文章目录
- 获取文章链接
- 批量爬取政策文件
- 应用selenium爬取文件信息
- 数据处理
- 导出为excel
获取文章链接
获取中央人民政府网站链接,进入国务院政策文件库,分为国务院文件和部门文件(发改委、工信部、交通运输部、市场监督局、商务部等)
搜索关键词——汽车,即可得到按照 相关度 或者 时间 排列的政策文件。
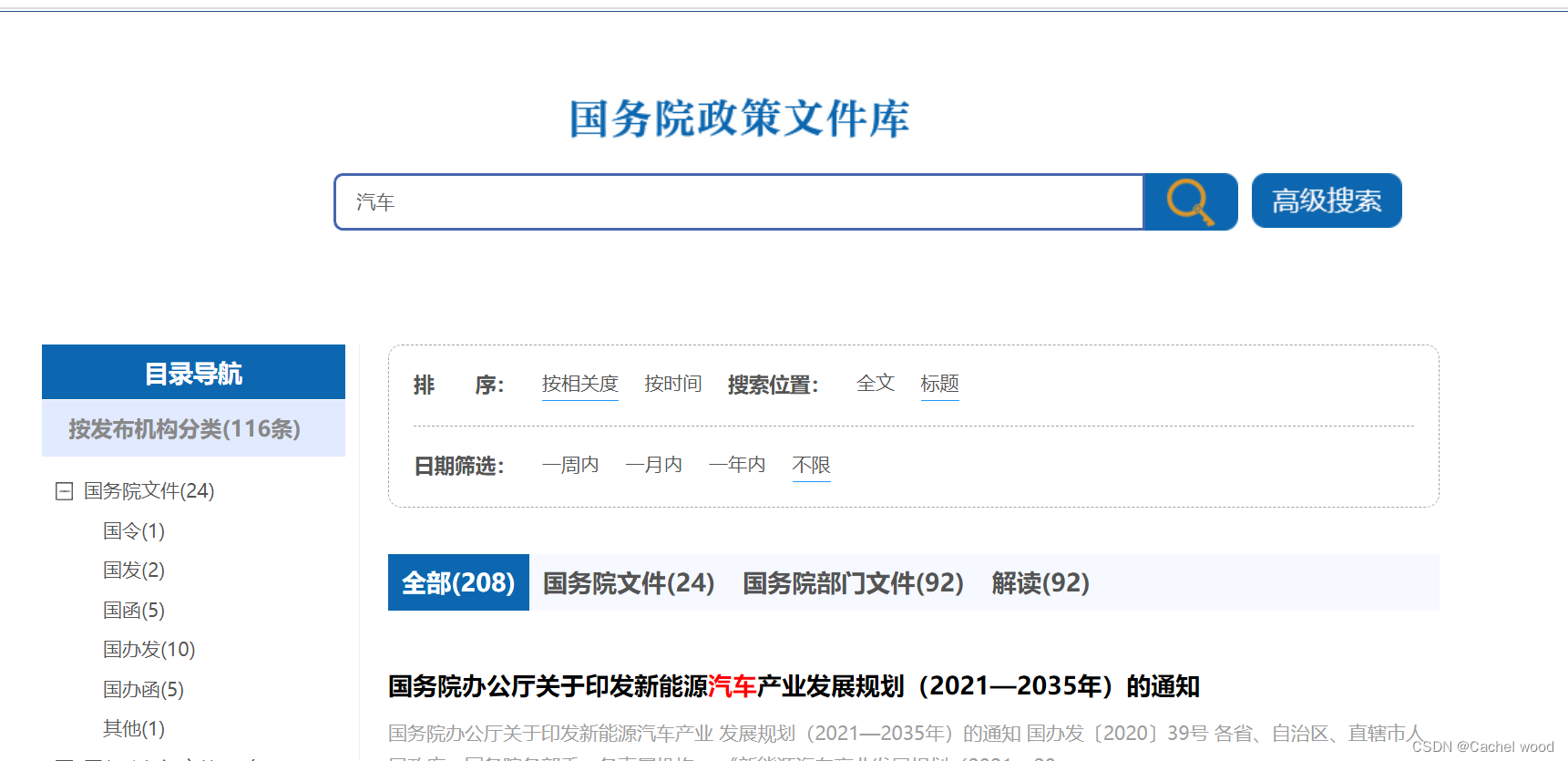
批量爬取政策文件
批量获取文件链接并存入列表
应用selenium爬取文件信息
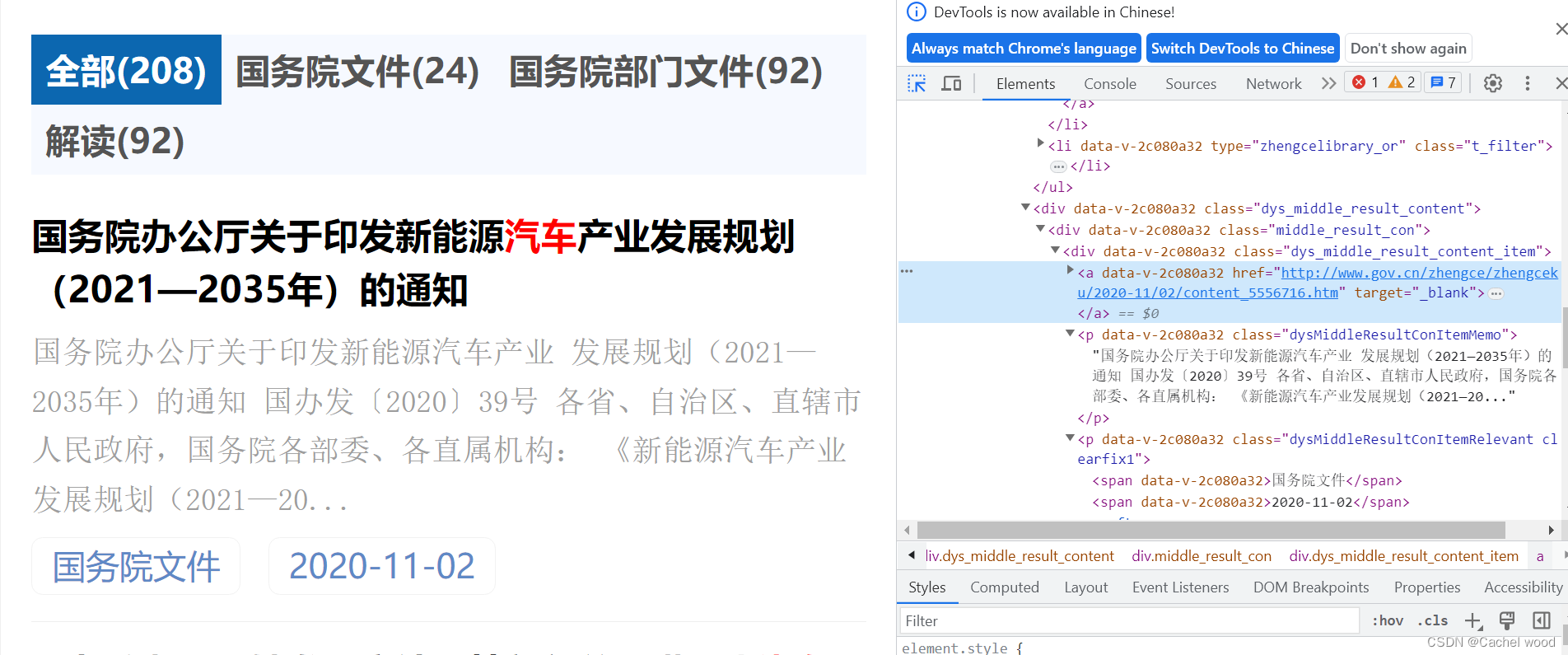
利用xpath定位链接、索引号、标题、发文机关、发文字号、主题分类、成文日期、发布日期、文件内容等信息。
右侧通过光标定位各部分信息,右键点击 copy 并选择 copy xpath即可复制xpath路径。
- 完整代码
from selenium import webdriver
from urllib.error import HTTPError
from selenium.webdriver.common.by import By #selenium新版本写法
import warnings
warnings.filterwarnings('ignore')
"""
爬虫国务院文件
传入链接,返还链接内的全部内容,生成字典
"""
def get_info(id,url):
options = webdriver.ChromeOptions()
options.add_argument('--headless')
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
driver = webdriver.Chrome(options=options)
link = {}
driver.get(url)
try:
link['文章ID'] = id # 序列ID,从0—现有的文件数
link['链接'] = url # 原文链接
#time.sleep(3)
link['索引号'] = driver.find_element(By.XPATH,
'/html/body/div[4]/div/div[2]/div[1]/table/tbody/tr/td/table/tbody/tr[1]/td[2]').text # 索引号
link['标题'] = driver.find_element(By.XPATH,
"/html/body/div[4]/div/div[2]/div[1]/table/tbody/tr/td/table/tbody/tr[3]/td[2]").text # 标题
link['发文机关'] = driver.find_element(By.XPATH,
"/html/body/div[4]/div/div[2]/div[1]/table/tbody/tr/td/table/tbody/tr[2]/td[2]").text # 发文机关
link['发文字号'] = driver.find_element(By.XPATH,
"/html/body/div[4]/div/div[2]/div[1]/table/tbody/tr/td/table/tbody/tr[4]/td[2]").text # 发文字号
link['主题分类'] = driver.find_element(By.XPATH,
"/html/body/div[4]/div/div[2]/div[1]/table/tbody/tr/td/table/tbody/tr[1]/td[4]").text # 主题分类
link['成文日期'] = driver.find_element(By.XPATH,
"/html/body/div[4]/div/div[2]/div[1]/table/tbody/tr/td/table/tbody/tr[2]/td[4]").text # 成文日期
link['发布日期'] = driver.find_element(By.XPATH,
'/html/body/div[4]/div/div[2]/div[1]/table/tbody/tr/td/table/tbody/tr[4]/td[4]') # 发布日期
link['文件内容'] = driver.find_element(By.XPATH,"//*[@id='UCAP-CONTENT']").text # 内容
with open('汽车/国务院文件/'+link['标题']+'.txt','w',encoding='utf-8') as file:
file.write(link['文件内容'])
except HTTPError:
return None
driver.quit()
return link
数据处理
每次爬取单一文件信息并整理为dataframe,之后按行合并。
import pandas as pd
df = pd.DataFrame()
with open('link1.txt','r',encoding='utf-8') as f:
links = f.readlines()
for id,url in enumerate(links):
url = url.strip('\n')
print(url)
result = get_info(id,url)
df1 = pd.DataFrame.from_dict(result,'index').T
df = pd.concat([df,df1],axis=0)
df
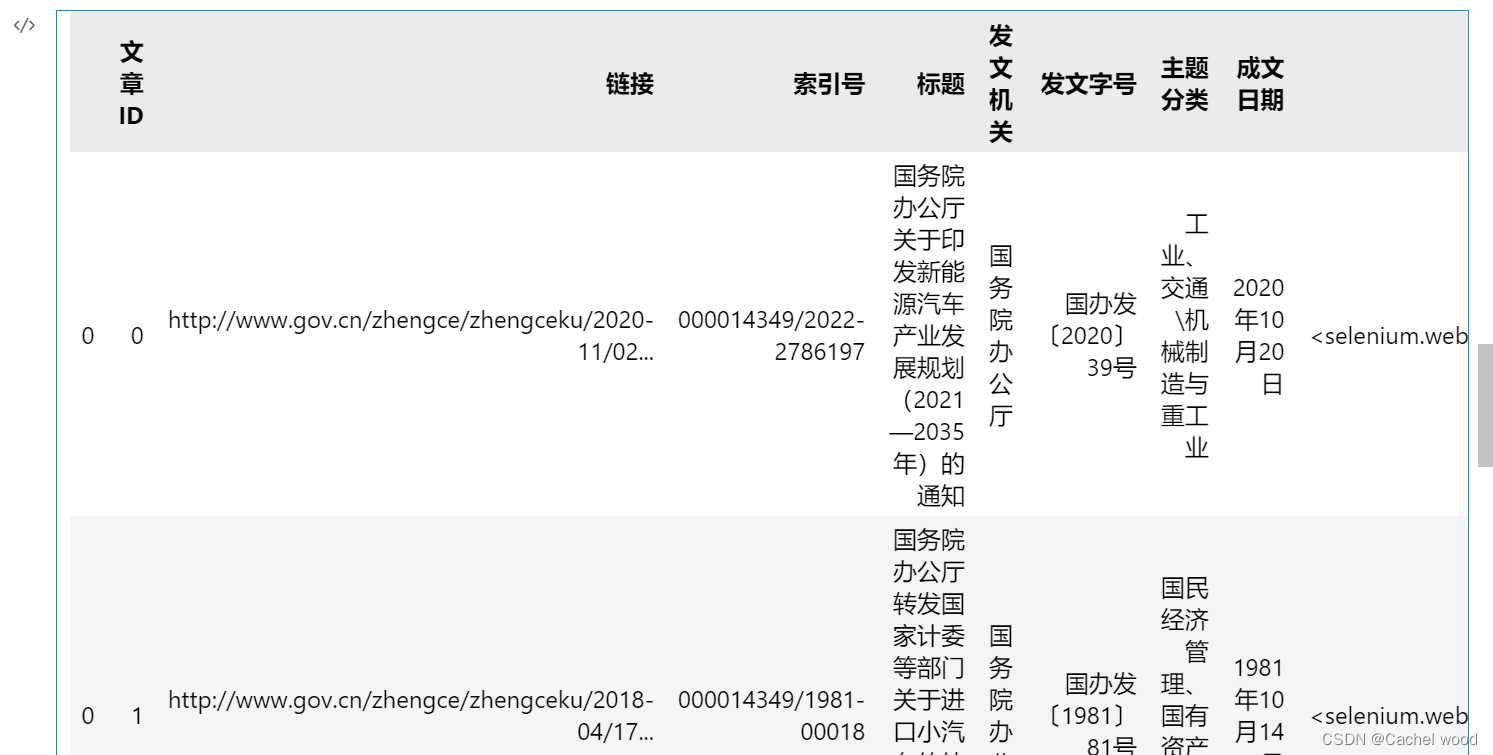
导出为excel
df.to_excel('汽车行业政策文本研究.xlsx',index=False)








![[QT编程系列-15]: 基础框架 - 信号与槽,connect函数详解](https://img-blog.csdnimg.cn/img_convert/331c4058d2d4bb01b322fcdba2fd97c0.png)