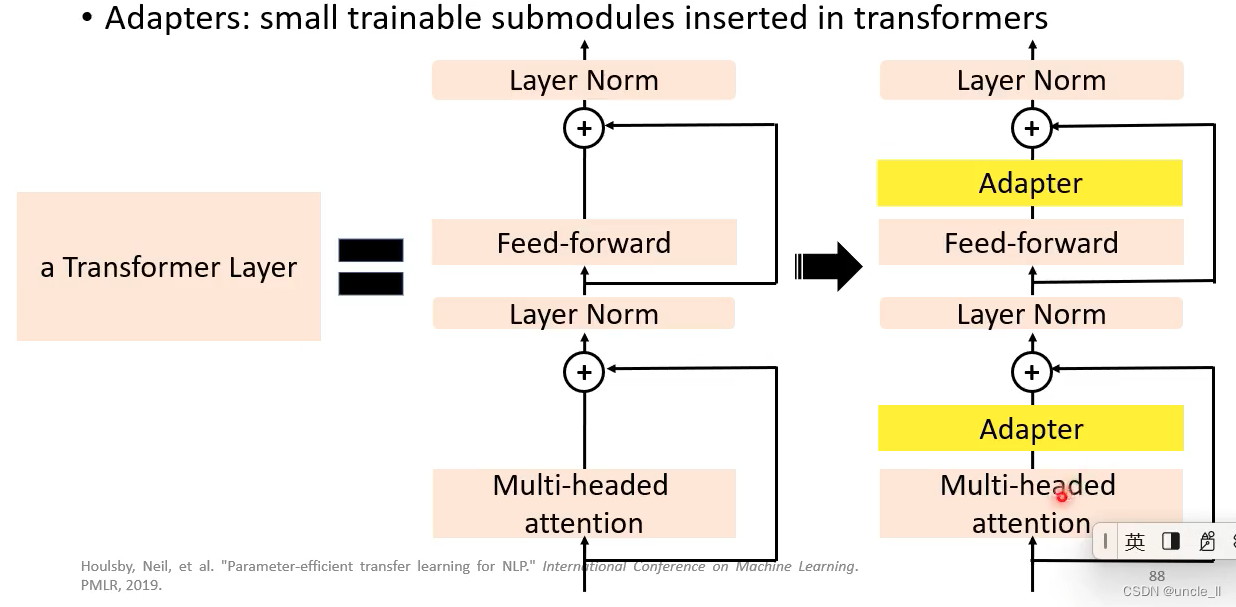
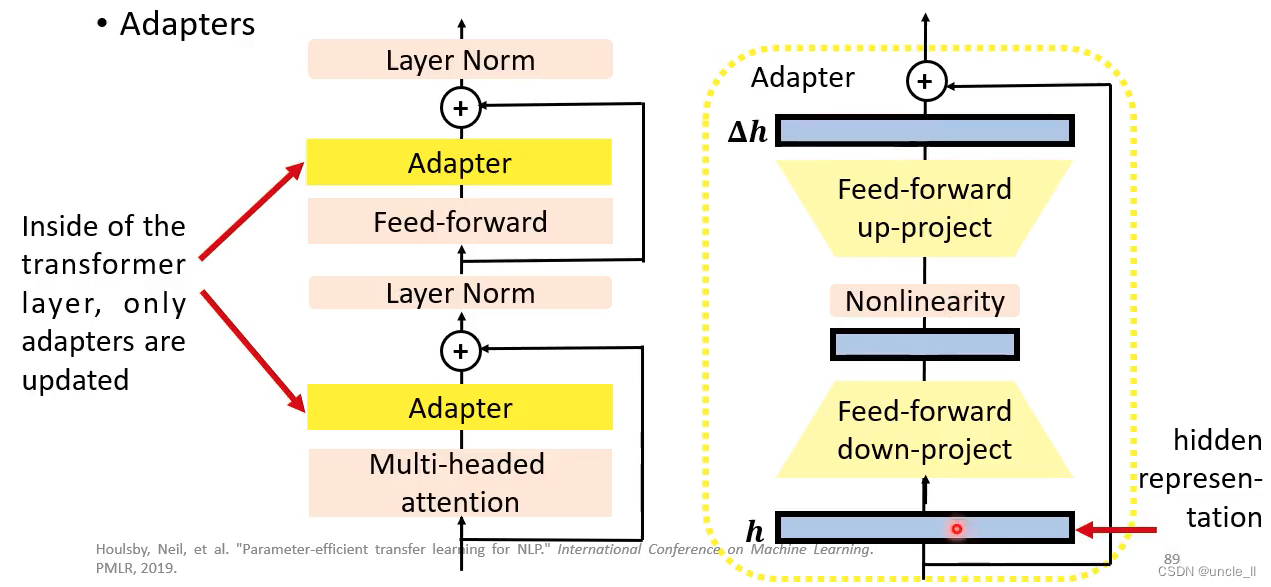
只更新adapter,不更新transformer;adapter做的事情是先降维,然后再升维,产生△h
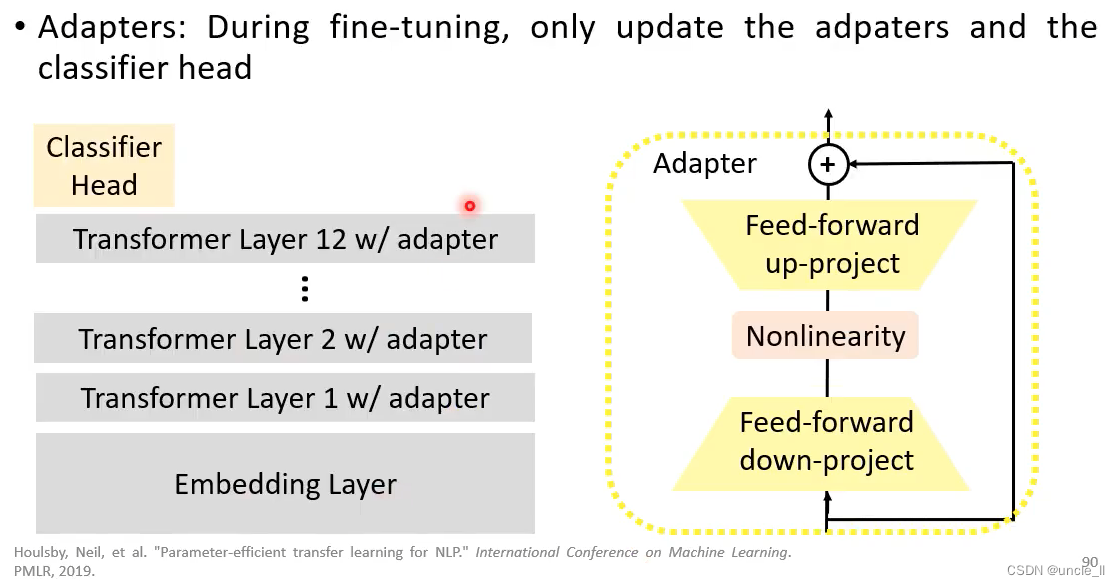
每个下游任务只学习它自己的△h, transformer层的参数h不动,这样能大大减少需要的显存空间。
LoRA
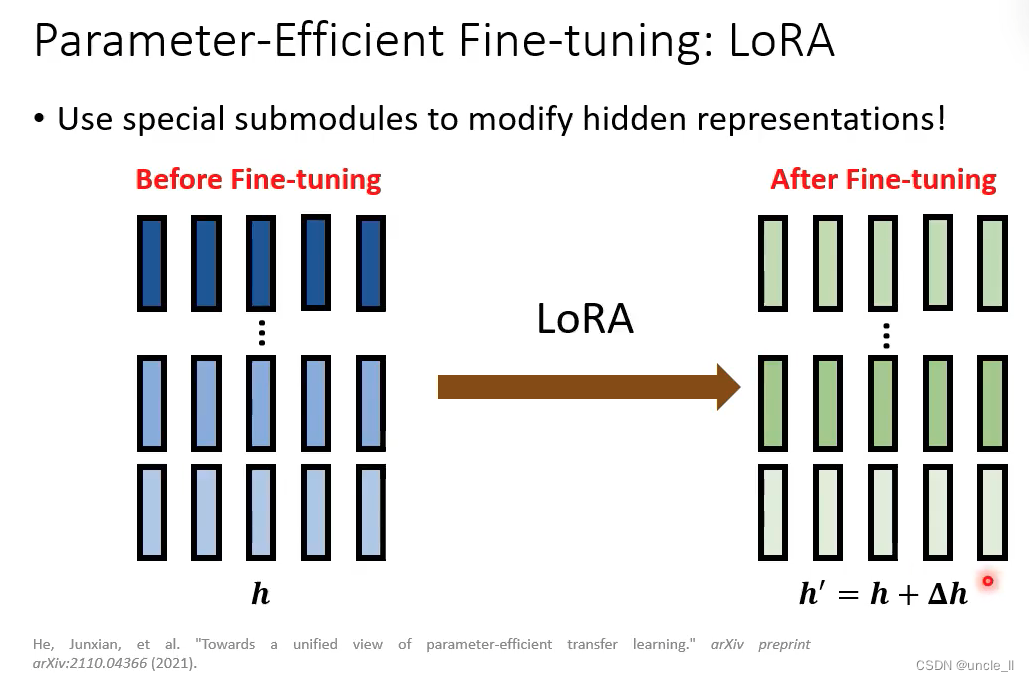
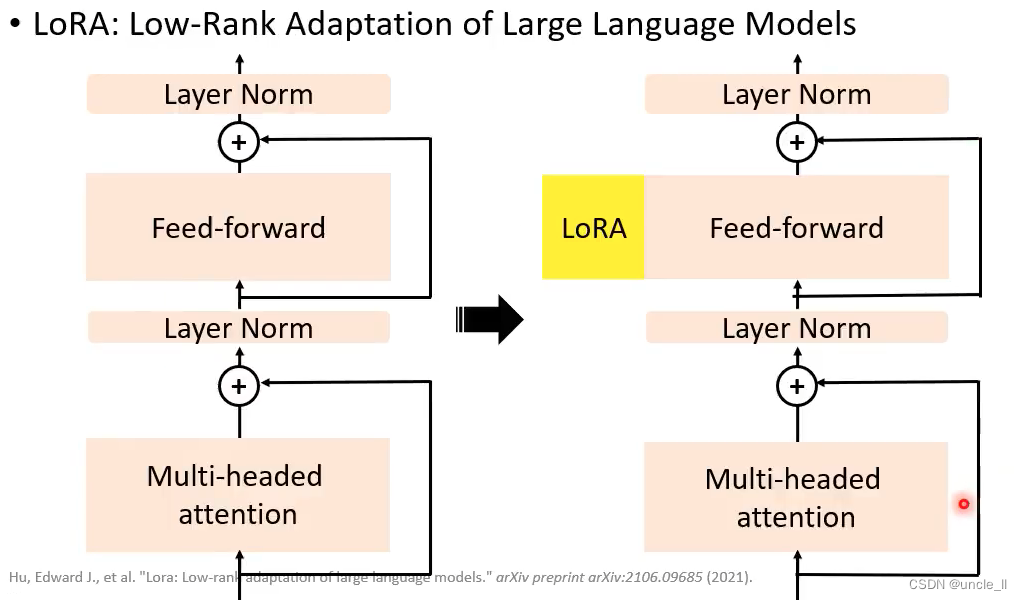
先把低维向量变成高维,然后高维再变成低维。
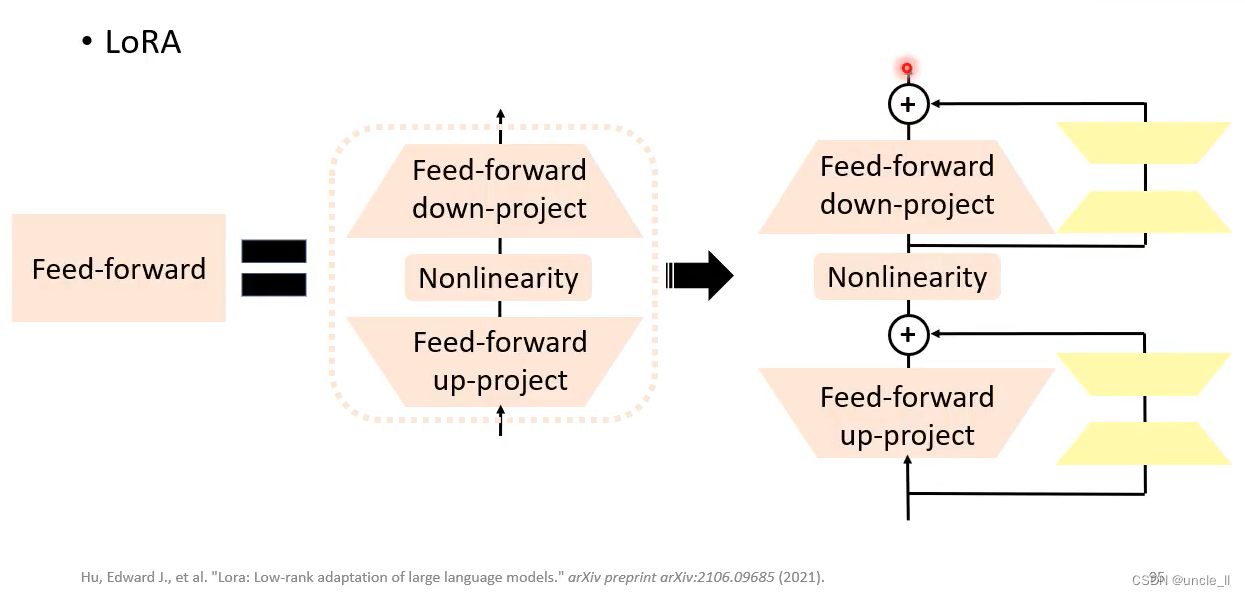
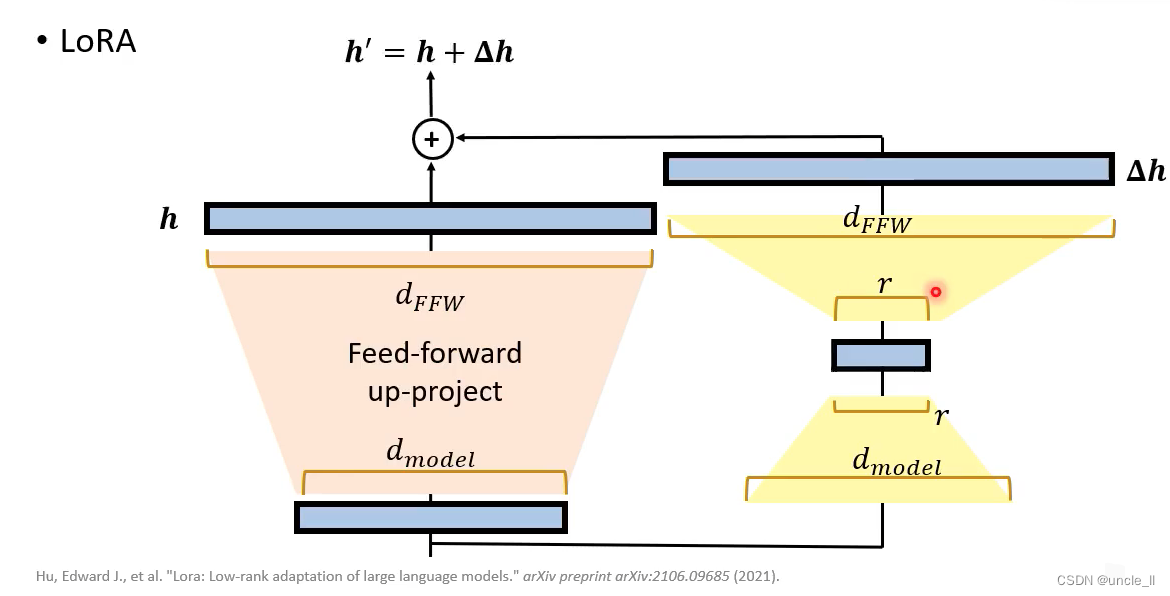
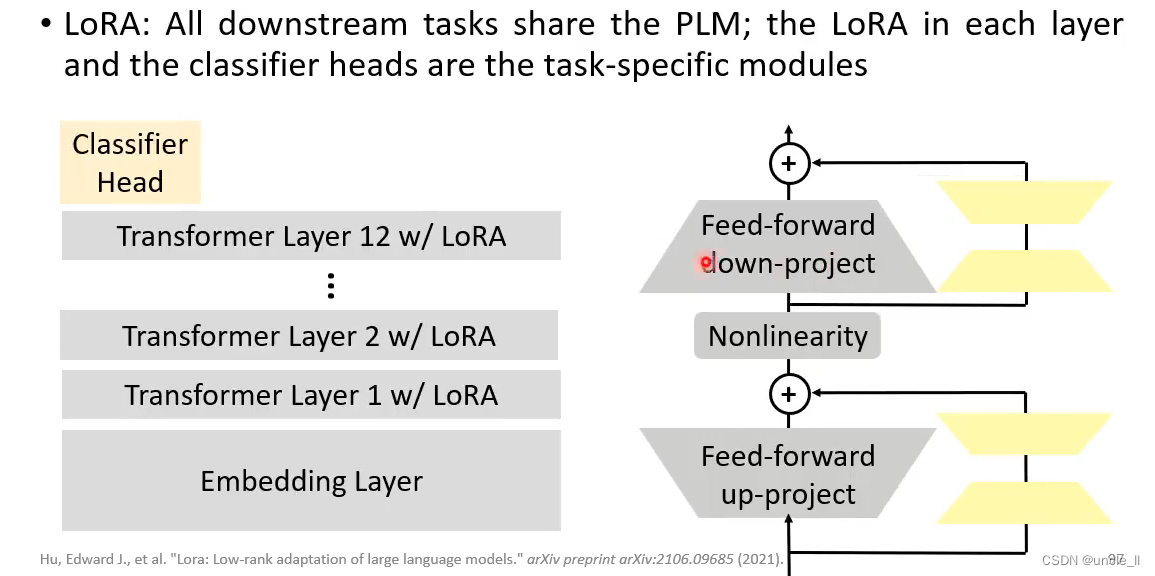
Lora效果比adaper效果好,不会增加模型层数,参数量比adapter要小。
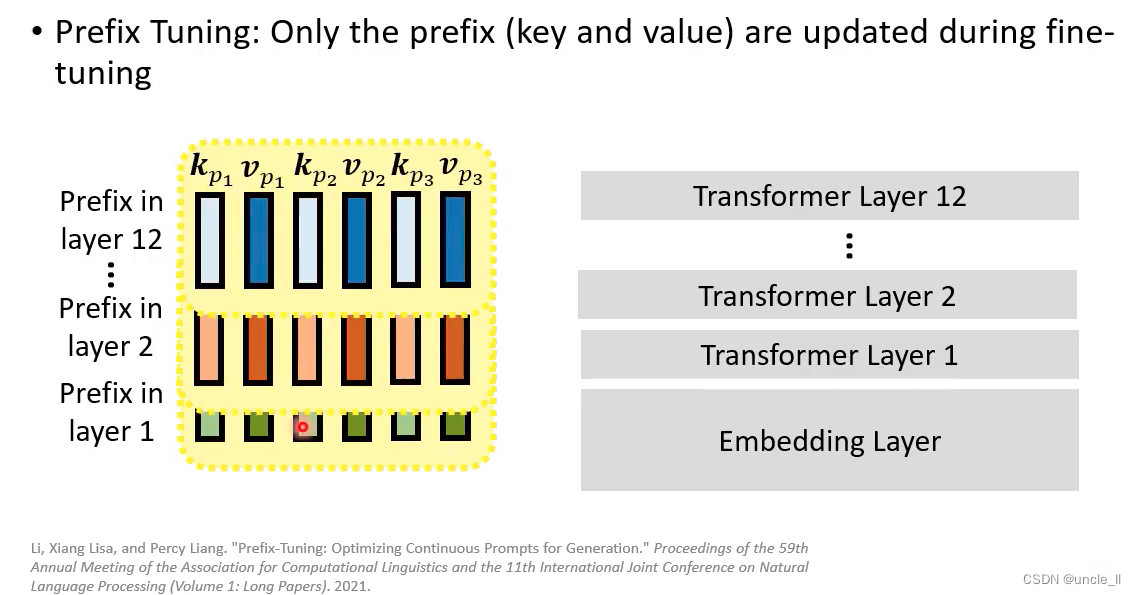
Prefix Tuning
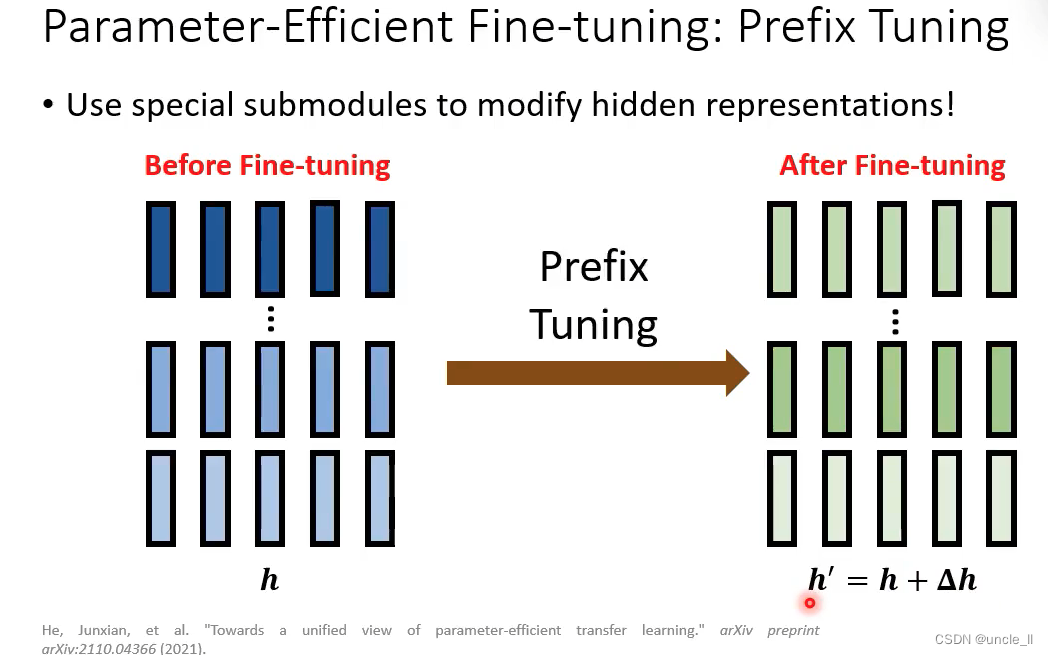

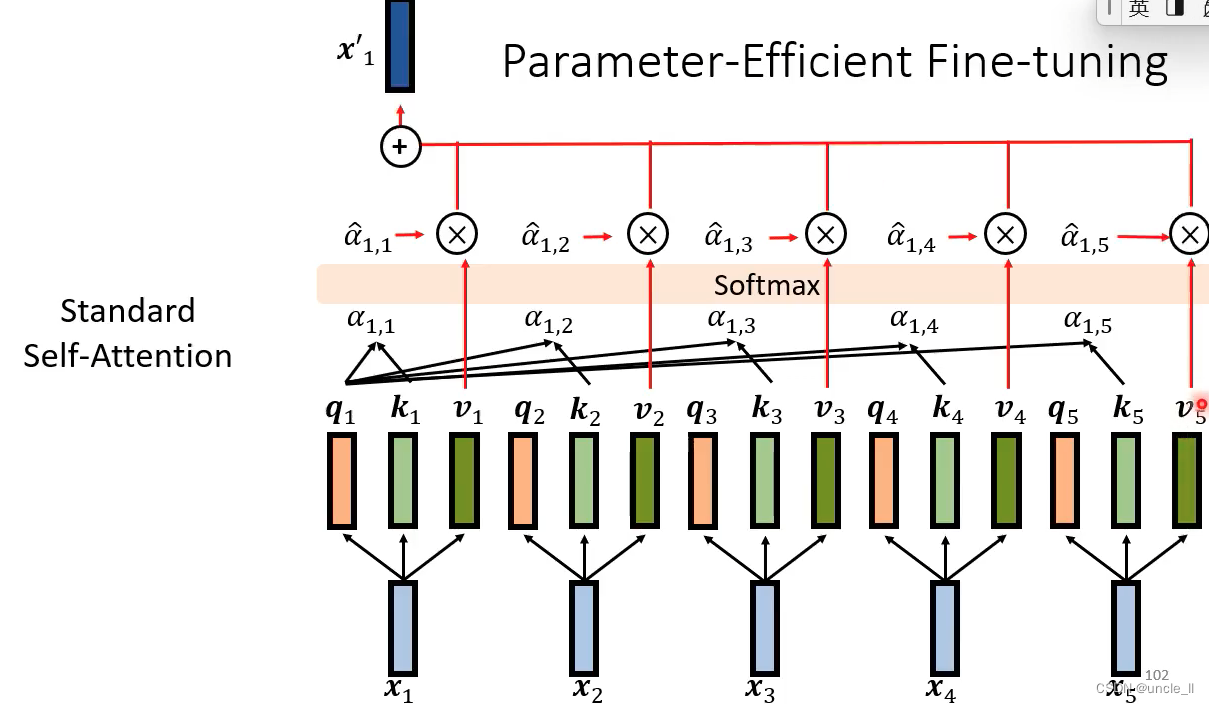
在标准的自注意力结构的前面插了一些东西
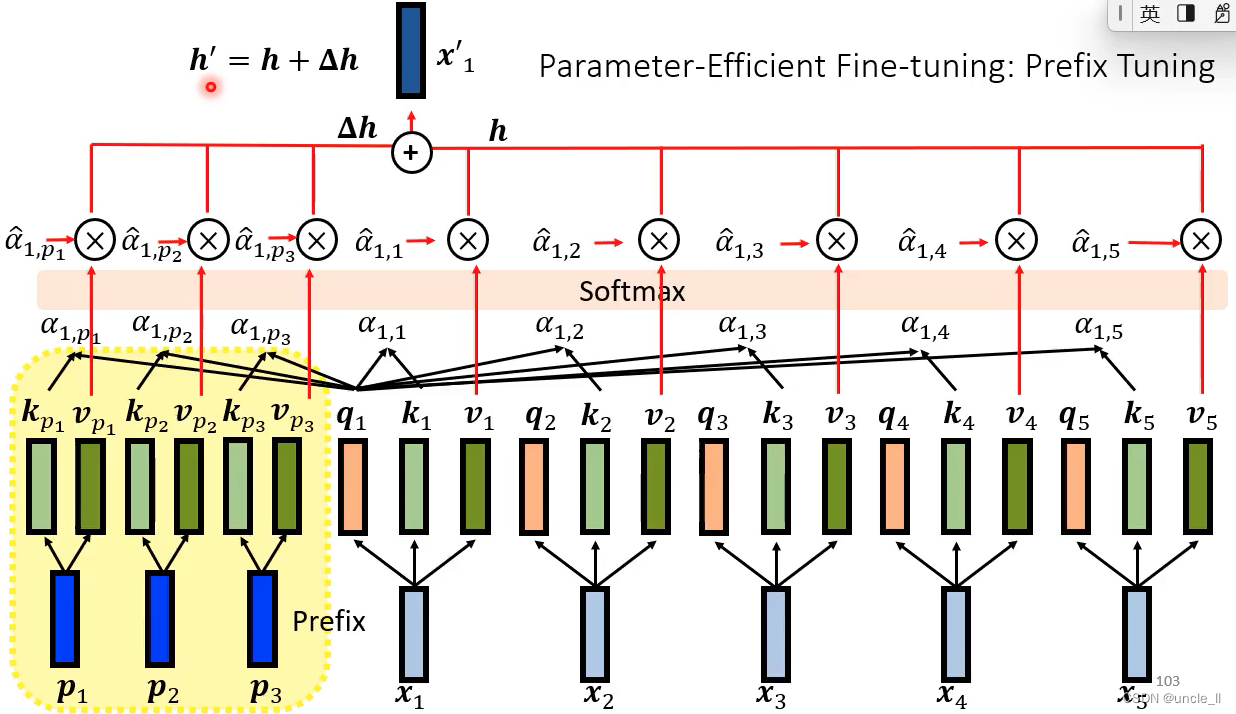
在infer的时候把蓝色的部分丢掉
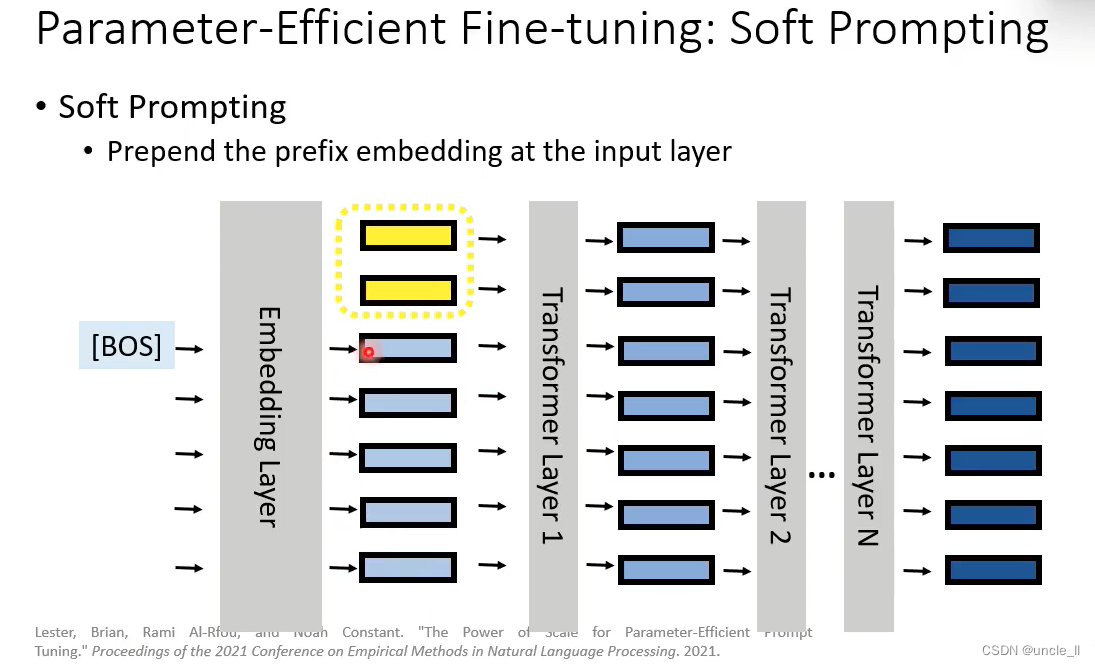
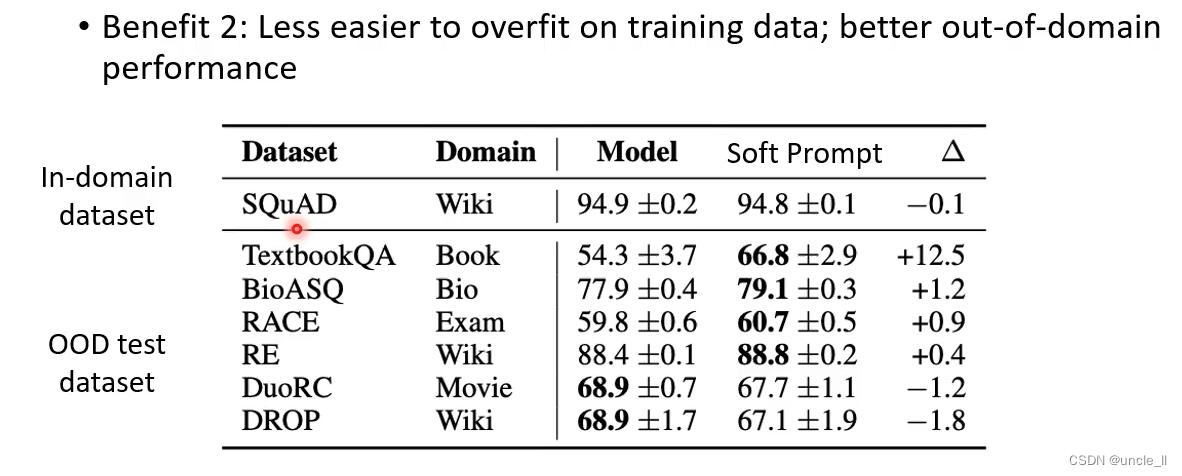
Soft Prompting
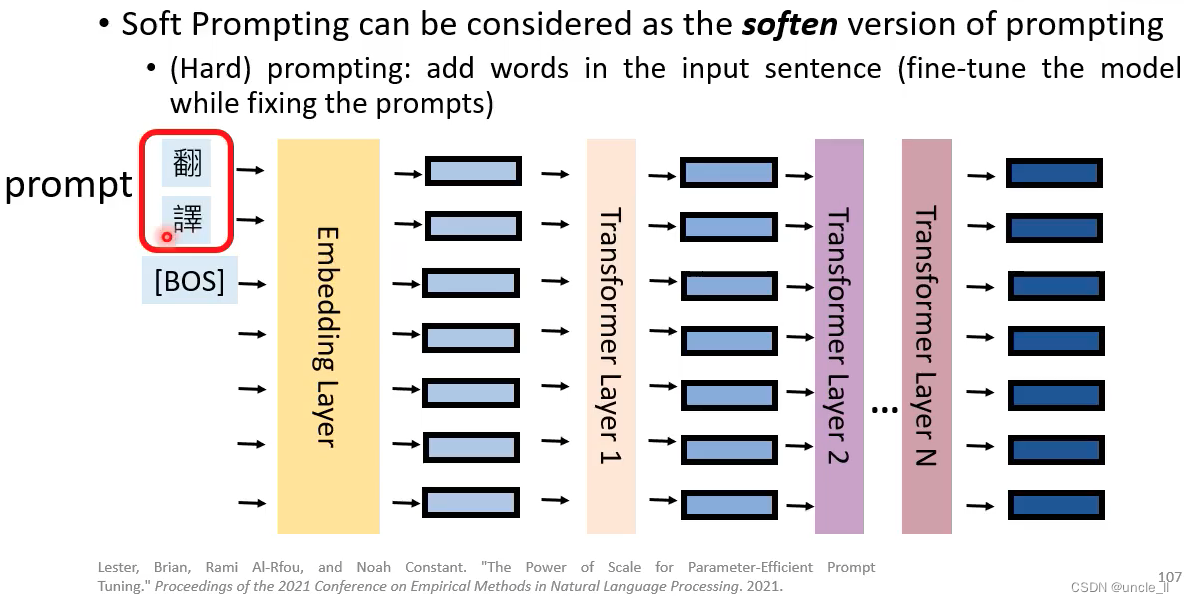
总结
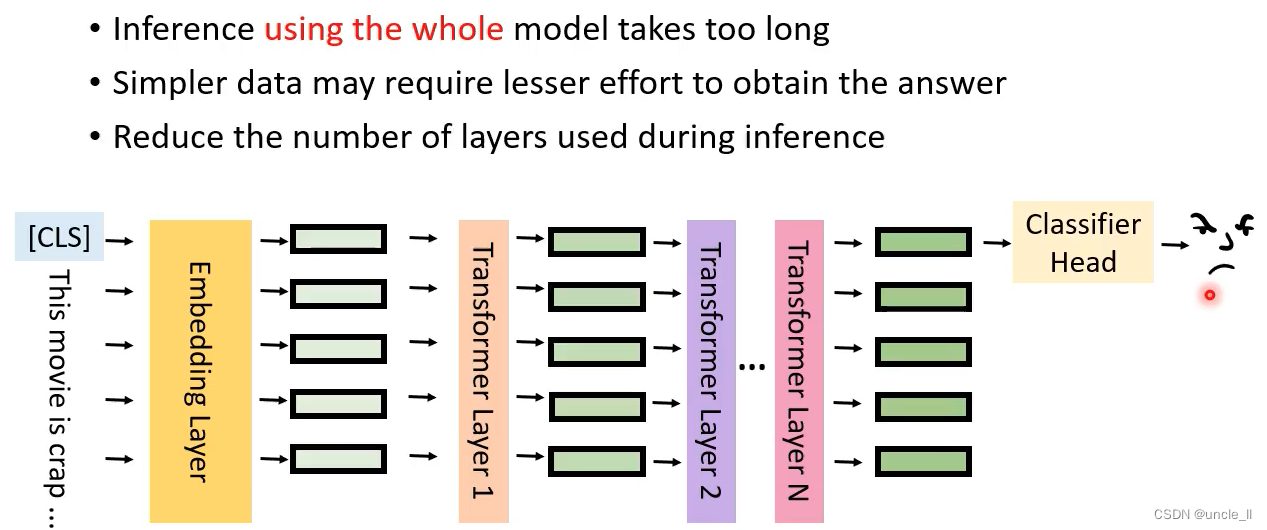
Early Exit
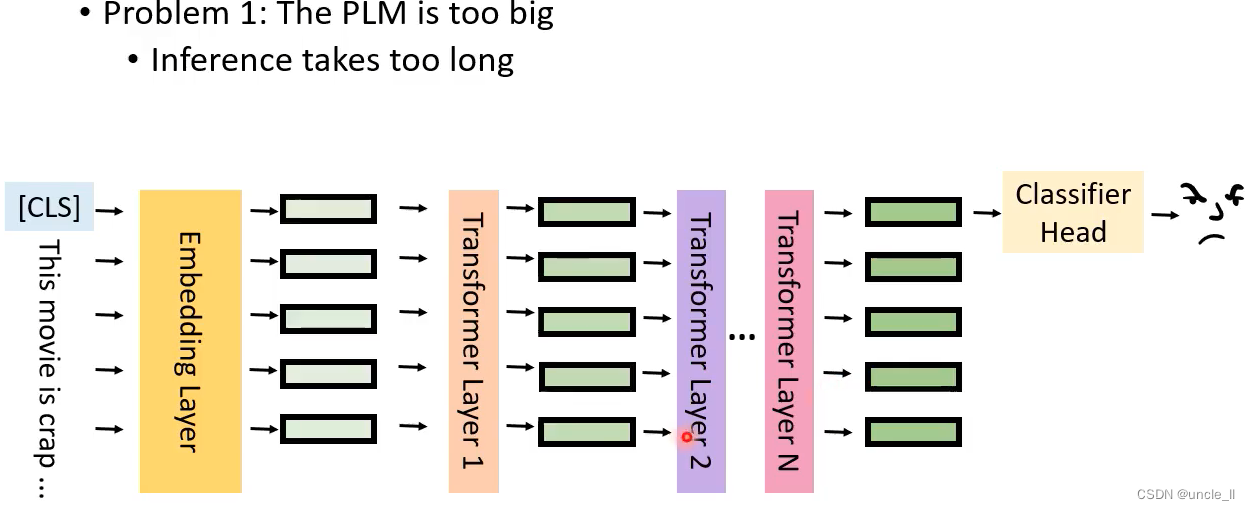
用整个模型跑花很长时间

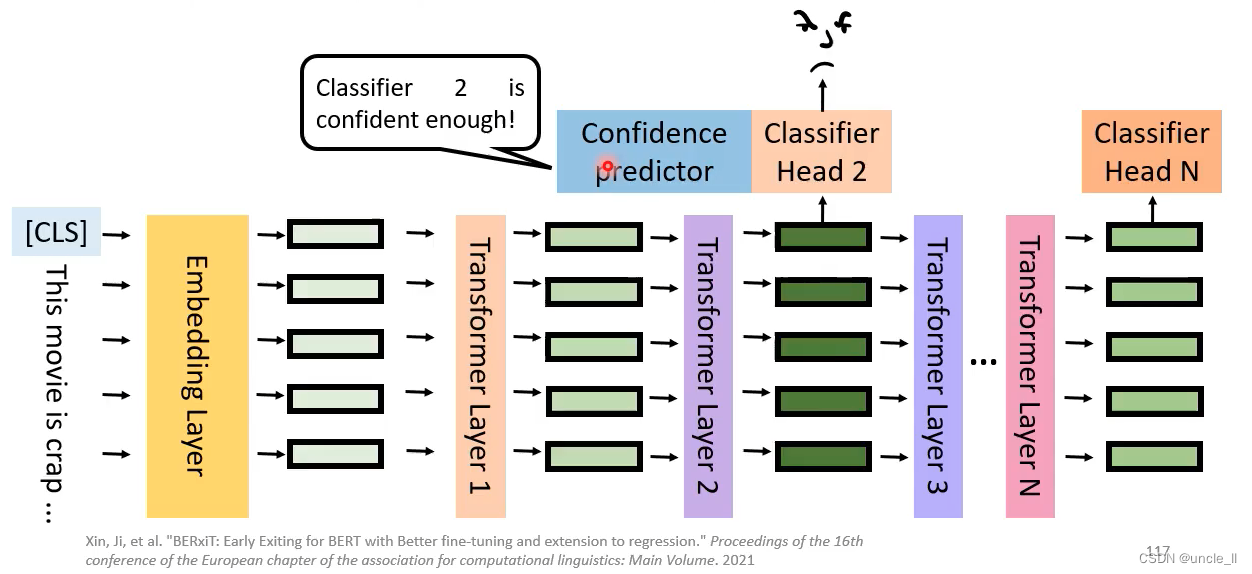
第一层的分类器信心不足,到第二层:
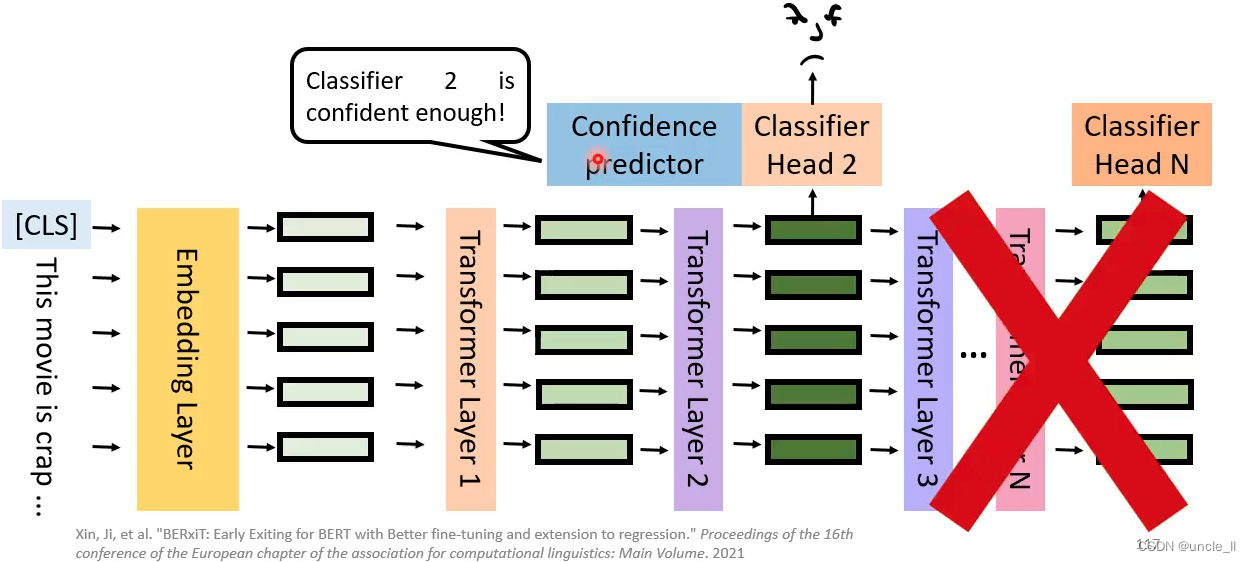
如果信心够了,就不用后面的过程了,以节约时间
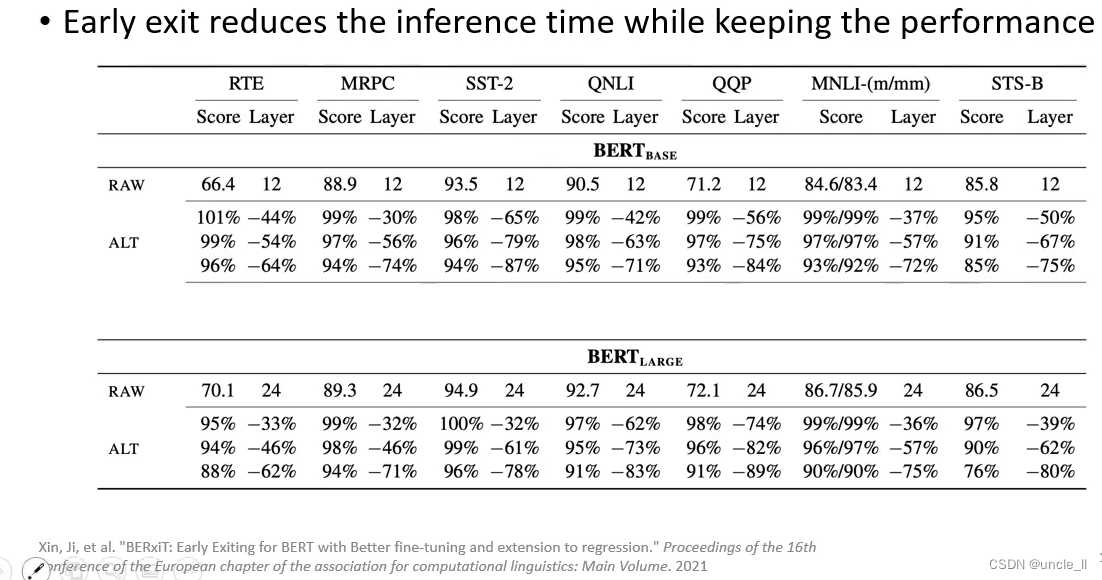
总结

Closing Remarks








![[Linux笔记]常见命令(持续施工)](https://img-blog.csdnimg.cn/880deb62f4704ccba141f5827eef335e.png)