一、脚本展示
1.流水线编译过程,执行apk --update add --no-cache xxx
2.报错ERROR: xxx package mentioned in index not found (try 'apk update')
3.内网环境缺依赖包,需要从清华源下载对应的包,但是需要根据报错一个个找,一个个点击下载麻烦
4.一开始打算下载官网全部依赖,但是数量太大,而且频繁拉取容易反爬,改为根据报错信息存放到E:\download\check.txt,程序自动识别包名下载到对应目录
import urllib.request # url request
import re # regular expression
import os # dirs
import time
'''
url 下载网址
pattern 正则化的匹配关键词
Directory 下载目录
'''
'''
1.流水线编译过程,执行apk --update add --no-cache xxx
2.报错ERROR: xxx package mentioned in index not found (try 'apk update')
3.内网环境缺依赖包,需要从清华源下载对应的包,但是需要根据报错一个个找,一个个点击下载麻烦
4.一开始打算下载官网全部依赖,但是数量太大,而且频繁拉取容易反爬,改为根据报错信息存放到E:\download\check.txt,程序自动识别包名下载到对应目录
'''
def BatchDownload(url, pattern, Directory):
# 拉动请求,模拟成浏览器去访问网站->跳过反爬虫机制
headers = {'User-Agent',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36'}
opener = urllib.request.build_opener()
opener.addheaders = [headers]
# 官网下载打开注释,获取网页内容
# content = opener.open(url).read().decode('utf8')
# 根据报错内容直接查询,官网下载注释
with open("E:\download\check.txt", "r") as f: # 打开文件
content = f.readlines() # 读取文件
content = str(content) # 转化为str方便正则匹配
content = content.replace(': ', '') # 利用两头字符串卡住关键词
# 构造正则表达式,从content中匹配关键词pattern
raw_hrefs = re.findall(pattern, content, 0)
# 官网下载打开注释,set函数消除重复元素
# list方便遍历,set去重,看情况选择
# hset = list(raw_hrefs)
# 创建本地文件夹存放依赖包,看情况选择
dir_name = 'E:\download\main'
if not os.path.isdir(dir_name):
os.makedirs(dir_name)
dir_name2 = 'E:\download\community'
if not os.path.isdir(dir_name2):
os.makedirs(dir_name2)
# 下载链接
for href in raw_hrefs:
# 之所以if else 是为了区别只有一个链接的特别情况
if (len(raw_hrefs) > 1):
# realhref = href.replace('href="', '') # 官网直接拉才有href字段
realhref = href.replace('ERROR', '').replace('package', '')
# main
link = url + realhref + '.apk'
filename = os.path.join(Directory, realhref + '.apk')
# community
url2 = "http://mirrors.tuna.tsinghua.edu.cn/alpine/v3.14/community/aarch64/"
link2 = url2 + realhref + '.apk'
Directory2 = 'E:\download\community'
filename2 = os.path.join(Directory2, realhref + '.apk')
# 因为依赖包下载地址不唯一,找不到依赖尝试其他地址
try:
print("正在下载", filename + '.apk')
urllib.request.urlretrieve(link, filename)
except IOError:
print("main无包,尝试community目录", filename2 + '.apk')
urllib.request.urlretrieve(link2, filename2)
print("community/" + realhref + ".apk" + " OK!")
else:
print("main/" + realhref + ".apk" + " OK!")
else:
link = url + href
filename = os.path.join(Directory, href)
print("正在下载", filename + '.apk')
urllib.request.urlretrieve(link, filename)
print("成功下载!")
# 无sleep间隔,网站认定这种行为是攻击,反反爬虫
time.sleep(1)
# 官网直接下载全部依赖
# BatchDownload('https://mirrors.tuna.tsinghua.edu.cn/alpine/v3.14/community/aarch64/',r'\bhref\S*?.apk\b','E:\download')
# 根据缺包提示下载对应的依赖
BatchDownload('http://mirrors.tuna.tsinghua.edu.cn/alpine/v3.14/main/aarch64/', r'\bERROR\S*?package\b', 'E:\download\main')
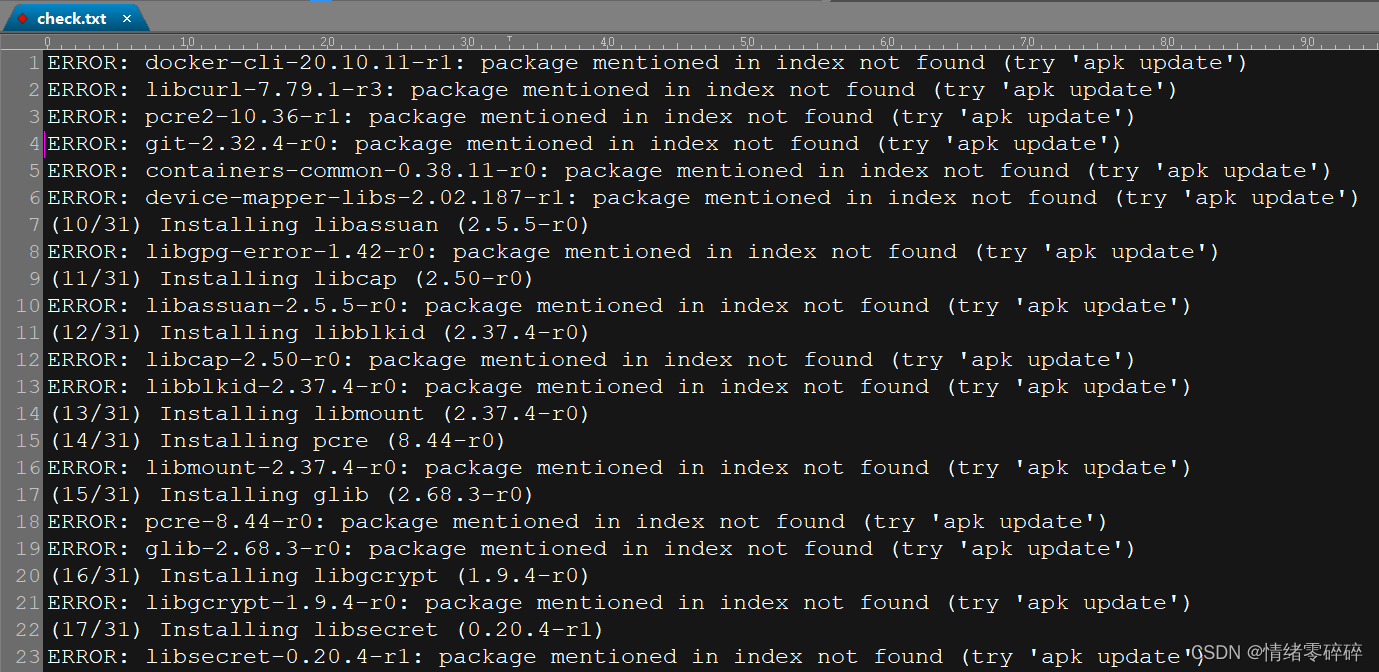
二、报错信息展示
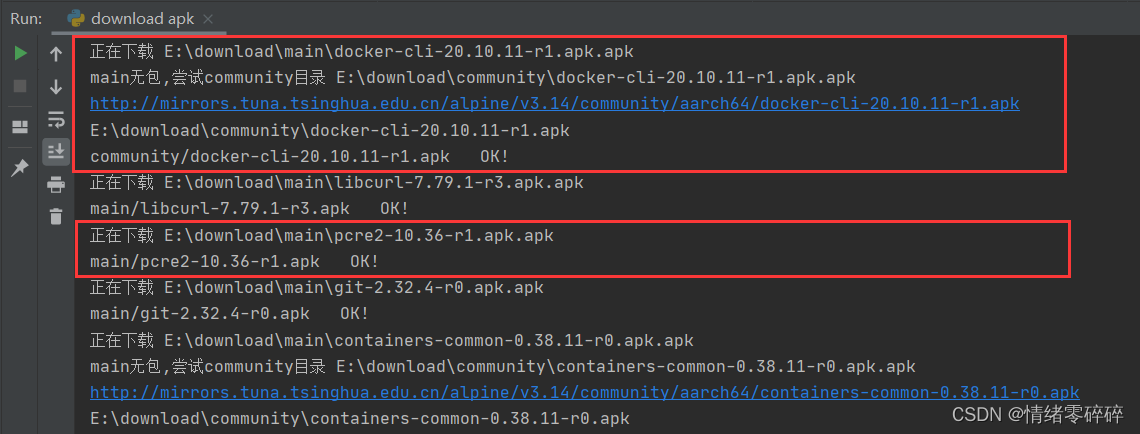
支持将缺少依赖的报错信息存放到E:\download\check.txt,脚本会根据正则自动匹配包名(类似skopeo-1.3.1-r2.apk)下载到对应目录E:\download\xxx\
三、执行结果展示
![[附源码]计算机毕业设计教学辅助系统Springboot程序](https://img-blog.csdnimg.cn/12c0841fba6746869dfcc27f9d822552.png)